使用scrapy框架爬取股票数据
@概述
- 本例将手把手带大家实现一个使用scrapy框架爬取股票数据的例子
- 我们将同花顺中融资融券中的几只个股的历史数据爬下来,并保存为csv文件(csv格式是数据分析最友好的格式)
- 本例使用到了pileline和中间件middleware
- scrapy的安装请参见我博客的其它相关文章
@爬取标的
- 我们对融资融券对应的相关个股的前三页历史数据爬下来,如图所示:
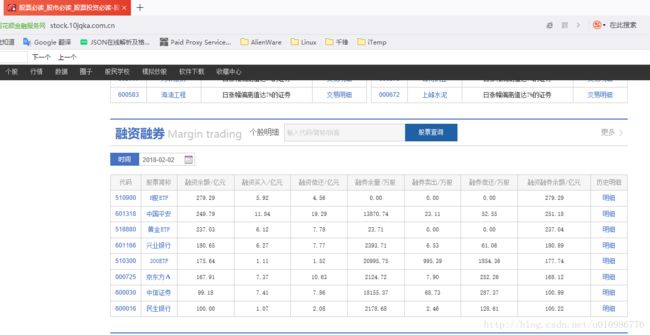
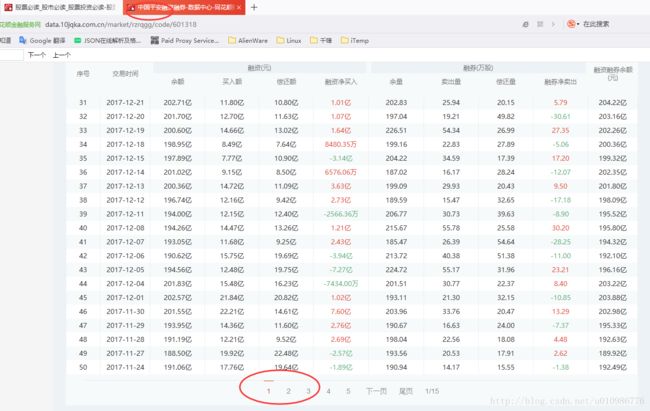
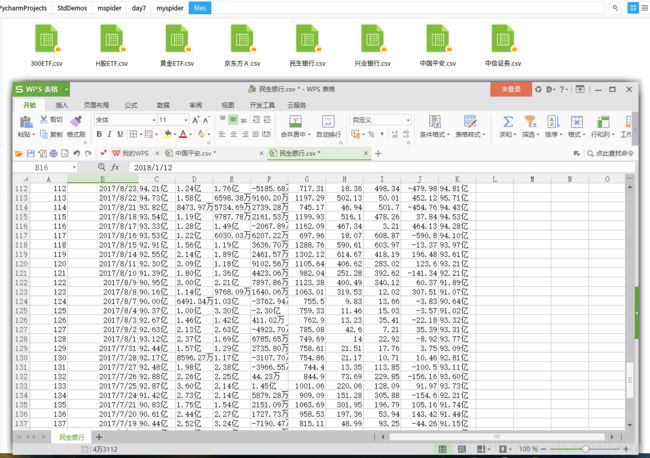
@创建工程
- scrapy startproject mystockspider

@工程结构简介
- mystocks/ 工程根目录
- mystocks/mystocks/ 工程代码存放目录
- scrapy.cfg 部署文件
- mystocks/mystocks/spiders/ 爬虫源文件存放目录
- mystocks/mystocks/items.py 数据模型模块
- mystocks/mystocks/pipelines.py 数据模型处理模块
- mystocks/mystocks/middlewares.py 下载中间件模块
- mystocks/mystocks/settings.py 设置模块
@在items.py中创建数据模型
# 个股数据模型
class StockItem(scrapy.Item):
# 股票名称
name = scrapy.Field()
# 股票详细信息
data = scrapy.Field()@在spiders/目录下创建爬虫源代码my_stock_spider.py
- 源文件名称和类名称都是任意的
- name属性所定义的爬虫名称,将来启动爬虫的命令会使用到
- start_urls是爬虫开始工作的起始页
# 定义爬虫类
class MyStockSpider(scrapy.Spider):
# 定义爬虫名称(命令行启动爬虫要用)
name = 'mystockspider'
# 定义起始 url
start_urls = ['http://stock.10jqka.com.cn/']
@定义起始页响应的处理函数parse
- 这里的parse函数的名称和参数都是固定的写法,不可改变,可以在IDE中直接通过插入覆写方法实现
# 响应处理函数
# response为start_url所返回的响应对象
def parse(self, response):@首页响应函数的具体实现
- 这里要做的事情就是从页面超链接中提取出【个股名称】和【详情页超链接】
- xpath规则请参见:http://blog.csdn.net/u010986776/article/details/79250788
- 向每支个股详情页分别发起请求
- 详情页的响应将由一个自定义的handle_detail方法来处理
# 响应处理函数
# response为start_url所返回的响应对象
def parse(self, response):
# 提取页面个股超链接
a_list = response.xpath("//div[@id='rzrq']/table[@class='m-table']/tbody/tr/td[2]/a")
# 遍历所有超链接
for a in a_list :
# 提取股票名称、下载数据的url
gp_name = a.xpath("./text()").extract()[0]
link = a.xpath("./@href").extract()[0]
gp_id = link.split('/')[-2]
print("gp_id : ", gp_id)
# 以个股名称作为文件名称,建立或清空一下文件
file_name = "./files/" + gp_name + ".csv"
with open(file_name,"w"):
pass
# 针对每只个股发起爬取子链接的请求
# 对子链接的处理交由download_data函数进行处理
# meta = 转交子链接处理函数所处理的数据
yield scrapy.Request(
url=link,
callback=self.handle_detail,
meta={'page': 1, 'url_base': link, 'name': gp_name,'id':gp_id}
)@实现详情页的处理函数handle_detail
- 详情页是一个分页数据,每一页的处理逻辑是相同的
- 即提取表格数据,逐行添加到数据模型中
- 提交数据模型给pipeline做后续处理
- 最后向下一页继续发起请求,请求的回调处理函数依然为当前函数
- 注意:这里由于递归调用了自身,一定要有终止条件,本例的终止条件是爬满三页即止
# 处理个股子链接返回的响应
def handle_detail(self, response):
# 构造数据模型
item = StockItem()
item['name'] = response.meta['name']
item['data'] = ""
# 提取出所有行,然后逐行提取所有单元格中的数据
# 将数据保存到数据模型
tr_list = response.xpath("//table[@class='m-table']/tbody/tr")
for tr in tr_list:
# 提取所有单元格中的数据,以英文逗号连接
text_list = tr.xpath("./td/text()").extract()
onerow = ','.join( [text.strip() for text in text_list] )
# 存储数据到item
item['data'] += onerow+"\n"
# 提交数据模型给pipeline处理
yield item
# 爬取个股分页数据,最多爬取3页
response.meta['page'] += 1
if response.meta['page'] > 3 :
# 不再提交新的请求,爬虫结束
return
# 组装个股分页数据url
url_str = 'http://data.10jqka.com.cn/market/rzrqgg/code/'+response.meta['id']+'/order/desc/page/' + str(response.meta['page']) + '/ajax/1/'
print("url_str = ", url_str)
# 稍事休息后,爬取下一页数据,仍交由当前函数处理
time.sleep(1)
yield scrapy.Request(
url=url_str,
callback=self.handle_detail,
meta={'page': response.meta['page'], 'url_base': url_str, 'name': response.meta['name'],'id':response.meta['id']}
)@在pipelines.py中定义数据模型处理类
- 这里的主要处理逻辑在process_item覆写方法中,
- 这里的处理逻辑很简单,就是把数据模型中的数据写入对应的文件
- 结尾处return了数据模型item,return给谁呢,答案是下一个pipeliine,如果有的话
# 处理spider返回的item对象
class StockSavingPipeline(object):
# 初始化方法
def __init__(self):
print("\n"*5,"StockSavingPipeline __init__")
# 处理spider返回的item对象
# item = 爬虫提交过来的数据模型
# spider = 提交item的爬虫实例
def process_item(self, item, spider):
print("\n" * 5, "StockSavingPipeline process_item")
# 提取数据
data = item['data']
file_name = "./files/"+item['name']+".csv"
# 向文件中写入数据
with open(file_name,"a") as file:
file.write(data)
# 如果有多个pipeline,继续向下一个pipeline传递
# 不返回则传递终止
# 这里主要体现一个分工、分批处理的思想
return item
# 对象被销毁时调用
def __del__(self):
print("\n" * 5, "StockSavingPipeline __del__")@告诉框架爬虫提交的数据对象由谁处理,这里有两种设置方式
- 方式1:设置在settings.py中
- 这里设置了多个pipeline处理类,所有爬虫类提交的所有item都会经过所有这些pipeline类
- 这些pipeline的处理顺序是从小到大的,即100的会先处理,200的后处理,其取值范围是0-1000
ITEM_PIPELINES = {
'myspider.pipelines.WbtcPipeline': 200,
'myspider.pipelines.WbtcPipeline_2': 100,
'myspider.pipelines.StockSavingPipeline': 100,
}- 方式2:设置在爬虫类中,本例即MyStockSpider类中
- 直接设置在爬虫类中,其优先级要高于设置在settings.py中
- 这个规则对于后面对于下载中间件的配置也同样适用
# 声明使用哪些pipelines和下载中间件
# 这里设置的优先级要高于settings.py文件
custom_settings = {
'ITEM_PIPELINES':{'myspider.pipelines.StockSavingPipeline':100},
}@配置下载中间件
- 下载中间件的作用是对请求和响应进行预处理
- 比如对所有请求添加随机的User-Agent
- 比如对所有请求随机配置代理IP
其配置同样有两种方式:配置在settings.py中或配置在爬虫类中,后者的优先级要高于前者
settings.py中的配置如下:
# 配置下载中间件
DOWNLOADER_MIDDLEWARES = {
# 'myspider.middlewares.MyCustomDownloaderMiddleware': 543,
'myspider.middlewares.ProxyMiddleware': 543,
}- 爬虫类中的配置如下:
# 声明使用哪些pipelines和下载中间件
# 这里设置的优先级要高于settings.py文件
custom_settings = {
'ITEM_PIPELINES':{'myspider.pipelines.StockSavingPipeline':100},
'DOWNLOADER_MIDDLEWARES':{'myspider.middlewares.ProxyMiddleware': 543},
}@实现下载中间件
- 这里实现对所有请求添加随机请求头和IP代理
- 由于中间件同样也是可以配置多个,串联成链式结构的,所以return的标的下一个中间件
class ProxyMiddleware(object):
# 对请求进行预处理
def process_request(self, request, spider):
print("\n" * 5, "ProxyMiddleware process_request")
# 随机选择USER_AGENTS
# 设置 request 对象的头部信息
user_agent = random.choice(USER_AGENTS)
# request.headers.setdefault("User-Agent", user_agent)
request.headers["User-Agent"] = user_agent
# 随机选择 代理ip
# 设置 request 代理 ip
ip = 'http://' + random.choice(PROXY_IP)
# print('user_agent ========== ' + user_agent)
print('Proxy ip ===== ' + ip)
request.meta['proxy'] = ip
# 这里如果return这个request会陷入死循环
# return request
# 对响应进行预处理
def process_response(self, request, response, spider):
print("\n" * 5, "ProxyMiddleware process_response")
print(request.headers)
print(request.meta)
# print(request.url)
# print(response.status)
# print(response.text)
return response@命令行中跑起来,爬虫就会源源不断地开始爬了
- 这里要提前cd到爬虫工程的根目录
- 如果在linux环境下,可以在前面加sudo,可以避免一些没必要的稀奇古怪的错误
scrapy crawl mystockspider