【NLP】Stanfordcorenlp和Stanfordnlp的安装和基本使用
一、stanfordcorenlp安装和使用
1.安装Python包
pip install stanfordcorenlp
2.下载数据文件
https://stanfordnlp.github.io/CoreNLP/index.html#download
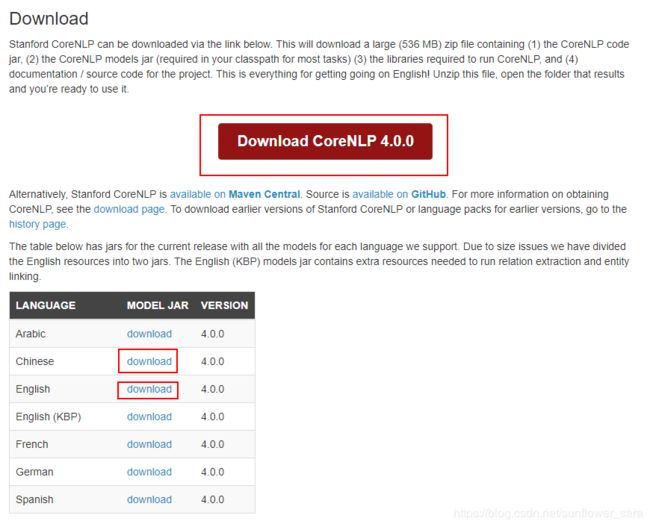
corenlp
![]()
下载好后解压,
记当前路径为path_or_host
另外,将下载的各语种模型文件
![]()
也放在解压后的目录path_or_host下
3.安装JDK 1.8 和JRE 1.8
Java SE JDK安装包下载
https://www.oracle.com/java/technologies/javase/javase-jdk8-downloads.html
Win 64位 JDK1.8
jdk-8u251-windows-x64.exe
tips:需要先用邮箱注册一个账号才能下载
配置环境:
Java环境的配置
https://blog.csdn.net/weixin_43529904/article/details/88370720
https://jingyan.baidu.com/article/08b6a591bdb18314a80922a0.html
检查:
cmd中输入java、 javac、 java -version有对应的信息出现
报错解决:
https://blog.csdn.net/sunflower_sara/article/details/106473753
Javac不是外部命令
https://blog.csdn.net/tg928600774/article/details/80992683
Java1.7和1.8冲突
https://blog.csdn.net/weinichendian/article/details/78559496
4. Ner
https://nlp.stanford.edu/software/CRF-NER.html
下载stanford-ner-4.0.0.zip
解压
5. 示例:
python直接调用
from stanfordcorenlp import StanfordCoreNLP
nlp = StanfordCoreNLP(r'.\\stanford_nlp\\stanford-corenlp-4.0.0', lang='en')
# sentence = '斯坦福大学自然语言处理包StanfordNLP'
sentence = "This is a growing trend particularly in the United States. Oftentimes there are great opportunities for glamping just outside national park boundaries. Yellowstone, Zion National Park, and Yosemite are excellent both for their supreme natural beauty as well as their many prime opportunities for some glamping."
print(nlp.word_tokenize(sentence)) # 分词
print(nlp.pos_tag(sentence)) # 词性标注
print(nlp.ner(sentence)) # 实体识别
print(nlp.parse(sentence)) # 语法树
print(nlp.dependency_parse(sentence)) # 依存句法
nlp.close() # Do not forget to close! The backend server will consume a lot memery.
如果用端口模式:
(详细可参考:https://blog.csdn.net/qq_35203425/article/details/80451243)
cmd中启动端口
java -mx4g -cp "*" edu.stanford.nlp.pipeline.StanfordCoreNLPServer -port 9000 -timeout 15000

Python脚本中用
nlp = StanfordCoreNLP('http://localhost', port=9000)
替换
nlp = StanfordCoreNLP(r'.\\stanford_nlp\\stanford-corenlp-4.0.0', lang='en')
from stanfordcorenlp import StanfordCoreNLP
nlp = StanfordCoreNLP('http://localhost', port=9000)
# sentence = '斯坦福大学自然语言处理包StanfordNLP'
sentence = "This is a growing trend particularly in the United States. Oftentimes there are great opportunities for glamping just outside national park boundaries. Yellowstone, Zion National Park, and Yosemite are excellent both for their supreme natural beauty as well as their many prime opportunities for some glamping."
print(nlp.word_tokenize(sentence)) # 分词
print(nlp.pos_tag(sentence)) # 词性标注
print(nlp.ner(sentence)) # 实体识别
print(nlp.parse(sentence)) # 语法树
print(nlp.dependency_parse(sentence)) # 依存句法
nlp.close() # Do not forget to close! The backend server will consume a lot memery.
二、Stanfordnlp安装和使用
1. 安装python包
pip install stanfordnlp
2. 下载数据文件
python中:
import stanfordnlp
stanfordnlp.download('en')
根据提示输入y即可下载数据
我的下载到了 D:\Users\user\stanfordnlp_resources
大小大概270M
3. 安装pytorch
需要依赖pytorch 1.0.0以上版本
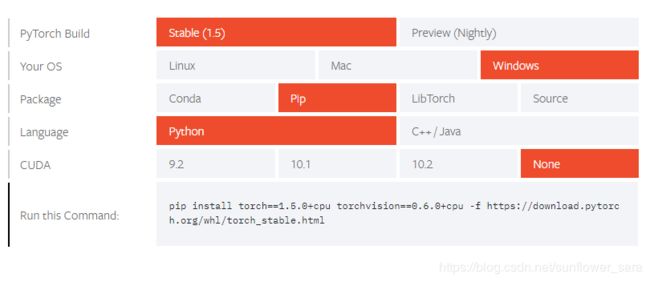
打开如下链接选择相应的环境和版本的pytorch
https://pytorch.org/get-started/locally/
https://download.pytorch.org/whl/torch_stable.html
4. 示例代码:
import stanfordnlp
# stanfordnlp.download('en') # This downloads the English models for the neural pipeline
nlp = stanfordnlp.Pipeline() # This sets up a default neural pipeline in English
doc = nlp("Barack Obama was born in Hawaii. He was elected president in 2008.")
doc.sentences[0].print_dependencies()
参考资料:
https://blog.csdn.net/qq_35203425/article/details/80451243
https://blog.csdn.net/qq_40426415/article/details/80994622
其他:
python nltk中使用StanfordNER
https://www.jianshu.com/p/f5c893c89c28