第十四章 数据分析示例
注:本章示例数据集可在附带的GitHub仓库(http://github.com/wesm/pydata-book)中找到
14.3 美国1880~2010年的婴儿名字
美国社会保障局(SSA)提供了从1880年至现在的婴儿姓名频率的数据。Hadley Wickham是一些流行R包的作者,他经常利用这个数据集来说明R中的数据操作。
1.我们需要做一些数据规整来加载这个数据集,但一旦我们这样做,我们将得到一个看起来如下的DataFrame:
In [4]: names.head(10)
Out[4]:
name sex births year
0 Mary F 7065 1880
1 Anna F 2604 1880
2 Emma F 2003 1880
3 Elizabeth F 1939 1880
4 Minnie F 1746 1880
5 Margaret F 1578 1880
6 Ida F 1472 1880
7 Alice F 1414 1880
8 Bertha F 1320 1880
9 Sarah F 1288 1880
你可能想要对数据集做很多事情:
· 根据给定的名字(可以是你自己的,或另一个名字)对婴儿名字随时间的比例进行可视化
· 确定一个名字的相对排位
· 确定每年最受欢迎的名字,或者流行程度最高或最低的名字
· 分析名字趋势:元音、辅音、长度、整体多样性、拼写变化、第一个和最后一个字母
· 分析额外的趋势来源:圣经中的名字,名人,人口变化
通过本书中的工具,许多这些分析都可以实现,所以我会引导你了解其中的一部分。
截至撰写本书时,美国社会保障局每年提供一份数据文件,其中包含每个性别/姓名组合的出生总数。这些文件的原始档案可以从http://www.ssa.gov/oact/babynames/limits. html获得。
如果你在阅读本书时,上面的网页被移动了,你可以再次通过互联网搜索找到该页面。下载“国家数据”文件names.zip并解压缩,你将拥有一个包含一系列文件(如yob1880. txt)的目录。
1.可以使用Unix head命令查看其中一个文件的前10行(在Windows上,可以使用more命令或在文本编辑器中打开它):
In [94]: ! head -n 10 datasets/babynames/yob1880.txt
Mary, F,7065
Anna, F,2604
Emma, F,2003
Elizabeth, F,1939
Minnie, F,1746
Margaret, F,1578
Ida, F,1472
Alice, F,1414
Bertha, F,1320
Sarah, F,1288
2.使用pandas.read_csv将其加载到DataFrame中(见图14-1)

3.使用pandas.concat将所有数据集中到一个DataFrame中,然后再添加一个年份字段。(见图14-2)
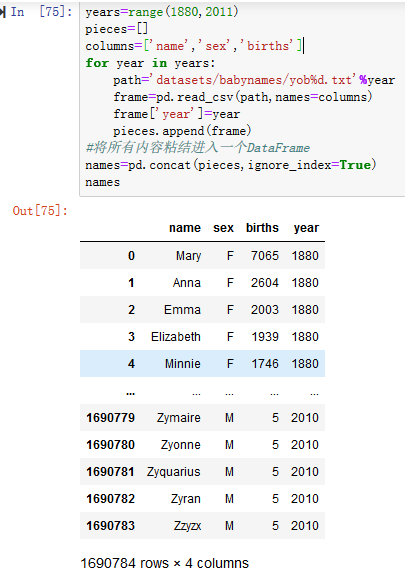
注:concat默认情况下将DataFrame对象以逐行方式黏合在一起。
其次,必须传递ignore_index = True,否则将会保留从read_csv返回的原始行号。
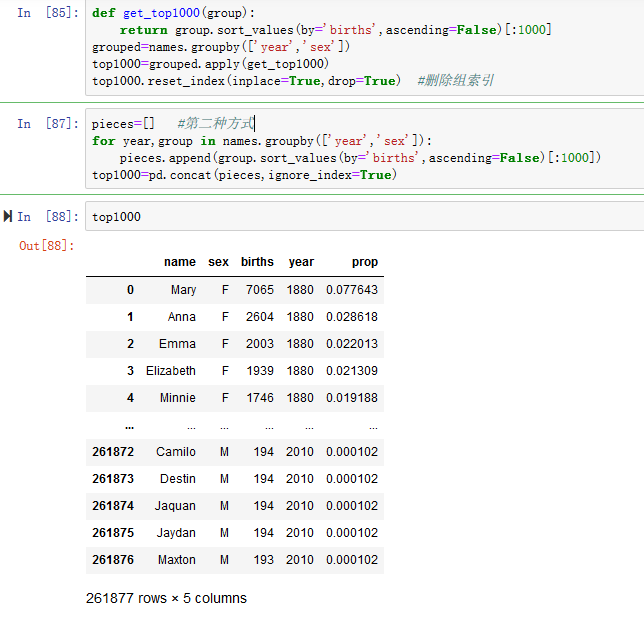
names是一个非常大的包含所有名字数据的DataFrame
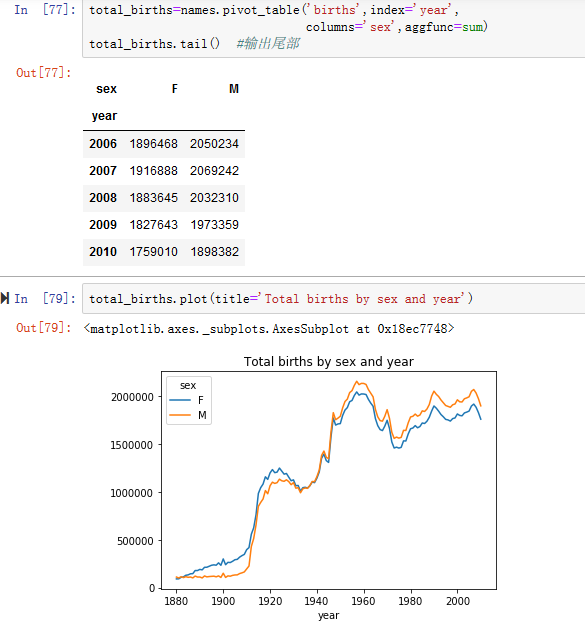
4.使用groupby或pivot_table开始聚合年份和性别的数据(见图14-4)
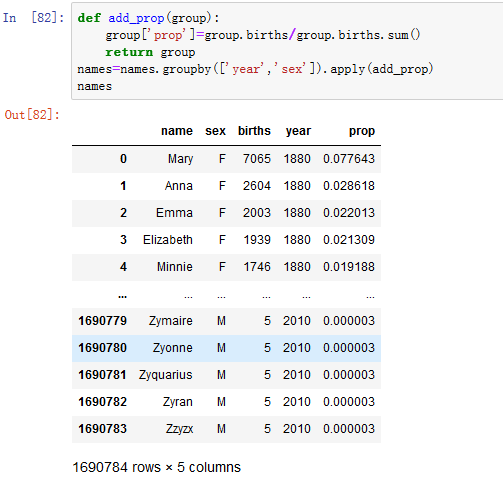
5.插入一个prop列,给出每个婴儿名字相对于出生总数的比例。
prop值为0.02表示每100个婴儿中有2个起了某个名字,按年份和性别对数据进行分组,然后将新列添加到每个组(见图14-5)
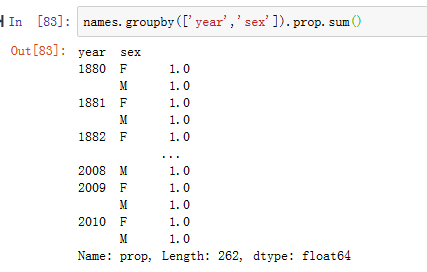
在执行此类组操作时,进行完整性检查通常很有价值,例如验证所有组中的prop列总计为1(见图14-6)
6.提取一部分数据以便于进一步分析:每个性别/年份组合的前1,000名(见图14-7)
14.3.1 分析名字趋势
利用完整的数据集和手上的Top 1,000数据集,我们可以开始分析各种感兴趣的命名趋势。
1.首先,将Top 1,000的名字分成男孩和女孩两部分是很容易实现的(见图14-8)

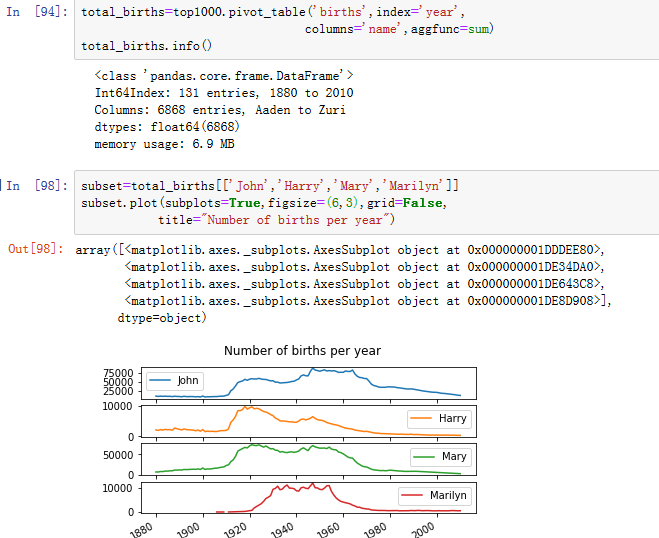
2.简单的时间序列,比如每年的John或Marry的数量,都可以绘制出来,但是需要一些处理才能更有用。让我们按年份和名字形成出生总数的数据透视表(见图14-9)
14.3.1.1 计量命名多样性的增加
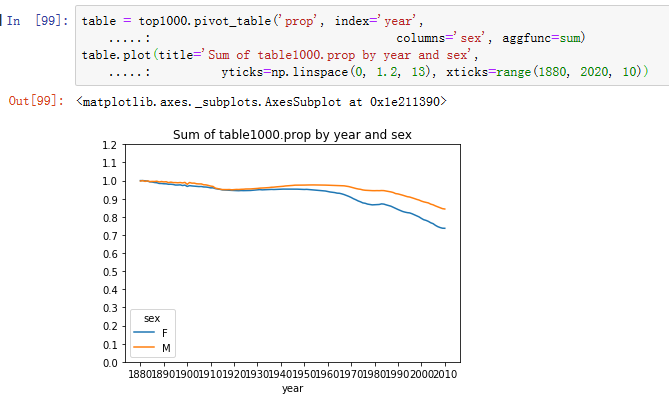
对上一节中趋势下降的一个解释是,越来越多的父母为他们的孩子选择常用名字。这个假设可以在数据中进行探索和确认。其中一个衡量指标是Top 1,000最受欢迎的名字所涵盖婴儿的出生比例
1.按照年份和性别进行聚合和绘图(图14-10显示了结果图)
2.第二项指标
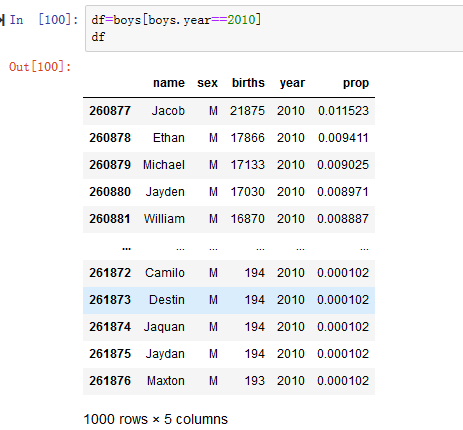
事实上似乎有越来越多的名字多样性(Top 1,000名字的总比例的降低)。另一个有趣的指标是不同名字的数量,按最高到最低的受欢迎程度在出生人数最高的50%的名字中排序。这个数字计算起来有点棘手。让我们考虑一下2010年的男孩名字(见图14-11)
按降序排列prop后,我们想知道有多少名字是最受欢迎的那50 %。你可以写一个for循环来实现这一点,但矢量化的NumPy方式更聪明一些。获取prop的累积总和cumsum,然后调用searchsorted方法返回累积总和中的位置,在该处需要插入0.5以保持排序顺序(见图14-12)
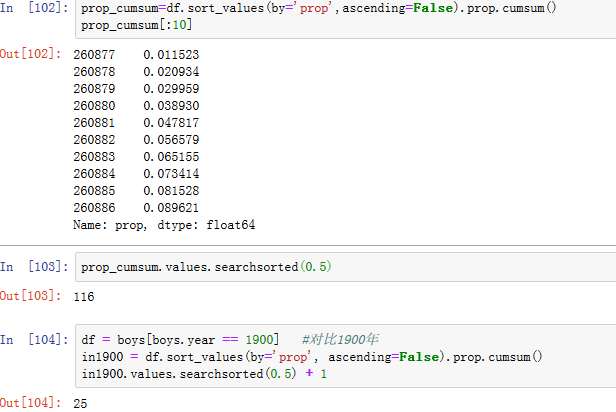
将此操作应用于每个年/性别分组,通过这些字段进行groupby,并将返回值是每个分组计数值的函数apply到每个分组上,产生的DataFrame diversity现在有两个时间序列,每个时间序列对应一种性别,并按照年份索引。diversity像之前一样可以在IPython中被检查并绘制(见图14-13)
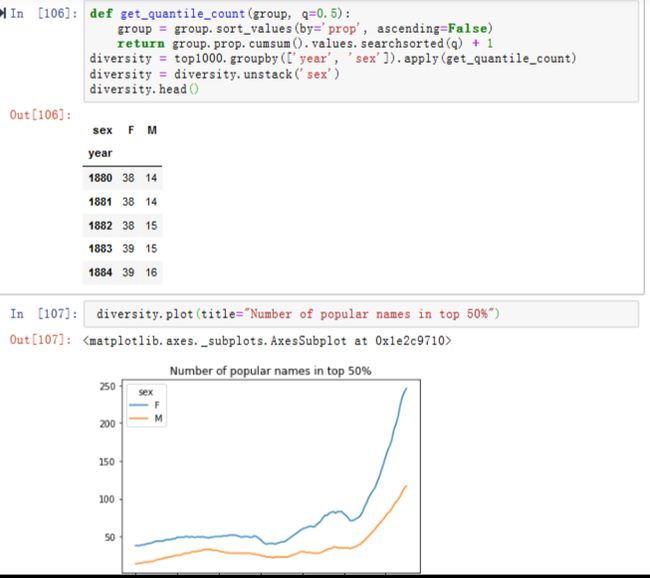
正如所看到的,女孩的名字一直比男孩的名字更加多样化,而且随着时间的推移它们变得越来越多。
14.3.1.2 “最后一个字母”革命
2007年,婴儿名字研究员Laura Wattenberg在她的网站(http://www.babynamewizard.com)上指出,男孩名字最后一个字母的分布在过去的一百年里发生了重大变化。
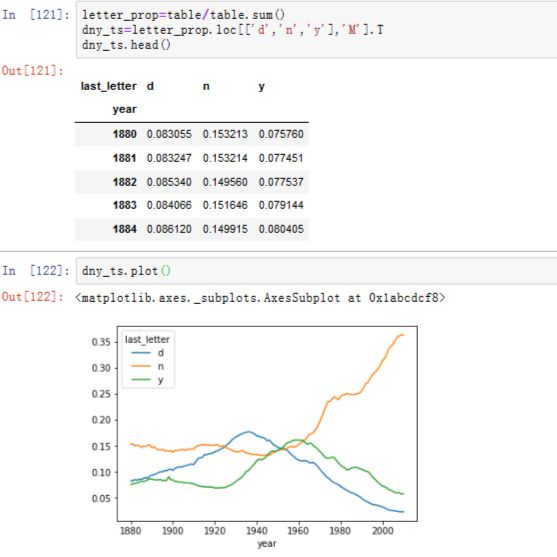
1.首先按照年份、性别和最后一个字母汇总完整数据集中的所有出生情况(见图14-14)

2.按照出生总数对表格进行归一化处理,计算一个新表格,其中包含每个性别的每个结束字母占总出生数的比例(见图14-15)
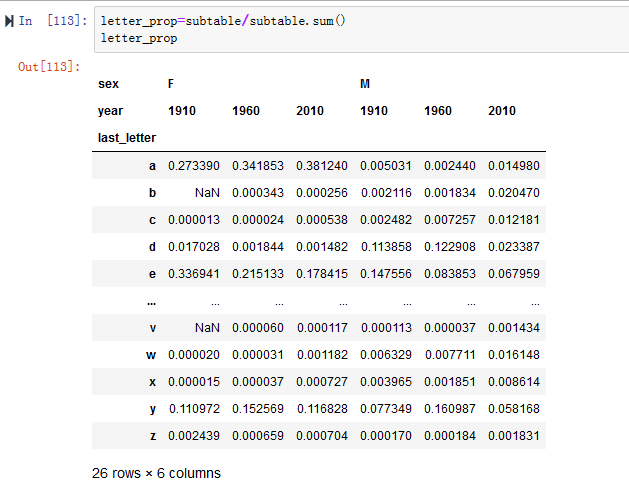
3.根据掌握的字母比例,我们可以绘制出按年划分的每个性别的条形图(见图14-16)
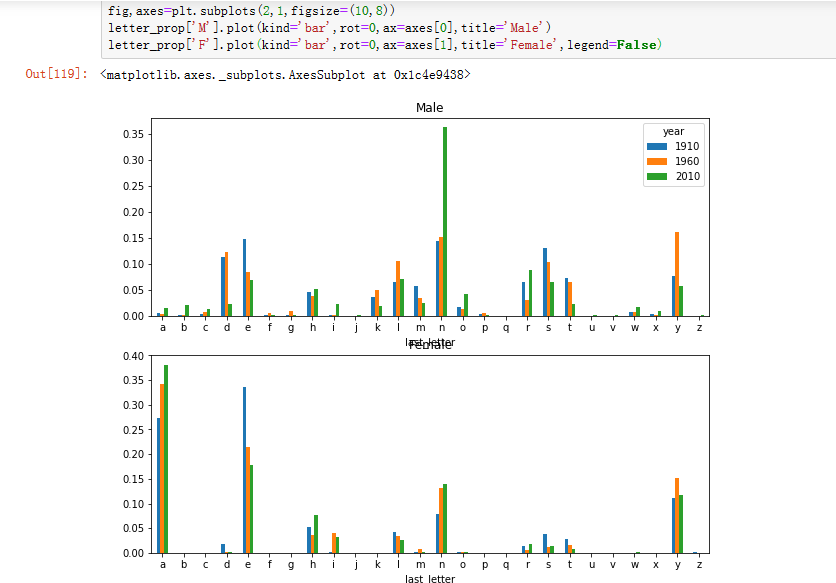
如图所见,自20世纪60年代以来,以n结尾的男孩名字经历了显著的增长。
4.再次按年份和性别进行标准化,并为男孩名字选择一个字母子集,最后转换为使每列成为一个时间序列(见图14-17)
14.3.1.3 男孩名字变成女孩名字(以及反向)
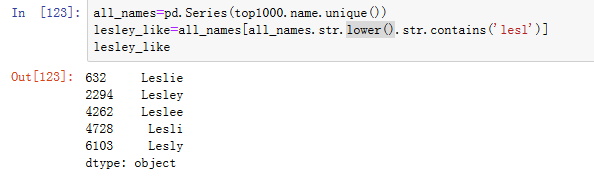
另一个有趣的趋势是看到样本中较早在男性中流行的男孩名字,但现在已经“改变了性别”。一个例子是Lesley或Leslie的名字。
1.回到top1000的DataFrame,我计算数据集中以“lesl”开头的名字列表(见图14-18)
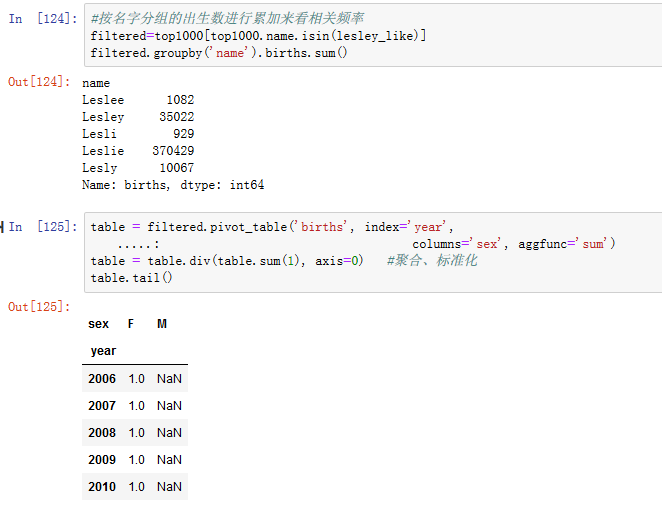
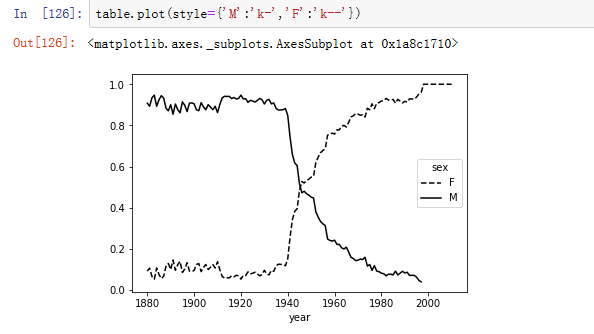
2.标准化、绘图(见图14-18、14-19)
注:(1)DataFrame.loc
Access a group of rows and columns by label(s) or a boolean array..loc[]is primarily label based, but may also be used with aboolean array.
(2)Series.str.contains(pat,case=True,flags=0,na=nan,regex=True)
Test if pattern or regex is contained within a string of a Series or Index.Return boolean Series or Index based on whether a given pattern or regex iscontained within a string of a Series or Index.
(3)Series.str.lower()
Convert strings in the Series/Index to lowercase.Equivalent tostr.lower().