高并发编程之高并发场景:秒杀(无锁、排他锁、乐观锁、redis缓存的逐步演变)
环境:
jdk1.8;spring boot2.0.2;Maven3.3
摘要说明:
在实际开发过程中往往会出现许多高并发场场景,秒杀,强红包,抢优惠卷等;
其中:
秒杀场景的特点就是单位时间涌入用户量极大,商品数少,且要保证不可超量销售;
秒杀产品的本质就是减库存;
秒杀场景常用的解决方案有限流、削峰、拓展等
本篇以秒杀场景为依据来主要从代码开发的角度阐述从无锁——》排他锁——》共享锁——》缓存中间件的一步步升级来不断完善及优化;同时也针对整体架构提出一些优化方案;
步骤:
1.准备高并发测试工具类
引入高并发编程的工具类:java.util.concurrent.CountDownLatch(发令枪)来进行模拟大批量用户高并发测试;
java.util.concurrent.CountDownLatch(发令枪):一个同步辅助类,控制一组线程的启动,当一组线程未完全准备好之前控制准备好一个或多个线程一直等待。犹如倒计时计数器,调用CountDownLatch对象的countDown方法就将计数器减1,当计数到达0时,则意味着这组线程完全准备好。此时通知所有等待者即整组线程同时开始执行。
package com.example.demo_20180925;
import java.util.Map;
import java.util.concurrent.CountDownLatch;
import org.junit.Before;
import org.junit.Test;
import org.junit.runner.RunWith;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.boot.test.context.SpringBootTest;
import org.springframework.boot.test.context.SpringBootTest.WebEnvironment;
import org.springframework.test.context.junit4.SpringRunner;
import com.example.demo_20180925.pojo.ProductInfo;
import com.example.demo_20180925.service.ProductInfoService;
@RunWith(SpringRunner.class)
// 引入SpringBootTest并生成随机接口
@SpringBootTest(webEnvironment = WebEnvironment.RANDOM_PORT)
public class Demo20180925ApplicationTests {
// 商品代码
private static final String CODE = "IPONE XR";
// 商品总数
private static final Long PRODUCTCOUNT = (long) 1000;
// 并发人数
private static final int USER_NUM = 1000;
// 发令枪;用于模拟高并发
private static CountDownLatch countDownLatch = new CountDownLatch(USER_NUM);
// 计数器,用于记录成功购买客户人数
private static int successPerson = 0;
// 计数器,用于记录卖出去对的商品个数
private static int saleOutNum = 0;
// 计数器,用于记录处理总时间
private static long doTime = 0;
// 计数器,用于记录处理最长时间
private static long maxTime = 0;
@Autowired
ProductInfoService productInfoService;
@Before
public void init() {
// 初始化库存
ProductInfo productInfo = new ProductInfo();
productInfo.setProductCode(CODE);
productInfo.setProductCount(PRODUCTCOUNT);
this.productInfoService.updateFirst(productInfo);
}
@Test
public void testSeckill() throws InterruptedException {
// 循环初始换USER_NUM个请求实例
for (int i = 0; i < USER_NUM; i++) {
new Thread(new BuyProduct(CODE, (long) 3)).start();
if (i == USER_NUM) {
Thread.currentThread().sleep(2000);// 最后一个子线程时休眠两秒等待所有子线程全部准备好
}
countDownLatch.countDown();// 发令枪减1,到0时启动发令枪
}
Thread.currentThread().sleep(30 * 1000);// 主线程休眠10秒等待结果
// Thread.currentThread().join();
System.out.println("购买成功人数:" + successPerson);
System.out.println("销售成功个数:" + saleOutNum);
System.out.println("剩余个数:"
+ productInfoService.selectByCode(CODE).getProductCount());
System.out.println("处理时间:" + doTime);
}
public class BuyProduct implements Runnable {
private String code;
private Long buys;
public BuyProduct(String code, Long buys) {
this.code = code;
this.buys = buys;
}
public void run() {
try {
countDownLatch.await();// 所有子线程运行到这里休眠,等待发令枪指令
} catch (InterruptedException e) {
// TODO Auto-generated catch block
e.printStackTrace();
}
// 直接减库存
// Map map = productInfoService.update(code, buys);
// 加排他锁(悲观锁)后减库存
Map map = productInfoService.selectForUpdate(code,
buys);
// 根据版本号加乐观锁减库存
// Map map =
// productInfoService.updateByVersion(code,
// buys);
// 根据库存加乐观锁减库存
// Map map = productInfoService.updateByBuys(code,
// buys);
// 根据缓存减库存
// Map map = productInfoService.updateByRedis(code,
// buys);
if ((boolean) map.get("result")) {
synchronized (countDownLatch) {
// 更新库存成功,修改购买成功人数及销售产品数量
successPerson++;
// 记录总购买成功人数
saleOutNum = (int) (saleOutNum + buys);
// 记录总消费时间
doTime = doTime + (long) map.get("time");
// 记录最大时间
if (maxTime < (long) map.get("time")) {
maxTime = (long) map.get("time");
}
}
}
}
}
}
2.无锁开发
许多开发对高并发编程及数据库锁的机制不是很理解,开发时就很简单的查询库存然后更新库存即select——》update;此时在高并发的环境下测试就会出现产品过多销售的情况;
@Service
public class ProductInfoServiceImpl implements ProductInfoService {
@Autowired
ProductInfoMapper productInfoMapper;
@Autowired
RedisTemplate redisTemplate;
private static long threadCount = 0;
/**
* 根据产品代码查询产品
*/
@Override
public ProductInfo selectByCode(String code) {
return productInfoMapper.findByCode(code);
}
/**
* 初始化库存
*/
@Override
public boolean updateFirst(ProductInfo productInfo) {
redisTemplate.opsForHash().put("productCount",
productInfo.getProductCode(), productInfo.getProductCount());
return productInfoMapper.updateForFirst(productInfo.getProductCode(),
productInfo.getProductCount()) > 0 ? true : false;
}
/**
* 直接减库存
*/
@Override
public Map update(String code, Long buys) {
threadCount++;
System.out.println("开启线程:" + threadCount);
Date date = new Date();
Map map = new HashMap();
ProductInfo productInfo = productInfoMapper.findByCode(code);
if (productInfo.getProductCount() < buys) {
map.put("result", false);
Date date1 = new Date();
map.put("time", date1.getTime() - date.getTime());
return map;
}
map.put("result", productInfoMapper.update(code, buys) > 0 ? true
: false);
Date date1 = new Date();
map.put("time", date1.getTime() - date.getTime());
return map;
}
} 我们执行下可以看到结果:
1000个人,每个人购买3个商品,商品总数1000个,理论上购买成功人数应该为333,商品销售成功个数应该为999;
但实际购买成功人数560,销售商品个数为1680;远远的过度销售;
开启线程:993
开启线程:991
开启线程:996
开启线程:995
开启线程:997
开启线程:998
开启线程:999
开启线程:1000
购买成功人数:560
销售成功个数:1680
剩余个数:-680
处理时间:2424240
最大处理时间:32202.锁的分类
数据库锁的机制从不同角度出发可进行不同的分类:
从颗粒度上可划分(基于mysql):
- 表级锁:表级锁是MySQL中锁定粒度最大的一种锁,表示对当前操作的整张表加锁,它实现简单,资源消耗较少,被大部分MySQL引擎支持;特点:开销小,加锁快;不会出现死锁;锁定粒度大,发出锁冲突的概率最高,并发度最低。
- 行级锁:行级锁是Mysql中锁定粒度最细的一种锁,表示只针对当前操作的行进行加锁。行级锁能大大减少数据库操作的冲突。其加锁粒度最小,但加锁的开销也最大。特点:开销大,加锁慢;会出现死锁;锁定粒度最小,发生锁冲突的概率最低,并发度也最高。
- 页级锁:页级锁是MySQL中锁定粒度介于行级锁和表级锁中间的一种锁。表级锁速度快,但冲突多,行级冲突少,但速度慢。所以取了折衷的页级,一次锁定相邻的一组记录。BDB支持页级锁;特点:开销和加锁时间界于表锁和行锁之间;会出现死锁;锁定粒度界于表锁和行锁之间,并发度一般
从级别上进行划分:
- 共享锁:又称读锁,是读取操作创建的锁。其他用户可以并发读取数据,但任何事务都不能对数据进行修改(获取数据上的排他锁),直到已释放所有共享锁。如果事务T对数据A加上共享锁后,则其他事务只能对A再加共享锁,不能加排他锁。获准共享锁的事务只能读数据,不能修改数据。
- 排他锁:又称写锁,如果事务T对数据A加上排他锁后,则其他事务不能再对A加任任何类型的封锁。获准排他锁的事务既能读数据,又能修改数据。
从使用方式上进行划分:
- 乐观锁:是一种并发控制的方法。它假设多用户并发的事务在处理时不会彼此互相影响,各事务能够在不产生锁的情况下处理各自影响的那部分数据。在提交数据更新之前,每个事务会先检查在该事务读取数据后,有没有其他事务又修改了该数据。如果其他事务有更新的话,正在提交的事务会进行回滚
- 悲观锁:是一种并发控制的方法。它可以阻止一个事务以影响其他用户的方式来修改数据。如果一个事务执行的操作都某行数据应用了锁,那只有当这个事务把锁释放,其他事务才能够执行与该锁冲突的操作。悲观并发控制主要用于数据争用激烈的环境,以及发生并发冲突时使用锁保护数据的成本要低于回滚事务的成本的环境中。
从操作上进行划分:
- DML锁:用于保护数据的完整性,其中包括行级锁(Row Locks (TX锁))、表级锁(table lock(TM锁))。
- DDL锁:用于保护数据库对象的结构,如表、索引等的结构定义。其中包排他DDL锁(Exclusive DDL lock)、共享DDL锁(Share DDL lock)、可中断解析锁(Breakable parse locks)
3.排他锁(悲观锁)开发
通过上面对锁的机制介绍之后我们可以看到,排他锁可以很好的解决我们上面商品多销售的问题;排他锁的本质即排队执行;
mysql的排他锁的用法为:SELECT ... FOR UPDATE;
在查询语句后面增加FOR UPDATE,Mysql会对查询结果中的每行都加排他锁,当没有其他线程对查询结果集中的任何一行使用排他锁时,可以成功申请排他锁,否则会被阻塞。所以它本质上也是一个行级锁;
/**
* 根据产品代码查询产品信息;排他锁
*
* @param code
* 产品代码
* @return
*/
@Select("SELECT id,version,product_code as productCode,product_name as productName, product_count AS productCount FROM product_info WHERE product_code = #{code} for update")
ProductInfo selectForUpdate(@Param("code") String code);业务层:
/**
* 加排他锁减库存
*/
@Transactional
@Override
public Map selectForUpdate(String code, Long buys) {
threadCount++;
System.out.println("开启线程:" + threadCount);
Date date = new Date();
Map map = new HashMap();
ProductInfo productInfo = productInfoMapper.selectForUpdate(code);
if (productInfo.getProductCount() < buys) {
map.put("result", false);
Date date1 = new Date();
map.put("time", date1.getTime() - date.getTime());
return map;
}
map.put("result", productInfoMapper.update(code, buys) > 0 ? true
: false);
Date date1 = new Date();
map.put("time", date1.getTime() - date.getTime());
return map;
} 执行结果:
开启线程:979
开启线程:980
开启线程:981
开启线程:982
开启线程:983
开启线程:984
购买成功人数:333
销售成功个数:999
剩余个数:1
处理时间:4101
最大处理时间:160结果可以看到排他锁可以很好的控制住商品数量的销售;但排他锁的本质是排队,如果业务复杂或者并发人数过多的情况下会产生超时现象;
4.乐观锁开发
乐观锁的本质上并没有使用数据库本身的锁机制;只是在提交的那一刻通过sql查询条件来约束更新;
常规的是乐观锁一般有两种:
一种是破坏表的业务接口添加版本号(version)或者时间戳(timestamp );
一种是使用业务本身做约束;
版本号形式共享锁:
/**
* 根据购买数量及版本号减少库存
*
* @param code
* 产品代码
* @param buys
* 购买数量
* @param version
* 版本信息
* @return
*/
@Update("update product_info SET product_count=product_count - #{buys},version=version+1 WHERE product_code = #{code} and version = #{version}")
int updateByVersion(@Param("code") String code, @Param("buys") Long buys,
@Param("version") Long version);业务层:共享锁当约束条件不满足之后,需要在嵌套调用,直到满足条件或商品销售成功才停止;
/**
* 根据版本号加乐观锁减库存
*/
@Override
public Map updateByVersion(String code, Long buys) {
Date date = new Date();
Map map = new HashMap();
try {
threadCount++;
System.out.println("开启线程:" + threadCount);
ProductInfo productInfo = productInfoMapper.findByCode(code);
if (productInfo.getProductCount() < buys) {
map.put("result", false);
Date date1 = new Date();
map.put("time", date1.getTime() - date.getTime());
return map;
}
if (productInfoMapper.updateByVersion(code, buys,
productInfo.getVersion()) > 0 ? true : false) {
map.put("result", true);
Date date1 = new Date();
map.put("time", date1.getTime() - date.getTime());
return map;
}
waitForLock();
return updateByVersion(code, buys);
} catch (Exception e) {
System.err.println(e);
map.put("result", false);
Date date1 = new Date();
map.put("time", date1.getTime() - date.getTime());
return map;
}
}
// 错峰执行
private void waitForLock() {
try {
Thread.sleep(new Random().nextInt(10) + 1);
} catch (InterruptedException e) {
e.printStackTrace();
}
} 执行结果:
开启线程:1612
开启线程:1613
开启线程:1614
开启线程:1615
开启线程:1616
购买成功人数:333
销售成功个数:999
剩余个数:1
处理时间:428636
最大处理时间:3215结果可以看到乐观锁锁可以很好的控制住商品数量的销售;但我们也可以看到乐观锁会导致线程的循环执行,若业务要求先到先得的话一定程度上是不满足的;
通过业务销量来实现共享锁:
/**
* 根据购买数量及剩余库存减少库存
*
* @param code
* 产品代码
* @param buys
* 购买数量
* @return
*/
@Update("update product_info SET product_count=product_count - #{buys} WHERE product_code = #{code} and (product_count - #{buys})>0")
int updateByBuys(@Param("code") String code, @Param("buys") Long buys);业务层:由于我们使用商品数量本身作为约束;故不需要做嵌套调用
/**
* 根据库存加乐观锁减库存
*/
@Override
public Map updateByBuys(String code, Long buys) {
threadCount++;
System.out.println("开启线程:" + threadCount);
Date date = new Date();
Map map = new HashMap();
try {
ProductInfo productInfo = productInfoMapper.findByCode(code);
if (productInfo.getProductCount() < buys) {
map.put("result", false);
Date date1 = new Date();
map.put("time", date1.getTime() - date.getTime());
return map;
}
if (productInfoMapper.updateByBuys(code, buys) > 0 ? true : false) {
map.put("result", true);
}else{
map.put("result", false);
}
Date date1 = new Date();
map.put("time", date1.getTime() - date.getTime());
return map;
// waitForLock();
// return updateByBuys(code, buys);
} catch (Exception e) {
System.err.println(e);
map.put("result", false);
Date date1 = new Date();
map.put("time", date1.getTime() - date.getTime());
return map;
}
} 执行结果:
开启线程:456
购买成功人数:333
销售成功个数:999
剩余个数:1
处理时间:487387
最大处理时间:27595.缓存中间件
上述的使用数据库的两种锁机制是可以很好的解决问题;但若是我们不断增加并发数,就可以看到对数据库会造成很大的压力;实际生产环境,数据库本身的资源压力就很大;在这种关键入口处最好引入缓存数据库来过滤请求限流减少数据库压力;
本篇使用redis缓存,其中redis缓存和spring boot的集合这里就不赘述,请自行查看源码;
这里使用的是redis数据库的Hash类型中的Redis Hincrby 命令:用于为哈希表中的字段值加上指定增量值,增量值可为负。
HINCRBY KEY_NAME FIELD_NAME INCR_BY_NUMBER @Autowired
RedisTemplate redisTemplate;
@Override
public Map updateByRedis(String code, Long buys) {
threadCount++;
System.out.println("开启线程:" + threadCount);
Date date = new Date();
Map map = new HashMap();
long count = Long.valueOf(redisTemplate.opsForHash().get(
"productCount", code)
+ "");
if (count > 0) {
count = Long.valueOf(redisTemplate.opsForHash().increment(
"productCount", code, -buys));
if (count >= 0) {
map.put("result", true);
Date date1 = new Date();
map.put("time", date1.getTime() - date.getTime());
return map;
} else {
map.put("result", false);
Date date1 = new Date();
map.put("time", date1.getTime() - date.getTime());
return map;
}
} else {
map.put("result", false);
Date date1 = new Date();
map.put("time", date1.getTime() - date.getTime());
return map;
}
} 执行结果:
开启线程:926
开启线程:924
开启线程:923
购买成功人数:333
销售成功个数:999
剩余个数:1000
处理时间:69702
最大处理时间:4626.拓展
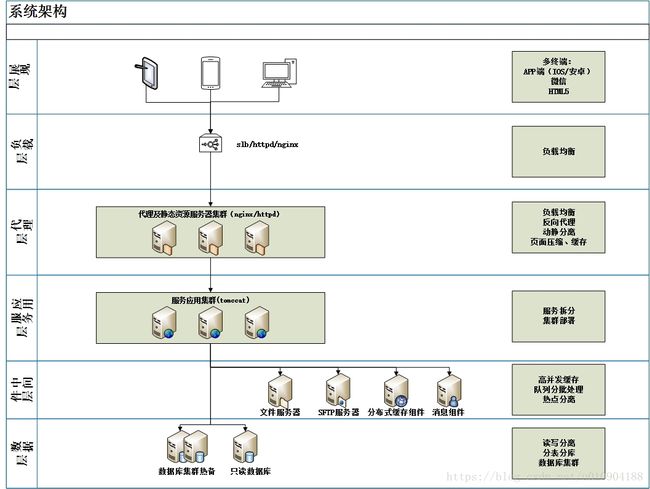
上述代码开发的演变不可能就此解决高并发带给体统的压力;这里就阐述下从整体架构上去提高服务的并发能力:
展现层:
禁止重复提交:用户提交之后按钮置灰,禁止重复提交
用户限流:在某一时间段内只允许用户提交一次请求
代理层:
动静分离:将所有静态资源放在apache httpd或者nginx服务下;减轻后端服务压力;本身处理静态资源能里也大于tomcat;
页面压缩、缓存:针对静态页面设置压缩机制及缓存机制,减少流量峰值;
服务层:
服务拆分及部署:系统拆分多个服务减少耦合度,同时达到热点隔离及进程隔离的效果;
集群部署:服务拆分后可根据每个服务的并发量进行横向拓展;同时也达到集群隔离的效果;
代码开发:乐观锁+缓存
中间件层:
缓存中间件:通常读多写少的场景及集中写入的都可以使用缓存中间件减少数据库压力
消息中间件:通过消息中间件可以将并发任务插入队列分批执行
数据层:
数据库集群:通过集群来提高数据库并发能力
读写分离:通过读写分离来分担数据库压力
7.源码
上述代码源码地址:https://github.com/cc6688211/demo_20180925.git