CRNN实现文本的识别测试
、自然场景文本提取是图像语义信息抽取的一个重要分支,它的实现需要CV和NLP技术,即既需要使用视觉处理技术来提取图像中文字区域的图像特征向量,又需要借助自然语言处理技术来解码图像特征向量为文字结果。
文本提取与识别技术是有着广泛的应用场景。已经被互联网公司落地的相关应用涉及了识别名片、识别菜单、识别快递单、识别身份证、识别营业证、识别银行卡、识别车牌、识别路牌、识别商品包装袋、识别会议白板、识别广告主干词、识别试卷、识别单据等等。
本博文主要针对目前较为流行的图文识别模型CRNN(Convolutional Recurrent Neural Network)进行学习和实验。该模型可识别较长的文本序列。它包含CNN特征提取层和BiLSTM序列特征提取层,能够进行端到端的联合训练。 它利用BiLSTM和CTC部件学习字符图像中的上下文关系, 从而有效提升文本识别准确率,使得模型更加鲁棒。预测过程中,前端使用标准的CNN网络提取文本图像的特征,利用BLSTM将特征向量进行融合以提取字符序列的上下文特征,然后得到每列特征的概率分布,最后通过转录层(CTC rule)进行预测得到文本序列。
1、论文原理
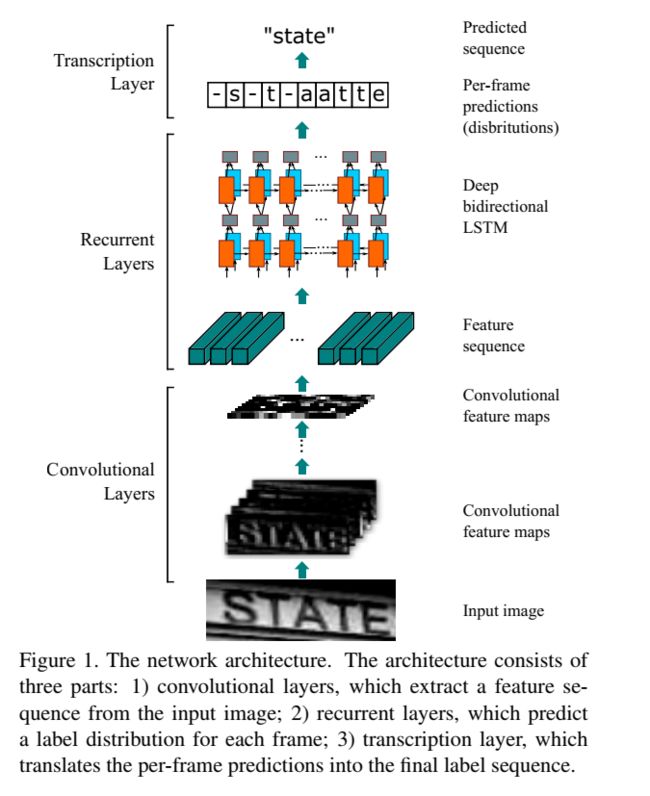
从上图可以看出,其为三层架构:
(1)CNN层来实现对图像的特征抽取;
(2)RNN层来实现对图像块的特征文字序列预测其真实的标签;
(3)转录层:把标签进行合并,生成结果。
其网络结构图如下所示:
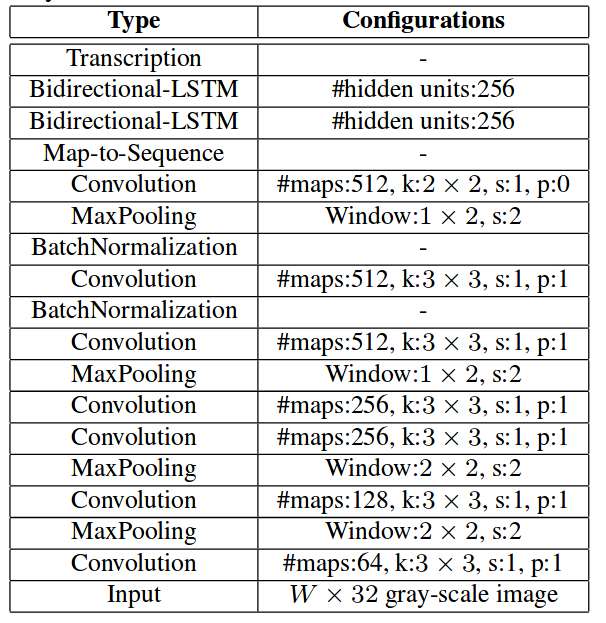
对应的其构建代码如下:
class CRNN(nn.Module):
def __init__(self, imgH, nc, nclass, nh, n_rnn=2, leakyRelu=False):
super(CRNN, self).__init__()
assert imgH % 16 == 0, 'imgH has to be a multiple of 16'
ks = [3, 3, 3, 3, 3, 3, 2]
ps = [1, 1, 1, 1, 1, 1, 0]
ss = [1, 1, 1, 1, 1, 1, 1]
nm = [64, 128, 256, 256, 512, 512, 512]
cnn = nn.Sequential()
def convRelu(i, batchNormalization=False):
nIn = nc if i == 0 else nm[i - 1]
nOut = nm[i]
cnn.add_module('conv{0}'.format(i),
nn.Conv2d(nIn, nOut, ks[i], ss[i], ps[i]))
if batchNormalization:
cnn.add_module('batchnorm{0}'.format(i), nn.BatchNorm2d(nOut))
if leakyRelu:
cnn.add_module('relu{0}'.format(i),
nn.LeakyReLU(0.2, inplace=True))
else:
cnn.add_module('relu{0}'.format(i), nn.ReLU(True))
convRelu(0)
cnn.add_module('pooling{0}'.format(0), nn.MaxPool2d(2, 2)) # 64x16x64
convRelu(1)
cnn.add_module('pooling{0}'.format(1), nn.MaxPool2d(2, 2)) # 128x8x32
convRelu(2, True)
convRelu(3)
cnn.add_module('pooling{0}'.format(2),
nn.MaxPool2d((2, 2), (2, 1), (0, 1))) # 256x4x16
convRelu(4, True)
convRelu(5)
cnn.add_module('pooling{0}'.format(3),
nn.MaxPool2d((2, 2), (2, 1), (0, 1))) # 512x2x16
convRelu(6, True) # 512x1x16
self.cnn = cnn
self.rnn = nn.Sequential(
BidirectionalLSTM(512, nh, nh),
BidirectionalLSTM(nh, nh, nclass))2、实验环节,采用CRNN_pytorch来实现。
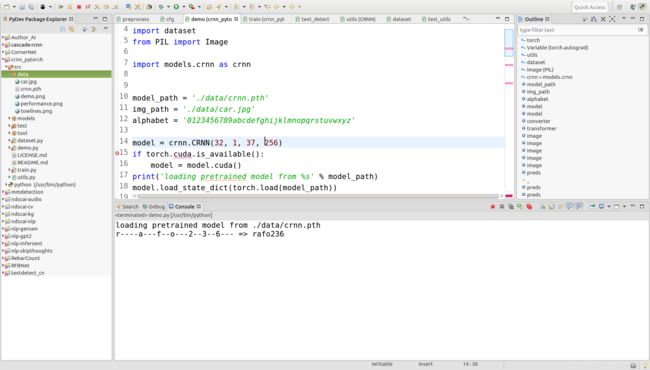
(1)https://github.com/meijieru/crnn.pytorch,参照网址程序进行复现的效果。
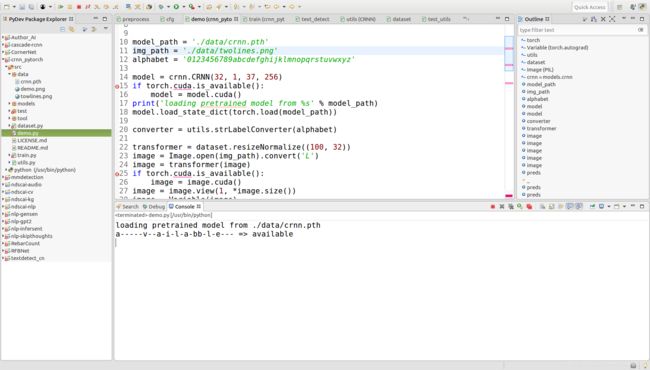
(2)换了个英文单词,进行训练后的效果如图所示:结果正确。

(3)换了个汽车号码牌,由于混合了汉字,原来训练的不包含汉字的识别,因此在识别过程中第一个字母有误。