三叉搜索树(Ternary Search Trie)和中文分词原理分析
三叉搜索树(Ternary Search Trie)
三叉搜索树是二叉搜索树和数字搜索树的混合体。它有和数字搜索树差不多的速度但是只需要和二叉搜索树一样相对较少的内存空间。在一个三叉搜索树中,每一个节点包含一个字符,和数字搜索树不同,三叉搜索树只有三个指针:一个指向左边的树;一个指向右边的树;还有一个向下,指向单词的下一个数据单元。
三叉树是否平衡取决于单词的读入顺序。单词的读入顺序对于创建平衡的三叉搜索树很重要,但对于二叉搜索树就不太重要。通过选择一个排序后数据单元集合的中间值,并把它作为开始节点,我们可以创建一个平衡的三叉树。可以写一个专门的过程来生成平衡的三叉树词典。
取得平衡的单词排序类似于洗扑克牌。假想有若干张扑克牌,每张牌对应一个单词,先把牌排好序,然后取最中间的一张牌,单独放着。剩下的牌分成了两摞,左边一摞牌中也取最中间的一张放在取出来的那张牌后面。右边一摞牌中也取最中间的一张放在取出来的牌后面,以此类推。
/**
* 在调用此方法前,先把词典数组dict排好序
*
* @param fp
* 写入平衡序的词典
* @param dict
* 排好序的词典数组
* @param offset
* 偏移量
* @param len
* 长度
* @throws IOException
*/
public void outputBalanced(BufferedWriter fp, ArrayList dict, int offset, int len) throws IOException {
int temp;
if ( len < 1 ) return;
temp = len >> 1; // temp=len/2
String item = dict.get( temp + offset );
fp.write(item);// 把词条写入到文件
fp.write("\n");
outputBalanced(fp, dict, offset, temp); // 输出左半部分
outputBalanced(fp, dict, offset + temp + 1, len - temp - 1); // 输出右半部分
}
以有序的数据单元(as at be by he in is it of on or to)为例。 首先我们把关键字"is"作为中间值并且构建一个包含字母"i"的根节点。它的直接后继节点包含字母"s"并且可以存储任何与"is"有关联的数据。对于"i"的左树,我们选择"be"作为中间值并且创建一个包含字母"b"的节点,字母"b"的直接后继节点包含"e"。该数据存储在"e"节点。对于"i"的右树,按照逻辑,选择"on"作为中间值,并且创建"o"节点以及它的直接后继节点"n"。最终的三叉树如图:
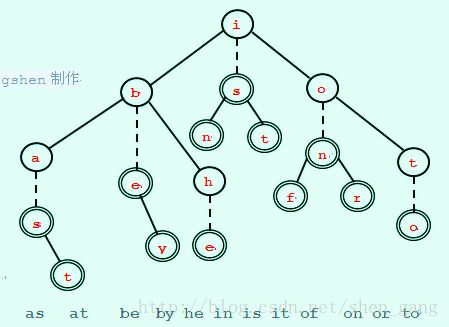
垂直的虚线代表一个父节点下的直接后继节点。只有父节点和它的直接后继节点才能形成一个数据单元的关键字;"i"和"s"形成关键字"is",但是"i"和"b"不能形成关键字,因为它们之间仅用一条斜线相连,不具有直接后继关系。图中带圈的节点为终止节点,如果查找一个词以终止节点结束,则说明三叉树包含这个词。从根节点开始查找单词,以搜索单词"is"为例,向下到相等的孩子节点"s",在两次比较后找到"is"。查找"ax"时,执行三次比较达到首字符"a",然后经过两次比较到达第二个字符"x",返回结果是"ax"不在树中。
TernarySearchTrie本身存储关键字到值的对应关系,可以当做HashMap对象来使用。关键字按照字符拆分成许多节点,以TSTNode的实例存在。值存储在TSTNode的data属性中。TSTNode的实现代码如下:
public final class TSTNode {
/** 节点的值 */
public Data data = null; // data属性可以存储 词原文和词性、词频等相关的信息
protected TSTNode loNode; // 左边节点
protected TSTNode eqNode; // 中间节点
protected TSTNode hiNode; // 右边节点
protected char splitchar; // 本节点表示的字符
/**
* 构造方法
*
* @param splitchar
* 该节点表示的字符
*/
protected TSTNode(char splitchar) {
this.splitchar = splitchar;
}
public String toString() {
return "splitchar:" + splitchar;
}
}
查找词典的基本过程是:输入一个词,返回这个词对应的TSTNode对象,如果该词不在词典中则返回空。在查找词典的过程中,从树的根节点匹配Key,按Char从前往后匹配Key。charIndex表示Key当前要比较的Char的位置。
protected TSTNode getNode(String key, TSTNode startNode) {
if (key == null) {
return null;
}
int len = key.length();
if (len == 0)
return null;
TSTNode currentNode = startNode; // 匹配过程中当前节点的位置
int charIndex = 0;
char cmpChar = key.charAt(charIndex);
int charComp;
while (true) {
if (currentNode == null) {// 没找到
return null;
}
charComp = cmpChar - currentNode.splitchar;
if (charComp == 0) {// 相等
charIndex++;
if (charIndex == len) {// 找到了
return currentNode;
} else {
cmpChar = key.charAt(charIndex);
}
currentNodecurrentNode = currentNode.eqNode;
} else if (charComp < 0) {// 小于
currentNodecurrentNode = currentNode.loNode;
} else {// 大于
currentNodecurrentNode = currentNode.hiNode;
}
}
}三叉树的创建过程也就是在Trie树上创建和单词对应的节点。实现代码如下:
// 向词典树中加入一个单词的过程
private TSTNode addWord(String key) {
TSTNode currentNode = root; // 从树的根节点开始查找
int charIndex = 0; // 从词的开头匹配
while (true) {
// 比较词的当前字符与节点的当前字符
int charComp = key.charAt(charIndex) - currentNode.splitchar;
if (charComp == 0) {// 相等
charIndex++;
if (charIndex == key.length()) {
return currentNode;
}
if (currentNode.eqNode == null) {
currentNode.eqNode = new TSTNode(key.charAt(charIndex));
}
currentNodecurrentNode = currentNode.eqNode;
} else if (charComp < 0) {// 小于
if (currentNode.loNode == null) {
currentNode.loNode = new TSTNode(key.charAt(charIndex));
}
currentNodecurrentNode = currentNode.loNode;
} else {// 大于
if (currentNode.hiNode == null) {
currentNode.hiNode = new TSTNode(key.charAt(charIndex));
}
currentNodecurrentNode = currentNode.hiNode;
}
}
}相对于查找过程,创建过程在搜索过程中判断出链接的空值后创建相关的节点,而不是碰到空值后结束搜索过程并返回空值。
同一个词可以有不同的词性,例如"朝阳"既可能是一个"区",也可能是一个"市"。可以把这些和某个词的词性相关的信息放在同一个链表中。这个链表可以存储在TSTNode 的Data属性中。
中文分词的原理
中文分词有以下两类方法。
机械匹配的方法:例如正向最大长度匹配(ForwardMaximum Match)的方法和逆向最大长度匹配(Reverse Maximum Matching)的方法。
统计的方法:例如最大概率分词方法和最大熵分词方法等。
正向最大长度匹配的分词方法实现起来很简单。每次从词典中查找和待匹配串前缀最长匹配的词,如果找到匹配词,则把这个词作为切分词,待匹配串减去该词;如果词典中没有词与其匹配,则按单字切分。
例如:"有意见分歧"这句话,正向最大长度切分的结果是"有意/见/分歧",逆向最大长度切分的结果是"有/意见/分歧"。因为汉语的主干成分后置,所以逆向最大长度切分的精确度稍高。
例如,Trie树结构的词典中包括如下的词语:大 大学 大学生 活动 生活 中 中心 心
为了形成平衡的Trie树,把词先排序,结果为:
中 中心 大 大学 大学生 心 活动 生活
按平衡方式生成的词典Trie树如图所示,其中粗黑显示的节点可以作为匹配终止节点。

从Trie树搜索最长匹配单词的方法如下所示:
public String matchLong(String key, int offset) { // 输入字符串和匹配的开始位置
String ret = null;
if (key == null || rootNode == null || "".equals(key)) {
return ret;
}
TSTNode currentNode = rootNode;
int charIndex = offset;
while (true) {
if (currentNode == null) {
return ret;
}
int charComp = key.charAt(charIndex) - currentNode.spliter;
if (charComp == 0) {
charIndex++;
if (currentNode.data != null) {
ret = currentNode.data; // 候选最长匹配词
}
if (charIndex == key.length()) {
return ret; // 已经匹配完
}
currentNodecurrentNode = currentNode.eqNode;
} else if (charComp < 0) {
} else {
}
}
}测试matchLong方法如下所示:
String sentence = "大学生活动中心";//输入字符串
int offset = 0;//匹配的开始位置
String ret = dic.matchLong(sentence,offset);
System.out.println(sentence+" match:"+ret); 返回结果如下所示:
大学生活动中心match:大学生
正向最大长度分词的实现代码如下所示:
public void wordSegment(String sentence) {// 传入一个字符串作为要处理的对象
int senLen = sentence.length();// 首先计算出传入的字符串的字符长度
int i = 0;// 控制匹配的起始位置
while (i < senLen) {// 如果i小于此字符串的长度就继续匹配
String word = dic.matchLong(sentence, i);// 正向最大长度匹配
if (word != null) {// 已经匹配上
// 下次匹配点在这个词之后
i += word.length();
// 如果这个词是词库中的那么就打印出来
System.out.print(word + " ");
} else {// 如果在词典中没有找到匹配上的词,就按单字切分
word = sentence.substring(i, i + 1);
// 打印一个字
System.out.print(word + " ");
++i;// 下次匹配点在这个字符之后
}
}
}因为采用了Trie树结构查找单词,所以和用HashMap查找单词的方式比较起来,这种实现方法代码更简单,而且切分速度更快。