使用Phoenix连接HBASE,squirrel使用,代码连接使用Phoenix
1 使用Phoenix连接HBASE
1.1 什么是Phoenix?
phoenix,中文译为“凤凰”,很美的名字。Phoenix是由saleforce.com开源的一个项目,后又捐给了Apache基金会。它相当于一个Java中间件,提供jdbc连接,操作hbase数据表。Phoenix是一个HBase的开源SQL引擎。你可以使用标准的JDBC API代替HBase客户端API来创建表,插入数据,查询你的HBase数据。Phoenix的团队用了一句话概括Phoenix:”We put the SQL back in NoSQL” 意思是:我们把SQL又放回NoSQL去了!这边说的NoSQL专指HBase,意思是可以用SQL语句来查询Hbase,你可能会说:“Hive和Impala也可以啊!”。但是Hive和Impala还可以查询文本文件,Phoenix的特点就是,它只能查Hbase,别的类型都不支持!但是也因为这种专一的态度,让Phoenix在Hbase上查询的性能超过了Hive和Impala!
1.2 Phoenix性能
Phoenix是构建在HBase之上的SQL引擎。你也许会存在“Phoenix是否会降低HBase的效率?”或者“Phoenix效率是否很低?”这样的疑虑,事实上并不会,Phoenix通过以下方式实现了比你自己手写的方式相同或者可能是更好的性能(更不用说可以少写了很多代码):
编译你的SQL查询为原生HBase的scan语句。
检测scan语句最佳的开始和结束的key。
精心编排你的scan语句让他们并行执行。
推送你的WHERE子句的谓词到服务端过滤器处理。
执行聚合查询通过服务端钩子(称为协同处理器)。除此之外,Phoenix还做了一些有趣的增强功能来更多地优化性能:
实现了二级索引来提升非主键字段查询的性能。
统计相关数据来提高并行化水平,并帮助选择最佳优化方案。
跳过扫描过滤器来优化IN,LIKE,OR查询。
优化主键的来均匀分布写压力。1.3 Phoenix的安装部署
1.3.1 准备工作
提前安装好ZK集群、hadoop集群、Hbase集群
1.3.2 安装包(放到142机器上)
从对应的地址下载:http://mirrors.cnnic.cn/apache/phoenix/
这里我们使用的是:
apache-phoenix-4.14.0-HBase-1.4-bin.tar.gz (因为HBASE是1.4.2版本的)
1.3.3 上传、解压
将对应的安装包上传到对应的Hbase集群其中一个服务器的一个目录下
解压:
[root@bigdata3 software]# cd /home/bigdata/software
[root@bigdata3 software]# tar -zxvf apache-phoenix-4.14.0-HBase-1.4-bin.tar.gz -C /home/bigdata/installed/重命名:
[root@bigdata3 software]# cd /home/bigdata/installed/
[root@bigdata3 installed]# mv apache-phoenix-4.14.0-HBase-1.4-bin phoenix1.3.4 配置
(1) 将phoenix目录下的phoenix-4.14.0-HBase-1.4-server.jar、
phoenix-core-4.14.0-HBase-1.4.jar拷贝到各个 hbase的lib目录下。命令如下:
[root@bigdata3 phoenix]# cp phoenix-4.14.0-HBase-1.4-server.jar $HBASE_HOME/lib
[root@bigdata3 phoenix]# cp phoenix-core-4.14.0-HBase-1.4.jar $HBASE_HOME/lib将142机器上的$HBASE_HOME/lib同步到140,141(即:bigdata1,bigdata2机器上)
[root@bigdata3 phoenix]# cd $HBASE_HOME/lib
[root@bigdata3 lib]# scp -r * root@bigdata1:$PWD
[root@bigdata3 lib]# scp -r * root@bigdata2:$PWD将hbase的配置文件hbase-site.xml、 hadoop/etc/hadoop下的core-site.xml 、hdfs-site.xml放到phoenix/bin/下,替换phoenix原来的配置文件。
重启hbase集群,使Phoenix的jar包生效。
[root@bigdata3 conf]# pwd
/home/bigdata/installed/hbase-1.4.2/conf
[root@bigdata3 conf]# cp hbase-site.xml /home/bigdata/installed/phoenix/bin/
[root@bigdata3 conf]# cp $HADOOP_HOME/etc/hadoop/core-site.xml /home/bigdata/installed/phoenix/bin/
[root@bigdata3 conf]# cp $HADOOP_HOME/etc/hadoop/hdfs-site.xml /home/bigdata/installed/phoenix/bin/重启hbase集群,进入bigdata1机器
1.3.5 验证是否成功
(1)在phoenix/bin下输入命令:
端口可以省略
[root@bigdata3 bin]# pwd
/home/bigdata/installed/phoenix/bin
[root@bigdata3 bin]# ./sqlline.py bigdata3:2181出现如下界面说明启动成功
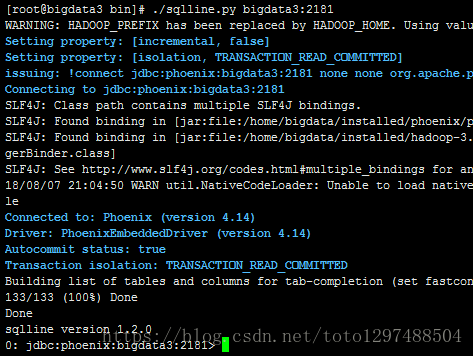
(2)输入!tables 查看都有哪些表。红框部分是用户建的表,其他为Phoenix系统表,系统表中维护了用户表的元数据信息。
+------------+--------------+----------------+---------------+----------+------------+-----------------+
| TABLE_CAT | TABLE_SCHEM | TABLE_NAME | TABLE_TYPE | REMARKS | TYPE_NAME | SELF_REFERENCIN |
+------------+--------------+----------------+---------------+----------+------------+-----------------+
| | SYSTEM | CATALOG | SYSTEM TABLE | | | |
| | SYSTEM | FUNCTION | SYSTEM TABLE | | | |
| | SYSTEM | SEQUENCE | SYSTEM TABLE | | | |
| | SYSTEM | STATS | SYSTEM TABLE | | | | |
+------------+--------------+----------------+---------------+----------+------------+-----------------+
(3)退出Phoenix。输入!quit

1.4 Phoenix使用
Phoenix可以有4种方式调用:
批处理方式
命令行方式
GUI方式
JDBC调用方式1.4.1 批处理方式
1.4.1.1 创建user_phoenix.sql文件
内容如下(把下面的内容添加到user_phoenix.sql中):
CREATE TABLE IF NOT EXISTS user_phoenix ( state CHAR(2) NOT NULL, city VARCHAR NOT NULL, population BIGINT CONSTRAINT my_pk PRIMARY KEY (state, city));要注意的是:关键字必须是大写的,否则会报错。上面的代码执行完成之后的效果如下:
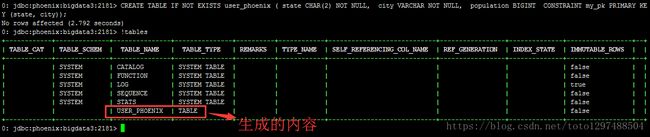
1.4.1.2 创建user_phoenix.csv数据文件
把下面的内容添加到user_phoenix.csv文件中:
NY,New York,8143197
CA,Los Angeles,3844829
IL,Chicago,2842518
TX,Houston,2016582
PA,Philadelphia,1463281
AZ,Phoenix,1461575
TX,San Antonio,1256509
CA,San Diego,1255540
TX,Dallas,1213825
CA,San Jose,9123321.4.1.3 创建user_phoenix_query.sql文件
内容为(将下面的内容写到user_phoenix_query.sql文件中):
SELECT state as "State",count(city) as "City Count",sum(population) as "Population Sum" FROM user_phoenix GROUP BY state ORDER BY sum(population) DESC; 显示的结果如下:
0: jdbc:phoenix:bigdata3:2181> SELECT state as "State",count(city) as "City Count",sum(population) as "Population Sum" FROM user_phoenix GROUP BY state ORDER BY sum(population) DESC;
+--------+-------------+-----------------+
| State | City Count | Population Sum |
+--------+-------------+-----------------+
+--------+-------------+-----------------+
No rows selected (0.253 seconds)
0: jdbc:phoenix:bigdata3:2181>1.4.1.4 执行
cd /home/bigdata/installed/phoenix
/home/bigdata/installed/phoenix/bin/psql.py bigdata3:2181 user_phoenix.sql user_phoenix.csv user_phoenix_query.sql这条命令同时做了三件事:创建表、插入数据、查询结果
例如:
[root@bigdata3 phoenix]# /home/bigdata/installed/phoenix/bin/psql.py bigdata3:2181 user_phoenix.csv user_phoenix_query.sql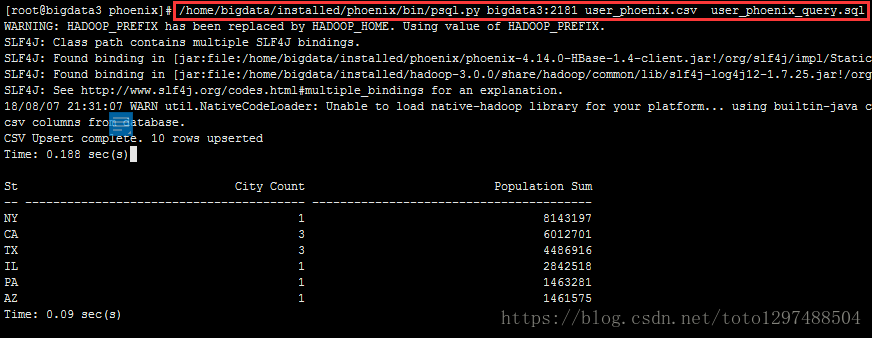
用Hbase shell 看下会发现多出来一个 USER_PHOENIX 表,用scan 命令查看一下这个表的数据
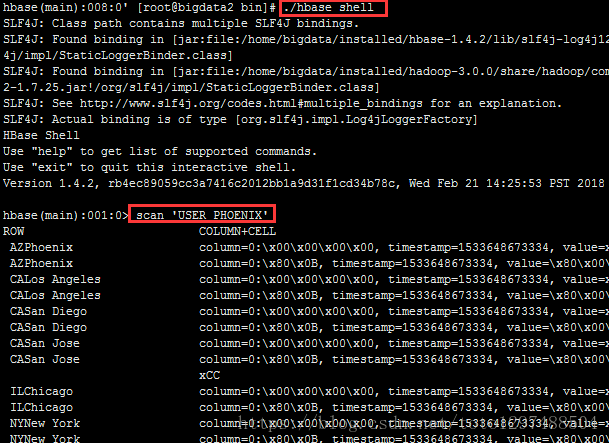
hbase(main):001:0> scan 'USER_PHOENIX'
ROW COLUMN+CELL
AZPhoenix column=0:\x00\x00\x00\x00, timestamp=1533648673334, value=x
AZPhoenix column=0:\x80\x0B, timestamp=1533648673334, value=\x80\x00\x00\x00\x00\x16MG
CALos Angeles column=0:\x00\x00\x00\x00, timestamp=1533648673334, value=x
CALos Angeles column=0:\x80\x0B, timestamp=1533648673334, value=\x80\x00\x00\x00\x00:\xAA\xDD
CASan Diego column=0:\x00\x00\x00\x00, timestamp=1533648673334, value=x
CASan Diego column=0:\x80\x0B, timestamp=1533648673334, value=\x80\x00\x00\x00\x00\x13(t
CASan Jose column=0:\x00\x00\x00\x00, timestamp=1533648673334, value=x
CASan Jose column=0:\x80\x0B, timestamp=1533648673334, value=\x80\x00\x00\x00\x00\x0D\xEB\
xCC
ILChicago column=0:\x00\x00\x00\x00, timestamp=1533648673334, value=x
结论:
1.之前定义的Primary key 为state,city, 于是Phoenix就把输入的state,city的值拼起来成为rowkey。
2.其他的字段还是按照列名去保存,默认的列族为0。
3.还有一个0:_0这个列是没有值的,这个是Phoenix处于性能方面考虑增加的一个列,不用管这个列。
1.4.2 命令行方式
1.4.2.1 执行命令
[root@bigdata3 bin]# pwd
/home/bigdata/installed/phoenix/bin
[root@bigdata3 bin]# ./sqlline.py bigdata3:2181 端口号可以不写1.4.2.2 可以进入命令行模式
0: jdbc:phoenix:bigdata3:2181>然后执行相关的命令
1.4.2.3 退出命令行方式
执行 !quit
1.4.2.4 命令开头需要一个感叹号
使用help可以打印出所有命令
0: jdbc:phoenix:bigdata3:2181> help
!all Execute the specified SQL against all the current
connections
!autocommit Set autocommit mode on or off
!batch Start or execute a batch of statements
!brief Set verbose mode off
!call Execute a callable statement
!close Close the current connection to the database
!closeall Close all current open connections
!columns List all the columns for the specified table
!commit Commit the current transaction (if autocommit is off)
!connect Open a new connection to the database.
!dbinfo Give metadata information about the database
!describe Describe a table
!dropall Drop all tables in the current database
!exportedkeys List all the exported keys for the specified table
!go Select the current connection
!help Print a summary of command usage
!history Display the command history
!importedkeys List all the imported keys for the specified table
!indexes List all the indexes for the specified table
!isolation Set the transaction isolation for this connection
!list List the current connections
!manual Display the SQLLine manual
!metadata Obtain metadata information
!nativesql Show the native SQL for the specified statement
!outputformat Set the output format for displaying results
(table,vertical,csv,tsv,xmlattrs,xmlelements)
!primarykeys List all the primary keys for the specified table
!procedures List all the procedures
!properties Connect to the database specified in the properties file(s)
!quit Exits the program
!reconnect Reconnect to the database
!record Record all output to the specified file
!rehash Fetch table and column names for command completion
!rollback Roll back the current transaction (if autocommit is off)
!run Run a script from the specified file
!save Save the current variabes and aliases
!scan Scan for installed JDBC drivers
!script Start saving a script to a file
!set Set a sqlline variable
Variable Value Description
=============== ========== ================================
autoCommit true/false Enable/disable automatic
transaction commit
autoSave true/false Automatically save preferences
color true/false Control whether color is used
for display
fastConnect true/false Skip building table/column list
for tab-completion
force true/false Continue running script even
after errors
headerInterval integer The interval between which
headers are displayed
historyFile path File in which to save command
history. Default is
$HOME/.sqlline/history (UNIX,
Linux, Mac OS),
$HOME/sqlline/history (Windows)
incremental true/false Do not receive all rows from
server before printing the first
row. Uses fewer resources,
especially for long-running
queries, but column widths may
be incorrect.
isolation LEVEL Set transaction isolation level
maxColumnWidth integer The maximum width to use when
displaying columns
maxHeight integer The maximum height of the
terminal
maxWidth integer The maximum width of the
terminal
numberFormat pattern Format numbers using
DecimalFormat pattern
outputFormat table/vertical/csv/tsv Format mode for
result display
propertiesFile path File from which SqlLine reads
properties on startup; default is
$HOME/.sqlline/sqlline.properties
(UNIX, Linux, Mac OS),
$HOME/sqlline/sqlline.properties
(Windows)
rowLimit integer Maximum number of rows returned
from a query; zero means no
limit
showElapsedTime true/false Display execution time when
verbose
showHeader true/false Show column names in query
results
showNestedErrs true/false Display nested errors
showWarnings true/false Display connection warnings
silent true/false Be more silent
timeout integer Query timeout in seconds; less
than zero means no timeout
trimScripts true/false Remove trailing spaces from
lines read from script files
verbose true/false Show verbose error messages and
debug info
!sql Execute a SQL command
!tables List all the tables in the database
!typeinfo Display the type map for the current connection
!verbose Set verbose mode on
Comments, bug reports, and patches go to ???
0: jdbc:phoenix:bigdata3:2181>1.4.2.5 建立employee的映射表—数据准备
数据准备然后我们来建立一个映射表,映射我之前建立过的一个hbase表 employee.有2个列族 company、family
create 'employee','company','family'
put 'employee','row1','company:name','ted'
put 'employee','row1','company:position','worker'
put 'employee','row1','family:tel','13600912345'
put 'employee','row2','company:name','michael'
put 'employee','row2','company:position','manager'
put 'employee','row2','family:tel','1894225698'
scan 'employee'在建立映射表之前要说明的是,Phoenix是大小写敏感的,并且所有命令都是大写,如果你建的表名没有用双引号括起来,那么无论你输入的是大写还是小写,建立出来的表名都是大写的,如果你需要建立出同时包含大写和小写的表名和字段名,请把表名或者字段名用双引号括起来。
你可以建立读写的表或者只读的表,他们的区别如下
1.读写表:如果你定义的列簇不存在,会被自动建立出来,并且赋以空值
2.只读表:你定义的列簇必须事先存在1.4.2.6 建立映射表
0: jdbc:phoenix:bigdata3:2181>CREATE TABLE IF NOT EXISTS "employee" ("no" VARCHAR(10) NOT NULL PRIMARY KEY, "company"."name" VARCHAR(30),"company"."position" VARCHAR(20), "family"."tel" VARCHAR(20), "family"."age" INTEGER);这个语句有几个注意点
- IF NOT EXISTS可以保证如果已经有建立过这个表,配置不会被覆盖
- 作为rowkey的字段用 PRIMARY KEY标定
- 列簇用 columnFamily.columnName 来表示
- family.age 是新增的字段,我之前建立测试数据的时候没有建立这个字段的原因是在hbase shell下无法直接写入数字型,等等我用UPSERT 命令插入数据的时候你就可以看到真正的数字型在hbase 下是如何显示的
建立好后,查询一下数据
1.4.2.7 查询映射表数据
0: jdbc:phoenix:bigdata3:2181> SELECT * FROM "employee";
+-------+----------+-----------+--------------+-------+
| no | name | position | tel | age |
+-------+----------+-----------+--------------+-------+
| row1 | ted | worker | 13600912345 | null |
| row2 | michael | manager | 1894225698 | null |
+-------+----------+-----------+--------------+-------+1.4.2.8 插入数据、更改数据
插入或者更改数据在phoenix中使用upsert关键字,
如果表中不存在该数据则插入,否则更新
插入:
0: jdbc:phoenix:bigdata3:2181> upsert INTO "employee" VALUES ('row3','billy','worker','16974681345',33);
修改数据:
0: jdbc:phoenix:bigdata3:2181> UPSERT INTO "employee" ("no","tel") VALUES ('row2','13588888888');查询:
0: jdbc:phoenix:bigdata3:2181:2181> select * from "employee";
+-------+----------+-----------+--------------+-------+
| no | name | position | tel | age |
+-------+----------+-----------+--------------+-------+
| row1 | ted | worker | 13600912345 | null |
| row2 | michael | manager | 13588888888 | null |
| row3 | billy | worker | 16974681345 | 33 |
+-------+----------+-----------+--------------+-------+
3 rows selected (0.06 seconds)1.4.2.9 查询Hbase数据
hbase(main):056:0> scan 'employee'
ROW COLUMN+CELL
row1 column=company:_0, timestamp=1484730892661, value=
row1 column=company:name, timestamp=1484730892527, value=ted
row1 column=company:position, timestamp=1484730892565, value=worker
row1 column=family:tel, timestamp=1484730892661, value=13600912345
row2 column=company:_0, timestamp=1484730892762, value=
row2 column=company:name, timestamp=1484730892702, value=michael
row2 column=company:position, timestamp=1484730892730, value=manager
row2 column=family:tel, timestamp=1484730892762, value=13588888888
row3 column=company:_0, timestamp=1484809036587, value=x
row3 column=company:name, timestamp=1484809036587, value=billy
row3 column=company:position, timestamp=1484809036587, value=worker
row3 column=family:age, timestamp=1484809036587, value=\x80\x00\x00!
row3 column=family:tel, timestamp=1484809036587, value=16974681345 1.4.3 GUI方式
1.4.3.1 squirrel下载
从网址http://www.squirrelsql.org/下载相应版本的squirrel的安装jar包,比如下载squirrel-sql-3.8.1-standard.jar window版本。
1.4.3.2 squirrel安装
Window下:通过cmd进入window控制台,
输入 java -jar squirrel-sql-3.8.1-standard.jar
显示安装界面。
出现安装界面之后,一直点击下一步下一步,直到最终执行完毕。
点击Done,最后在桌面就有一个Squirrel
1.4.3.3 squirrel配置连接Phoenix
(1)配置squirrel
解压的apache-phoenix-4.14.0-HBase-1.4-bin.tar.gz包的主目录下将如下几个jar包拷贝到squirrel安装目录的lib下
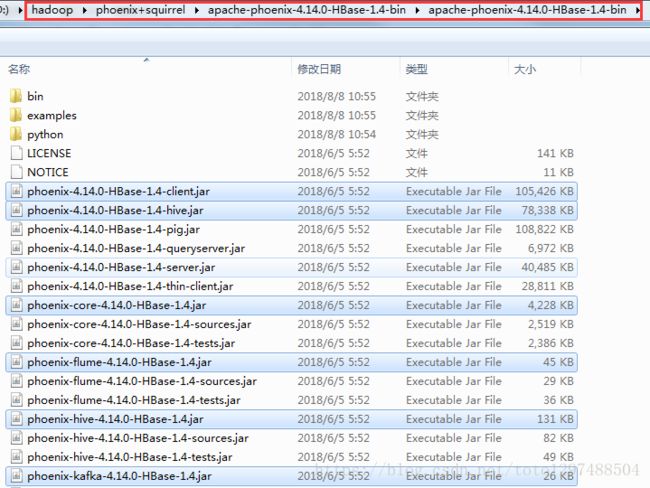
即:
在安装目录下双击squirrel-sql.bat、点击左侧的Drivers,添加图标
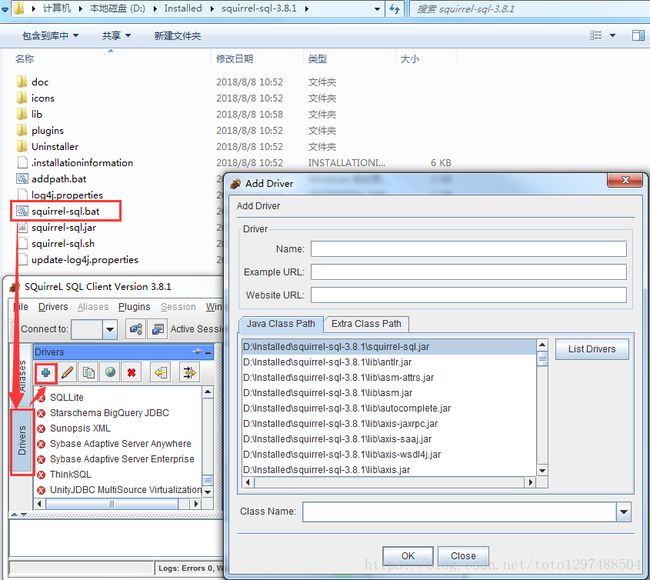
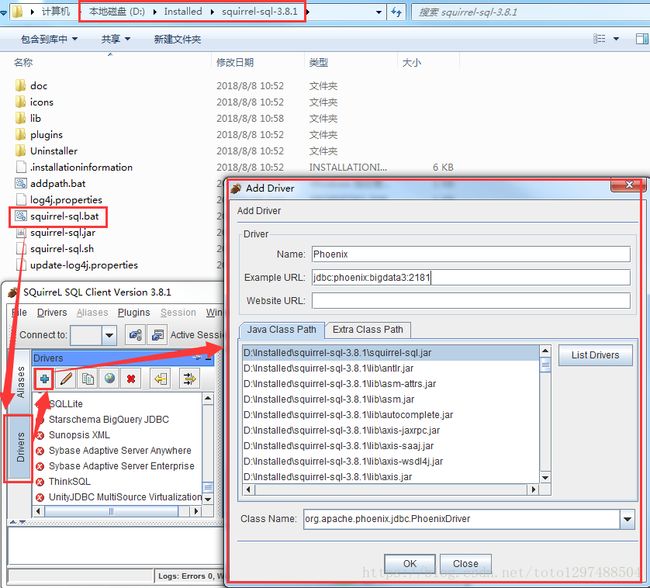
配置说明:
在出现的窗口中填写如下项
Name:就是个名字任意取就可以,这里使用phoenix
Example URL :jdbc:phoenix:bigdata1:2181(这里是你的phonenix的jdbc地址,注意端口也可以不写,多个用逗号隔开)
Class Name:org.apache.phoenix.jdbc.PhoenixDriver
1.4.3.4 连接Phoenix
点击Aiiasses,点击右边的添加图标
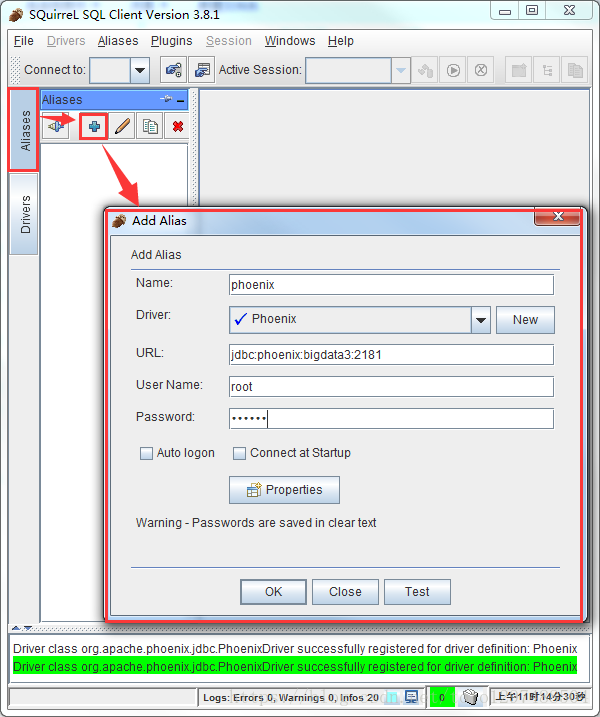
配置说明:
这里还是名字随意写(这里使用phoenix),driver要选择刚才配置的可用的driver,我们刚才配置的是phoenix
url这里就是连接phonex的url选择了phoenix的driver以后自动出现也可以改,user name就是phoenix连接的主机的用户名,密码就是该机器的密码,点击自动登录
然后点击test,显示连接成功即可(在这里最好不要直接点OK,先点Test,连接成功了再OK)
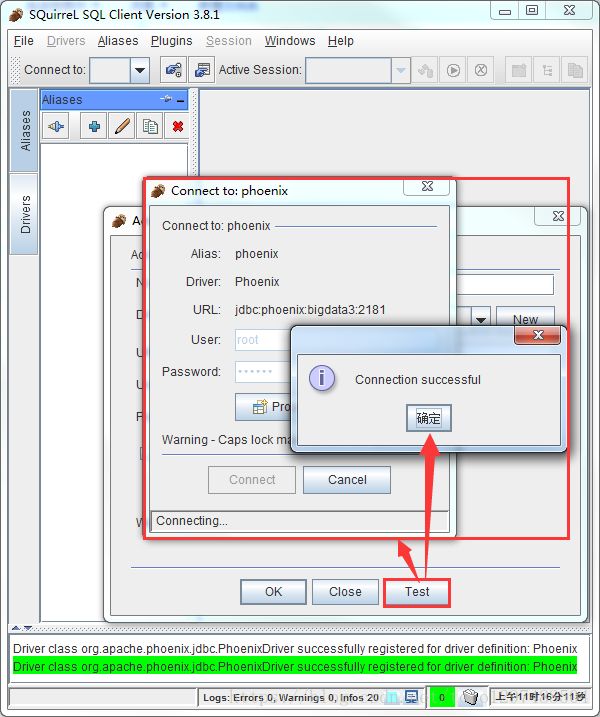
点击OK按钮
查看对应的表
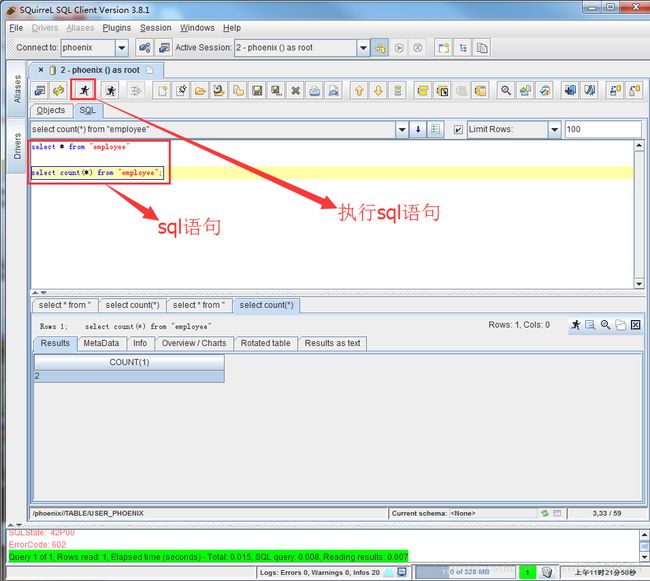
通过sql语句查询数据
1.4.4 JDBC调用方式
打开idea建立一个简单的Maven项目 phoenix
pom.xml文件内容:
<project xmlns="http://maven.apache.org/POM/4.0.0"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0modelVersion>
<groupId>com.test.phoenixgroupId>
<artifactId>phoenix-testartifactId>
<version>1.0-SNAPSHOTversion>
<properties>
<project.build.sourceEncoding>UTF-8project.build.sourceEncoding>
properties>
<dependencies>
<dependency>
<groupId>junitgroupId>
<artifactId>junitartifactId>
<version>3.8.1version>
dependency>
<dependency>
<groupId>org.apache.phoenixgroupId>
<artifactId>phoenix-coreartifactId>
<version>4.14.0-HBase-1.4version>
dependency>
dependencies>
project>建立一个类 PhoenixManager
package com.test.phoenix;
import java.sql.*;
public class PhoenixManager {
public static void main(String[] args) throws SQLException {
Connection conn = null;
Statement state = null;
ResultSet rs = null;
try {
Class.forName("org.apache.phoenix.jdbc.PhoenixDriver");
conn = DriverManager.getConnection("jdbc:phoenix:bigdata3:2181");
state = conn.createStatement();
rs= state.executeQuery("select * from \"employee\"");
while(rs.next()){
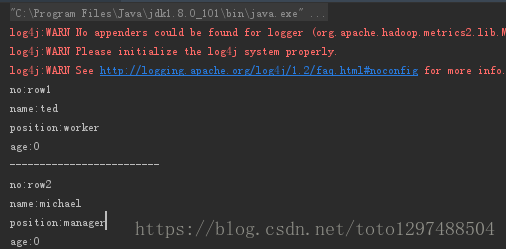
System.out.println("no:"+rs.getString("no"));
System.out.println("name:"+rs.getString("name"));
System.out.println("position:"+rs.getString("position"));
System.out.println("age:"+rs.getInt("age"));
System.out.println("-------------------------");
}
}catch (Exception e) {
e.printStackTrace();
} finally {
if (rs != null) rs.close();
if (state != null) state.close();
if (conn != null) conn.close();
}
}
}运行结果展现: