拍拍贷金融风控案例(总结)
项目主要分为:
1.背景数据介绍,是一个二分类的问题,预测贷款的人是否会逾期还款!
2.数据清洗,对缺失值的填充等,异常点的判别,字符串大小写,空格等问题!
3.原始信息的特征提取,主要是从原始数据,提取出来有用的特征,
4.特征选择/降维,主要进行了特征选择,降维没有使用,
5.模型设计,还是用了最主流的模型融合(blending),有一个线性模型学习各个分类器权重的过程,
这五个类别,其中第3和第4项可以归纳为特征工程!其中代码已经基本全部实现,模型还在训练中,我会把代码贴下 来,数据上传百度网盘(链接末尾给出)请自行学习与尝试!
一.背景数据介绍
1.有三个CSV格式的表,训练样本:master_info表存放3W条数据,login_info表存放5W+貌似,update_info表存放37W+
测试样本2W条测试集!
2.idx字段三个表里都有的字段(有的idx对应不上,这个是脏数据不好处理,切记此坑!)每个样本包含200多条特征!
master_info表:
UserInfo_*:借款人特征字段
WeblogInfo_*:Info网络行为字段
Education_Info*:学历学籍字段
ThirdParty_Info_PeriodN_*:第三方数据时间段N字段
SocialNetwork_*:社交网络字段
LinstingInfo:借款成交时间
Target:违约标签(1 = 贷款违约,0 = 正常还款)。测试集里不包含target字段
login_info表:
Log_Info(借款人的登陆信息)
ListingInfo:借款成交时间
LogInfo1:操作代码
LogInfo2:操作类别
LogInfo3:登陆时间
idx:每一笔贷款的unique key
update_info表:
Userupdate_Info(借款人修改信息)
ListingInfo1:借款成交时间
UserupdateInfo1:修改内容
UserupdateInfo2:修改时间
idx:每一笔贷款的unique key
二.数据清洗
首先说明,这是一个很脏的数据!
1.对缺失值的多维度处理
按列对缺失值进行绘图:
master_info.isnull().sum().sort_values(ascending=False)/30000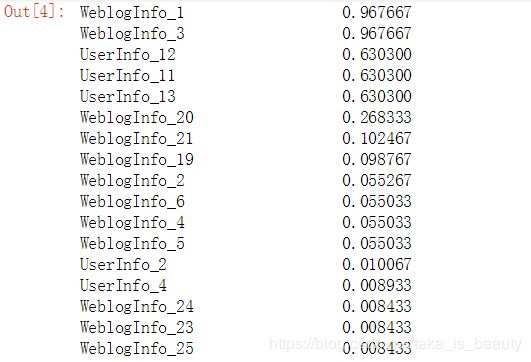
可以发现前两项缺失值太多了,我学习不到甚么东西的,直接选择drop掉!
对缺失值63%左右的数据,发现他是,类别型的,在这可以做出一个选择,就是全部映射为一个类型,就是把NA当成一 个新的类别!但是数值型的呢?可以选择使用随机森林(降低的是方差)进行拟合数据!
对于缺失值比较少的,在这里我的选择是,对于类别性数据选择填充众数/中位数,对于数值型的数据填充均值!
在这里能做出这样的判断,你可以想向一下,有些数据能不填用户也是不想填的嘛,所以说你这样填充数据是可行的!
2.对离群点的剔除方法
按行:对缺失值进行绘图,可以根据缺失值来找出一少量离群点,缺的太多剔除即可!
#寻找离群点
#训练集
plt.figure(figsize=(10,10))
y_arr = []
for row in master_info.values:
y_arr.append(pd.Series(row).isnull().sum())
y_arr.sort()
x = [ i for i in range(1,len(y_arr)+1)]
plt.scatter(x,y_arr)
plt.show()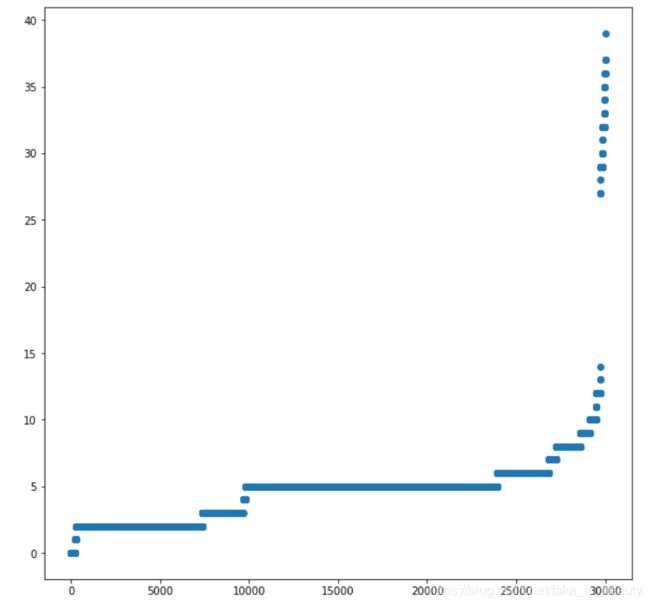
按列:对数值型特征统计标准差/方差,对值特别小的特征进行剔除,因为根据此值,可以衡量一个特征数值的离散程 度,如果都聚在一块那么变化太小学习不到甚么东西!
master_info.std().sort_values()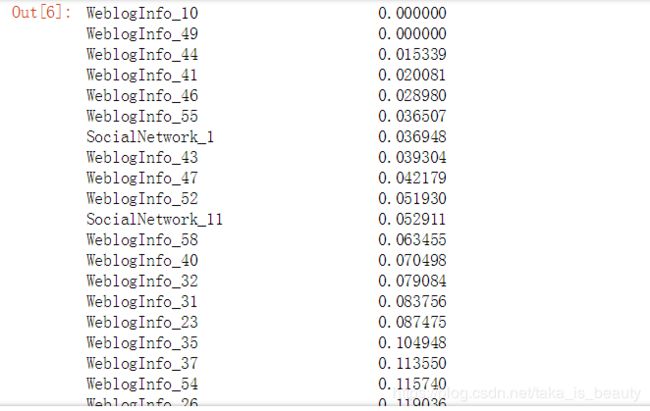
按模型:使用xgboost,使用原始数据训练模型,选择出最好的前20/40个特征,然后统计每个样本在这前top特征中的缺失值情况,进行判断是否是离群点,如果在好的特征上缺失值比较多那么这个样本点就可当作异常点!
3.字符串数据处理
通常会包含,字符串大小写问题,例如"_QQ"和"_qQ",字符串空格问题,例如Master表中 UserInfo_9 字段的"中国移 动"和" 中国移动",城市名称的问题,例如: UserInfo_8 字段中出现“重庆”和“重庆市”!
三.原始信息的特征提取
1.对地理位置特征的特殊处理
省份:UserInfo_7字段代表省份,一共32种,我选择了对每个省份绘制了一个逾期率的柱状图,筛选出来前几个排名的省 份,因 为我认为这几个省份,区分度比较大,我就想要尽可能多的找到逾期的这群人!映射成N个特征类似于 one-hot编码!
#32种,可以通过作图来得出有区分度(违约率大)的几列,而舍弃其他省份
y = []
for city in citys:
y.append(sum( master_info["UserInfo_7"]==city ))
plt.figure(figsize=(10,10))
plt.bar(citys,y)
plt.show()
print(citys[0],citys[1],citys[5],citys[11],citys[12],citys[3],citys[28])
"""广东 浙江 山东 江苏 福建 河南"""
master_info["UserInfo_7广东"] = 0
master_info.loc[master_info["UserInfo_7"] == "广东","UserInfo_7广东"] = 1
master_info["UserInfo_7浙江"] = 0
master_info.loc[master_info["UserInfo_7"] == "浙江", "UserInfo_7浙江"] = 1
master_info["UserInfo_7山东"] = 0
master_info.loc[master_info["UserInfo_7"] == "山东", "UserInfo_7山东"] = 1
master_info["UserInfo_7江苏"] = 0
master_info.loc[master_info["UserInfo_7"] == "江苏", "UserInfo_7江苏"] = 1
master_info["UserInfo_7福建"] = 0
master_info.loc[master_info["UserInfo_7"] == "福建", "UserInfo_7福建"] = 1
master_info["UserInfo_7河南"] = 0
master_info.loc[master_info["UserInfo_7"] == "河南", "UserInfo_7河南"] = 1
master_info.drop(labels="UserInfo_7",inplace=True,axis=1)以上方式是基于人工选择,当类别更多呢?例如:城市信息的种类高达300多种
城市:在这里很trick,利用xgboost,把城市信息用one-hot进行编码,然后送入xgboost中,保留top20/40不就行了嘛!
在这里在挖掘城市信息,可以不可以,用一线二线三线城市进行离散化呢,可不可以用南方北方城市历史那话呢?
在挖掘,经纬度的引入,对每个城市找到,经纬度,可以分成两个数值型特征,也可以直接求距离变为一个特征!
在挖掘,城市特征向量化,对每个城市进行计数(可能需要值域的变化取log或者exp都可以试试),然后对函数 曲线分为6段,那个样本在哪一段,就把向量变为1,在这里这六个向量用6个特征维度来表示,还是类似 于one-hot 编码!
在这里再不贴代码信息了!!!!!
地理位置的差异度:
对 UserInfo_2,4,8,20进行地理位置差异特征计算!进行组合diff_24 diff_28 ...有差异就为1,没有就为0!
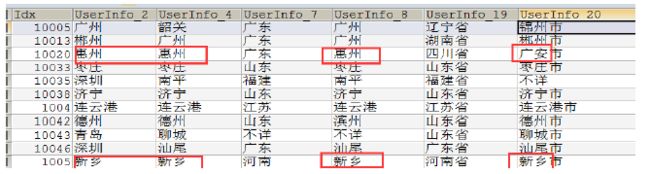
成交时间的特征:
对时间进行排序,绘制每一天成交量的样本中,逾期数和未逾期数的两条折线图!
(blue是未逾期数,red是逾期数)
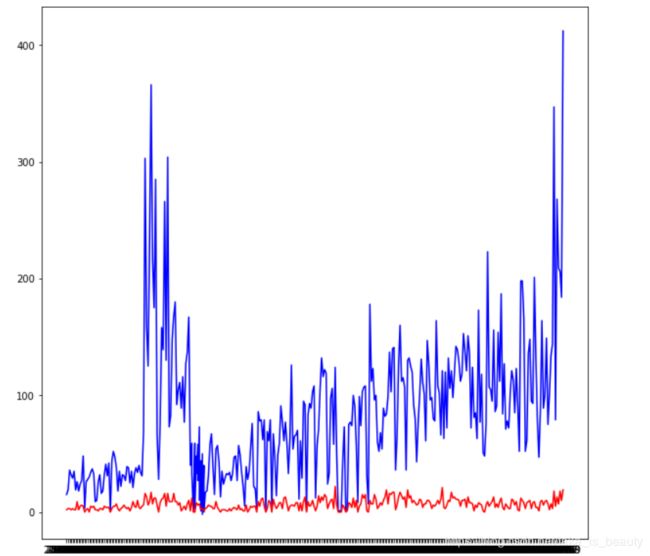
从图中可以看出,时间信息比较强,逾期数不跟他变化,但是能很好的和未逾期数呈增长关系!
在这里的处理是,将时间离散化,每十天为一个区间!
2.标准化/one-hot编码特征
以上的处理都是特殊的处理,在这里对其他的特征进行,类别型使用one-hot编码,数值型标准化!
3.组合特征生成
利用xgboost挑选出前top40/20,然后两两进行组合(可以相减,可以相加,相乘在取对数都可以),在这里效果最好的 还是相乘在取对数,效果最好!然后在利用xgboost对生成出来的组合特征进行筛选,选出top500即可(自己定)!
4.update和login表
在这里这两个表处理思路一致,可以对修改时间的日期,到基于贷款之间的间隔构造出来一个特征,也可以使用更新次数 和登陆次数再来构造出来两个特征,在这里仅提供这些,其他的可以自己思考嘛!
四.特征选择/降维
1.特征选择
:最常用的还是利用xgboost模型来进行选择,前top500左右(最常用)
:利用LR模型加L1正则,对系数的绝对值进行排序,选择出top500左右
:这两种都是基于模型的选择,还有基于单个特征与目标值的相关性进行评分来选择,
还有是利用模型递归的每次淘汰末尾5%-10%直到误差有大幅度下降!
2.降维
:这是一种特征提取,来达到降维的方式!
:一般基于PCA(方差最大化为目标)和LDA(线性判别模型,目标是,使得类别内的点距离越近越好(集中),类别间 的点越远越好,将多维数据投影到一条直线上,是的同类数据的投影点尽可能接近,异类数据点尽可能远离)来进行 降维!
:降维是黑盒机制的可解释性差,而且一般用于比赛中,效果往往不好!
五.模型的设计
1.类别不平衡
可以发现lables的比例大约是11:1,类别会严重失衡,如果直接学习的话,那么模型可能会全判断为0的,因为这样误差 可能最小,所以我们必须进行样本的调整!
:上采样:直接使用SMOTH算法,对与样本点找到离他最近的一个样本点,在他们之间的连线上进行生成数据!
:代价敏感学习:直接使用模型里的样本权重设置项(可以和上采样进行结果比较)
:下采样:一般不考虑,直接抛弃了大量数据,但是可以用11份数据来训练11个模型,然后投票选择即可,可以试试!
2.模型融合(blending)
在这里主模型使用了,LR,SVM,Xgboost三个模型,然后利用三个模型的预测概率值,当作线性模型的特征进行输入 进去,学习一组权重,来对三个模型进行加权即可!
模型组合这块,全看自己,都可以试试的,还有特征工程那块也是都可以试试的嘛,多想即可,谁也没有一个确切的答案
六.总结与思考
耗时两天完成的一个机器学习项目,在我完成机器学习后,进行熟悉pandas,numpy,matplotlib,sklearn库,还有很多简单的项目有了这些基础后,才完成的一个纯手写,自己实现的一个项目。其中遇到了很多的BUG,例如:索引重置问题,导致学习模型学不到值等等,但是在这两天当中,自己代码能力和API熟悉是感觉提升很大的,当然更多的还是这个项目,带给我一些很好的思路,让我在以后的实际当中尽可能多的学着思考一些自己的想法,并且在kaggle/天池等等竞赛的一些思路!