Pytorch深度学习框架YOLOv3目标检测学习笔记(一)——YOLOv3原理详解
准备知识
源码链接YOLOv3pytorch实现
需要了解CNN工作原理,包括残差块,跳跃连接,上采样
什么是目标检测、边界框回归IoU和非最大抑制
基础pytorch语法,可以轻松创建神经网络
全卷积神经网络
YOLOv3全部由卷积层组成,简称FCN,有跳跃层和上采样层连接的75个卷积层。YOLOv3没有使用池化层,而使用一层步长为2的卷积层来帮助下采样,帮助我们避免池化带来的低级特征损失
网络下采样通常通过设置网络的步长进行,例如我们的网络的步长为32,输入的图像416x416会变成大小13x13
预测输出
目标检测通常来讲,学习卷积层得到的特征通过分类器或者回归器来做预测,配合着边界框和分类标签
在YOLO中,卷积层用1*1卷积核来预测。
现在,输出是功能图,因为我们用了1*1卷积核,预测图的大小就是特征图的大小,在YOLOv3中每个单元可以预测一个边界框的固定数据,可以达到预测图的目的。
深度方向,我们在特征图中有有(B*(5+C))个通道,B代表每个单元可以预测的边界框的数量,每个边界框能特殊地检测一种物体,每个边界框有5+C个属性,用来描述中心坐标,维度和目标分数和每个锚框的C类权值,YOLOv3给每个单元预设三种锚框。
如果物体中心落到某个单元的可接收区域内,就可以通过这个单元的一个锚框来预测物体(接受区域是输入图像的可视化单元)任何给定的物体只有一个锚框负责检测,首先,我们必须确认锚框属于哪个单元。
为此,我们将输入图片放入和输出特征图同样大小的网格中。
例如,当输入416×416,网络步长32,输出特征图为13x13,将输入图片分成13x13个单元
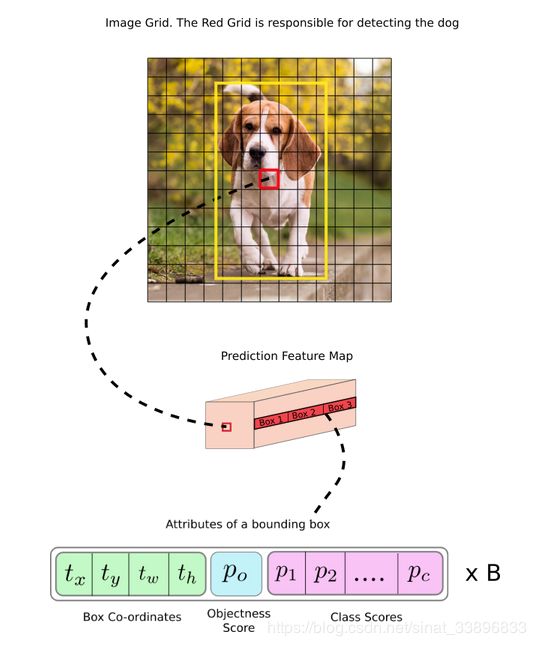
之后,输入图像中包含真实框中心的网格被选为物体的预测。在图像中,被标记为红的网格,包含真实盒的中心。
红色单元是特征图的7行7列。
这个网格可以用来预测三个边界框,哪一个是真的狗的标签,我们必须引出锚点的概念
我们将输入图形分成网格是想要确认可以预测的特征图的网格是哪个。
锚框
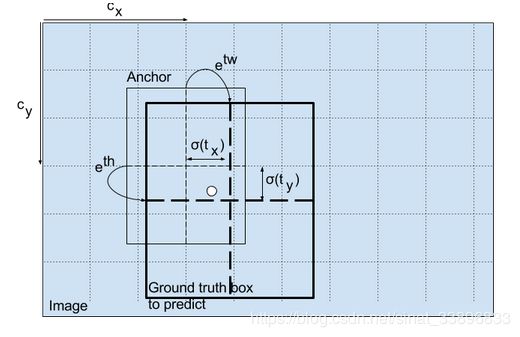
预设边界框的宽和高可能行得通,但实际上,在训练中,这样会导致不稳定的梯度。大多数目标检测预设了大空间的变换,或仅仅预定义默认框的偏置叫做锚点
这些变形被应用到锚框中来预测。YOLOv3有三个锚点,导致每个网格有三种预测。
锚框用来检测狗看哪个锚框和真实框有最高的IoU
预测
bx, by, bw, bh 是我们预测的中心坐标,宽和高。 tx, ty, tw, th 是网络输出。cx、cy是网格左上角的坐标. pw、ph是框的维度
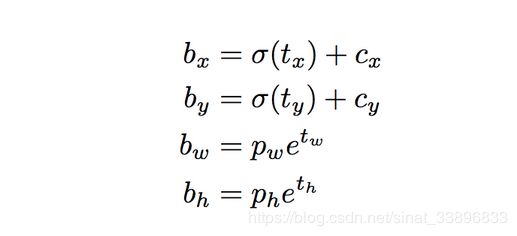
结果预测,bw和bh被图像的高和宽标准化(训练的标签这样选择),所以如果预测的bx和by包含狗的概率为(0.3,0.8),真实的宽和高在13*13的特征图上是13x0.3,13x0.8
目标得分
目标得分代表一个物体包含在锚点的可能性,在红色和其相邻的网格接近1,在角落的格有可能是0
目标得分也要经过sigmoid激活函数,以便作为概率使用
不同尺度的预测
YOLOv3通过3个不同尺度做出预测,检测层用三种不同大小特征图,有32,16,8三种步长,这意味着输入416×416我们可以在13×13,26×26,52×52的尺度下做出检测。

网络在遇到第一个检测层时对输入图像做下采样。
在每一个尺度,每一个单元预测三种边界框用三个锚框,得到9个锚框。
这样可以帮助更好识别小的物体,上采样帮助网络习得检测小物体的方法
输出过程
对于416×416图像,YOLO预测(52×52+26×26+13×13)=10647个锚框,但是对于我们的图像来说,这里只有一个物体,狗,我们怎么将10637转换成1。
目标得分的阈值
首先,我们根据目标置信度的筛选了锚框,通常得分低于阈值的锚框会被忽略
非最大抑制
非最大抑制想要解决同一张图片的多检测问题,例如,所有的红色格子的3个锚框可能检测到的是相同物体

工程实现
YOLOv3能够仅仅检测在网络中训练过的数据集,我们会用官方的权重文件来检测,权重是我们用COCO数据集训练得到的,可以用来检测80个物体名目。