最适合物联网应用的开源数据库
术语“物联网”指的是:(i)通过互联网技术互联的智能对象的全球网络,(ii)实现这一点所需的一组支持技术,即RFID,传感器, 机器通信设备,以及(iii)利用这些技术开发新的业务和营销机会的应用和服务集合。
根据Gartner的报告,2017年全球将有84亿个互联设备投入使用。物联网呈现出高度新颖的挑战,特别是对数据库管理系统的挑战,如实时集成大量庞大的数据,将事件处理为他们流,并处理数据的安全性。一个例子就是安装在智能城市中的基于物联网的环境温度传感器,它可以在几分钟内产生大量关于活跃大气温度和湿度的数据。
为了有效处理物联网数据,找到合适的数据库非常重要。但是,物联网应用选择高效的数据库可能非常具有挑战性,因为物联网环境并不总是相同的。在为物联网应用选择数据库时,需要牢记许多因素。其中最重要的是可扩展性,以足够的速度处理大量数据的能力,灵活的模式,可移植性以及各种分析工具,安全性和成本。
物联网数据库应具有容错能力和高可用性。如果数据库集群中的任何节点出现故障,它仍应能够接受读取和写入请求。分布式数据库创建数据的多个副本或副本,并将数据写入多个服务器。如果任何存储数据的服务器失败,则其他服务器接管存储并响应该查询的任务,直到失败的服务器启动。物联网数据库应该具有高度的可用性,因为物联网数据库处理系统可能面临高度庞大的写入和存储。如果任何数据库服务器关闭或实时分布式数据库的数据写入过高,则可以将数据存储在消息传递系统中,直到数据库处理数据积压或添加到主数据库集群的任何其他服务器。
以下是一些可用于基于IoT的应用程序的顶级开放源代码数据库。
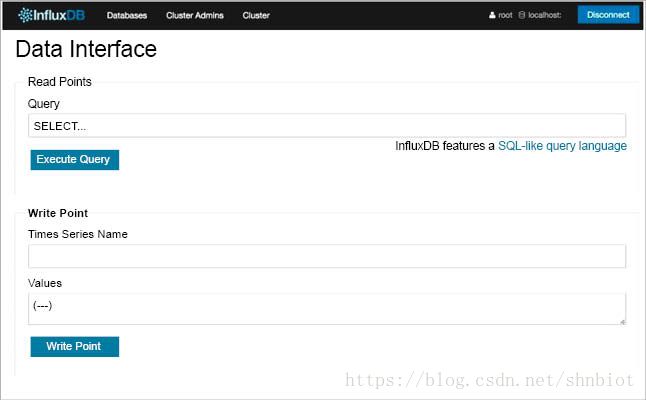
InfluxDBInfluxDB是由InfluxData开发的开源分布式时间序列数据库。它是用Go编程语言编写的,基于KeyDB数据库LevelDB。除了前端之外,HTTP接口和库还提供给用户进行数据库交互。 InfluxDB的主要优势在于它可以实时汇总时间段中的值,而无需任何手动干预。
InfluxDB可以通过像Grafana这样的软件来访问,Grafana是一个功能强大的前端工具,可以为时间序列数据提供可视化功能。 InfluxDB没有外部依赖关系,SQL查询用于查询包含度量,系列和点的数据结构。每个点由不同的键值对组成,称为fieldset和timestamp。值可以是64位整数,64位浮点,字符串和布尔值。点按其时间和标记集进行索引。 InfluxDB通过HTTP,TCP和UDP存储数据。
特征
- 纯粹用Go编程语言编写,便于将其编译为单个二进制文件,而无需外部依赖。
- 高性能的定制数据存储,专为时间序列数据编写。 InfluxDB的TSM引擎允许高效和高速的数据存储和压缩。
- 插件支持其他数据摄入协议,如Graphite,collectd,OpenTSDB。
- 用于数据库和用户管理的内置Web前端工具。
- 有能力将多个系列合并在一起。
最新版本:1.5.3
CrateDB
CrateDB是由Crate.io Inc.开发的开源分布式SQL数据库管理系统,它完全集成了一个可搜索的面向文档的数据存储。 Crate.io首席执行官Christian Lutz表示:“当我们创建Crate.io时,我们着手为机器数据时代重塑SQL。今天,我们75%的客户使用CrateDB管理机器和物联网,因为它的易用性,性能和多功能性。“
CrateDB使机器数据应用程序可以被SQL开发人员访问;在此之前,这些只能使用NoSQL解决方案。 CrateDB将SQL与搜索的多功能性以及易于扩展的容器相结合。它为分析数据存储工具(如Splunk)提供了一个很好的选择。 CrateDB平台包括分布式SQL查询引擎,用于提供更快的连接,聚合和即席查询;具有集成搜索数据和查询多功能性的SQL;容器架构和自动数据分片以实现简单的缩放。
CrateDB使用的主要语言是SQL,但它也使用NoSQL样式数据库的面向文档的方法。它使用Facebook Presto的SQL解析器进行查询和预测分析。它包含一个内置的管理界面。 Crate Shell CLI允许用户放置交互式SQL查询。
特征
- 高度可扩展性:对数据库的更新非常简单,只需添加新机器即可更新群集;由于CrateDB会自动完成数据集群中的任何重新分配,因此无需进行任何重新分配。
- 高可用性:CrateDB允许数据库在出现问题时高度可用,因为它提供了跨群集自动复制数据;即使硬件和软件更新也不会中断正常的数据操作。 CrateDB具有自我修复受感染节点的能力。
- 实时数据提取:即使正在进行写操作,CrateDB也能提供毫秒级的速度查询性能,并消除锁定开销。
- 支持各种数据:CrateDB支持关系和JSON文档。它还提供blob存储来存储和检索视频,图片或其他非结构化文件。
- 它支持地理空间查询和动态模式,使CrateDB非常灵活,这对后端的基于敏捷的开发和物联网数据库存储非常有用。
最新版本:2.3.11
Riak时间序列数据库(Riak time series database)
Basho的Riak时间序列(TS)数据库是一个开源的分布式NoSQL键值存储优化数据库,用于物联网(IoT)。有了这个数据库,用户可以将大量数据点与特定时间点相关联。它基于无主架构,其中群集中的每个节点都能够提供读取和写入请求;分布式数据库会自动在集群中共同定位,复制和分发数据,以实现高性能和可用性。
Riak TS数据库针对数据访问需求进行了高度优化。它支持Apache Spark集成,从而可以为Spark流,数据框和Spark SQL提供集成支持。
Riak TS可以直接安装在数据中心或公共云上。 AWS亚马逊机器映像(AMI)也可用于此数据库,以方便用户体验AWS工作区中的Riak TS。
特征
- 支持在不分片的情况下向现有集群架构添加新节点;数据在数据库集群中自动均匀地分布。
- 支持表格和字段定义的DDL或数据定义语言,并支持结构化和半结构化数据的存储。
- 支持多集群复制,这有助于系统管理员通过内部数据中心和全球任何地理位置数据中心复制数据。
- 支持用户轻松灵活地访问全局数据库的类SQL数据查询。
- 支持与Java,Ruby,Python,Erlang,Go,Node.js和.NET等各种语言的API和客户端库的应用程序集成。
- Riak Meso框架为RIAK节点提供高效的集群资源管理和“按钮”放大/缩小。
- 支持与Apache Spark的完全集成,以便对时间序列数据进行操作分析。
Supported Operating Systems
- CentOS 6
- CentOS 7
- RHEL 6
- RHEL 7
- Ubuntu 14.04 (Trusty)
- Ubuntu 16.04 (Xenial)
- Debian 7 “Wheezy” (development only)
- Debian 8 “Jessie”
- OS X 10.11+ (development only)
- Amazon Linux 2016.09
官方网站:http://basho.com/products/riak-ts/
最新版本:1.5.2
MongoDB
MongoDB是一个功能强大,灵活,免费且开源,面向文档,可扩展和通用的数据库。它可以扩展二级索引,范围查询,排序,聚合和地理空间索引等功能。它被归类为NoSQL数据库,因为它使用类似JSON的文档和模式。
MongoDB为文档添加了动态填充,并预先分配数据文件来交换额外的空间使用量以实现一致的性能。它有效地利用RAM来缓存和纠正索引查询。 MongoDB支持丰富的查询语言,以支持读写操作(CRUD)以及数据聚合,文本搜索和地理空间查询。
特征
- 支持各种快速查询的通用二级索引,并为用户提供独特的复合,地理空间和全文索引功能。
- 支持'聚合管道'从简单的部分构建复杂的聚合以优化数据库。
- 支持TTL(生存时间)集合,用于在一段时间后过期的数据。
- 支持易于使用的协议,用于存储大型文件和元数据文件。
- 支持JSON来存储和传输信息。作为标准协议的JSON对于Web和数据库都是非常有利的。
- 支持使用JavaScript函数进行信息处理的服务器端的Map-Reduce。
- 支持MongoDB管理服务(MMS)工具,允许用户跟踪数据库和备份数据。
- 由于数据放置在分片中,因此支持自动负载平衡配置。
Cloud Available on AWS, Azure, and Google Cloud Platform
官方网站:https://www.mongodb.com/
最新版本:4.0
RethinkDB
RethinkDB是一个开源的分布式数据库,主要用于存储JSON文档;它具有扩展到多台机器的能力。 RethinkDB被视为开发人员(尤其是基于物联网的开发人员)提供实时数据的首选和最重要的选择。它通过调用一个新的访问模型实时地将查询结果更新到应用程序,彻底改变了传统的数据库体系结构。 RethinkDB为监控API提供了一种灵活的查询语言,并且非常容易设置和学习。
RethinkDB比MongoDB提供了许多优点。这些是:
- 高级查询语言,支持表连接,子查询和大规模并行分布式计算。
- 一个优雅而强大的操作和监视API,与查询语言集成在一起,并且使RethinkDB的缩放更加容易。
- 一个简单而美观的管理用户界面,可让您在几次点击中进行分片和复制,并提供在线文档和查询语言建议。
- 容错:如果主服务器发生故障,它支持自动切换到新的服务器。
- 轻松添加节点:实时即插即用节点,即使是一秒钟也不会停机。
- 异步应用程序编程接口:通过Ruby和Tornado中的Eventmachine支持异步查询。
- 支持SSL访问,通过公共互联网安全访问RethinkDB。
- 更多功能:支持各种数学运算符,如楼层,小区和圆形。
最新版本:2.3.6

SQLite是一个开源和嵌入式的关系数据库,旨在为应用程序提供一种简单的方式来管理数据,而不会产生开销。它非常便携,易于使用,结构紧凑,高效可靠。
SQLite是ACID兼容的;它实现了大多数SQL标准,并使用动态和弱类型的SQL语法。 SQLite引擎不像其他数据库那样是独立的进程;它可以链接到静态以及动态应用程序。
特征- 不需要单独的服务器进程或系统来运行,并且可以在无服务器环境中运行。
- 不需要任何系统管理,并且需要低配置的机器来建立。
- 自包含并且没有外部依赖性。
- 用ANSI-C编写,提供简单易用的API。
- 跨平台:兼容UNIX,LINUX,Windows,MAC-OS x等。
- 事务完全兼容ACID,允许从多个进程安全访问。
- 支持SQL92中的所有SQL查询。
- SQLite中经过充分测试和验证的代码,无错误且始终保持最新。
最新版本:3.24.0
Apache Cassandra
Apache Cassandra被认为是一个高度可扩展的分布式开源数据库,用于管理大量商品服务器上的大量结构化数据。与其他开源数据库相比,Cassandra在可用性,线性扩展性能,简单性以及在多个数据库服务器间轻松分发数据方面提供了各种其他高性能功能。
Cassandra由Facebook开发,其主要动机是促进Inbox搜索,并于2008年成为开源软件。它实现了没有单点故障的'Dynamo-style复制模型',并添加了更强大的'列族'数据模型。
特征
- 大规模可扩展的架构:Cassandra拥有无主设计,所有节点都处于同一级别,这提供了操作简单性和轻松扩展。
- 无主架构:可以在任何节点上写入和读取数据。
- 线性缩放性能:随着更多节点的添加,Cassandra的性能也随之增加。
- 故障检测和恢复:可以轻松恢复和恢复失败的节点。
- 灵活和动态的数据模型:支持快速写入和读取的数据类型。
- 数据保护:数据受到提交日志设计和内置安全性(如备份和恢复机制)的保护。
- 可调数据一致性:支持跨分布式架构的强大数据一致性。
- 多数据中心复制:Cassandra提供了跨多个数据中心复制数据的功能。
- 数据压缩:Cassandra可以压缩多达80%的数据,无需任何开销。
- Cassandra查询语言:Cassandra提供了一种类似于SQL语言的查询语言。
- 这使得开发人员从关系数据库转移到Cassandra非常容易使用它。
最新版本:3.11.2