深度学习论文: Pyramidal Convolution: Rethinking CNN for Visual Recognition及其PyTorch实现
深度学习论文: Pyramidal Convolution: Rethinking Convolutional Neural Networks for Visual Recognition及其PyTorch实现
Pyramidal Convolution: Rethinking Convolutional Neural Networks for Visual Recognition
PDF:https://arxiv.org/pdf/2006.11538.pdf
PyTorch: https://github.com/shanglianlm0525/PyTorch-Networks
1 概述
该文提出一种金字塔卷积(Pyramidal Convolution, PyConv),它可以在多个滤波器尺度对输入进行处理。PyConv包含一个核金字塔,每一层包含不同类型的滤波器(滤波器的大小与深度可变,因此可以提取不同尺度的细节信息)。除了上述提到的可以提取多尺度信息外,相比标准卷积,PyConv实现高效,即不会提升额外的计算量与参数量。更进一步,它更为灵活并具有可扩展性,为不同的应用提升了更大的架构设计空间。
2 Pyramidal Convolution

def ConvBNReLU(in_channels,out_channels,kernel_size,stride,groups=1):
return nn.Sequential(
nn.Conv2d(in_channels=in_channels, out_channels=out_channels, kernel_size=kernel_size, stride=stride,padding=kernel_size//2,groups=groups),
nn.BatchNorm2d(out_channels),
nn.ReLU(inplace=True)
)
def Conv1x1BNReLU(in_channels,out_channels,groups=1):
return nn.Sequential(
nn.Conv2d(in_channels=in_channels, out_channels=out_channels, kernel_size=1, stride=1,groups=groups),
nn.BatchNorm2d(out_channels),
nn.ReLU6(inplace=True)
)
class PyConv(nn.Module):
def __init__(self, in_channels, out_channels, kernel_sizes, groups, stride=1):
super(PyConv, self).__init__()
if out_channels is None:
out_channels = []
assert len(out_channels) == len(kernel_sizes) == len(groups)
self.pyconv_list = nn.ModuleList()
for i in range(len(kernel_sizes)):
self.pyconv_list.append(ConvBNReLU(in_channels=in_channels,out_channels=out_channels[i],kernel_size=kernel_sizes[i],stride=stride,groups=groups[i]))
def forward(self, x):
outputs = []
for pyconv in self.pyconv_list:
outputs.append(pyconv(x))
return torch.cat(outputs, 1)
3 应用
3-1 PyConv Networks for Image Classification
将PyConv嵌入到Bottleneck中,提出两种PyConvResNet与PyConvHGResNet结构

3-2 PyConv Network on Semantic Segmentation
PyConvPH。PyConvPH包含三个主要成分:
- Local PyConv Block:用于小目标并进行多尺度细粒度特征提取
- Global PyConv Block:用于捕获场景的全局信息以及大尺度目标
- Merge PyConv Block:对全局与局部特征融合

class LocalPyConv(nn.Module):
def __init__(self, planes):
super(LocalPyConv, self).__init__()
inplanes = planes//4
self._reduce = Conv1x1BNReLU(planes, 512)
self._pyConv = PyConv(in_channels=512, out_channels=[inplanes, inplanes, inplanes, inplanes], kernel_sizes=[3, 5, 7, 9], groups=[1, 4, 8, 16])
self._combine = Conv1x1BNReLU(512, planes)
def forward(self, x):
return self._combine(self._pyConv(self._reduce(x)))
class GlobalPyConv(nn.Module):
def __init__(self, planes):
super(GlobalPyConv, self).__init__()
inplanes = planes // 4
self.global_pool = nn.AdaptiveAvgPool2d(output_size=9)
self._reduce = Conv1x1BNReLU(planes, 512)
self._pyConv = PyConv(in_channels=512, out_channels=[inplanes, inplanes, inplanes, inplanes],
kernel_sizes=[3, 5, 7, 9], groups=[1, 4, 8, 16])
self._fuse = Conv1x1BNReLU(512, 512)
def forward(self, x):
b,c,w,h = x.shape
x = self._fuse(self._pyConv(self._reduce(self.global_pool(x))))
out = F.interpolate(x,(w,h),align_corners=True,mode='bilinear')
return out
class MergePyConv(nn.Module):
def __init__(self, img_size,in_channels, num_classes):
super(MergePyConv, self).__init__()
self.img_size = img_size
self.conv3 = ConvBNReLU(in_channels=in_channels,out_channels=256,kernel_size=3,stride=1)
self.conv1 = nn.Conv2d(in_channels=256, out_channels=num_classes, kernel_size=1, stride=1,groups=1)
def forward(self, x):
x = self.conv3(x)
x = F.interpolate(x, self.img_size, align_corners=True,mode='bilinear')
out = self.conv1(x)
return out
class PyConvParsingHead(nn.Module):
def __init__(self, img_size=(473,473), planes=512,num_classes=150):
super(PyConvParsingHead, self).__init__()
self.globalPyConv = GlobalPyConv(planes=planes)
self.localPyConv = LocalPyConv(planes=planes)
self.mergePyConv = MergePyConv(img_size,1024, num_classes)
def forward(self, x):
g_x = self.globalPyConv(x)
l_x = self.localPyConv(x)
x = torch.cat([g_x,l_x],dim=1)
out = self.mergePyConv(x)
return out
3-3 PyConv Network on Object Detection
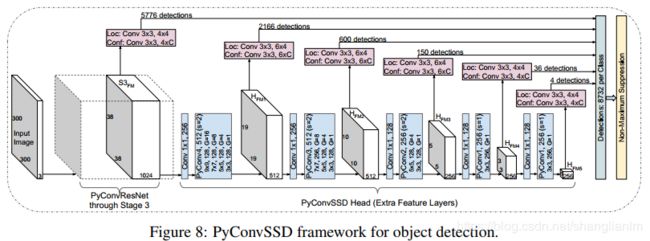
class PyConv4(nn.Module):
def __init__(self, inplaces, places, kernel_sizes=[3, 5, 7, 9], groups=[1, 4, 8, 16], stride=2):
super(PyConv4, self).__init__()
assert len(kernel_sizes) == len(groups)
out_channels = [places//4, places//4, places//4, places//4]
self.pyconv_list = nn.ModuleList()
for i in range(len(kernel_sizes)):
self.pyconv_list.append(ConvBNReLU(in_channels=inplaces,out_channels=out_channels[i],kernel_size=kernel_sizes[i],stride=stride,groups=groups[i]))
def forward(self, x):
outputs = []
for pyconv in self.pyconv_list:
outputs.append(pyconv(x))
return torch.cat(outputs, 1)
class PyConv3(nn.Module):
def __init__(self, inplaces,places, kernel_sizes=[3, 5, 7], groups=[1, 4, 8], stride=2):
super(PyConv3, self).__init__()
assert len(kernel_sizes) == len(groups)
out_channels = [places // 4, places // 4, places // 2]
self.pyconv_list = nn.ModuleList()
for i in range(len(kernel_sizes)):
self.pyconv_list.append(ConvBNReLU(in_channels=inplaces,out_channels=out_channels[i],kernel_size=kernel_sizes[i],stride=stride,groups=groups[i]))
def forward(self, x):
outputs = []
for pyconv in self.pyconv_list:
outputs.append(pyconv(x))
return torch.cat(outputs, 1)
class PyConv2(nn.Module):
def __init__(self, inplaces,places, kernel_sizes=[3, 5], groups=[1, 4], stride=2):
super(PyConv2, self).__init__()
assert len(kernel_sizes) == len(groups)
out_channels = [places // 2, places // 2]
self.pyconv_list = nn.ModuleList()
for i in range(len(kernel_sizes)):
self.pyconv_list.append(ConvBNReLU(in_channels=inplaces,out_channels=out_channels[i],kernel_size=kernel_sizes[i],stride=stride,groups=groups[i]))
def forward(self, x):
outputs = []
for pyconv in self.pyconv_list:
outputs.append(pyconv(x))
return torch.cat(outputs, 1)
class PyConv1(nn.Module):
def __init__(self, inplaces,places, kernel_sizes, groups, stride=1):
super(PyConv1, self).__init__()
assert len(kernel_sizes) == len(groups)
self.pyconv = ConvBNReLU(in_channels=inplaces,out_channels=places,kernel_size=3,stride=stride,groups=1)
def forward(self, x):
return self.pyconv(x)
3-4 PyConv Network on Video Classification
