台湾大学深度学习课程 学习笔记 lecture3-2 Recursive Neural Network(RvNN)
以下内容和图片均来自台湾大学深度学习课程。
课程地址:https://www.csie.ntu.edu.tw/~yvchen/f106-adl/syllabus.html
当把所有word 转化成vector后,需要将这些vector进行整合,传统整合方法一般使用average, sum等,接下来介绍使用Recursive Neural Network(RvNN)递归神经网络进行处理。

Property
Syntactic Compositionality
但是目前语言是否具有Recursive 还存在争议。所以这里先假设语言是可以递归描述的。

哪些字应该被组合到一起呢?
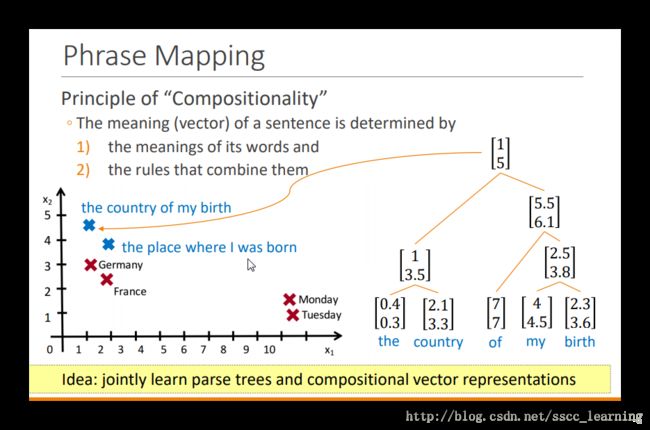
理论上讲,意思相近的词应该离得比较近,从下图看,地区的词和时间的词已区分开来。现在有一句话“the country of my birth”应该放在什么地方呢?
如果知道了语言的架构,先将“the”与“country”合并,然后再将之后的按照架构合并好,最终输出的结果会和地区位置比较相近。
那么如何确定语言的架构,从而一层一层的组合?
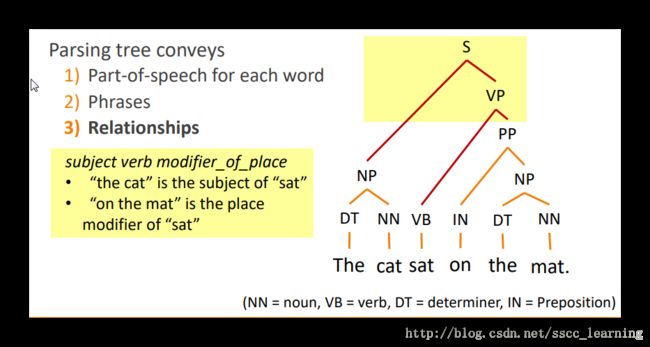
例如下面这句话:“The cat sat on the mat.”
先确定每个词的词性;

接下来转化成短语后,确定短语的性质,例如NP、PP、VP;

根据句子中各短语的关系确定结合的方法顺序,确定句子之间的关系。具体如何进行组合下面还会详细讲。
最后经过每一步处理,用向量表示句子的结构和意义。

Recursion Assumption
一开始就讲到,语言中存不存在递归形式,目前还存在争议,没有定论。但是假设存在递归的话,有什么优势呢?
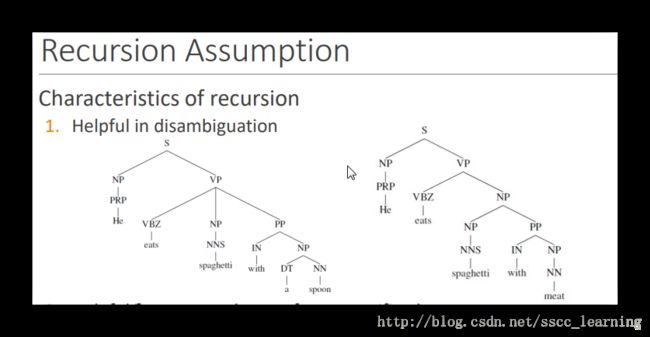
- 消除歧义,通过递归可以判断语义,确定单词词性。从下图的两个句子结构中,可以判断出“a spoon”和“meat”词性的区别。
- 判定指代短语,具体指代关系可以参照下图;

- 判断一个句子是否符合文法结构,而不存在病句。

总而言之,虽然有优点,但是存在仍有争议。所以,下面介绍基于假设存在Recursive。
Network Architecture and Definition
Standard Recursive Neural Network 标准RvNN
Weight-Tied
首先说一下与RNN相似,各个神经网络共用一套权重 W 的情况。
基本结构

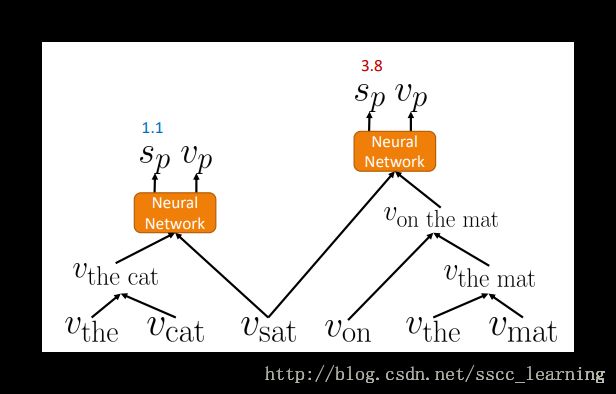
RvNN的基本结构:输入两个候选子向量( von 、 vthe mat ),经过处理后输出一个新的向量( von the mat )和一个得分( score ),分数体现两个子向量结合的合理性。
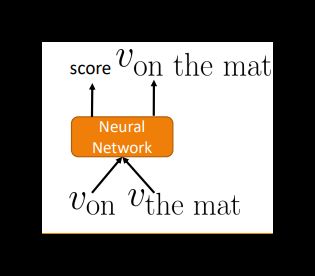
按照上述方法,每一次的两个向量结合生成一个新的向量节点都会进行一次分数计算,选择分数最高的结合方式。接下来将产生的新向量继续进行判断,直到完成一句话,得到这句话总的向量表示。

下图使用公式表示的话,和普通的神经网络模型公式一致。参数设置也和之前讲的RNN参数一致, W 和 U 也都是同一套的。

组合方式
上面说完一个标准神经网络的结构以及计算方法。下面讲一下,句子是如何进行组合,又怎么进行递归的。
还是“the cat sat on the mat”这句话为例,首先,按照顺序两两之间进行计算,计算出每种组合的得分 sp 与组合后的vector vp 。计算都是通过一个神经网络完成的。
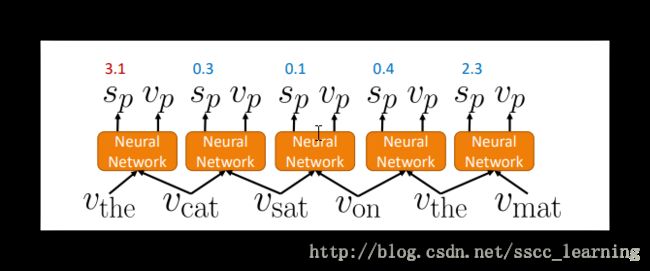
选择得分最高的两个word进行组合。将新的vector与相邻的词继续进行计算,计算得到新的一批的分数。
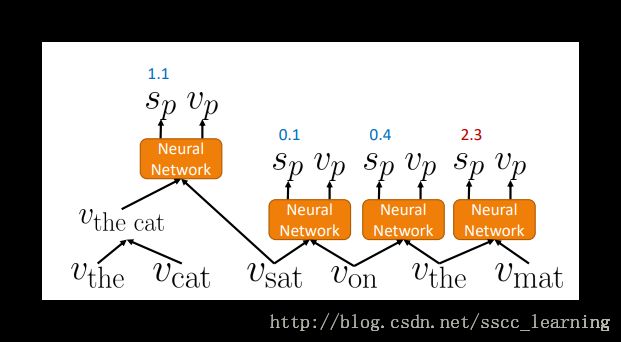
继续选取得分最高的两个word进行组合。再将结果与相邻的词进行计算。
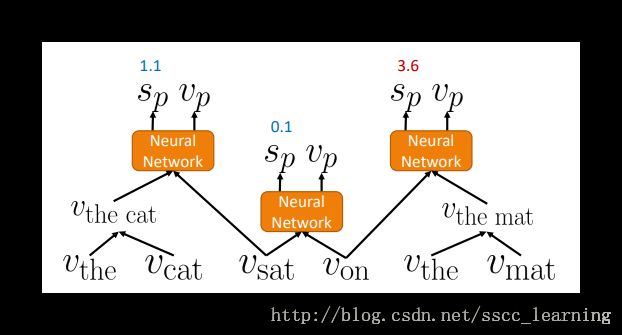
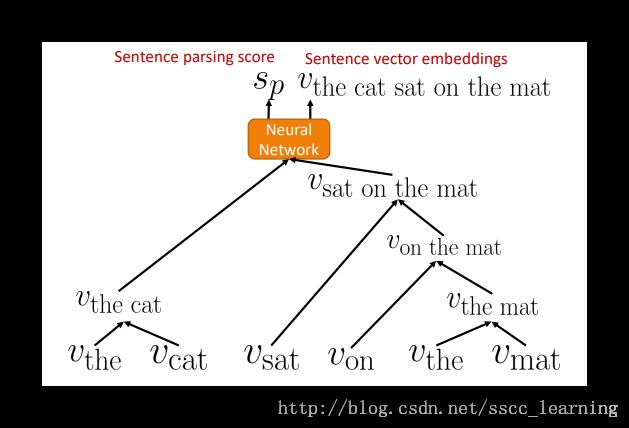
不断的重复上面的步骤,直到将整个句子进行整合,最终能得到这个句子的得分,以及句子的vector。最终的vector包含整句话的结构和意义。
反向传播
反向传播的过程与一般的反向传播基本相似。
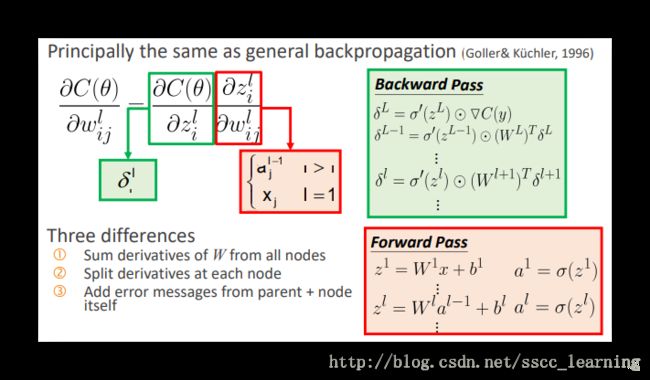
不过还是有一些差异,如下:
首先,RvNN采用的是与RNN相似的多个神经网络的结合,这样在反向传播时,也是像RNN一样多个神经网络同时进行,并共享一套参数。

其次,由于RvNN一个新的节点是由两个子节点组成的,所以在反向传播过程中,偏导结果也会分开到两个子节点中。

再次,由于输出的结果除了向量 vp 还有分数 sp ,所以最终的误差信息需要考虑这两种情况。

Weight-Untied
上面介绍的是 W 共用一个的情况,这样会有一个问题:由于words存在不同词性,会产生不同的组合方式,比如“副词+形容词”、“动词+名词”等。不同方式的组合理应使用不同的 W ,所以针对每一种组合方式设置了相应的的 W 。
但是这样又产生了一个新问题,由于存在多种不同此词性的组合方式,就会产生很多不同的 W ,太多的参数会降低模型训练的速度。
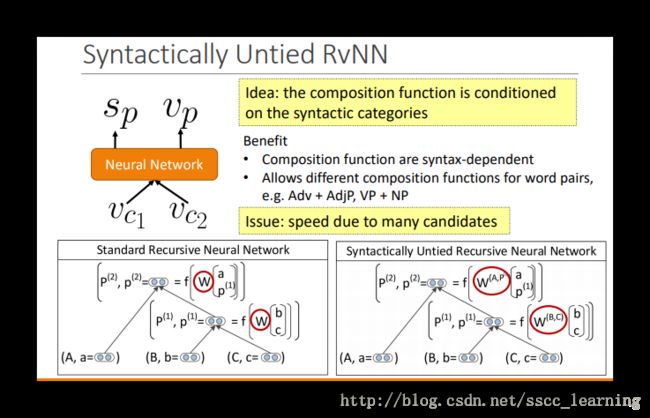
太多的 W 会降低模型训练的速度,这篇文章Parsing with Compositional Vector Grammars - Socher et al. 给出了一些解决方法。比如,去掉一些不太可能出现的组合方式;或者只考虑可能性最大的几种组合方式。

Matrix-Vector Recursive Neural Network & Recursive Neural Tensor Network
有些词有时表示加强语气的含义,比如“very”,这时就需要一种方法能体现出这种word的意义。
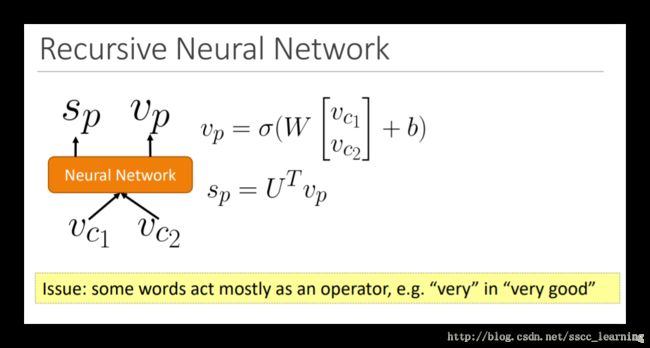
课程中对这种方法没有进行详细讲解,这里也简单了介绍一下。
在每个word开始训练时,为其增加一个参数,如下图,通过这种方式,训练的结果一般能使“ operator”达到目的。

针对这种情况,还有一些更复杂的操作。
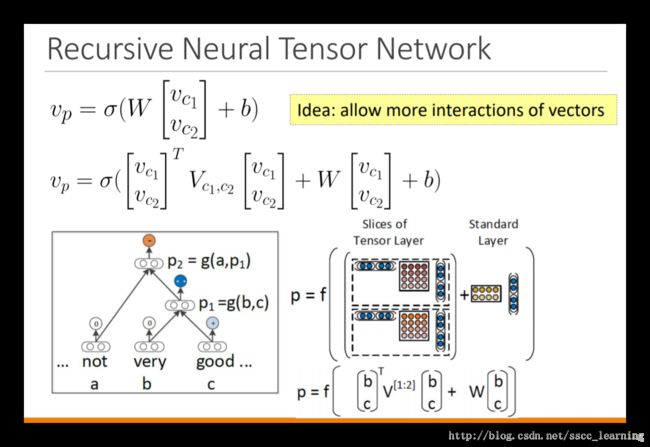
Applications
Parsing 语法分析
首先最常见的应用,当然是在上面讲过的语义分析方面。

比较不常见的,有时会用到图片方面,比如下面讲到的,通过分析图片中各个部分,进而组合而成一个完整的建筑。

Paraphrase Detection 语义检测
通过学习,比较Sentence Vectors的关系,从而判断两句话之间的关系是否相近。

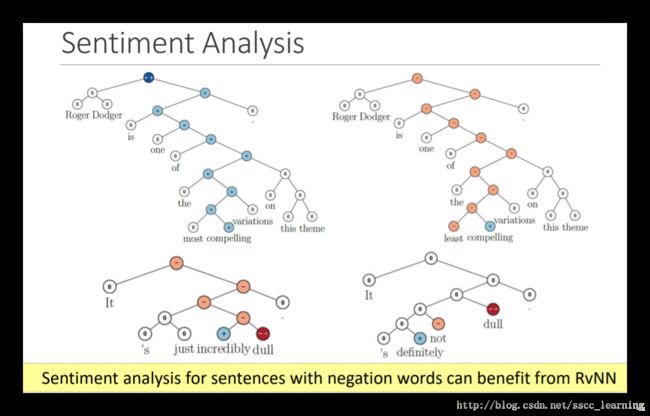
Sentiment Analysis 情感分析
可以判断句子表达的含义是正面的还是负面的。Stanford live demo