虚拟机搭建Hadoop集群(单机模式)
首先,请确保你已经安装了虚拟机,并安装配置了JAVA环境,需要这两方面教程的,请参考:
1、虚拟机, http://blog.csdn.net/uq_jin/article/details/51355124
2、JAVA, http://blog.csdn.net/uq_jin/article/details/51356799
下面开始在虚拟机上搭建单机模式的Hadoop集群。
一、下载Hadoop
下载地址为: http://apache.fayea.com/hadoop/common/
选择你要安装的Hadoop版本,下载到本地,楼主用的是Hadoop-2.6.4。
二、安装Hadoop
将下载下来的Hadoop压缩包上传至虚拟机根目录,并解压、重命名:
tar xzvf hadoop-2.6.4.tar.gz
mv hadoop-2.6.4 hadoop三、配置并启动Hadoop
1、修改hadoop/etc/hadoop/hadoop-env.sh中Java的安装路径JAVA_HOME
当配置了环境变量JAVA_HOME时,直接用“echo $JAVA_HOME”命令即可定位Java安装路径;
echo $JAVA_HOME但是如果没有配置环境变量JAVA_HOME,直接用“echo $JAVA_HOME”命令就定位不到Java安装路径,这时候需要用以下方法进行定位:
[root@localhost ~]# java -version
java version "1.8.0_181"
Java(TM) SE Runtime Environment (build 1.8.0_181-b13)
Java HotSpot(TM) 64-Bit Server VM (build 25.181-b13, mixed mode)
[root@localhost ~]# which java
/opt/java/jdk1.8.0_181/bin/java
[root@localhost ~]# ls -lrt /opt/java/jdk1.8.0_181/bin/java
-rwxr-xr-x. 1 10 143 7734 Jul 7 04:06 /opt/java/jdk1.8.0_181/bin/java知道了虚拟机中JAVA安装路径,便可将hadoop/etc/hadoop/hadoop-env.sh中的JAVA_HOME修改成对应安装路径(如下图所示,将①中JAVA_HOME修改成②中JAVA对应安装路径)

2、修改hdfs的配置文件hadoop/etc/hadoop/core-site.xml和hadoop/etc/hadoop/hdfs-site.xml
①修改配置文件hadoop/etc/hadoop/core-site.xml:
在hadoop/etc/hadoop/core-site.xml文件的configuration中加入下图中框内的内容

fs.defaultFS
hdfs://0.0.0.0:9000
hadoop.tmp.dir
/home/xupanpan/hadoop/temp
②修改配置文件hadoop/etc/hadoop/hdfs-site.xml:
在hadoop/etc/hadoop/hdfs-site.xml文件的configuration中加入下图中框内的内容

dfs.replication
2
3、hdfs的启动与停止
①hdfs第一次启动前需先格式化
/root/hadoop/bin/hdfs namenode -format
②启动hdfs
/root/hadoop/sbin/start-dfs.sh
启动之后,可以在浏览器里输入你的虚拟机地址加50070端口进行访问预览,楼主的虚拟机地址为192.168.1.224,故预览网址为:
http://192.168.1.224:50070/

当你不用hdfs时,可以把hdfs关闭掉:
/root/hadoop/sbin/stop-dfs.sh
4、HDFS shell的常用操作
①查看帮助
/root/hadoop/bin/hadoop fs -help②上传文件
/root/hadoop/bin/hadoop fs -put /root/hadoop/word.txt /
<hadoop可执行文件所在路径> fs -put <虚拟机上文件路径> <hdfs上文件保存路径>其余操作可根据查看帮助中的内容进行。
5、上传文件对hdfs进行测试
①新建一个test.txt文件:

②将test.txt文件上传至hdfs的根目录
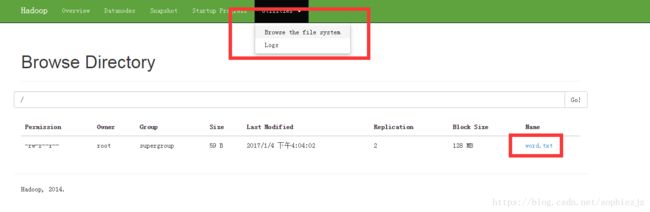
/root/hadoop/bin/hadoop fs -put /root/hadoop/test.txt /③在http://192.168.1.224:50070/中进行查看
四、YARN的配置、启动与停止
1、重命名并修改配置文件/root/hadoop/etc/hadoop/mapred-site.xml
mv /root/hadoop/etc/hadoop/mapred-site.xml.template /root/hadoop/etc/hadoop/mapred-site.xml
mapreduce.framework.name
yarn

2、修改配置文件/root/hadoop/etc/hadoop/yarn-site.xml
yarn.nodemanager.aux-services
mapreduce_shuffle

3、启动YARN
/root/hadoop/sbin/start-yarn.sh
启动之后,可以在浏览器里输入你的虚拟机地址加8088端口进行访问预览,楼主的虚拟机地址为192.168.1.224,故预览网址为:
http://192.168.1.224:8088/cluster

4、关闭YARN
/root/hadoop/sbin/stop-yarn.sh 
至此,虚拟机上的一个单机模式Hadoop集群便搭建好了,我们的MapperReduce将会在YARN上运行,并将结果存于HDFS上,我们可以通过用hadoop执行一个叫 hadoop-mapreduce-examples.jar 的 wordcount 方法,运行一个简单的MP程序来计算文本中的词频来进行测试,这里不再赘述。
参考:
http://hadoop.apache.org/docs/current/hadoop-project-dist/hadoop-common/SingleCluster.html