初学深度学习(二):搭建多层感知器识别手写字符集
初学深度学习(二):搭建多层感知器识别手写字符集
写在前面
这些博客是我的一些学习心得,如果有什么改进的地方,记得留言,另外, 我写的每一篇博客有参阅一些网上教程和书籍,书籍如下:
- 《Deep Learning with Keras》—— Antonio Gulli
- 《TensorFlow+Keras》深度学习人工智实践应用 林大贵著
1. 构建项目
本章需要继续上一篇初学深度学习(一):初试Keras与多层感知机的搭建所搭建的环境和部分代码。首先先创建文件夹:
dlwork) jingyudeMacBook-Pro:~ jingyuyan$ mkdir project01
创建成功后,在dlwork环境下,进入到project02目录下,打开jupyter notebook:
cd project01
jupyter notebook
2. 搭建多层感知机模型
2.1 搭建带有隐藏层的多层感知机模型
这边我们回顾和整理上一篇所搭建的多层感知机模型,并且运行代码,训练模型。
# 导包
import numpy as np
from keras.utils import np_utils
from keras.datasets import mnist
import pandas as pd
import matplotlib.pyplot as plt
from keras.models import Sequential
from keras.layers import Dense,Dropout,Flatten,Conv2D,MaxPooling2D,Activation
# 加载数据集
(X_train_image,y_train_label),(X_test_image,y_test_label) = mnist.load_data()
# 图像转换成向量的处理
X_Train = X_train_image.reshape(60000, 28*28).astype('float32')
X_Test = X_test_image.reshape(10000, 28*28).astype('float32')
# 图像归一化处理
X_Train_normalize = X_Train / 255
X_Test_normalize = X_Test / 255
# 标签one-hot编码处理
y_TrainOneHot = np_utils.to_categorical(y_train_label)
y_TestOneHot = np_utils.to_categorical(y_test_label)
# 设置模型参数和训练参数
# 分类的类别
CLASSES_NB = 10
# 模型输入层数量
INPUT_SHAPE = 28 * 28
# 隐藏层数量
UNITS = 256
# 验证集划分比例
VALIDATION_SPLIT = 0.2
# 训练周期,这边设置10个周期即可
EPOCH = 10
# 单批次数据量
BATCH_SIZE = 300
# 训练LOG打印形式
VERBOSE = 2
# 建立Sequential模型
model = Sequential()
# 添加一个Dense,Deense的特点是上下层的网络均连接
# 该Dense层包含输入层和隐藏层
model.add(Dense(units=UNITS,
input_dim=INPUT_SHAPE,
kernel_initializer='normal',
activation='relu'))
# 定义输出层,使用softmax将0到9的十个数字的结果通过概率的形式进行激活转换
model.add(Dense(CLASSES_NB, activation='softmax'))
# 搭建完成后输出模型摘要
model.summary()
Using TensorFlow backend.
WARNING:tensorflow:From /Users/jingyuyan/anaconda3/envs/dlwork/lib/python3.6/site-packages/tensorflow/python/framework/op_def_library.py:263: colocate_with (from tensorflow.python.framework.ops) is deprecated and will be removed in a future version.
Instructions for updating:
Colocations handled automatically by placer.
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
dense_1 (Dense) (None, 256) 200960
_________________________________________________________________
dense_2 (Dense) (None, 10) 2570
=================================================================
Total params: 203,530
Trainable params: 203,530
Non-trainable params: 0
_________________________________________________________________
搭建好模型后下一步是训练模型
# 设置训练参数
model.compile(loss='categorical_crossentropy',optimizer='adam',metrics=['accuracy'])
# 传入数据,开始训练
# verbose为表示显示打印的训练过程
train_history = model.fit(
x=X_Train_normalize,
y=y_TrainOneHot,
epochs=EPOCH,
batch_size=BATCH_SIZE,
verbose=VERBOSE,
validation_split=VALIDATION_SPLIT)
WARNING:tensorflow:From /Users/jingyuyan/anaconda3/envs/dlwork/lib/python3.6/site-packages/tensorflow/python/ops/math_ops.py:3066: to_int32 (from tensorflow.python.ops.math_ops) is deprecated and will be removed in a future version.
Instructions for updating:
Use tf.cast instead.
Train on 48000 samples, validate on 12000 samples
Epoch 1/10
- 2s - loss: 0.4479 - acc: 0.8771 - val_loss: 0.2250 - val_acc: 0.9405
Epoch 2/10
- 1s - loss: 0.1975 - acc: 0.9441 - val_loss: 0.1699 - val_acc: 0.9542
Epoch 3/10
- 1s - loss: 0.1431 - acc: 0.9593 - val_loss: 0.1383 - val_acc: 0.9616
Epoch 4/10
- 2s - loss: 0.1104 - acc: 0.9690 - val_loss: 0.1187 - val_acc: 0.9659
Epoch 5/10
- 1s - loss: 0.0893 - acc: 0.9752 - val_loss: 0.1044 - val_acc: 0.9696
Epoch 6/10
- 2s - loss: 0.0743 - acc: 0.9799 - val_loss: 0.0988 - val_acc: 0.9704
Epoch 7/10
- 1s - loss: 0.0618 - acc: 0.9834 - val_loss: 0.0916 - val_acc: 0.9729
Epoch 8/10
- 1s - loss: 0.0517 - acc: 0.9865 - val_loss: 0.0919 - val_acc: 0.9722
Epoch 9/10
- 1s - loss: 0.0439 - acc: 0.9889 - val_loss: 0.0891 - val_acc: 0.9738
Epoch 10/10
- 1s - loss: 0.0381 - acc: 0.9905 - val_loss: 0.0858 - val_acc: 0.9743
创建show_train_history函数,尝试绘制出训练准确率和训练误差率图像。
def show_train_history(train_history,train,validation):
plt.plot(train_history.history[train])
plt.plot(train_history.history[validation])
plt.title('Train histoty')
plt.ylabel(train)
plt.xlabel('Epoch')
plt.legend(['train','validation',],loc = 'upper left')
plt.show()
show_train_history(train_history,'acc','val_acc')
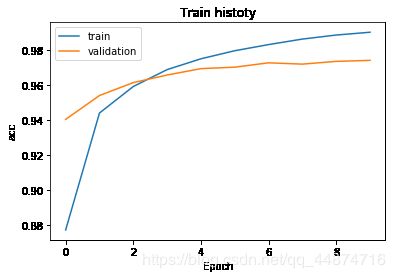
show_train_history(train_history,'loss','val_loss')

由图片绘制的结果可得,上一章节所搭建的多层感知机模型所训练的过程来看,训练的后期,在训练集合与验证集的训练结果出现了一点问题。
可以发现在准确率图中,训练集准确率(蓝线)在后期是大于验证集准去率(橙线)的,这便表示出现了过拟合的情况。
3. 误差说明与过拟合问题
3.1 训练误差与泛化误差
训练误差(training error)与泛化误差(generalization error)通俗的来讲,训练误差是指在训练模型的过程中,使用的训练数据上所呈现的误差,泛化误差则表示模型在任意一个不参与到训练过程中的测试集数据上所呈现的误差。
我们采用以学生上课和参加考试为例子,直观的描述这两种误差有何区别。首先,训练误差可以将其看作是学生在平时上课时所学习内容和知识掌握程度的误率。好比你让一个上3年级的学生去做6年级的学生的期末试卷,那显然错误率会非常高,因为1年级的小朋友并没有学过比自己更高年级的课程,在知识的掌握程度上,便有了比较高的误差。泛化误差可以将其看作是学生的升学考试,通常升学考试所出现知识点和学生平时所学习时所训练的知识想通,但是题目却和平时所练习的习题有有所不相同,学生往往需要通过平时学习下所积攒的知识去面对不同的考题所带来的问题。
训练误差和泛化误差之间的关系,拿高三的学生作为举例,就好比学生的平时成绩和高考成绩。假设有一名学生,他平时可能在做过非常多的练习题和真题卷,并且成绩较为理想,但是高考成绩却远远不如平时练习的成绩。这就是一个泛化误差大于训练误差的一个场景,说明该考生只会做练习题,遇到新的题目成绩便不理想。如果有一位学生,平时做真题时成绩优异,并且高考时也发挥了自己的水平,成绩和平时一样优秀,那训练误差和泛化误差便相对的缩小,这是一个较为理想的场景。
3.2 过拟合问题
在机器学习中,我们把训练集比作模型的练习题,把验证集比作模型的自测题,把测试集比作模型的正式的考试题。验证集通常用于模型调超参数,监控模型是否发生过拟合(以决定是否停止训练),就好比一个学生每次做完一小节的练习题后都能把题目做对,于是学生会寻找没有做过的新题目,来尝试自己是否在练习完当一小节的题目后掌握了该小节的知识点,如果掌握程度较低,那就表示该生在学习时出现了问题,通过这项测试可以尽快找出问题,并且解决问题,否则到了期末考试,后果不堪设想。机器学习中把这种情况定义为过拟合,表示训练集在训练过程中取得的成绩大于验证集所取得的成绩。这就说明训练集准确率高并不代表着模型精度越好,在机器学习的过程中也应该关注如何降低泛化误差的问题。
如下图所示,如果用一条线分割蓝色的球与红色的球的话,那么黑色的线是一个比较理想的结果,而绿色的线则是过拟合的结果。
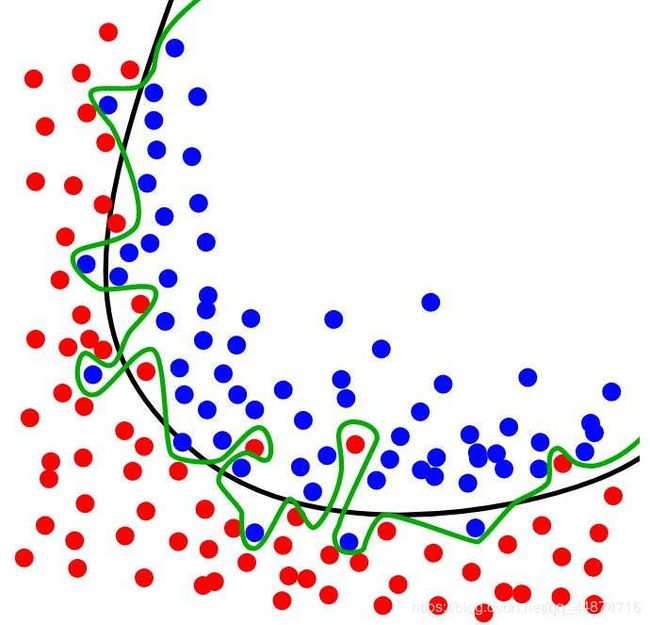
4. 处理模型过拟合问题
4.1 增加隐藏层神经元查看过拟合情况
为了更加直观的提现过拟合问题,我们修改已经搭建好的多层感知器模型的参数。这边将原本256个隐藏层的神经元修改到1000个后,查看模型摘要,可以看到模型的参数比原来的参数增加了不少。
# 设置模型参数和训练参数
# 分类的类别
CLASSES_NB = 10
# 模型输入层数量
INPUT_SHAPE = 28 * 28
# 隐藏层数量修改为1000个神经元
UNITS = 1000
# 验证集划分比例
VALIDATION_SPLIT = 0.2
# 训练周期,这边设置10个周期即可
EPOCH = 10
# 单批次数据量
BATCH_SIZE = 300
# 训练LOG打印形式
VERBOSE = 2
# 建立模型
model = Sequential()
# 添加一个Dense,Deense的特点是上下层的网络均连接
# 该Dense层包含输入层和隐藏层
model.add(Dense(units=UNITS,
input_dim=INPUT_SHAPE,
kernel_initializer='normal',
activation='relu'))
# 定义输出层,使用softmax将0到9的十个数字的结果通过概率的形式进行激活转换
model.add(Dense(CLASSES_NB, activation='softmax'))
# 搭建完成后输出模型摘要
model.summary()
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
dense_3 (Dense) (None, 1000) 785000
_________________________________________________________________
dense_4 (Dense) (None, 10) 10010
=================================================================
Total params: 795,010
Trainable params: 795,010
Non-trainable params: 0
_________________________________________________________________
# 设置训练参数
model.compile(loss='categorical_crossentropy',optimizer='adam',metrics=['accuracy'])
# 传入数据,开始训练
# verbose为表示显示打印的训练过程
train_history = model.fit(
x=X_Train_normalize,
y=y_TrainOneHot,
epochs=EPOCH,
batch_size=BATCH_SIZE,
verbose=VERBOSE,
validation_split=VALIDATION_SPLIT)
Train on 48000 samples, validate on 12000 samples
Epoch 1/10
- 4s - loss: 0.3439 - acc: 0.9024 - val_loss: 0.1677 - val_acc: 0.9540
Epoch 2/10
- 4s - loss: 0.1398 - acc: 0.9598 - val_loss: 0.1259 - val_acc: 0.9632
Epoch 3/10
- 5s - loss: 0.0910 - acc: 0.9744 - val_loss: 0.0971 - val_acc: 0.9709
Epoch 4/10
- 3s - loss: 0.0633 - acc: 0.9827 - val_loss: 0.0856 - val_acc: 0.9740
Epoch 5/10
- 3s - loss: 0.0482 - acc: 0.9868 - val_loss: 0.0836 - val_acc: 0.9743
Epoch 6/10
- 3s - loss: 0.0348 - acc: 0.9910 - val_loss: 0.0770 - val_acc: 0.9768
Epoch 7/10
- 3s - loss: 0.0257 - acc: 0.9941 - val_loss: 0.0728 - val_acc: 0.9780
Epoch 8/10
- 4s - loss: 0.0196 - acc: 0.9960 - val_loss: 0.0800 - val_acc: 0.9752
Epoch 9/10
- 3s - loss: 0.0149 - acc: 0.9971 - val_loss: 0.0727 - val_acc: 0.9775
Epoch 10/10
- 3s - loss: 0.0123 - acc: 0.9980 - val_loss: 0.0697 - val_acc: 0.9791
show_train_history(train_history,'acc','val_acc')
show_train_history(train_history,'loss','val_loss')
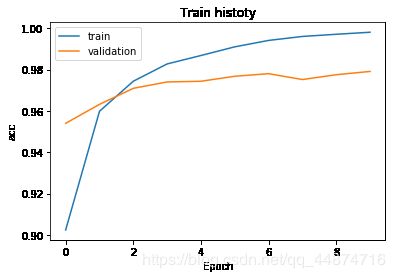
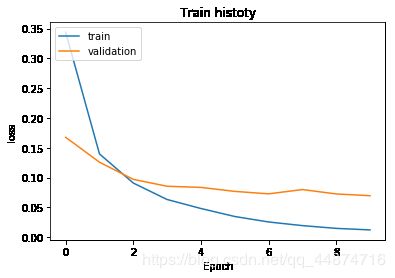
可以看到,在修改了1000个神经元后,过拟合的现象更加严重了。
4.1 加入Dropout功能来处理过拟合问题
# 将Dropout模块导入
from keras.layers import Dropout
# 建立模型
model = Sequential()
# 添加一个Dense,Deense的特点是上下层的网络均连接
# 该Dense层包含输入层和隐藏层
model.add(Dense(units=UNITS,
input_dim=INPUT_SHAPE,
kernel_initializer='normal',
activation='relu'))
# 在隐藏层和输出层之间加入Dropout层,参数0.5表示随机丢弃50%的神经元
model.add(Dropout(0.5))
# 定义输出层,使用softmax将0到9的十个数字的结果通过概率的形式进行激活转换
model.add(Dense(CLASSES_NB, activation='softmax'))
# 搭建完成后输出模型摘要
model.summary()
WARNING:tensorflow:From /Users/jingyuyan/anaconda3/envs/dlwork/lib/python3.6/site-packages/keras/backend/tensorflow_backend.py:3445: calling dropout (from tensorflow.python.ops.nn_ops) with keep_prob is deprecated and will be removed in a future version.
Instructions for updating:
Please use `rate` instead of `keep_prob`. Rate should be set to `rate = 1 - keep_prob`.
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
dense_5 (Dense) (None, 1000) 785000
_________________________________________________________________
dropout_1 (Dropout) (None, 1000) 0
_________________________________________________________________
dense_6 (Dense) (None, 10) 10010
=================================================================
Total params: 795,010
Trainable params: 795,010
Non-trainable params: 0
_________________________________________________________________
搭建好带有Dropout层的模型后,进行训练,仔细观察训练过程中的日志与之前的日志有何不同。
# 设置训练参数
model.compile(loss='categorical_crossentropy',optimizer='adam',metrics=['accuracy'])
# 传入数据,开始训练
# verbose为表示显示打印的训练过程
train_history = model.fit(
x=X_Train_normalize,
y=y_TrainOneHot,
epochs=EPOCH,
batch_size=BATCH_SIZE,
verbose=VERBOSE,
validation_split=VALIDATION_SPLIT)
Train on 48000 samples, validate on 12000 samples
Epoch 1/10
- 4s - loss: 0.3955 - acc: 0.8831 - val_loss: 0.1777 - val_acc: 0.9513
Epoch 2/10
- 4s - loss: 0.1759 - acc: 0.9492 - val_loss: 0.1275 - val_acc: 0.9630
Epoch 3/10
- 4s - loss: 0.1286 - acc: 0.9633 - val_loss: 0.1081 - val_acc: 0.9677
Epoch 4/10
- 4s - loss: 0.1019 - acc: 0.9702 - val_loss: 0.0933 - val_acc: 0.9723
Epoch 5/10
- 4s - loss: 0.0831 - acc: 0.9754 - val_loss: 0.0903 - val_acc: 0.9716
Epoch 6/10
- 4s - loss: 0.0699 - acc: 0.9787 - val_loss: 0.0801 - val_acc: 0.9771
Epoch 7/10
- 4s - loss: 0.0610 - acc: 0.9817 - val_loss: 0.0738 - val_acc: 0.9783
Epoch 8/10
- 4s - loss: 0.0533 - acc: 0.9843 - val_loss: 0.0741 - val_acc: 0.9785
Epoch 9/10
- 5s - loss: 0.0458 - acc: 0.9860 - val_loss: 0.0698 - val_acc: 0.9785
Epoch 10/10
- 4s - loss: 0.0414 - acc: 0.9872 - val_loss: 0.0702 - val_acc: 0.9797
通过训练日志可以看到,无论是训练误差和验证误差或者训练准去率或者验证准去率,都是不断的在接近,表示两种误差在不断的缩小。
画出训练过程的图片,可以看到,在后期两条曲的误差逐渐缩短。
show_train_history(train_history,'acc','val_acc')
show_train_history(train_history,'loss','val_loss')
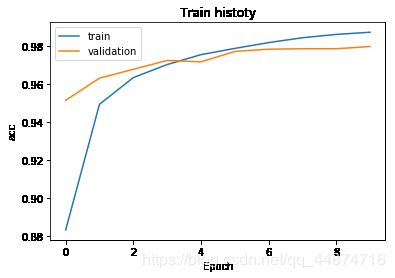
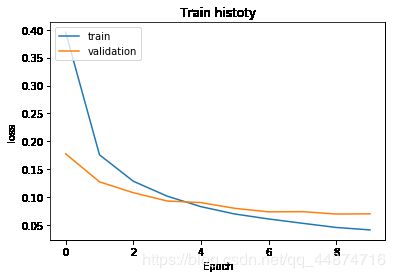
4.2 建立两个隐藏层的多层感知器模型
我们尝试再建立一层隐藏层,提升模型准确率的同时观察模型的泛化能力。
# 建立模型
model = Sequential()
加入隐藏层1
# 建立隐藏层 - 1
model.add(Dense(units=UNITS,
input_dim=INPUT_SHAPE,
kernel_initializer='normal',
activation='relu'))
# 在隐藏层1和隐藏层2之间加入Dropout层,参数0.5表示随机丢弃50%的神经元
model.add(Dropout(0.5))
加入隐藏层2
# 建立隐藏层 - 2
model.add(Dense(units=UNITS,
kernel_initializer='normal',
activation='relu'))
# 在隐藏层2和输出层之间加入Dropout层,参数0.5表示随机丢弃50%的神经元
model.add(Dropout(0.5))
加入输出层
# 添加输出层
model.add(Dense(CLASSES_NB, activation='softmax'))
# 搭建完成后输出模型摘要
model.summary()
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
dense_7 (Dense) (None, 1000) 785000
_________________________________________________________________
dropout_2 (Dropout) (None, 1000) 0
_________________________________________________________________
dense_8 (Dense) (None, 1000) 1001000
_________________________________________________________________
dropout_3 (Dropout) (None, 1000) 0
_________________________________________________________________
dense_9 (Dense) (None, 10) 10010
=================================================================
Total params: 1,796,010
Trainable params: 1,796,010
Non-trainable params: 0
_________________________________________________________________
训练模型,并且绘制出训练过程的图像
# 设置训练参数
model.compile(loss='categorical_crossentropy',optimizer='adam',metrics=['accuracy'])
# 传入数据,开始训练
# 参数引用上面定义好的参数
train_history = model.fit(
x=X_Train_normalize,
y=y_TrainOneHot,
epochs=EPOCH,
batch_size=BATCH_SIZE,
verbose=VERBOSE,
validation_split=VALIDATION_SPLIT)
Train on 48000 samples, validate on 12000 samples
Epoch 1/10
- 11s - loss: 0.4019 - acc: 0.8746 - val_loss: 0.1414 - val_acc: 0.9584
Epoch 2/10
- 10s - loss: 0.1680 - acc: 0.9489 - val_loss: 0.1042 - val_acc: 0.9676
Epoch 3/10
- 10s - loss: 0.1235 - acc: 0.9611 - val_loss: 0.0917 - val_acc: 0.9720
Epoch 4/10
- 10s - loss: 0.0984 - acc: 0.9688 - val_loss: 0.0852 - val_acc: 0.9746
Epoch 5/10
- 10s - loss: 0.0825 - acc: 0.9743 - val_loss: 0.0797 - val_acc: 0.9768
Epoch 6/10
- 9s - loss: 0.0725 - acc: 0.9772 - val_loss: 0.0746 - val_acc: 0.9771
Epoch 7/10
- 9s - loss: 0.0640 - acc: 0.9794 - val_loss: 0.0731 - val_acc: 0.9794
Epoch 8/10
- 9s - loss: 0.0559 - acc: 0.9813 - val_loss: 0.0774 - val_acc: 0.9778
Epoch 9/10
- 9s - loss: 0.0544 - acc: 0.9823 - val_loss: 0.0737 - val_acc: 0.9796
Epoch 10/10
- 9s - loss: 0.0473 - acc: 0.9845 - val_loss: 0.0759 - val_acc: 0.9785
show_train_history(train_history,'acc','val_acc')
show_train_history(train_history,'loss','val_loss')
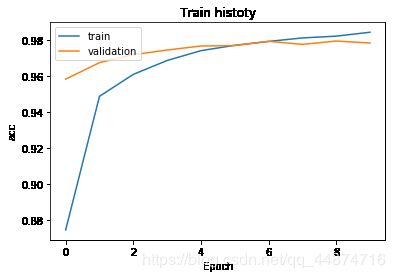

可以看到在经过加入两个隐藏层和Dropout层后,验证集的准确率逐渐提高,验证集的损失率有所下降,验证集和训练集的曲线均逐渐靠近,这说明过拟合的问题逐渐得到了解决。
5. 保存模型
之前训练模型准确率已经可以达到0.97,算是一个较为不错的成绩。那么,我们在训练的时候并没有设置任何保存机智,简单的MNIST手写字符集训练起来时间较短,如果碰到较大的模型不可能让工程师每次都重新训练,所以本节先讲述如何将训练好的模型保存到本地,以便一次读取使用。
5.1 将模型结构保存json格式
将模型的结构按层保存到json格式,这样可以实现互用效果,下次使用时不需要自己手动再搭建一次模型,如果需要将模型和他人分享也只需转发json格式即可。
from keras.models import model_from_json
import json
# 将上节的model转换成json
model_json = model.to_json()
# 格式化json方便阅读
model_dict = json.loads(model_json)
model_json = json.dumps(model_dict, indent=4, ensure_ascii=False)
# 将json保存到当前目录下
with open("./model_json.json",'w') as json_file:
json_file.write(model_json)
保存完成后,我们尝试读取json文件来创建一个新的模型。
# 打开文件
with open("./model_json.json",'r') as json_file:
# 读取文件中的信息
load_json = json_file.read()
# 输出读取的json接口
print(load_json)
{
"class_name": "Sequential",
"config": {
"name": "sequential_4",
"layers": [
{
"class_name": "Dense",
"config": {
"name": "dense_7",
"trainable": true,
"batch_input_shape": [
null,
784
],
"dtype": "float32",
"units": 1000,
"activation": "relu",
"use_bias": true,
"kernel_initializer": {
"class_name": "RandomNormal",
"config": {
"mean": 0.0,
"stddev": 0.05,
"seed": null
}
},
"bias_initializer": {
"class_name": "Zeros",
"config": {}
},
"kernel_regularizer": null,
"bias_regularizer": null,
"activity_regularizer": null,
"kernel_constraint": null,
"bias_constraint": null
}
},
{
"class_name": "Dropout",
"config": {
"name": "dropout_2",
"trainable": true,
"rate": 0.5,
"noise_shape": null,
"seed": null
}
},
{
"class_name": "Dense",
"config": {
"name": "dense_8",
"trainable": true,
"units": 1000,
"activation": "relu",
"use_bias": true,
"kernel_initializer": {
"class_name": "RandomNormal",
"config": {
"mean": 0.0,
"stddev": 0.05,
"seed": null
}
},
"bias_initializer": {
"class_name": "Zeros",
"config": {}
},
"kernel_regularizer": null,
"bias_regularizer": null,
"activity_regularizer": null,
"kernel_constraint": null,
"bias_constraint": null
}
},
{
"class_name": "Dropout",
"config": {
"name": "dropout_3",
"trainable": true,
"rate": 0.5,
"noise_shape": null,
"seed": null
}
},
{
"class_name": "Dense",
"config": {
"name": "dense_9",
"trainable": true,
"units": 10,
"activation": "softmax",
"use_bias": true,
"kernel_initializer": {
"class_name": "VarianceScaling",
"config": {
"scale": 1.0,
"mode": "fan_avg",
"distribution": "uniform",
"seed": null
}
},
"bias_initializer": {
"class_name": "Zeros",
"config": {}
},
"kernel_regularizer": null,
"bias_regularizer": null,
"activity_regularizer": null,
"kernel_constraint": null,
"bias_constraint": null
}
}
]
},
"keras_version": "2.2.4",
"backend": "tensorflow"
}
可以看到,我们所搭建的模型均通过json格式呈现出来,每一层的参数都在其中,效果比较直观。
接下去通过已经读取json搭建一个新的模型。
# 创建新模型并加载模型
new_model = model_from_json(load_json)
# 输出新的模型摘要
new_model.summary()
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
dense_7 (Dense) (None, 1000) 785000
_________________________________________________________________
dropout_2 (Dropout) (None, 1000) 0
_________________________________________________________________
dense_8 (Dense) (None, 1000) 1001000
_________________________________________________________________
dropout_3 (Dropout) (None, 1000) 0
_________________________________________________________________
dense_9 (Dense) (None, 10) 10010
=================================================================
Total params: 1,796,010
Trainable params: 1,796,010
Non-trainable params: 0
_________________________________________________________________
可以看到创建好模型后能成功输出模型摘要,与之前搭建的模型无异。
5.2 保存模型权重
上小节我们保存了模型的结构为json格式,这次我们尝试保存模型权重,这样下次打开程序可以直接读取,不需要每次使用时反复的训练。保存的格式为HDF5格式。
from keras.models import load_model
# 保存训练的好的model权重
model.save('mnist_model_v1.h5')
# 从本地读取mnist_model_v1
model_v1 = load_model('mnist_model_v1.h5')
利用测试集验证权重是否加载成功
model_v1.evaluate(X_Test_normalize, y_TestOneHot)
10000/10000 [==============================] - 1s 142us/step
[0.06437948538406636, 0.9799]
# 预测测试集
result_class = model.predict(X_Test)
# 查看前十项数据的预测结果
result_class[:10]
array([[0., 0., 0., 0., 0., 0., 0., 1., 0., 0.],
[0., 0., 1., 0., 0., 0., 0., 0., 0., 0.],
[0., 1., 0., 0., 0., 0., 0., 0., 0., 0.],
[1., 0., 0., 0., 0., 0., 0., 0., 0., 0.],
[0., 0., 0., 0., 1., 0., 0., 0., 0., 0.],
[0., 1., 0., 0., 0., 0., 0., 0., 0., 0.],
[0., 0., 0., 0., 1., 0., 0., 0., 0., 0.],
[0., 0., 0., 0., 0., 0., 0., 0., 0., 1.],
[0., 0., 0., 0., 0., 1., 0., 0., 0., 0.],
[0., 0., 0., 0., 0., 0., 0., 0., 0., 1.]], dtype=float32)
权重是加载成功的,并且可以正常使用,以后训练满意的模型可以用这种方式进行保存。
6. 小结
本章主要讲述了模型存在过拟合的问题,采用添加多层感知器提升模型的精度和添加Dropout可以解决过拟合问题。下一章将引入卷积神经网络的概念,这是深度学习领域的一个非常重要的创新,尤其是在图形图像方面,取得了非常大的成功。