1.自然语言处理(NLP)与Python
自然语言工具包(NLTK)
NLTK 创建于 2001 年,最初是宾州大学计算机与信息科学系计算语言学课程的一部分 。从那以后,在数十名贡献者的帮助下不断发展壮大。如今,它已被几十所大学的课程所采纳 ,并作为许多研究项目的基础。NLTK模块及功能介绍如下:
| 语言处理任务 | NLTK模块 | 功能描述 |
|---|---|---|
| 获取语料库 | nltk.corpus | 语料库和词汇的标准化接口 |
| 字符串处理 | nltk.tokenize, nltk.stem | 分词器,句子分解提取主干 |
| 搭配发现 | nltk.collocations | t-检验,卡方,点互信息(PMI) |
| 词性标识符 | nltk.tag | n-gram,backoff,Brill,HMM,TnT |
| 分类 | nltk.classify, nltk.cluster | 决策树,最大熵,贝叶斯,EM,k-means |
| 分块 | nltk.chunk | 正则表达式,n-gram,命名实体 |
| 解析 | nltk.parse | 图表,基于特征,一致性,概率,依赖 |
| 语义解释 | nltk.sem, nltk.inference | λ演算,一阶逻辑,模型检验 |
| 指标评测 | nltk.metrics | 精度,召回率,协议系数 |
| 概率与估计 | nltk.probability | 频率分布,平滑概率分布 |
| 应用 | nltk.app, nltk.chat | 图形化的关键词排序,分析器,WordNet查看器,聊天机器人 |
| 语言学领域的工作 | nltk.toolbox | 处理 SIL工具箱格式的数据 |
NLTK设计中4个主要目标:
1、简易性:提供一个直观的框架以及大量的模块,使用户获取 NLP 知识而不必陷入像标注语言数据那样繁琐的事务中。
2、一致性:提供一个具有一致的接口和数据结构并且方法名称容易被猜到的统一的框架。
3、可扩展性:提供一种结构,新的软件模块包括同一个任务中的不同的实现和相互冲突的方法都可以方便添加进来。
4、模块化:提供可以独立使用而与工具包的其他部分无关的组件。
NLTK入门
首先应该安装 NLTk。可以从 http://www.nltk.org/免费下载。按照说明下载适合你的操作系统的版本。
安装完 NLTK 之后,启动 Python 解释器。在 Python 提示符后面输入下面两个命令来安装本书所需的数据,然后选择 book进行下载。(我的Python版本是3.5.1)
>>>import nltk
>>>nltk.download()此时会出现下载界面(我的已近下载完毕):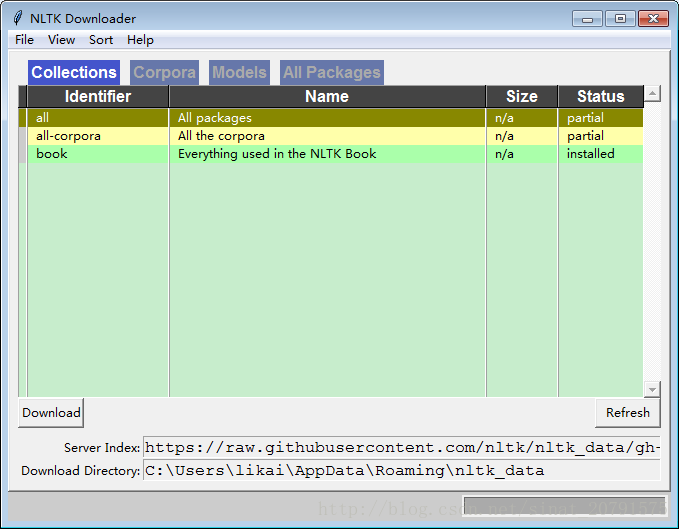
然后从nltk的book模块加载所有东西:
>>>from nltk.book import *
*** Introductory Examples for the NLTK Book ***
Loading text1, ..., text9 and sent1, ..., sent9
Type the name of the text or sentence to view it.
Type: 'texts()' or 'sents()' to list the materials.
text1: Moby Dick by Herman Melville 1851
text2: Sense and Sensibility by Jane Austen 1811
text3: The Book of Genesis
text4: Inaugural Address Corpus
text5: Chat Corpus
text6: Monty Python and the Holy Grail
text7: Wall Street Journal
text8: Personals Corpus
text9: The Man Who Was Thursday by G . K . Chesterton 1908任何时候我们想要找到这些文本,只需要在 Python 提示符后输入它们的名字。
>>> text1
<Text: Moby Dick by Herman Melville 1851>
>>> text2
<Text: Sense and Sensibility by Jane Austen 1811>搜索文本
我们输入 text1 后面跟一个点,再输入函数名 concordance,然后将 monstrous放在括号里,来查一下《白鲸记》中的词monstrous :

concordance使我们看到词的上下文。例如:我们看到 monstrous 出现的上下文,如 the___ pictures 和 a___ size 。还有哪些词出现在相似的上下文中?我们可以通过在被查询的文本名后添加函数名 similar,然后在括号中插入相关的词来查找到。
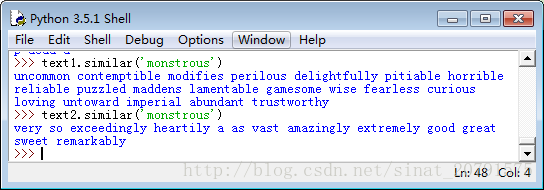
函数common_contexts允许我们研究两个或两个以上的词共同的上下文,如 monstrous 和 very 。我们必须用方括号和圆括号把这些词括起来,中间用逗号分割。
>>> text2.common_contexts(["monstrous", "very"])
be_glad am_glad a_pretty is_pretty a_lucky我们也可以判断词在文本中的位置:从文本开头算起在它前面有多少词。这个位置信息可以用 离散图表示。每一个竖线代表一个单词,每一行代表整个文本。
>>> text4.dispersion_plot(["citizens", "democracy", "freedom", "duties", "America"])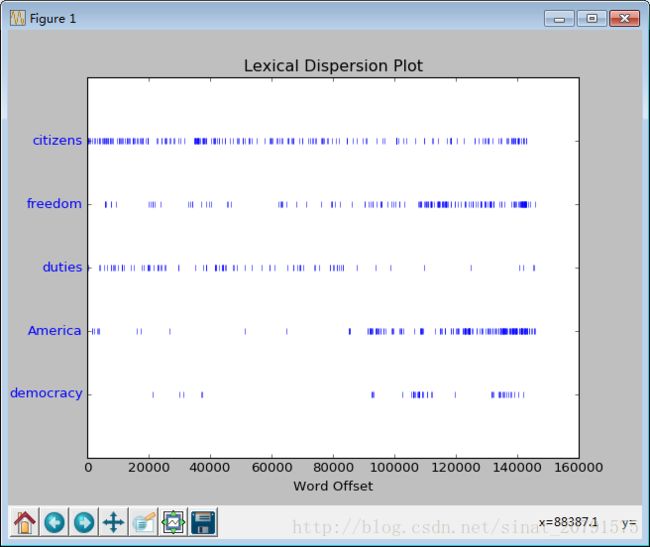
计数词汇
我们使用函数 len 获取长度,请看在《创世纪》中使用的例子:
>>> len(text3)
44764《创世纪》有 44764 个词和标点符号或者叫“标识符”。这样重复出现的词汇或标点也会被计入在内。
《创世纪》中有多少不同的词?要用 Python 来回答这个问题,我们处理问题的方法将稍有改变 。一个文本词汇表只是它用到的标识符的集合,因为在集合中所有重复的元素都只算一个。
>>> sorted(set(text3))
['!', "'", '(', ')', ',', ',)', '.', '.)', ':', ';', ';)', '?', '?)','A', 'Abel', 'Abelmizraim', 'Abidah', 'Abide', 'Abimael', 'Abimelech','Abr', 'Abrah', 'Abraham', 'Abram', 'Accad', 'Achbor', 'Adah', ...]
>>> len(set(text3))
2789
>>>用 sorted()包裹起 Python 表达式 set(text3),我们得到一个词汇项的排序表,这个表以各种标点符号开始,然后是以 A 开头的词汇。大写单词排在小写单词前面。我们通过求集合中项目的个数间接获得词汇表的大小。再次使用 len 来获得这个数值。
现在,让我们对文本词汇丰富度进行测量。下一个例子向我们展示了每个字平均被使用
了 16 次(我们需要确保 Python 使用的是浮点除法):
>>> len(text3) / len(set(text3))
16.050197203298673
>>>接下来,让我们专注于特定的词。计数一个词在文本中出现的次数,计算一个特定的词在文本中占据的百分比。
>>> text3.count("smote")
5
>>> 100 * text4.count('a') / len(text4)
1.4643016433938312频率分布(Frequency Distributions)
让我们使用 FreqDist 寻找《白鲸记》中最常见的 50 个词:
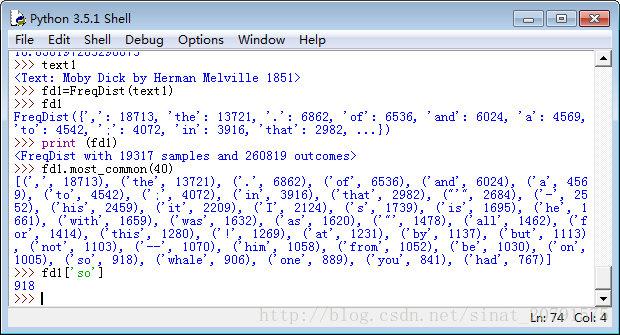
第一次调用 FreqDist 时,传递文本的名称作为参数。我们可以看到已经被计算出来的《白鲸记》中的总的词数(“结果”)——高达 260,819。
我们可以产生一个这些词汇的累积频率图,使用 fd1.plot(50, cumulative=True):
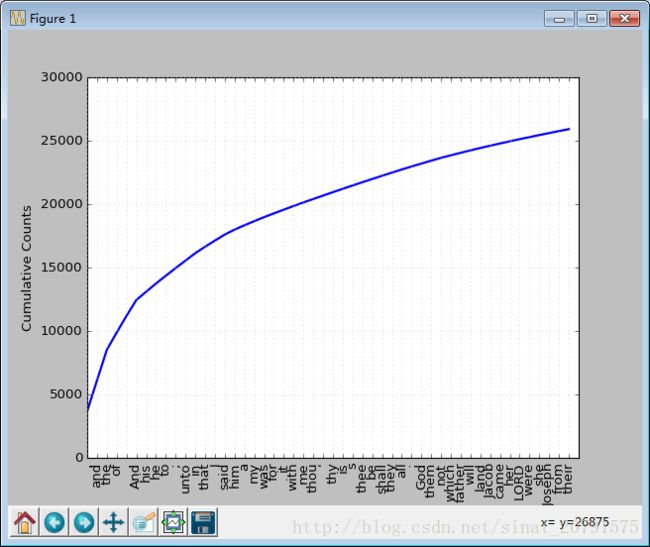
如果高频词对我们没有帮助,那些只出现了一次的词(所谓的 hapaxes)输入 fdist1.hapaxes()查看它们。
细粒度的词语选择(Fine-grained Selection of Words)
以下是聊天语料库中所有长度超过7 个字符出现次数超过 7 次的词:
>>> fdist5 = FreqDist(text5)
>>> sorted([w for w in set(text5) if len(w) > 7 and fdist5[w] > 7])
['#14-19teens', '#talkcity_adults', '((((((((((', '........', 'Question','actually', 'anything', 'computer', 'cute.-ass', 'everyone', 'football','innocent', 'listening', 'remember', 'seriously', 'something', 'together','tomorrow', 'watching']词语搭配和双连词(Collocations and Bigrams)
一个搭配是经常在一起出现的词序列。 red wine 是一个搭配而 the wine 不是 。collocations()函数为我们做这些:

NLTK频率分布类中定义的函数
| 例子 | 描述 |
|---|---|
| fdist = FreqDist(samples) | 创建包含给定样本的频率分布 |
| fdist.inc(sample) | 增加样本 |
| fdist[‘monstrous’] | 计数给定样本出现的次数 |
| fdist.freq(‘monstrous’) | 给定样本的频率 |
| fdist.N() | 样本总数 |
| fdist.most_common(n) | 前n个最长出现的样本以及它们的频率 |
| for sample in fdist: | 遍历样本 |
| fdist.max() | 数值最大的样本 |
| fdist.tabulate() | 绘制频率分布表 |
| fdist.plot() | 绘制频率分布图 |
| fdist.plot(cumulative=True) | 绘制累积频率分布图 |
| fdist1 < fdist2 | 测试样本在 fdist1 中出现的频率是否小于 fdist2 |