论文阅读: FaceID-GAN: Learning a Symmetry Three-Player GAN for Identity-Preserving Face Synthesis
转载请注明本文出处,谢谢。
论文链接:FaceID-GAN

文章题目叫做FACEID-GAN,学习一个对称的三者对抗的GAN,来做保留身份的人脸生成。

首先用这张图解释一下本文的目的。对于一幅输入的人脸图像,这个GAN网络可以生成多种视角,多种表情的人脸,并且可以保留这个人的身份,也就是说生成出来的人脸仍然都还是这个人。
油管上还有一个生动的小视频,动态的展示了各种连续角度的生成变化。视频链接
1. Contributions
本文主要有三大贡献:
1) 把传统D和G之间的对抗进行扩展,加入分类器C,C和D共同对抗G,确保生成的图像同时具有高质量和保留身份。
Two-player game --> Three-player game
2) 本文的网络结构遵循信息对称,减小了训练难度。
Information symmetry
3) 本文的网络结构可以生成多种视角和表情。
High diversity in viewpoints and expressions
2. Introduction
2.1 GAN - Two player game
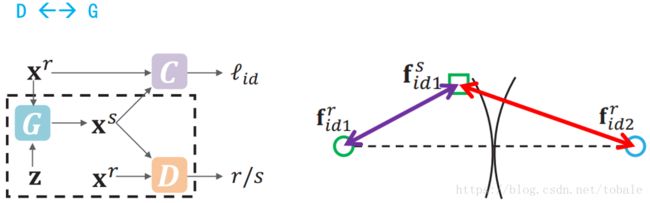
原始的GAN一般是生成器和判别器二者对抗,当判别器无法区分是生成的还是真实的的时候,网络就收敛了。比如说左图虚线框里就是一个原始的GAN,一个G,一个D。
那之前生成人脸的方法,就是在原始GAN上做的改进。还是左边这个图。为了保证生成的人脸具有相同的id,他们就加入了一个额外的分类器C。用于对真实图像xr或者生成图像xs做分类,预测类别标签。那么就依靠这个标签来监督生成器,希望生成的图像通过分类器后具有和真实图像相同的标签。
这类方法里面,尽管C学习了人脸的身份特征,但他不一定能很好的保留身份。原因之一是他仅仅用图像的类别标签作为监督信息。另外一点是我们希望生成的人脸和真实的人脸的空间距离越小越好。右边这张图,fr1和fr2,就是两个绿色和蓝色圆圈,他们俩代表两个不同id的人脸。绿色正方形fs1代表的是生成的人脸。我们现在希望生成人脸具有id1的身份,那么在现在的这些方法中,只要当fr1和fs1的距离小于fr2和fs1的距离,就是只要紫色的线段比红色的线段要小。即使fs1就落在这两个身份的边界处。分类器C就会认为fr1和fs1是具有相同的身份,把fs1归类为id1。但是没有考虑到他们俩在特征空间里的距离究竟是多少,这就一定程度上影响了保留身份的这种能力。
另外,这个网络结构是不对称的。看左边这个图,真实图像直接输入生成器G,用生成器G去直接提取真实图像的特征,再做生成。而生成的图像是用分类器C去提特征。那这两个特征既然都不是一个模型提取的,根本不在同一个特征空间里,差别很大,会导致训练困难。
2.2 FaceID-GAN - Three player game
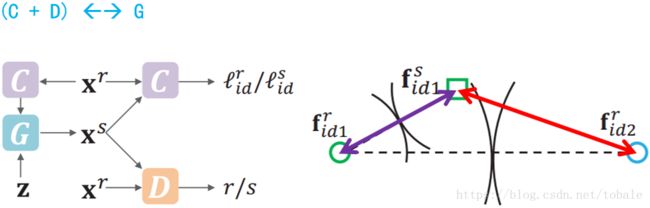
那么这篇文章就提出了FaceID-GAN。那么他有两个主要特点。
1) 把原始的二者对抗的GAN扩展到三者对抗的GAN。之前的方法仅仅把分类器C作为一个监督信息,并没有参与图像生成的过程。那么FaceID-GAN把分类器C作为除了D和G以外的第三个参与者。直观上来说,就是分类器C和判别器D一块对抗生成器G。具体点说呢,就是C用来区分生成图像和真实图像是否属于同一类,D用来区分生成的图像是否足够真实。那么G就尝试去生成真实的保留身份的图像来减少C和D的分类准确率。当C和D无法区分生成图像和真实图像的时候,训练就收敛了。
然后看右边这个图,这个时候的分类器C,不仅会分类不同的id1和id2,还会区分真实的fr1和生成的fs1。这样的话,为了迷惑分类器C,生成器G就必须生成和真实图像特征足够接近的图像。这个绿色正方形就会越来越靠近绿色圆圈,远离id1和id2的边界。经过这样的对抗训练,生成器就可以稳定的生成保留人脸身份的图像了。
2) FaceID-GAN遵循信息对称,这是设计GAN网络的基本准则。我们刚才说之前的网络结构是不对称的,因为真实图像和生成图像的特征不在同一个特征空间。那从本文提出来的网络结构可以看出来,真实图像和生成图像都会通过分类器C提取特征。保证它们在同一个特征空间,这样他们之间的距离就会相对而言更小一些,很大程度上减小了训练难度。
2.3 Information symmetry

一开始,我是有一个疑惑,这边有两条线,真实图像和生成图像完全都可以使用分类器C提特征。为什么不直接使用C提他们俩的特征计算距离呢,这样不就在同一个特征空间里面了吗?
后来想想是因为,真实图像和生成图像都用C提特征计算距离,这种做法仅仅把分类器作为一个特征提取器,这样对于生成器没有直接的贡献。生成器G的输入还是原始图像。
而在FaceID中,原始图像先通过分类器提特征,然后再送到生成器。这样就可以让分类器参与到整个对抗过程中。另外,真实图像通过分类器得到的特征和生成图像通过分类器得到的特征,处于同一个特征空间里,保证了信息对称。
2.4 Comparison
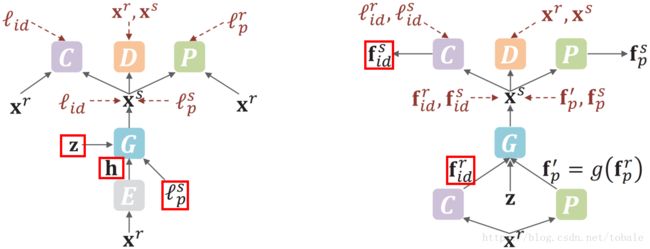
为了更明确的对比,作者画了这两组图,左边是现有方法的做法,右边是本文提出的方法。
这两幅图中,C都是人脸特征分类器,P是用于提取姿态的模型。
在左边这类方法中,首先输入真实图像xr,通过一个自动编码器E,然后再输入生成器G,除此之外,输入生成器的还有随机噪声z和期望得到的姿态标签ls。在这种方法中已经去除了groundtruth图像和生成图像之间的像素级损失。这样就不需要成对的训练数据,更早的方法必须需要成对的训练数据。另外一点,这种方法不能保证信息对称,真实图像的特征是通过编码器E后得到的,而生成图像的特征是由分类器C提取的。这两者的特征在不同的特征空间。那生成器G在学习让生成图像保留身份之前,还要学习两种特征空间之间的转换,无形之间带来了训练的困难。另外,生成图像的身份信息仍然是靠分类器输出的类别标签来监督。
而右图中的FaceID-GAN使用分类器C和姿态模型P替换掉编码器E。整个模型中的C和P是参数共享的。这样的话,输入图像的特征和生成图像特征就在同一个特征空间,而且身份信息的监督是用的时分类器提取的特征,而不是分类器输出的类别标签。
3. Proposed method
3.1 Overall framework

上图就是整个网络的结构框架。绿色的P是姿态模型,用于提取输入图像的姿态特征。对于输入的真实图像,首先对他提取姿态特征fr,然后通过函数g。函数g的作用是把输入图像的姿态转变为期望输出的姿态特征f撇。
输入生成器G的特征分别是分类器特征,随机噪声z和期望得到的姿态特征f撇。
然后,生成的图像再次分别通过分类器C,姿态模型P和判别器D,来提取生成图像的身份和姿态特征,以及判别图像是否是同一个id,是否真实。
生成器,判别器和分类器三者之间的对抗,可以分别得到下面的损失函数。

需要注意的是,这里面没有姿态模型P的损失函数,因为姿态模型用的是预训练的已有算法。
3.2 Discriminator D
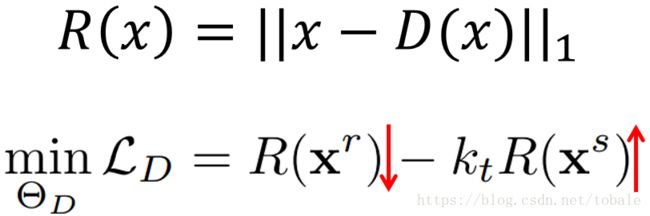
然后我们来挨个看一下,首先是判别器D。传统的判别器D是一个简单的二分类器。而本文的D是一个自动编码器。就是上面的R,他通过最小化输入输出的像素级误差来重构输入图像。那么判别器的损失函数就是下面这个式子,最小化真实图像的重构误差,最大化生成图像的重构误差。
式子里面的这个kt是一个在训练过程中动态更新的权重参数。
3.3 Classifier C
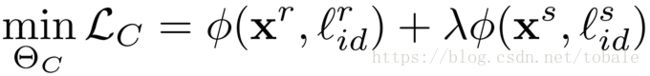
然后是分类器C的损失函数。他由两个部分组成,分别是真实图像和对应标签以及生成图像和对应标签的损失。其中两部分都是交叉熵损失。我们之前说生成图像应该和真实图像距离越近越好。所以加入一个损失权重来木他,来均衡生成图像在这个损失函数中的贡献。
3.4 Generator G
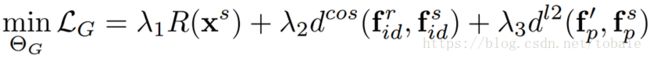
最后是生成器G的损失函数。第一项R就是刚才说的判别器D里面的自动编码器,使生成图像的重构误差最小。第二项是输入图像和生成图像的身份特征的cosine距离。第三项是输入图像和生成图像的姿态特征的欧式距离。
4. Experiments
4.1 Frontalization and Identity

第一组实验是把输入的侧脸摆正。对于本文而言,把侧脸摆正这个事情其实就是生成任意姿态在0°时候的子任务。
第一行是输入的侧脸图像,最后一行是本文的算法,中间两行是其他算法。生成图像左上角的数字是生成图像和输入图像的相似度。
从这个结果可以得到三点结论:
1) 由于姿态模型P,本文可以生成绝对正脸的视角,而其他算法都产生了不同程度的畸变。
2) 本文真的是生成了一幅新的脸,而不只是简单的学习和映射。这是由于我们给生成器输入的是分类器C的特征,而不是整幅图像的特征。分类器C出来的特征滤掉了很多无关的背景信息,更关注人脸的特征。
3) 本文生成的图像可以保持更好的图像质量以及和输入图像更高的相似度,这是由于C和D共同对抗G的结果。
4.2 Rotation and Identity

第二组实验是多种角度的人脸生成。和之前的算法相比,本文的方法还是有很提升的。奇数行是之前的方法,偶数行数本文的方法。首先,本文生成的图像是128x128,而之前的方法是96x96。从左上角的相似度,可以发现,本文的算法可以更好的保留身份信息。另外,我们可以发现本文的方法视觉效果比之前的好了很多。
4.3 Pose, Expression and Identity
第三组实验是本文算法在更多测试集上的视觉效果图。我们可以看到在第8种姿态下,每个生成图像的笑容都不一样,但是又都保持了和输入图像相同的身份信息。这就是一个生成图像表情的多样性。