Pytorch学习笔记
Pytorch 如何定义自己的数据集
数据集:Penn-Fudan数据集
前言
在学习pytorch官网教程时,作者对Penn-Fudan数据集进行了定义,并且在自定义的数据集上实现了对R-CNN模型的微调。
此篇笔记简单总结一下pytorch如何实现定义自己的数据集
数据集必须继承torch.utils.data.Dataset类,并且实现__len__和__getitem__方法
其中__getitem__方法返回的是image和target(一个包含图像相关信息的字典类型)
Penn-Fudan数据集的介绍

数据集主要分为三个部分,其中的PNGImages为行人的照片图片的集合
PedMasks为图片的掩膜集合
通过掩膜,产生目标程序要实现的蒙版效果
官方例子,原图:
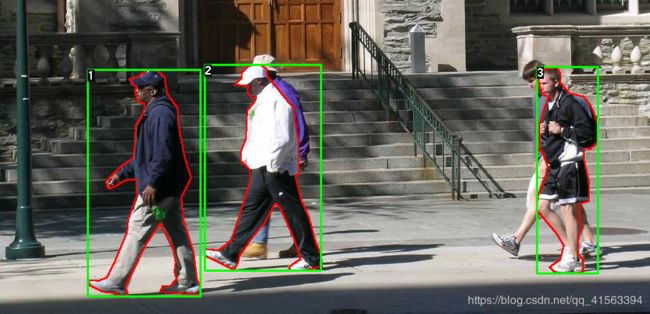
Mask处理后

#官方定义数据集代码(含自己的注释)
import os
import numpy as np
import torch
from PIL import Image
class PennFudanDataset(object):
def __init__(self, root, transforms):
self.root = root
self.transforms = transforms
#分别读取PNGImages和PedMasks文件夹下面的所有文件,并组成一个list
self.imgs = list(sorted(os.listdir(os.path.join(root, "PNGImages"))))
self.masks = list(sorted(os.listdir(os.path.join(root, "PedMasks"))))
def __getitem__(self, idx):
# 分别相应的加载每个list里面的图片信息
img_path = os.path.join(self.root, "PNGImages", self.imgs[idx])
mask_path = os.path.join(self.root, "PedMasks", self.masks[idx])
img = Image.open(img_path).convert("RGB")
#不需要convert("RGB")因为Mask的背景全是0
mask = Image.open(mask_path)
# 将mask的PIL图转换为numpy数组
mask = np.array(mask)
# 将mask简化,此时的obj_ids为[0,1,2],有两种类型的边界框
obj_ids = np.unique(mask)
# first id is the background, so remove it
#0表示黑色的背景,进行去除
obj_ids = obj_ids[1:]
#split the color-encoded mask into a set of binary masks
#None就是newaxis,相当于多了一个轴,维度
masks = mask == obj_ids[:, None, None]
#get bounding box coordinates for each mask
#定义边界框的tensor
num_objs = len(obj_ids)
boxes = []
for i in range(num_objs):
pos = np.where(masks[i])
xmin = np.min(pos[1])
xmax = np.max(pos[1])
ymin = np.min(pos[0])
ymax = np.max(pos[0])
boxes.append([xmin, ymin, xmax, ymax])
#convert everything into a torch.Tensor
boxes = torch.as_tensor(boxes, dtype=torch.float32)
# there is only one class
labels = torch.ones((num_objs,), dtype=torch.int64)
masks = torch.as_tensor(masks, dtype=torch.uint8)
image_id = torch.tensor([idx])
area = (boxes[:, 3] - boxes[:, 1]) * (boxes[:, 2] - boxes[:, 0])
# suppose all instances are not crowd
iscrowd = torch.zeros((num_objs,), dtype=torch.int64)
#返回的target字典赋予相应的值
target = {}
target["boxes"] = boxes
target["labels"] = labels
target["masks"] = masks
target["image_id"] = image_id
target["area"] = area
target["iscrowd"] = iscrowd
if self.transforms is not None:
img, target = self.transforms(img, target)
return img, target
def __len__(self):
return len(self.imgs)
reference
官方文档:TORCHVISION对象检测微调程序
定义自己的数据集及加载训练