Linux性能监控之vmstat和dstat
说来惭愧,做了这么久的性能测试,居然对linux的vmstat这个命令还不熟悉,对很多指标的具体意义都有点模糊不清,今天花了点时间好好学习、整理一下这个命令的相关资料。因为这个命令确实比较重要,而且频繁用到。顺便再介绍一下另一个更强大的工具dstat。
vmstat是Virtual Meomory Statistics(虚拟内存统计)的缩写,可对操作系统的虚拟内存、进程、IO读写、CPU活动等进行监视。它是对系统的整体情况进行统计,不足之处是无法对某个进程进行深入分析。
命令语法:
vmstat [-a] [-n] [-S unit] [delay [ count]]
vmstat [-s] [-n] [-S unit]
vmstat [-m] [-n] [delay [ count]]
vmstat [-d] [-n] [delay [ count]]
vmstat [-p disk partition] [-n] [delay [ count]]
vmstat [-f]
vmstat [-V]
命令参数:
不同版本Linux的cp命令参数有可能不同。不过默认应该都是[ delay [ count ] ] ,delay是间隔,count显示多少次信息。可以和上面的某些参数结合使用。
| 参数 |
英文描述 |
描叙 |
| delay |
|
刷新时间间隔。如果不指定,只显示一条结果。 |
| count |
|
刷新次数。如果不指定刷新次数,但指定了刷新时间间隔,这时刷新次数为无穷。 |
| -a |
The -a switch displays active/inactive memory, given a 2.5.41 kernel or better. |
开启显示active/inactive memory。 |
| -f |
The -f switch displays the number of forks since boot. This includes the fork, vfork, and clone system calls, and is equivalent to the total number of tasks created. Each process is represented by one or more tasks, depending on thread usage. This display does not repeat. |
显示此系统启动以来的forks的总数,包括fork、vfork和clone system calls |
| -m |
The -m displays slabinfo |
显示slabinfo信息 |
| -n |
The -n switch causes the header to be displayed only once rather than periodically. |
只显示头信息,不周期性显示.也就是说开启这个参数,只显示头部信息一次。 |
| -s |
The -s switch displays a table of various event counters and memory statistics. This display does not repeat. |
显示各种事件计数器表和内存统计信息,这显示不重复。 |
| -d |
The -d reports disk statistics (2.5.70 or above required) |
显示磁盘统计数据(内核要求2.5.70 或以上) |
| -w |
The -w enlarges field width for big memory sizes |
可以扩大字段长度,当内存较大时,默认长度不够完全展示内存。 |
| -p |
The -p followed by some partition name for detailed statistics (2.5.70 or above required) |
显示磁盘分区数据(disk partition statistics ) |
| -S |
The -S followed by k or K or m or M switches outputs between 1000, 1024, 1000000, or 1048576 bytes |
参数S控制输出性能指标的单位,k(1000) K(1024) 或 M(1048576) 默认单位为K(1024 bytes) |
| -V |
The -V switch results in displaying version information.
|
查看vmstat命令的版本 |
我们常用的示例是(每隔3秒刷新一次):
vmstat -n 3
vmstat -a 3
vmstat -w 3
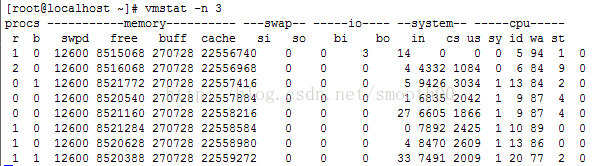
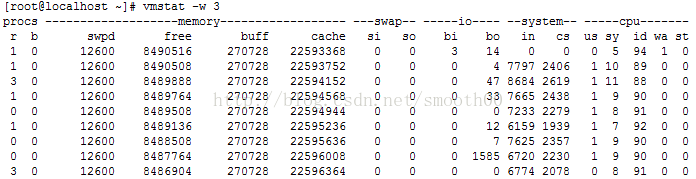
输出字段的意义:
这块是我一直也记不住的地方,所以特别整理了下面一张表,部分参考网上的说明,部分根据自己的理解进行补充。
| 输出列 |
输出列说明 |
输出列详细说明 |
| Procs |
||
| r |
The number of processes waiting for run time |
等待运行的进程数。如果等待运行的进程数越多,意味着CPU非常繁忙。另外,如果该参数长期大于和等于逻辑cpu个数,则CPU资源可能存在较大的瓶颈。 |
| b |
The number of processes in uninterruptible sleep |
处在非中断睡眠状态的进程数。意味着进程被阻塞。主要是指被资源阻塞的进程对列数(比如IO资源、页面调度等),当这个值较大时,需要根据应用程序来进行分析,比如数据库产品,中间件应用等。 |
| Memory |
||
| swpd |
the amount of virtual memory used |
已使用的虚拟内存大小。如果虚拟内存使用较多,可能系统的物理内存比较吃紧,需要采取合适的方式来减少物理内存的使用。swapd不为0,并不意味物理内存吃紧,如果swapd没变化,si、so的值长期为0,这也是没有问题的 |
| free |
the amount of idle memory |
空闲的物理内存的大小,free很小并不代表内存不足,这是linux的优越性,大量的buffers和cache也属于可用内存的一部分。 |
| buff |
the amount of memory used as buffers |
用来做buffer(缓存,主要用于块设备缓存)的内存数, 单位:KB |
| cache |
the amount of memory used as cache |
用来做cache(缓存,主要用于缓存文件)的内存, 单位:KB |
| inact |
the amount of inactive memory. |
inactive memory的总量(长时间未访问过的页面放进inactive list,该值大表明在必要时可以回收的页面很多) |
| active |
the amount of active memory. |
active memroy的总量(刚访问过的页面放进active list,无法马上回收,只能通过与文件或交换区进行页交换) |
| Swap |
||
| si |
Amount of memory swapped in from disk (/s) |
从磁盘交换到内存的交换页数量,单位:KB/秒。 |
| so |
Amount of memory swapped to disk (/s) |
从内存交换到磁盘的交换页数量,单位:KB/秒 |
| 内存够用的时候,这2个值都是0,如果这2个值长期大于0时,系统性能会受到影响,磁盘IO和CPU资源都会被消耗。当看到空闲内存(free)很少的或接近于0时,就认为内存不够用了,这个是不正确的。不能光看这一点,还要结合si和so,如果free很少,但是si和so也很少(大多时候是0),那么不用担心,系统性能这时不会受到影响的。 |
||
| 当内存的需求大于RAM的数量,服务器启动了虚拟内存机制,通过虚拟内存,可以将RAM段移到SWAP DISK的特殊磁盘段上,这样会 出现虚拟内存的页导出和页导入现象,页导出并不能说明RAM瓶颈,虚拟内存系统经常会对内存段进行页导出,但页导入操作就表明了服务器需要更多的内存了, 页导入需要从SWAP DISK上将内存段复制回RAM,导致服务器速度变慢。 |
||
| IO |
||
| bi |
Blocks received from a block device (blocks/s) |
每秒从块设备接收到的块数,单位:块/秒 也就是读块设备。 |
| bo |
Blocks sent to a block device (blocks/s) |
每秒发送到块设备的块数,单位:块/秒 也就是写块设备。 |
| System |
||
| in |
The number of interrupts per second, including the clock |
每秒的中断数,包括时钟中断。与cs一般同步增长。in和cs两值越大,会看到由内核消耗的CPU时间(sy)也会越大。 |
| cs |
The number of context switches per second |
每秒的环境(上下文)切换次数。比如我们调用系统函数,就要进行上下文切换,而过多的上下文切换会浪费较多的cpu资源,这个数值应该越小越好,如果太大了,要考虑调低线程或者进程的数目,例如apache和nginx这种web服务进程。 |
| CPU These are percentages of total CPU time. |
||
| us |
Time spent running non-kernel code.(user time, including nice time) |
用户CPU时间(非内核进程占用时间)(单位为百分比)。 us的值比较高时,说明用户进程消耗的CPU时间多。 |
| sy |
Time spent running kernel code. (system time) |
系统使用的CPU时间(单位为百分比)。sy的值高时,说明系统内核消耗的CPU资源多,这并不是良性表现,我们应该检查原因。 |
| id |
Time spent idle. Prior to Linux 2.5.41, this includes IO-wait time. |
空闲的CPU的时间(百分比),在Linux 2.5.41之前,这部分包含IO等待时间。 |
| wa |
Time spent waiting for IO. Prior to Linux 2.5.41, shown as zero. |
等待IO的CPU时间,在Linux 2.5.41之前,这个值为0 .这个指标意味着CPU在等待硬盘读写操作的时间,用百分比表示。wait越大则机器io性能就越差。说明IO等待比较严重,这可能由于磁盘大量作随机访问造成,也有可能磁盘出现瓶颈(块操作)。 |
| st |
Time stolen from a virtual machine |
针对虚拟技术,如果st不为0,说明本来分配给本机的CPU时间被其他虚拟机偷走了。 |
Vmstat是对系统的整体情况进行统计,不足之处是无法对某个进程进行深入分析,所以我们再引入另一个工具dstat。dstat是一个可以取代vmstat、iostat、netstat和ifstat这些命令的多功能产品。dstat克服了这些命令的局限并增加了一些功能和监控项,也变得更灵活了。dstat可以很方便监控系统运行状况并用于基准测试和排除故障。
特性:
- 结合了vmstat,iostat,ifstat,netstat以及更多的信息
- 实时显示统计情况
- 在分析和排障时可以通过启用监控项并排序
- 模块化设计
- 使用python编写的,更方便扩展现有的工作任务
- 容易扩展和添加你的计数器(请为此做出贡献)
- 包含的许多扩展插件充分说明了增加新的监控项目是很方便的
- 可以分组统计块设备/网络设备,并给出总数
- 可以显示每台设备的当前状态
- 极准确的时间精度,即便是系统负荷较高也不会延迟显示
- 显示准确地单位和和限制转换误差范围
- 用不同的颜色显示不同的单位
- 显示中间结果延时小于1秒
- 支持输出CSV格式报表,并能导入到Gnumeric和Excel以生成图形
安装方法:
Ubuntu/Mint和Debin系统:
# sudo apt-get install dstat
RHEL/Centos和Fedora系统:
# yum install dstat
ArchLinux系统:
# pacman -S dstat
使用方法:
dstat的基本用法就是输入dstat命令,输出如下: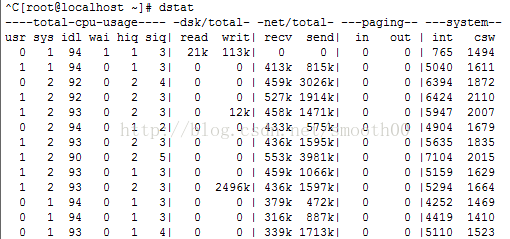
这是默认输出显示的信息:
CPU状态:CPU的使用率。这项报告更有趣的部分是显示了用户,系统和空闲部分,这更好地分析了CPU当前的使用状况。如果你看到"wait"一栏中,CPU的状态是一个高使用率值,那说明系统存在一些其它问题。当CPU的状态处在"waits"时,那是因为它正在等待I/O设备(例如内存,磁盘或者网络)的响应而且还没有收到。
磁盘统计:磁盘的读写操作,这一栏显示磁盘的读、写总数。
网络统计:网络设备发送和接受的数据,这一栏显示的网络收、发数据总数。
分页统计:系统的分页活动。分页指的是一种内存管理技术用于查找系统场景,一个较大的分页表明系统正在使用大量的交换空间,或者说内存非常分散,大多数情况下你都希望看到page in(换入)和page out(换出)的值是0 0。
系统统计:这一项显示的是中断(int)和上下文切换(csw)。这项统计仅在有比较基线时才有意义。这一栏中较高的统计值通常表示大量的进程造成拥塞,需要对CPU进行关注。你的服务器一般情况下都会运行运行一些程序,所以这项总是显示一些数值。
默认情况下,dstat每秒都会刷新数据。如果想退出dstat,你可以按"CTRL-C"键。
需要注意的是报告的第一行,通常这里所有的统计都不显示数值的。这是由于dstat会通过上一次的报告来给出一个总结,所以第一次运行时是没有平均值和总值的相关数据。
但是dstat可以通过传递2个参数运行来控制报告间隔和报告数量。例如,如果你想要dstat输出默认监控、报表输出的时间间隔为3秒钟,并且报表中输出10个结果,你可以运行如下命令:
dstat 3 10在dstat命令中有很多参数可选,你可以通过man dstat命令查看,大多数常用的参数有这些:
- -l :显示负载统计量
- -m :显示内存使用率(包括used,buffer,cache,free值)
- -r :显示I/O统计
- -s :显示交换分区使用情况
- -t :将当前时间显示在第一行
- –fs :显示文件系统统计数据(包括文件总数量和inodes值)
- –nocolor :不显示颜色(有时候有用)
- –socket :显示网络统计数据
- –tcp :显示常用的TCP统计
- –udp :显示监听的UDP接口及其当前用量的一些动态数据
- -–disk-util :显示某一时间磁盘的忙碌状况
- -–freespace :显示当前磁盘空间使用率
- -–proc-count :显示正在运行的程序数量
- -–top-bio :指出块I/O最大的进程
- -–top-cpu :图形化显示CPU占用最大的进程
- -–top-io :显示正常I/O最大的进程
- -–top-mem :显示占用最多内存的进程
举一个我常用的例子,显示哪些进程在占用IO、内存、CPU:
# dstat -l -m -r -c --top-io --top-mem --top-cpu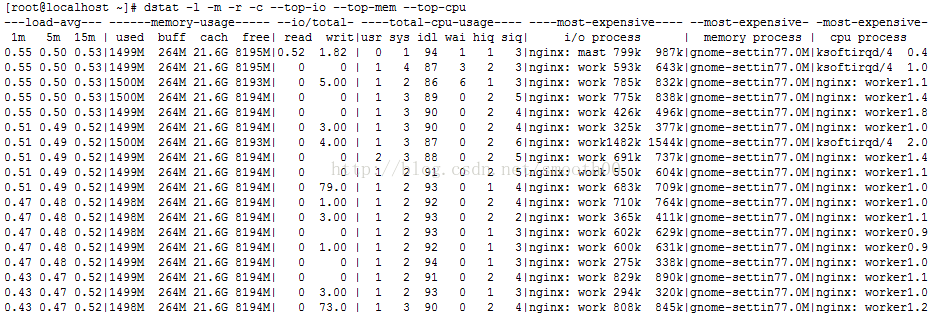
如何输出一个csv文件
想输出一个csv格式的文件用于以后,可以通过下面的命令:
# dstat –output /tmp/sampleoutput.csv -cdn