HPL环境安装、配置及初步优化方案(报告)
Linpack测试过程
本机硬件环境为
| Item |
Configuration |
| Server |
CPU: Intel Xeon E5-2680 * 2, 2.70GHz, 32 cores |
| Memory: 4G *8, DDR3, 1333MHz |
|
| Hard disk: 300G ATA * 1 |
| Item |
Description |
Version |
| OS |
GNU/Linux |
RH6.4 |
| Compiler |
Intel Composer XE Suites |
I_ccompxe_2013_sp1.1.106 I_fcompxe_2013_sp1.1.106 |
| MKL |
Intel MKL |
|
| MPI |
MPI OPENMPI |
MPICH-3.04 OPENMPI-1.6.5 |
| HPL |
Linpack Benchmark |
HPL-2.1 |
HPL环境搭建
1.下载 GotoBLAS2.tar.gz
2.解压缩 GotoBLAS2(解压后的文件夹)
3.修改GotoBLAS2 Makefile.rule
去掉注释
VERSION = 1.13
TARGET = NEHALEM
BINARY=64 /*如果你是用的是64位进行该操作*/
USE_OPENMP = 1
INTERFACE64 = 1
运行GotoBLAS2 中的 建立文件
即: ./quickbuild.64bit /*根据机器环境此处是Linux (64bit)*/
MPICH安装
1.下载 mpich.tar.gz
2.将下载的 mpich.tar.gz 解压
tar zxvf mpich.tar.gz
3.建立安装文件夹(此处为setmpich)
mkdir setmpich
4.在解压文件夹mpich中
5./configure --prefix=(要安装的文件夹)
6.make
7.make install
8.导出所需路径(mpich/bin mpich/lib)
vim ~/.bashrc
在最后添加
export PATH=/home/gy/HPL/setmpich/bin:$PATH
export LD_LIBRARY_PATH=/home/gy/HPL/setmpich/lib:$LD_LIBRARY_PATH
/*保存退出(:wq)*/
9.更新配置
source ~/.bashrc
10.检测是否将命令导出成功
which mpirun
如果成功就为会显示你的安装路径.
11.测试
在mpich 解压文件夹中 cd example
运行hellow
[whj@intel-xeon-phi examples]$ mpirun -np 4 ./hello
Hello world from process 3 of 4
Hello world from process 1 of 4
Hello world from process 0 of 4
Hello world from process 2 of 4
/*安装成功*/
下载hpl-2.1.tar.gz
1.解压 (此处存放于hpl)
进入安装文件夹下的 setup,在setup中中找到
Make.Linux_PII_FBLAS
将其放置到上层目录,即为hpl安装目录 ,并且命名为Make.name_str ,name_str是任意后缀
切换到hpl目录
vim Make.name_str 并进行如下配置
ARCH = name_str
TOPdir = $(HOME)/HPL/hpl /*改为hpl解压后产生文件夹*/
MPdir = /home/gy/HPL/setmpich /*改为mpich安装文件夹*/
LAdir = $(HOME)/HPL/GotoBLAS2 /*GotoBLAS2解压文件夹*/
LAinc =
LAlib = $(LAdir)/libatlas2.a
HPL_OPTS = -DHPL_CALL_CBLAS
CC = /home/whj/HPL/setmpich/bin/mpicc
CCFLAGS = $(HPL_DEFS) -fomit-frame-pointer -fopenmp -03 -funroll-loops
LINKER = /home/whj/HPL/setmpich/bin/mpif77
LINKFLAGS = $(CCFLAGS) -nofor main
/*配置完毕后,保存退出*/
2.切换到hpl,安装文件夹下.
make arch=name_str
3.此时查看安装文件夹下bin
会看到有name_str 文件夹
进入 name_str
看到 HPL.dat xhpl
/*到此为止,就全部安装好了,就可以修改HPL.dat,运行xhpl 进行hpl测试了*/
测试平台为单节点,通过修改HPL.dat中的参数,再使用mpirun -np 2 ./xhpl得到测试结果
测试步骤:
优化方案
1 由于测试环境是单节点2CPU的系统,故各个CPU之间的通信就可以通过共享内存进行通信,所以不需要对网络进行选择。
2确定P,Q,测试台比较简单,PQ只有1×2, 2×1两种选择,经测试后发现P×Q=1×2时性能较优。确定P×Q为1×2;
3首先,我们先确定BLAS,并且提取各个BLAS对应的性能较好的NB值。因为测试环境为内存为32GB的服务器,单节点,故初步取N值为58600和58000,NB取值变化的情况下进行测试和比较,确定最佳的BLAS函数库。以下分别为N一定,P×Q=1×2时,Gflops和NB的关系图像。每组的规模的最大取值根据公式 N*N*8=内存容量*80%计算得出。
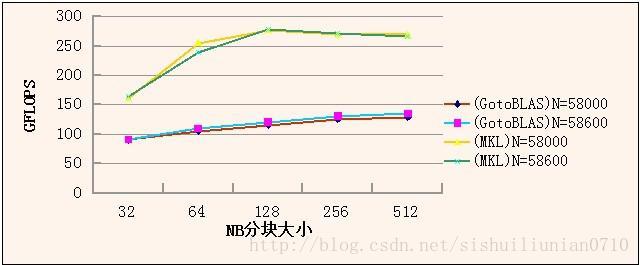
根据图像分析可得,当N=58600,N=128时,测试最大Gflops峰值达到280.7Gflops,同样条件下,使用MKL库比使用GotoBLAS的性能更高。
4 确定MPI库
本测试环境属于单平台的2CPU环境,故刚开始测试时采用OPENMP库,但在实际测试的过程中,由于条件的限制,平台同时供多人使用,使用MPI的峰值反而更高,所以放弃OPENMP,转而使用MPI进行测试。
5确定N NB的值
(1)根据上面测试数据,修正矩阵分块参数NB
前几步已经初步定为N=58600,经过不同的NB,发现当NB=128时,Gflops达到最大值。
表格如下:

(2)根据上面N的取值,选择不同的参数N进行测试,

| Gflops |
NB=64 |
NB=128 |
NB=256 |
NB=512 |
| N=40000 |
221.3 |
245.9 |
240.8 |
234.7 |
| N=57900 |
232.4 |
271 |
269.7 |
265.5 |
| N=58600 |
245.7 |
280.7 |
271 |
276 |
| N=58888 |
239.6 |
273.1 |
270.6 |
258 |
根据表格和图像,我们可以发现N=58888时,系统性能在NB=256时最高,但从整体分析,N=58600时较好。
6其他参数的修订
首先分析并修正非关键参数——分解算法参数组合(PFACTs, RFACTs, NBMINs, NDIVs)
当使用小规模矩阵大小N进行测试时发现,PFACT * RFACT 对于同一矩阵的影响较大,性能最大差距可达到50%,但是随着矩阵规模的增加,差距仍然存在,只是影响较小。当N=58600时,差距仍然存在.
修改HPL.dat文件中的参数,分析得到的文件当WR00C2C4时,Gflops=280.7
此时HPL效率为 280.7/(2*2.7*8)=65.98%
3 # of panel fact
0 1 2 PFACTs (0=left, 1=Crout, 2=Right)
3 #of recursive stopping criterium
2 4 8 NBMINs (>= 1)
3 # of panels in recursion
2 4 8 NDIVs
3 # of recursive panel fact.
0 1 2 RFACTs (0=left, 1=Crout, 2=Right)
=============================================================================
T/V N NB P Q Time Gflops
--------------------------------------------------------------------------------
WR00C2C4 58600 128 1 2 490.90 2.807e+02
HPL_pdgesv() start time Wed Feb 26 05:01:13 2014
HPL_pdgesv() end time Wed Feb 26 05:09:24 2014
--------------------------------------------------------------------------------
||Ax-b||_oo/(eps*(||A||_oo*||x||_oo+||b||_oo)*N)= 0.0019552 ...... PASSED
===============================================================================
此时,PFACT=0,RFACT=0,NBMINs取值为2,NDIV取值为4,Gflops为280.7
问题:
(1)从GotoBLAS换用本机已安装的MKL库,运行mpirun -np X ./xhpl,并无线程开启。
解决:通过查找资料发现,在HPL的Make文件中,LAlib的路径以及参数错误,具体可以在
http://software.intel.com/en-us/articles/intel-mkl-link-line-advisor得到具体的参数。
(2)在调试HPL.dat参数的过程中,为了得到最优的效果,需要大量的测试,但由于条件的限制,总是不能有充足的的时间和资源进行测试。所以先研究HPL的用处和原理,了解每个参数的含义和用处,在测试时更有针对性的调试。
结果分析
矩阵的分块大小对计算的影响非常大 ,数据分块如果过大 ,则容易造成负载不平衡;但是如果数据分块过小,则通信开销就会很大,同样会影响计算的整体性能。综合以上考虑,要选取一个比较均衡的数值。
从测试结果还可以看出,当数组的规模越大,一般来说测试性能就会越好,整体呈上升趋势,但是达到一定阶段后却转而下降。这是因为当数组规模增大时.计算相对于通信的
开销增大,有利于提高机群计算的性能。但是它还有一个重要的制约条件就是内存的大小。当数组增大到超过内存的容量时。测试性能反而会下降,这是因为使用磁盘交换区的性能显 然要远远低于内存的性能.因此适当增加机群系统的内存对于提高机群系统的整体性能是至 关重要的。
对于本测试平台,关闭超线程可能提高提示效率,但由于条件限制,无法进行验证