利用python爬取博客信息并保存在Excel中
只放代码
import re,json,requests
from lxml import etree
import xlwt
# 分页
# 找页码变化的规律
for i in range(1,6):
base_url = 'https://blog.csdn.net/qq_42374697/article/list/%s'%(i)
headers = {
'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/80.0.3987.122 Safari/537.36',
}
response = requests.get(base_url,headers=headers)
html = etree.HTML(response.text)
div_list = html.xpath('//div[@class="article-item-box csdn-tracking-statistics"]')
# print(dd_list)
info_list = []
for div in div_list:
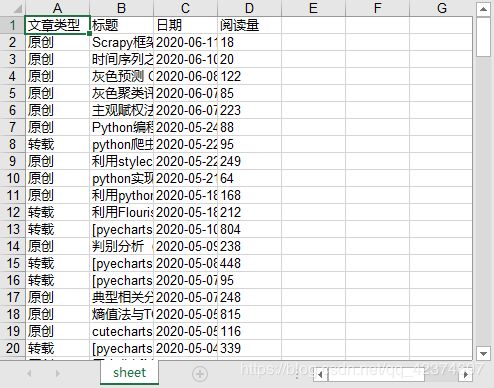
type_ = div.xpath('./h4/a/span/text()')[0]
title = div.xpath('./h4/a/text()')[1].strip()
date = div.xpath('.//span[@class="date"]/text()')[0].strip()
read_num = div.xpath('.//span[@class="read-num"]/text()')[0]
item = {}
item['文章类型'] = type_
item['标题'] = title
item['日期'] = date
item['阅读量'] = read_num
info_list.append(item)
filename = 'C:/爬取数据.xls'
import xlwt
import os
import xlrd
from xlutils.copy import copy
class ExcelUtils(object):
#工具类的方法:不适用外部变量
#静态方法:直接可以用类名.方法名来调用
# @staticmethod
#类变量:
#实例变量
#类方法
@staticmethod
def write_to_excel(filename,sheetname,word_list):
'''
写入excel
:param filename: 文件名
:param sheetname: 表单名
:param word_list: [item,item,{}]
:return:
'''
try:
# 创建workbook
workbook = xlwt.Workbook(encoding='utf-8')
# 给工作表添加sheet表单
sheet = workbook.add_sheet(sheetname)
# 设置表头
head = []
for i in word_list[0].keys():
head.append(i)
# print(head)
# 将表头写入excel
for i in range(len(head)):
sheet.write(0, i, head[i])
# 写内容
i = 1
for item in word_list:
for j in range(len(head)):
sheet.write(i, j, item[head[j]])
i += 1
# 保存
workbook.save(filename)
print('写入excle成功!')
except Exception as e:
print(e)
print('写入失败!')
@staticmethod
def write_to_excel_append(filename,infos):
'''
追加excel的方法
:param filename: 文件名
:param infos: 【item,item】
:return:
'''
#打开excle文件
work_book = xlrd.open_workbook(filename)
#获取工作表中的所有sheet表单名称
sheets = work_book.sheet_names()
#获取第一个表单
work_sheet = work_book.sheet_by_name(sheets[0])
#获取已经写入的行数
old_rows = work_sheet.nrows
#获取表头的所有字段
keys = work_sheet.row_values(0)
print('===================',keys)
#将xlrd对象转化成xlwt,为了写入
new_work_book = copy(work_book)
#获取表单来添加数据
new_sheet = new_work_book.get_sheet(0)
i = old_rows
for item in infos:
for j in range(len(keys)):
new_sheet.write(i, j, item[keys[j]])
i += 1
new_work_book.save(filename)
print('追加成功!')
if os.path.exists(filename):
#如果文件存在就追加
ExcelUtils.write_to_excel_append(filename,info_list)
else:
#不存在就新建
ExcelUtils.write_to_excel(filename,'sheet',info_list)
多线程
from selenium import webdriver
from lxml import etree
import threading
import os
from queue import Queue
import xlwt
import xlrd
from xlutils.copy import copy
class ExcelUtils(object):
#工具类的方法:不适用外部变量
#静态方法:直接可以用类名.方法名来调用
# @staticmethod
#类变量:
#实例变量
#类方法
@staticmethod
def write_to_excel(filename,sheetname,word_list):
'''
写入excel
:param filename: 文件名
:param sheetname: 表单名
:param word_list: [item,item,{}]
:return:
'''
try:
# 创建workbook
workbook = xlwt.Workbook(encoding='utf-8')
# 给工作表添加sheet表单
sheet = workbook.add_sheet(sheetname)
# 设置表头
head = []
for i in word_list[0].keys():
head.append(i)
# print(head)
# 将表头写入excel
for i in range(len(head)):
sheet.write(0, i, head[i])
# 写内容
i = 1
for item in word_list:
for j in range(len(head)):
sheet.write(i, j, item[head[j]])
i += 1
# 保存
workbook.save(filename)
print('写入excle成功!')
except Exception as e:
print(e)
print('写入失败!')
@staticmethod
def write_to_excel_append(filename,infos):
'''
追加excel的方法
:param filename: 文件名
:param infos: 【item,item】
:return:
'''
#打开excle文件
work_book = xlrd.open_workbook(filename)
#获取工作表中的所有sheet表单名称
sheets = work_book.sheet_names()
#获取第一个表单
work_sheet = work_book.sheet_by_name(sheets[0])
#获取已经写入的行数
old_rows = work_sheet.nrows
#获取表头的所有字段
keys = work_sheet.row_values(0)
print('===================',keys)
#将xlrd对象转化成xlwt,为了写入
new_work_book = copy(work_book)
#获取表单来添加数据
new_sheet = new_work_book.get_sheet(0)
i = old_rows
for item in infos:
for j in range(len(keys)):
new_sheet.write(i, j, item[keys[j]])
i += 1
new_work_book.save(filename)
print('追加成功!')
class SPIDER(threading.Thread):
def __init__(self,url,queue_page,name,filename):
super().__init__() #调用父类的init方法
self.url=url
self.queue_page=queue_page
self.name=name
self.filename=filename
def run(self):
while True:
# 一定要先做跳出循环的条件准备
if self.queue_page.empty(): #如果队列中页码为空了,就跳出循环
break
#取页码
page = self.queue_page.get() #出队操作
#请求+解析
self.parse_page(page)
def parse_page(self,page):
driver = webdriver.PhantomJS() #创建一个驱动
driver.get(self.url.format(page))
html = etree.HTML(driver.page_source)
info_list=[]
ii_list = html.xpath('//div[@class="article-item-box csdn-tracking-statistics"]')
for ii in ii_list:
try:
##提取
type_ = ii.xpath('./h4/a/span/text()')[0]
title = ii.xpath('./h4/a/text()')[1].strip()
date = ii.xpath('.//span[@class="date"]/text()')[0].strip()
read_num = ii.xpath('.//span[@class="read-num"]/text()')[0]
#获取到的信息放入字典
item = {}
item['文章类型'] = type_
item['标题'] = title
item['日期'] = date
item['阅读量'] = read_num
info_list.append(item)
except Exception:
pass
# 保存
if os.path.exists(self.filename):
#如果文件存在就追加
ExcelUtils.write_to_excel_append(self.filename,info_list)
else:
#不存在就新建
ExcelUtils.write_to_excel(self.filename,'sheet1',info_list)
if __name__ == '__main__':
#基础url
base_url = 'https://blog.csdn.net/qq_42374697/article/list/{}'
#第一步:创建任务队列并初始化
queue_page = Queue()
# 找页码变化的规律
for i in range(1,3):
queue_page.put(i) #入队操作 就是 0,1,2,3,4,...,9 页码
name_list = ['a','b','c','d','e']
thread_list = []
for i in name_list:
#创建线程
#queue_page:将创建好的队列传进去
#传线程名称
t = SPIDER(base_url,queue_page,i,'C:/爬取数据.xls')
t.start()
thread_list.append(t)
for t in thread_list:
t.join()
