golang接口与反射剖析
interface的实质
golang中的interface是什么
接口相当于是一份契约,它规定了一个对象所能提供的一组操作。要理解golang中接口的概念我们最好还是先来看看别的现代语言是如何实现接口的。
C++没有提供interface这样的关键字,它通过纯虚基类实现接口,而java则通过interface关键字声明接口。它们有个共同特征就是一个类要实现该接口必须进行显示的声明,如下是java方式:
interface IFoo {
void Bar();
}
class Foo implements IFoo {
void Bar(){}
}
这种必须明确声明自己实现了 某个接口的方式我们称为侵入式接口。关于侵入式接口的坏处我们这里就不再详细讨论,看java庞大的继承体系及其繁复的接口类型我们就可以窥之一二了。
golang则采取了完全不同的设计理念,在Go语言中,一个类只需要实现了接口要求的所有函数,我们就说这个类实现了该接口, 例如:
type IWriter interface {
Write(buf [] byte) (n int, err error)
}
type File struct {
// ...
}
func (f *File) Write(buf [] byte) (n int, err error) {
// ...
}
非侵入式接口一个很重要的好处就是去掉了繁杂的继承体系,我们看许大神在《go语言编程》一书中作的总结:
其一, Go语言的标准库,再也不需要绘制类库的继承树图。你一定见过不少C++、 Java、 C# 类库的继承树图。这里给个Java继承树图。 在Go中,类的继承树并无意义,你只需要知道这个类实现了哪些方法,每个方法是啥含义就足够了。
其二,实现类的时候,只需要关心自己应该提供哪些方法,不用再纠结接口需要拆得多细才 合理。接口由使用方按需定义,而不用事前规划。
其三,不用为了实现一个接口而导入一个包,因为多引用一个外部的包,就意味着更多的耦 合。接口由使用方按自身需求来定义,使用方无需关心是否有其他模块定义过类似的接口。
如果仔细研究golang中的结构,学C++的同学可能会发现,golang中关于接口的概念很似有点像C++中的Concept,不知道concept的同学可以参看刘未鹏的《C++0x漫谈》系列之:Concept, Concept! 。c++用模板来达到这样的效果,不管你使用什么类型来实例化,只要满足该模板所对应的一组操作就可以正常实例化,否则则会编译不通过。不同于C++的模板在可以完全在编译时检查,golang在大多数情况下只能在运行时进行接口查询,关于接口查询的详细情况我们稍后再解释。
另外,如果有同学之前了解过Qt,则很容易的发现这种非侵入式接口的另一个好处,Qt里面一个重要的特性就是信号与槽,它实现了监听者与接收者之间的解耦,它所用的方式实际上是qt的预处理生成静态的连接代码。而如果使用golang来实现这套机制就简直在方便了,不需要预先生成代码的方式,监听者与接收者之间的解耦本身就是golang的自然表现。
golang中的interface在面向对象思想中所扮演的角色
golang不支持完整的面向对象思想,它没有继承,多态则完全依赖接口实现。golang只能模拟继承,其本质是组合,只不过golang语言为我们提供了一些语法糖使其看起来达到了继承的效果。面向对象中一个很重要的基本原则--里氏代换原则(Liskov Substitution Principle LSP)在这里就行不通了,习惯面向对象语言的同学可能会有些不适应,当你将一个父类的指针指向子类的对象时,golang会毫不吝啬的抛出一个编译错误。
golang的设计理念是大道至简,传统的继承概念在golang中已经显得不是那么必要,golang通过接口去实现多态,下面我们看一个例子,看看golang是如何实现依赖倒置原则的,先看C++的实现:
struct IPizzaCooker {
virtual void Prepare(Pizza*) = 0;
virtual void Bake(Pizza*) = 0;
virtual void Cut(Pizza*) = 0;
}
struct PizzaDefaultCooker : public IPizzaCooker {
Pizza* CookOnePizza() {
Pizza* p = new Pizza();
Prepare(p);
Bake(p);
Cut(p);
return p;
}
virtual void Prepare(Pizza*) {
//....default prepare pizza
}
virtual void Bake(Pizza*) {
//....default bake pizza
}
virtual void Cut(Pizza*) {
//....default cut pizza
}
}
struct MyPizzaCooker : public PizzaDefaultCooker {
virtual void Bake(Pizza*) {
//....bake pizza use my style
}
}
int main() {
MyPizzaCooker cooker;
Pizza* p = cooker.CookOnePizza();
//....
return 0;
}
本例子很简单,就是通过一个做pizza的类烹饪一个新pizza,烹饪的流程在父类中实现CookOnePizza,子类重写了Bake方法。下面我们看看golang中是如何实现这个例子的:
type IPizzaCooker interface {
Prepare(*Pizza)
Bake(*Pizza)
Cut(*Pizza)
}
func cookOnePizza(ipc IPizzaCooker) *Pizza {
p := new(Pizza)
ipc.Prepare(p)
ipc.Bake(p)
ipc.Cut(p)
return p
}
type PizzaDefaultCooker struct {
}
func (this *PizzaDefaultCooker) CookOnePizza() *Pizza {
return cookOnePizza(this)
}
func (this *PizzaDefaultCooker) Prepare(*Pizza) {
//....default prepare pizza
}
func (this *PizzaDefaultCooker) Bake(*Pizza) {
//....default bake pizza
}
func (this *PizzaDefaultCooker) Cut(*Pizza) {
//....default cut pizza
}
type MyPizzaCooker struct {
PizzaDefaultCooker
}
func (this *MyPizzaCooker) CookOnePizza() *Pizza {
return cookOnePizza(this)
}
func (this *MyPizzaCooker) Bake(*Pizza) {
//....bake pizza use my style
}
func main() {
var cooker MyPizzaCooker
p := cooker.CookOnePizza()
//....
}
由于golang的多态必须借助接口来实现,这实际上已不是严格意义上的依赖倒置了,在这个例子中golang显得有些笨拙,它其实完全可以有更优雅的实现方案,举这个例子只是为了给大家介绍多态在golang中的实现方式,以及所谓模拟继承并不等价于面向对象中的继承关系。
interface的内存布局
了解interface的内存结构是非常有必要的,只有了解了这一点,我们才能进一步分析诸如类型断言等情况的效率问题。先看一个例子:
type Stringer interface {
String() string
}
type Binary uint64
func (i Binary) String() string {
return strconv.Uitob64(i.Get(), 2)
}
func (i Binary) Get() uint64 {
return uint64(i)
}
func main() {
b := Binary{}
s := Stringer(b)
fmt.Print(s.String())
}
interface在内存上实际由两个成员组成,如下图,tab指向虚表,data则指向实际引用的数据。虚表描绘了实际的类型信息及该接口所需要的方法集
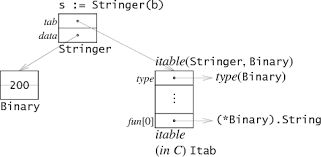
观察itable的结构,首先是描述type信息的一些元数据,然后是满足Stringger接口的函数指针列表(注意,这里不是实际类型Binary的函数指针集哦)。因此我们如果通过接口进行函数调用,实际的操作其实就是s.tab->fun[0](s.data)。是不是和C++的虚表很像?接下来我们要看看golang的虚表和C++的虚表区别在哪里。
先看C++,它为每种类型创建了一个方法集,而它的虚表实际上就是这个方法集本身或是它的一部分而已,当面临多继承时(或者叫实现多个接口时,这是很常见的),C++对象结构里就会存在多个虚表指针,每个虚表指针指向该方法集的不同部分,因此,C++方法集里面函数指针有严格的顺序。许多C++新手在面对多继承时就变得蛋疼菊紧了,因为它的这种设计方式,为了保证其虚表能够正常工作,C++引入了很多概念,什么虚继承啊,接口函数同名问题啊,同一个接口在不同的层次上被继承多次的问题啊等等……就是老手也很容易因疏忽而写出问题代码出来。
我们再来看golang的实现方式,同C++一样,golang也为每种类型创建了一个方法集,不同的是接口的虚表是在运行时专门生成的。可能细心的同学能够发现为什么要在运行时生成虚表。因为太多了,每一种接口类型和所有满足其接口的实体类型的组合就是其可能的虚表数量,实际上其中的大部分是不需要的,因此golang选择在运行时生成它,例如,当例子中当首次遇见s := Stringer(b)这样的语句时,golang会生成Stringer接口对应于Binary类型的虚表,并将其缓存。
理解了golang的内存结构,再来分析诸如类型断言等情况的效率问题就很容易了,当判定一种类型是否满足某个接口时,golang使用类型的方法集和接口所需要的方法集进行匹配,如果类型的方法集完全包含接口的方法集,则可认为该类型满足该接口。例如某类型有m个方法,某接口有n个方法,则很容易知道这种判定的时间复杂度为O(mXn),不过可以使用预先排序的方式进行优化,实际的时间复杂度为O(m+n)。
反射的实质
反射来自元编程,指通过类型检查变量本身数据结构的方式,只有部分编程语言支持反射。
类型
反射构建在类型系统之上,Go是静态类型语言,每一个变量都有静态类型,在编译时就确定下来了。
比如:
type MyInt int
var i int
var j MyInt
i和j的底层类型都是int,但i的静态类型是int,j的静态类型是MyInt,这两个是不同类型,是不能直接赋值的,需要类型强制转换。
接口类型比较特殊,接口类型的变量被多种对象类型赋值,看起来像动态语言的特性,但变量类型始终是接口类型,Go是静态的。举例:
var r io.Reader
r = os.Stdin
r = bufio.NewReader(r)
r = new(bytes.Buffer)
// and so on
虽然r被3种类型的变量赋值,但r的类型始终是io.Reader。
最特别:空接口
interface{}的变量可以被任何类型的值赋值,但类型一直都是interface{}。
接口的表示
Russ Cox(Go语言创始人)在他的博客详细介绍了Go语言接口,结论是:
接口类型的变量存储的是一对数据:
-
变量实际的值
-
变量的静态类型
例子:
var r io.Reader
tty, err := os.OpenFile("/dev/tty", os.O_RDWR, 0)
if err != nil {
return nil, err
}
r = tty
r是接口类型变量,保存了值tty和tty的类型*os.File,所以才能使用类型断言判断r保存的值的静态类型:
var w io.Writer
w = r.(io.Writer)
虽然r中包含了tty和它的类型,包含了tty的所有函数,但r是接口类型,决定了r只能调用接口io.Reader中包含的函数。
记住:接口变量保存的不是接口类型的值,还是英语说起来更方便:Interfaces do not hold interface values.
反射的3条定律
定律1:从接口值到反射对象
反射是一种检测存储在接口变量中值和类型的机制。通过reflect包的一些函数,可以把接口转换为反射定义的对象。
掌握reflect包的以下函数:
-
reflect.ValueOf({}interface) reflect.Value:获取某个变量的值,但值是通过reflect.Value对象描述的。 -
reflect.TypeOf({}interface) reflect.Type:获取某个变量的静态类型,但值是通过reflect.Type对象描述的,是可以直接使用Println打印的。 -
reflect.Value.Kind() Kind:获取变量值的底层类型(类别),注意不是类型,是Int、Float,还是Struct,还是Slice,具体见此。 -
reflect.Value.Type() reflect.Type:获取变量值的类型,效果等同于reflect.TypeOf。
再解释下Kind和Type的区别,比如:
type MyInt int
var x MyInt = 7
v := reflect.ValueOf(x)
v.Kind()得到的是Int,而Type得到是MyInt。
定律2:从反射对象到接口值
定律2是定律1的逆向过程,上面我们学了:普通变量 -> 接口变量 -> 反射对象的过程,这是从反射对象 -> 接口变量的过程,使用的是Value的Interface函数,是把实际的值赋值给空接口变量,它的声明如下:
func (v Value) Interface() (i interface{})
回忆一下:接口变量存储了实际的值和值的类型,Println可以根据接口变量实际存储的类型自动识别其值并打印。
注意事项:如果Value是结构体的非导出字段,调用该函数会导致panic。
定律3:当反射对象所存的值是可设置时,反射对象才可修改
从定律1入手理解,定律3就不再那么难懂。
Settability is a property of a reflection Value, and not all reflection Values have it.
可设置指的是,可以通过Value设置原始变量的值。
通过函数的例子思考一下可设置:
func f(x int)
在调用f的时候,传入了参数x,从函数内部修改x的值,外部的变量的值并不会发生改变,因为这种是传值,是拷贝的传递方式。
func f(p *int)
函数f的入参是指针类型,在函数内部的修改变量的值,函数外部变量的值也会跟着变化。
使用反射也是这个原理,如果创建Value时传递的是变量,则Value是不可设置的。如果创建Value时传递的是变量地址,则Value是可设置的。
可以使用Value.CanSet()检测是否可以通过此Value修改原始变量的值。
x := 10
v1 := reflect.ValueOf(x)
fmt.Println("setable:", v1.CanSet())
p := reflect.ValueOf(&x)
fmt.Println("setable:", p.CanSet())
v2 := p.Elem()
fmt.Println("setable:", v2.CanSet())
如何通过Value设置原始对象值呢?
Value.SetXXX()系列函数可设置Value中原始对象的值。
系列函数有:
-
Value.SetInt()
-
Value.SetUint()
-
Value.SetBool()
-
Value.SetBytes()
-
Value.SetFloat()
-
Value.SetString()
-
…
设置函数这么多,到底该选用哪个Set函数?
根据Value.Kind()的结果去获得变量的底层类别,然后选用该类别的Set函数。
参考文献
1.《go语言编程》 许世伟
2. https://blog.golang.org/laws-of-reflection
3. https://blog.csdn.net/justaipanda/article/details/43155949