LeetCode(SQL)难度-中等
LeetCode(SQL)难度-中等
注:排名知识点(题目1->思路来源于牛客-小数志(公众号))
- 连续排名,例如3000,2000,2000,1000排名结果为1-2-3-4,体现同薪不同名,排名类似于编号
- 同薪同名,但总排名不连续,如上薪水,排名为1-2-2-4
- 同薪同名,总排名连续,如上薪水,排名为1-2-2-3
题目1:编写一个 SQL 查询,获取 Employee 表中第 n 高的薪水(Salary)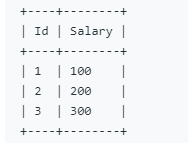
思路1:单表查询
本题只需考虑全局第N高的一个,可用order by+limit
-
本题情况为排名中的第三种同薪同名,总排名连续,所以需要利用group by按薪水分组后再order by
-
排名第N高意味着要跳过N-1个薪水,由于无法直接用limit N-1,所以需先在函数开头处理N为N=N-1
注1: 这里不能直接用limit N-1是因为limit和offset字段后面只接受正整数(意味着0、负数、小数都不行)或者单一变量(意味着不能用表达式),也就是说想取一条,limit 2-1、limit 1.1这类的写法都是报错的
注2: 这种解法形式最为简洁直观,但仅适用于查询全局排名问题,如果要求各分组的每个第N名,则该方法不适用;而且也不能处理存在重复值的情况
CREATE FUNCTION getNthHighestSalary(N INT) RETURNS INT
BEGIN
SET N:=N-1; ##因为limit不能出现表达式,所以需提前定义,注意要有分号
RETURN (
SELECT salary
FROM employee
GROUP BY salary ##可能出现同薪,需要分组
ORDER BY salary DESC
LIMIT N, 1
);
END
思路2:子查询
- 排名第N高的薪水意味着该表中粗在N-1个比其更高的薪水
- 注意这里的N-1个更高的薪水是去重后的N-1个,实际对应人数可能不止N-1个
- 最后返回的薪水也应该去重,因为可能不止一个薪水排名第N
- 由于对于每个薪水的where条件都要执行一遍子查询,注定其效率低下
CREATE FUNCTION getNthHighestSalary(N INT) RETURNS INT
BEGIN
RETURN (
SELECT e.salary
FROM employee e
WHERE
(SELECT count(DISTINCT salary) FROM employee where salary>e.salary) = N-1 ##表示前面有N-1的不同的薪资比第N个薪资大
);
END
思路3:自连接
注: 一般来说,能用子查询解决的问题也能用连接解决
- 两表自连接,连接条件设定为表1的salary小于表2的salary
- 以表1的salary分组,统计表1中每个salary分组后对应表2中salary唯一值个数,即去重
- 限定步骤2中having 计数个数为N-1,即实现了该分组中表1salary排名为第N个
- 考虑N=1的特殊情形(特殊是因为N-1=0,计数要求为0),此时不存在满足条件的记录数,但仍需返回结果,所以连接用left join
- 如果仅查询薪水这一项值,那么不用left join当然也是可以的,只需把连接条件放宽至小于等于、同时查询个数设置为N即可。因为连接条件含等号,所以一定不为空,用join即可。
CREATE FUNCTION getNthHighestSalary(N INT) RETURNS INT
BEGIN
RETURN (
SELECT e1.salary
FROM employee e1 inner join employee e2
on e1.salary <= e2.salary
GROUP by e1.salary
HAVING count(DISTINCT e2.salary) = N
);
END
思路4:笛卡尔积
CREATE FUNCTION getNthHighestSalary(N INT) RETURNS INT
BEGIN
RETURN (
SELECT DISTINCT e1.salary
FROM employee e1, employee e2
WHERE e1.salary <= e2.salary
GROUP BY e1.salary
HAVING count(DISTINCT e2.salary) = N
);
END
思路5:自定义变量(不懂)
注: 以上方法2-4中均存在两表关联的问题,表中记录数少时尚可接受,当记录数量较大且无法建立合适索引时,实测速度会比较慢,用算法复杂度来形容大概是O(n^2)量级(实际还与索引有关)。那么,用下面的自定义变量的方法可实现O(2*n)量级,速度会快得多,且与索引无关。
- 自定义变量实现按薪水降序后的数据排名,同薪同名不跳级,即3000、2000、2000、1000排名后为1、2、2、3
- 对带有排名信息的临时表二次筛选,得到排名为N的薪水
- 因为薪水排名为N的记录可能不止1个,用distinct去重
CREATE FUNCTION getNthHighestSalary(N INT) RETURNS INT
BEGIN
RETURN (
SELECT
DISTINCT salary
FROM
(SELECT
salary, @r:=IF(@p=salary, @r, @r+1) AS rnk, @p:= salary
FROM
employee, (SELECT @r:=0, @p:=NULL)init
ORDER BY
salary DESC) tmp
WHERE rnk = N
);
END
本题将查询语句封装成一个自定义函数并给出了模板,实际上是降低了对函数语法的书写要求和难度,而且提供的函数写法也较为精简。然而,自定义函数更一般化和常用的写法应该是分三步:
- 定义变量接收返回值
- 执行查询条件,并赋值给相应变量
- 返回结果
CREATE FUNCTION getNthHighestSalary(N INT) RETURNS INT
BEGIN
# i 定义变量接收返回值
DECLARE ans INT DEFAULT NULL;
# ii 执行查询语句,并赋值给相应变量
SELECT
DISTINCT salary INTO ans
FROM
(SELECT
salary, @r:=IF(@p=salary, @r, @r+1) AS rnk, @p:= salary
FROM
employee, (SELECT @r:=0, @p:=NULL)init
ORDER BY
salary DESC) tmp
WHERE rnk = N;
# iii 返回查询结果,注意函数名中是 returns,而函数体中是 return
RETURN ans;
END
思路6:自定义变量
- row_number():同薪不同名,相当于行号,相当于排名知识点中的第一个1-2-3-4
- rank():同薪同名,有跳级,相当于1-2-2-4
- dense_rank():同薪同名,无跳级,相当于1-2-2-3
CREATE FUNCTION getNthHighestSalary(N INT) RETURNS INT
BEGIN
RETURN (
SELECT
DISTINCT salary
FROM
(SELECT
salary, dense_rank() over(ORDER BY salary DESC) AS rnk
FROM
employee) tmp
WHERE rnk = N
);
END
窗口函数

题目2:编写一个 SQL 查询来实现分数排名。如果两个分数相同,则两个分数排名(Rank)相同。请注意,平分后的下一个名次应该是下一个连续的整数值。换句话说,名次之间不应该有“间隔”
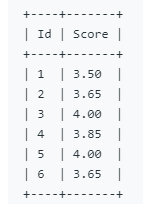
思路:利用开窗函数,进行排序,也就是第一题所提到的第三种排序
select Score,dense_rank() over(order by Score desc) as 'Rank'##必须加引号,否则会出现错误
from Scores;
select a.Score Score,
(select count(distinct b.score) from Scores b where b.score>=a.Score ) 'Rank'
##排名的思路,需要找出a.Score前面有N个大于他的,a.Score的排名则是N+1,也就是大于a.Score不同分数的个数,可以再纸上举出一个小例子,即可明白,例如43321,1是第4名,distinct 4:1个,distinct 3:1个,distinct 2:1个,用>=也就是1所在的第4名
FROM Scores a
order by a.Score desc
题目3:部门工资最高的员工,Employee 表包含所有员工信息,每个员工有其对应的 Id, salary 和 department Id;Department 表包含公司所有部门的信息
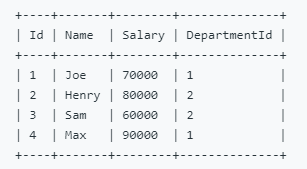
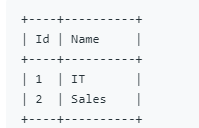 ##### 思路:先查找Employee表中的部门中的最高薪资,在连接两个表。
##### 思路:先查找Employee表中的部门中的最高薪资,在连接两个表。
select
Department.Name as Department,
Employee.Name as Employee,
Salary
from Employee inner join Department
on Department.ID = Employee.DepartmentId
where (Employee.DepartmentId,Salary) IN
(SELECT DepartmentId,MAX(Salary)##可以先查找部门内的最高薪资,在Employee表,然后再去查找名字,连接两个表
FROM Employee
GROUP BY DepartmentId)
题目4:换座位,小美是一所中学的信息科技老师,她有一张 seat 座位表,平时用来储存学生名字和与他们相对应的座位 id。其中纵列的 id 是连续递增的,小美想改变相邻俩学生的座位。如果学生人数是奇数,则不需要改变最后一个同学的座位

思路1:首先找出有多少个座位,然后判断id在为奇数的情况下,是否为最后一个座位,若不是则id+1,如果为最后一个,则id不变,若id为偶数,则id-1
SELECT
(CASE
WHEN MOD(id, 2) != 0 AND counts != id THEN id + 1 ##奇数且不是最后一个座位,则和下一个id交换
WHEN MOD(id, 2) != 0 AND counts = id THEN id ##如果学生人数是奇数,则不需要改变最后一个同学的座位
ELSE id - 1##偶数,则id-1和奇数交换
END) AS id,
student
FROM
seat,
(SELECT
COUNT(*) AS counts
FROM
seat) AS seat_counts ##查找座位的个数
ORDER BY id ASC;
思路2:先利用(id+1)^1-1交换id,然后连接座位表和更新id后的座位表,然后id升序排列,具体思路如表所示:

SELECT
s1.id, COALESCE(s2.student, s1.student) AS student ##返回第一个非空的表达式
FROM
seat s1
LEFT JOIN
seat s2 ON ((s1.id + 1) ^ 1) - 1 = s2.id ##异或,就是^两边,第一次相加,第二次相减,以此类推
ORDER BY s1.id;
题目5 :编写一个 SQL 查询,查找所有至少连续出现三次的数字(有两个字段 ID, Num,表名Log)要求输出Num的值。
思路:连续出现的意味着相同数字的 Id 是连着的,由于这题问的是至少连续出现 3 次,我们使用 Logs 并检查是否有 3 个连续的相同数字.
Select distinct L1.Num ConsecutiveNums ##必须写distinct ,只输出1个值
from Logs L1,Logs L2, Logs L3
where L1.ID=L2.ID+1 AND L2.ID=L3.ID+1 AND L1.Num=L2.Num and L2.Num=L3.Num