ElasticSearch全文检索&Spring Data
花有重开日,人无再少年
- Elasticsearch简介
- Elasticsearch的安装与启动
- 安装es和ik分词器
- 安装es图形化界面-->elasticsearch-head-master
- ElasticSearch相关概念(术语)
- Elasticsearch编程操作
- 搭建工程
- 创建索引
- 删除索引
- 创建映射(基于jsonBuilder)
- 添加索引+创建文档
- 基于jsonBuilder添加文档
- 基于map添加文档
- 基于json添加文档
- 批量添加
- 修改文档
- 通过prepareUpdate修改
- 通过update修改
- 删除文档数据
- 通过preparedDelete删除
- 通过delete删除
- 查询文档
- 根据文档id查询(不经索引)
- 查询全部(不经索引)
- 字符串查询
- 词条查询
- 通配符查询
- 相似度查询
- 范围查询
- 组合查询
- 分页排序
- 高亮
- 查询结果封装成bean
- 注意事项:
- RESTFul操作索引
- 创建索引+映射
- 删除索引
- 创建文档
- 修改文档
- 删除文档
- 根据id查询
- 根据字符串查询
- 词条查询
- Spring Data 操作 ES
- 搭建工程
- 实体类
- DAO
- Service
- service接口
- service实现类
- 配置映射
- 核心配置文件
- 测试类
Elasticsearch简介
ElaticSearch,简称为es,es是一个开源的高扩展的分布式全文检索引擎,它可以近乎实时的存储、检索数据;本身扩展性很好,可以扩展到上百台服务器,处理PB级别的数据。es也使用Java开发并使用Lucene作为其核心来实现所有索引和搜索的功能,但是它的目的是通过简单的RESTful API来隐藏Lucene的复杂性,从而让全文搜索变得简单。
Elasticsearch的安装与启动
笔者开发环境使用的是1.8JDK版本;
![]()
Elasticsearch版本为5.6.8,分词器使用IK分词器,请自行下载。

安装es和ik分词器
注意安装目录不要有中文和特殊字符,笔者将其放在磁盘根目录下。并将分词器解压放入plugins目录并重命名为ik,修改配置文件并创建停用词和自定义词条文件。


准备完毕后启动es,如果闪退请降低配置内存,
正常启动后浏览器访问本地9200端口,出现如下界面说明安装成功。
![]()
安装es图形化界面–>elasticsearch-head-master
解压elasticsearch-head-master,同样放到了磁盘根目录。
![]()
需要提前准备node.js环境,笔者用的版本为8.9.4

然后安装grunt构建工具,在head目录启动dos窗口,在命令提示符下输入命令:
grunt server
解决跨域访问:
修改elasticsearch/config下的配置文件:elasticsearch.yml,增加以下三句命令:
http.cors.enabled: true
http.cors.allow-origin: "*"
network.host: 127.0.0.1
重启Elasticsearch。
本地访问9100端口,出现以下页面说明安装成功,至此所有准备工作完成。
![]()

ElasticSearch相关概念(术语)
Elasticsearch是面向文档(document oriented)的,这意味着它可以存储整个对象或文档(document)。然而它不仅仅是存储(store),还会索引(index)每个文档的内容使之可以被搜索。在Elasticsearch中,你可以对文档(而非成行成列的数据)进行索引、搜索、排序、过滤。
- 索引index:一个索引就是一个拥有几分相似特征的文档(记录[数据])的集合。类似于database
- 类型type:在一个索引中,你可以定义一种或多种类型。类似table
- 文档document:一个文档是一个可被索引的基础信息单元,类似于一条记录
- 域field:对文档数据根据不同属性进行的分类标识,类似于字段
- 映射mapping:指定field的类型和属性。
Elasticsearch编程操作
搭建工程
工程坐标:
<groupId>pers.buyusangroupId>
<artifactId>elasticsearch-day1-demo1artifactId>
<version>1.0-SNAPSHOTversion>
添加依赖:
<dependency>
<groupId>org.elasticsearchgroupId>
<artifactId>elasticsearchartifactId>
<version>5.6.8version>
dependency>
<dependency>
<groupId>org.elasticsearch.clientgroupId>
<artifactId>transportartifactId>
<version>5.6.8version>
dependency>
<dependency>
<groupId>org.apache.logging.log4jgroupId>
<artifactId>log4j-to-slf4jartifactId>
<version>2.9.1version>
dependency>
<dependency>
<groupId>org.slf4jgroupId>
<artifactId>slf4j-apiartifactId>
<version>1.7.24version>
dependency>
<dependency>
<groupId>org.slf4jgroupId>
<artifactId>slf4j-simpleartifactId>
<version>1.7.21version>
dependency>
<dependency>
<groupId>log4jgroupId>
<artifactId>log4jartifactId>
<version>1.2.12version>
dependency>
<dependency>
<groupId>junitgroupId>
<artifactId>junitartifactId>
<version>4.12version>
dependency>
代码全部在测试类中进行:

提取公共部分:
private TransportClient client;
@Before
public void setUp() throws Exception{
//不使用集群,创建TransprotClient对象
client = new PreBuiltTransportClient(Settings.EMPTY);
//配置连接信息,ip+端口
client.addTransportAddress(new InetSocketTransportAddress(InetAddress.getByName("127.0.0.1"),9300));
}
@After
public void close(){
//关闭资源
client.close();
}
创建索引
只创建索引:
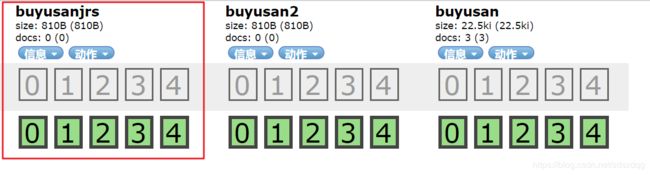
client.admin().indices().prepareCreate("buyusanjrs").get();
执行结果:
删除索引
删除名称为“buyusanjrs”的索引:
client.admin().indices().prepareDelete("buyusanjrs").get();
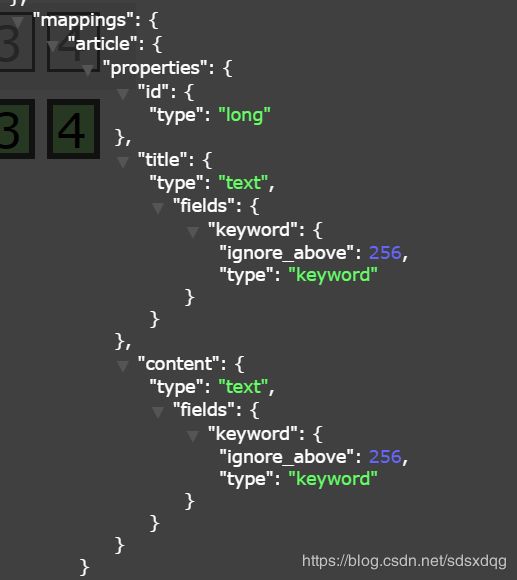
创建映射(基于jsonBuilder)
创建索引后如果不创建映射,es会根据默认根据文档的数据来创建。
如果需要指定ik分词器,则需要手动创建映射。
可以通过jsonBuilder对象来创建映射。
XContentBuilder builder = XContentFactory.jsonBuilder();
builder.startObject()
.startObject("article")
.startObject("properties")
.startObject("id")
.field("type","long")
.endObject()
.startObject("title")
.field("type","string")
.field("store","false")
.field("analyzer","ik_smart")
.endObject()
.startObject("content")
.field("type","string")
.field("store","false")
.field("analyzer","ik_smart")
.endObject()
.endObject()
.endObject()
.endObject();
PutMappingRequest mapping = Requests.putMappingRequest("buyusanjrs").type("article").source(builder);
client.admin().indices().putMapping(mapping);
执行完毕后,查看“buyusanjrs”的索引信息:

添加索引+创建文档
基于jsonBuilder添加文档
//构建文档对象
XContentBuilder builder = XContentFactory.jsonBuilder().startObject();
builder.field("id",1);
builder.field("title","ElasticSearch是一个基于Lucene的搜索服务器。");
builder.field("content","它提供了一个分布式多用户能力的全文搜索引擎,基于RESTful web接口。Elasticsearch是用Java开发的,并作为Apache许可条款下的开放源码发布,是当前流行的企业级搜索引擎。设计用于云计算中,能够达到实时搜索,稳定,可靠,快速,安装使用方便。");
builder.endObject();
//使用TransportClient对象创建文档
client.prepareIndex("buyusan","article","1").setSource(builder).get();
执行代码后,索引、类型若不存在,则会生成,并可以查看到数据。
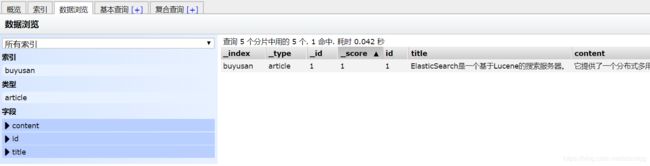
查看索引信息:
可见索引在添加数据时自动生成。
基于map添加文档
也可以基于map存储。
//构建文档对象
Map<String,Object> map = new HashMap<String,Object>();
map.put("id",2);
map.put("title","map-ElasticSearch是一个基于Lucene的搜索服务器");
map.put("content","map-它提供了一个分布式多用户能力的全文搜索引擎,基于RESTful web接口。Elasticsearch是用Java开发的,并作为Apache许可条款下的开放源码发布,是当前流行的企业级搜索引擎。");
//使用TransportClient对象创建文档
client.prepareIndex("buyusan","article","2").setSource(map).get();
运行查看结果:

基于json添加文档
添加Jackson依赖和实体类Article
<dependency>
<groupId>com.fasterxml.jackson.coregroupId>
<artifactId>jackson-coreartifactId>
<version>2.8.1version>
dependency>
<dependency>
<groupId>com.fasterxml.jackson.coregroupId>
<artifactId>jackson-databindartifactId>
<version>2.8.1version>
dependency>
<dependency>
<groupId>com.fasterxml.jackson.coregroupId>
<artifactId>jackson-annotationsartifactId>
<version>2.8.1version>
dependency>
public class Article implements Serializable {
private Integer id;
private String title;
private String content;
//..get..set..toString
}
添加文档:
//创建article对象
Article article = new Article();
article.setId(1);
article.setTitle("小米");
article.setContent("小米是饭小萌的吉祥物");
//把article对象转换成json
ObjectMapper objectMapper = new ObjectMapper();
String articleJson = objectMapper.writeValueAsString(article);
//创建文档
client.prepareIndex("buyusanjrs","article",article.getId()+"")
.setSource(articleJson, XContentType.JSON)
.get();
结果查看:

批量添加
实际开发中,批量添加比一条一条依次添加效率高很多倍。
//json转换对象
ObjectMapper objectMapper = new ObjectMapper();
//批量增加数据构建对象
BulkRequestBuilder builder = client.prepareBulk();
for (int i = 1; i <= 100; i++) {
//创建article对象
Article article = new Article();
article.setId(i);
article.setTitle(i + "小米");
article.setContent(i + "小米是饭小萌的吉祥物");
builder.add(
client.prepareIndex("buyusanjrs","article",article.getId()+"")
.setSource(objectMapper.writeValueAsString(article),XContentType.JSON)
);
}
//执行操作
builder.execute().actionGet();
结果查看(只能显示50条):
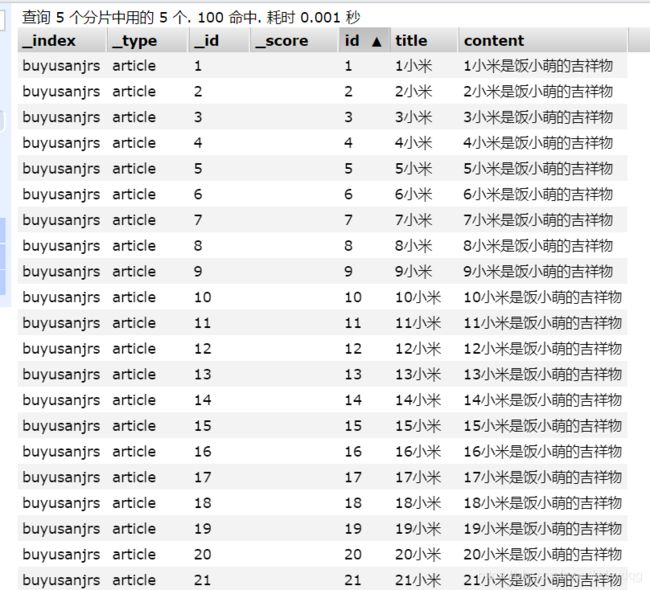
修改文档
通过prepareUpdate修改
代码:
//创建article对象
Article article = new Article();
article.setId(1);
article.setTitle("大米");
article.setContent("大米是饭小萌的顶梁柱");
//把article对象转换成json
ObjectMapper objectMapper = new ObjectMapper();
String articleJson = objectMapper.writeValueAsString(article);
//修改文档
client.prepareUpdate("buyusanjrs","article",article.getId()+"")
.setDoc(articleJson, XContentType.JSON)
.get();
查看结果:

通过update修改
代码:
//创建article对象
Article article = new Article();
article.setId(1);
article.setTitle("大小米");
article.setContent("大小米是饭小萌的顶梁柱");
//把article对象转换成json
ObjectMapper objectMapper = new ObjectMapper();
String articleJson = objectMapper.writeValueAsString(article);
//创建文档
client.update(new UpdateRequest("buyusanjrs","article",article.getId()+"")
.doc(articleJson,XContentType.JSON))
.get();
查看结果:

删除文档数据
通过preparedDelete删除
client.prepareUpdate("buyusan","article","3").get();
通过delete删除
client.delete(new DeleteRequest("buyusan","article","3")).get();
查询文档
根据文档id查询(不经索引)
//查询数据
GetResponse response = client.prepareGet("buyusan", "article", "1").get();
//获取结果集数据
String result = response.getSourceAsString();
System.out.println(result);
![]()
这里代码中的id是es为每个文档生成的唯一标识id,而不是article中的id域,虽然这两个值相等,但不是同一个含义。查询结果中的id是article中的id域。
查询全部(不经索引)
SearchResponse response = client.prepareSearch("buyusan")
.setTypes("article")
.setQuery(QueryBuilders.matchAllQuery())
.get();
SearchHits hits = response.getHits();
long totalHits = hits.getTotalHits();
for (SearchHit hit : hits) {
//获取指定域数据
//String title = hit.getSource().get("title").toString();
//获取所有数据,并转成JSON字符串
String result = hit.getSourceAsString();
//System.out.println(title);
System.out.println(result);

这里用了QueryBuilders.matchAllQuery(),得到hits集合(封装了所有的document),通过遍历可以依次取出每个文档。
字符串查询
只需要修改QueryBuilders.matchAllQuery(),改为QueryBuilders.queryStringQuery(“搜索”)。其余不变。
如果指定field,可以在后边直接调用field(String fieldname)来指定域。
这里搜索条件为“搜索”,其实是拆分成了“搜”“索”两个字依次通过索引去查询。这时没有通过映射去指定分词器,所以在索引中,中文被拆分成了单个字作为词条,所以这里通过“搜索”查询经过索引域,但仍然可以查询到数据信息。
词条查询
如果改用词条查询,只需要修改QueryBuilders调用termQuery方法。指定域和词条。
![]()
这里查询结果为空,就是因为词条搜索不会拆分搜索条件,把搜索当成一个词条去索引库中查询,由于没有指定分词器,所以索引库中都是单个中文,故找不到结果。
通配符查询
只需要修改QueryBuilders调用wildcardQuery方法。
其中*代表任意,?代表一个。
![]()
这样搜索仍然没有结果,因为这里相当于词条查询,搜索条件不会拆分。如果搜索条件为“搜”则可以查询到结果。而搜索条件为“?索”则不可以,因为“?”代表一个任意字符,如果没有字符是匹配不到的。
相似度查询
![]()
只要输入内容满足一定程度上与“搜索”相似,就可以搜到。
范围查询
![]()
还有lt lte gt gte分别表示小于、小于等于、大于、大于等于。
组合查询
must(QueryBuilders) : AND,求交集
mustNot(QueryBuilders): NOT IN
should(QueryBuilders):OR ,求并集
分页排序

高亮
本质就是在搜索的词语前后加上标签内容使其在html上显示颜色。
代码表示:
//ObjectMapper
ObjectMapper objectMapper = new ObjectMapper();
//做分页
SearchRequestBuilder searchRequestBuilder = client.prepareSearch("buyusanjrs")
.setTypes("article")
//搜索的关键词 "小米" 小米
.setQuery(QueryBuilders.termQuery("title", "小米"))
//分页参数 哪一页开始,每页显示多少条
.setFrom(0) //从0开始,0:第1条记录 N*size PageHelper.startPage(pageNum,size)
.setSize(2);//size 每页显示的条数
//开启高亮
HighlightBuilder highlightBuilder = new HighlightBuilder(); //高亮配置
highlightBuilder.preTags(""); //前缀
highlightBuilder.postTags(""); //后缀
//指定高亮域:用户搜索的关键词在指定域中如果出现,则给他添加高亮域样式 关键词
highlightBuilder.field("title");
//设置高亮对象
searchRequestBuilder.highlighter(highlightBuilder);
//搜索实现
SearchResponse response = searchRequestBuilder.get();
//解析数据
SearchHits hits = response.getHits();
long totalHits = hits.getTotalHits();
//数据集合
Iterator<SearchHit> iterator = hits.iterator();
while (iterator.hasNext()){
SearchHit hit = iterator.next();
//获取数据-JSON字符串
String articleJson = hit.getSourceAsString();
//System.out.println(articleJson);
Article article = objectMapper.readValue(articleJson, Article.class);
//获取高亮数据
Map<String, HighlightField> highlightFields = hit.getHighlightFields();
String hlstr = "";
if(highlightFields!=null && highlightFields.size()>0){
//数组
Text[] titles = highlightFields.get("title").getFragments();
hlstr = titles[0].toString();
//将非高亮数据替换成高亮数据
article.setTitle(hlstr);
}
System.out.println(article);
查询结果封装成bean
Article article = objectMapper.readValue(result,Article.class);
result是json字符串。
注意事项:
查询是如果用户输入大写字母进行模糊查询,需要转换成小写再查,因为分词器会把所有英语单词转换成小写字母。
RESTFul操作索引
ES是支持RESTFul风格发送请求和操作索引的。这里笔者用postman工具进行测试。
创建索引+映射
发送请求,指定一个新的索引,这里笔者使用buyusan2:
PUT http://localhost:9200/buyusan2
请求体:
{
"mappings": {
"article": {
"properties": {
"id": {
"type": "long",
"store": false,
"index":"not_analyzed"
},
"title": {
"type": "text",
"store": false,
"index":"analyzed",
"analyzer":"ik_smart"
},
"content": {
"type": "text",
"store": false,
"index":"analyzed",
"analyzer":"ik_smart"
}
}
}
}
}
发送请求查看索引信息:

删除索引
DELETE http://localhost:9200/buyusan
创建文档
POST http://localhost:9200/buyusan/article/3
请求体:
{
"id":3,
"title":"postman-restful-ElasticSearch是一个基于Lucene的搜索服务器",
"content":"restful-它提供了一个分布式多用户能力的全文搜索引擎,基于RESTfulweb接口。Elasticsearch是用Java开发的,并作为Apache许可条款下的开放源码发布,是当前流行的企业级搜索引擎。设计用于云计算中,能够时搜索。"
}
结果查看:

修改文档
POST http://localhost:9200/buyusan/article/3
请求体:
{
"id":3,
"title":"修改啦postman-restful-ElasticSearch是一个基于Lucene的搜索服务器",
"content":"修改啦restful-它提供了一个分布式多用户能力的全文搜索引擎,基于RESTfulweb接口。Elasticsearch是用Java开发的,并作为Apache许可条款下的开放源码发布,是当前流行的企业级搜索引擎。设计用于云计算中,能够时搜索。"
}
结果查看:

删除文档
DELETE http://localhost:9200/buyusan/article/3
根据id查询
GET http://localhost:9200/buyusan/article/1
查询结果:

根据字符串查询
POST http://localhost:9200/buyusan/article/_search
要有固定格式的请求体:
{
"query": {
"query_string": {
"default_field": "title",
"query": "搜索"
}
}
}
查看结果:

原理与代码操作字符串查询相同。
词条查询
POST http://localhost:9200/buyusan/article/_search
请求体:
{
"query": {
"term": {
"title": "搜索"
}
}
}
Spring Data 操作 ES
搭建工程
坐标:
<groupId>pers.buyusangroupId>
<artifactId>elasticsearch-springdata-esartifactId>
<version>1.0-SNAPSHOTversion>
依赖:
<dependency>
<groupId>org.elasticsearchgroupId>
<artifactId>elasticsearchartifactId>
<version>5.6.8version>
dependency>
<dependency>
<groupId>org.elasticsearch.clientgroupId>
<artifactId>transportartifactId>
<version>5.6.8version>
dependency>
<dependency>
<groupId>org.apache.logging.log4jgroupId>
<artifactId>log4j-to-slf4jartifactId>
<version>2.9.1version>
dependency>
<dependency>
<groupId>org.slf4jgroupId>
<artifactId>slf4j-apiartifactId>
<version>1.7.24version>
dependency>
<dependency>
<groupId>org.slf4jgroupId>
<artifactId>slf4j-simpleartifactId>
<version>1.7.21version>
dependency>
<dependency>
<groupId>log4jgroupId>
<artifactId>log4jartifactId>
<version>1.2.12version>
dependency>
<dependency>
<groupId>junitgroupId>
<artifactId>junitartifactId>
<version>4.12version>
dependency>
<dependency>
<groupId>org.springframeworkgroupId>
<artifactId>spring-testartifactId>
<version>5.0.8.RELEASEversion>
dependency>
<dependency>
<groupId>org.springframework.datagroupId>
<artifactId>spring-data-elasticsearchartifactId>
<version>3.0.7.RELEASEversion>
dependency>
实体类
public class Article {
private Integer id;
private String title;
private String content;
//..set..get..toString
}
DAO
public interface ArticleDao extends ElasticsearchRepository<Article,Integer> {
}
Service
service接口
public interface ArticleService {
/***
* 增加数据
* @param article
*/
void save(Article article);
}
service实现类
@Service
public class ArticleServiceImpl implements ArticleService {
@Autowired
private ArticleDao articleDao;
@Override
public void save(Article article) {
articleDao.save(article);
}
}
配置映射
配置实体类注解,配置映射
@Document(indexName = "buyusan4",type = "article")
public class Article implements Serializable {
//@Id 文档主键 唯一标识
@Id
private Integer id;
@Field(index = true,analyzer = "ik_smart",store=false,searchAnalyzer="ik_smart",type = FieldType.Text)
private String title;
@Field(index = true,analyzer = "ik_smart",store=false,searchAnalyzer="ik_smart",type = FieldType.Text)
private String content;
}
核心配置文件
在resources下创建springdata-es.xml:
<beans xmlns="http://www.springframework.org/schema/beans"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xmlns:context="http://www.springframework.org/schema/context"
xmlns:elasticsearch="http://www.springframework.org/schema/data/elasticsearch"
xsi:schemaLocation="
http://www.springframework.org/schema/beans
http://www.springframework.org/schema/beans/spring-beans.xsd
http://www.springframework.org/schema/context
http://www.springframework.org/schema/context/spring-context.xsd
http://www.springframework.org/schema/data/elasticsearch
http://www.springframework.org/schema/data/elasticsearch/spring-elasticsearch-1.0.xsd
">
<context:component-scan base-package="pers.buyusan.service" />
<elasticsearch:repositories base-package="pers.buyusan.dao"/>
<elasticsearch:transport-client id="client" cluster-nodes="localhost:9300" cluster-name="elasticsearch"/>
<bean id="elasticsearchTemplate" class="org.springframework.data.elasticsearch.core.ElasticsearchTemplate">
<constructor-arg name="client" ref="client">constructor-arg>
bean>
beans>
测试类
@RunWith(SpringJUnit4ClassRunner.class)
@ContextConfiguration(locations="classpath:springdata-es.xml")
public class SpringDataEsTest {
@Autowired
private ArticleService articleService;
@Autowired
private ElasticsearchTemplate elasticsearchTemplate;
/**
* 创建索引和映射信息
*/
@Test
public void testCreateMapping(){
elasticsearchTemplate.createIndex(Article.class);
elasticsearchTemplate.putMapping(Article.class);
}
/**
* 添加文档数据
*/
@Test
public void testSave(){
Article article = new Article();
article.setId(1);
article.setTitle("测试SpringData ElasticSearch");
article.setContent("Spring Data ElasticSearch 基于 spring data API 简化 elasticSearch操作,将原始操作elasticSearch的客户端API 进行封装Spring Data为Elasticsearch Elasticsearch项目提供集成搜索引擎");
articleService.save(article);
}
}
运行结果:

可见用spring data大大简化了es操作。
并且在查询时,可以直接通过方法名在决定查询方式:
| 关键字 | 命名规则 | 解释 | 示例 |
|---|---|---|---|
| and | findByField1AndField2 | 根据Field1和Field2获得数据 | findByTitleAndContent |
| or | findByField1OrField2 | 根据Field1或Field2获得数据 | findByTitleOrContent |
| is | findByField | 根据Field获得数据 | findByTitle |
| not | findByFieldNot | 根据Field获得补集数据 | findByTitleNot |
| between | findByFieldBetween | 获得指定范围的数据 | findByPriceBetween |
| lessThanEqual | findByFieldLessThan | 获得小于等于指定值的数据 | findByPriceLessThan |