基于tensorflow2复用InceptionV3作为编码器利用GRU的RNN+Attention作为解码器在MS-COCO数据集上进行图片描述(Image Caption)
Copyright 2018 The TensorFlow Authors.
#@title Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# https://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
Image captioning with visual attention
| View on TensorFlow.org | Run in Google Colab | View source on GitHub | Download notebook |
Given an image like the example below, our goal is to generate a caption such as “a surfer riding on a wave”.
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-zvSAts4W-1590303462026)(https://tensorflow.org/images/surf.jpg)]
Image Source; License: Public Domain
To accomplish this, you’ll use an attention-based model, which enables us to see what parts of the image the model focuses on as it generates a caption.
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-0Gx9Si46-1590303462029)(https://tensorflow.org/images/imcap_prediction.png)]
The model architecture is similar to Show, Attend and Tell: Neural Image Caption Generation with Visual Attention.
This notebook is an end-to-end example. When you run the notebook, it downloads the MS-COCO dataset, preprocesses and caches a subset of images using Inception V3, trains an encoder-decoder model, and generates captions on new images using the trained model.
In this example, you will train a model on a relatively small amount of data—the first 30,000 captions for about 20,000 images (because there are multiple captions per image in the dataset).
import tensorflow as tf
# You'll generate plots of attention in order to see which parts of an image
# our model focuses on during captioning
import matplotlib.pyplot as plt
# Scikit-learn includes many helpful utilities
from sklearn.model_selection import train_test_split
from sklearn.utils import shuffle
import re
import numpy as np
import os
import time
import json
from glob import glob
from PIL import Image
import pickle
Download and prepare the MS-COCO dataset
You will use the MS-COCO dataset to train our model. The dataset contains over 82,000 images, each of which has at least 5 different caption annotations. The code below downloads and extracts the dataset automatically.
Caution: large download ahead. You’ll use the training set, which is a 13GB file.
# Download caption annotation files
annotation_folder = '/annotations/'
if not os.path.exists(os.path.abspath('.') + annotation_folder):
annotation_zip = tf.keras.utils.get_file('captions.zip',
cache_subdir=os.path.abspath('.'),
origin = 'http://images.cocodataset.org/annotations/annotations_trainval2014.zip',
extract = True)
annotation_file = os.path.dirname(annotation_zip)+'/annotations/captions_train2014.json'
os.remove(annotation_zip)
# Download image files
image_folder = '/train2014/'
if not os.path.exists(os.path.abspath('.') + image_folder):
image_zip = tf.keras.utils.get_file('train2014.zip',
cache_subdir=os.path.abspath('.'),
origin = 'http://images.cocodataset.org/zips/train2014.zip',
extract = True)
PATH = os.path.dirname(image_zip) + image_folder
os.remove(image_zip)
else:
PATH = os.path.abspath('.') + image_folder
Downloading data from http://images.cocodataset.org/annotations/annotations_trainval2014.zip
252878848/252872794 [==============================] - 36s 0us/step
Downloading data from http://images.cocodataset.org/zips/train2014.zip
13510574080/13510573713 [==============================] - 1976s 0us/step
Optional: limit the size of the training set
To speed up training for this tutorial, you’ll use a subset of 30,000 captions and their corresponding images to train our model. Choosing to use more data would result in improved captioning quality.
# Read the json file
with open(annotation_file, 'r') as f:
annotations = json.load(f)
# Store captions and image names in vectors
all_captions = []
all_img_name_vector = []
for annot in annotations['annotations']:
caption = ' ' + annot['caption'] + ' '
image_id = annot['image_id']
full_coco_image_path = PATH + 'COCO_train2014_' + '%012d.jpg' % (image_id)
all_img_name_vector.append(full_coco_image_path)
all_captions.append(caption)
# Shuffle captions and image_names together
# Set a random state
train_captions, img_name_vector = shuffle(all_captions,
all_img_name_vector,
random_state=1)
# Select the first 30000 captions from the shuffled set
num_examples = 30000
train_captions = train_captions[:num_examples]
img_name_vector = img_name_vector[:num_examples]
len(train_captions), len(all_captions)
(30000, 414113)
Preprocess the images using InceptionV3
Next, you will use InceptionV3 (which is pretrained on Imagenet) to classify each image. You will extract features from the last convolutional layer.
First, you will convert the images into InceptionV3’s expected format by:
- Resizing the image to 299px by 299px
- Preprocess the images using the preprocess_input method to normalize the image so that it contains pixels in the range of -1 to 1, which matches the format of the images used to train InceptionV3.
def load_image(image_path):
img = tf.io.read_file(image_path)
img = tf.image.decode_jpeg(img, channels=3)
img = tf.image.resize(img, (299, 299))
img = tf.keras.applications.inception_v3.preprocess_input(img)
return img, image_path
Initialize InceptionV3 and load the pretrained Imagenet weights
Now you’ll create a tf.keras model where the output layer is the last convolutional layer in the InceptionV3 architecture. The shape of the output of this layer is 8x8x2048. You use the last convolutional layer because you are using attention in this example. You don’t perform this initialization during training because it could become a bottleneck.
- You forward each image through the network and store the resulting vector in a dictionary (image_name --> feature_vector).
- After all the images are passed through the network, you pickle the dictionary and save it to disk.
image_model = tf.keras.applications.InceptionV3(include_top=False,
weights='imagenet')
new_input = image_model.input
hidden_layer = image_model.layers[-1].output
image_features_extract_model = tf.keras.Model(new_input, hidden_layer)
Downloading data from https://storage.googleapis.com/tensorflow/keras-applications/inception_v3/inception_v3_weights_tf_dim_ordering_tf_kernels_notop.h5
87916544/87910968 [==============================] - 12s 0us/step
Caching the features extracted from InceptionV3
You will pre-process each image with InceptionV3 and cache the output to disk. Caching the output in RAM would be faster but also memory intensive, requiring 8 * 8 * 2048 floats per image. At the time of writing, this exceeds the memory limitations of Colab (currently 12GB of memory).
Performance could be improved with a more sophisticated caching strategy (for example, by sharding the images to reduce random access disk I/O), but that would require more code.
The caching will take about 10 minutes to run in Colab with a GPU. If you’d like to see a progress bar, you can:
-
install tqdm:
!pip install -q tqdm -
Import tqdm:
from tqdm import tqdm -
Change the following line:
for img, path in image_dataset:to:
for img, path in tqdm(image_dataset):
# Get unique images
encode_train = sorted(set(img_name_vector))
# Feel free to change batch_size according to your system configuration
image_dataset = tf.data.Dataset.from_tensor_slices(encode_train)
image_dataset = image_dataset.map(
load_image, num_parallel_calls=tf.data.experimental.AUTOTUNE).batch(16)
for img, path in image_dataset:
batch_features = image_features_extract_model(img)
batch_features = tf.reshape(batch_features,
(batch_features.shape[0], -1, batch_features.shape[3]))
for bf, p in zip(batch_features, path):
path_of_feature = p.numpy().decode("utf-8")
np.save(path_of_feature, bf.numpy())
Preprocess and tokenize the captions
- First, you’ll tokenize the captions (for example, by splitting on spaces). This gives us a vocabulary of all of the unique words in the data (for example, “surfing”, “football”, and so on).
- Next, you’ll limit the vocabulary size to the top 5,000 words (to save memory). You’ll replace all other words with the token “UNK” (unknown).
- You then create word-to-index and index-to-word mappings.
- Finally, you pad all sequences to be the same length as the longest one.
# Find the maximum length of any caption in our dataset
def calc_max_length(tensor):
return max(len(t) for t in tensor)
# Choose the top 5000 words from the vocabulary
top_k = 5000
tokenizer = tf.keras.preprocessing.text.Tokenizer(num_words=top_k,
oov_token="" ,
filters='!"#$%&()*+.,-/:;=?@[\]^_`{|}~ ')
tokenizer.fit_on_texts(train_captions)
train_seqs = tokenizer.texts_to_sequences(train_captions)
tokenizer.word_index['' ] = 0
tokenizer.index_word[0] = ''
# Create the tokenized vectors
train_seqs = tokenizer.texts_to_sequences(train_captions)
# Pad each vector to the max_length of the captions
# If you do not provide a max_length value, pad_sequences calculates it automatically
cap_vector = tf.keras.preprocessing.sequence.pad_sequences(train_seqs, padding='post')
# Calculates the max_length, which is used to store the attention weights
max_length = calc_max_length(train_seqs)
Split the data into training and testing
# Create training and validation sets using an 80-20 split
img_name_train, img_name_val, cap_train, cap_val = train_test_split(img_name_vector,
cap_vector,
test_size=0.2,
random_state=0)
len(img_name_train), len(cap_train), len(img_name_val), len(cap_val)
(24000, 24000, 6000, 6000)
Create a tf.data dataset for training
Our images and captions are ready! Next, let’s create a tf.data dataset to use for training our model.
# Feel free to change these parameters according to your system's configuration
BATCH_SIZE = 64
BUFFER_SIZE = 1000
embedding_dim = 256
units = 512
vocab_size = top_k + 1
num_steps = len(img_name_train) // BATCH_SIZE
# Shape of the vector extracted from InceptionV3 is (64, 2048)
# These two variables represent that vector shape
features_shape = 2048
attention_features_shape = 64
# Load the numpy files
def map_func(img_name, cap):
img_tensor = np.load(img_name.decode('utf-8')+'.npy')
return img_tensor, cap
dataset = tf.data.Dataset.from_tensor_slices((img_name_train, cap_train))
# Use map to load the numpy files in parallel
dataset = dataset.map(lambda item1, item2: tf.numpy_function(
map_func, [item1, item2], [tf.float32, tf.int32]),
num_parallel_calls=tf.data.experimental.AUTOTUNE)
# Shuffle and batch
dataset = dataset.shuffle(BUFFER_SIZE).batch(BATCH_SIZE)
dataset = dataset.prefetch(buffer_size=tf.data.experimental.AUTOTUNE)
Model
Fun fact: the decoder below is identical to the one in the example for Neural Machine Translation with Attention.
The model architecture is inspired by the Show, Attend and Tell paper.
- In this example, you extract the features from the lower convolutional layer of InceptionV3 giving us a vector of shape (8, 8, 2048).
- You squash that to a shape of (64, 2048).
- This vector is then passed through the CNN Encoder (which consists of a single Fully connected layer).
- The RNN (here GRU) attends over the image to predict the next word.
class BahdanauAttention(tf.keras.Model):
def __init__(self, units):
super(BahdanauAttention, self).__init__()
self.W1 = tf.keras.layers.Dense(units)
self.W2 = tf.keras.layers.Dense(units)
self.V = tf.keras.layers.Dense(1)
def call(self, features, hidden):
# features(CNN_encoder output) shape == (batch_size, 64, embedding_dim)
# hidden shape == (batch_size, hidden_size)
# hidden_with_time_axis shape == (batch_size, 1, hidden_size)
hidden_with_time_axis = tf.expand_dims(hidden, 1)
# score shape == (batch_size, 64, hidden_size)
score = tf.nn.tanh(self.W1(features) + self.W2(hidden_with_time_axis))
# attention_weights shape == (batch_size, 64, 1)
# you get 1 at the last axis because you are applying score to self.V
attention_weights = tf.nn.softmax(self.V(score), axis=1)
# context_vector shape after sum == (batch_size, hidden_size)
context_vector = attention_weights * features
context_vector = tf.reduce_sum(context_vector, axis=1)
return context_vector, attention_weights
class CNN_Encoder(tf.keras.Model):
# Since you have already extracted the features and dumped it using pickle
# This encoder passes those features through a Fully connected layer
def __init__(self, embedding_dim):
super(CNN_Encoder, self).__init__()
# shape after fc == (batch_size, 64, embedding_dim)
self.fc = tf.keras.layers.Dense(embedding_dim)
def call(self, x):
x = self.fc(x)
x = tf.nn.relu(x)
return x
class RNN_Decoder(tf.keras.Model):
def __init__(self, embedding_dim, units, vocab_size):
super(RNN_Decoder, self).__init__()
self.units = units
self.embedding = tf.keras.layers.Embedding(vocab_size, embedding_dim)
self.gru = tf.keras.layers.GRU(self.units,
return_sequences=True,
return_state=True,
recurrent_initializer='glorot_uniform')
self.fc1 = tf.keras.layers.Dense(self.units)
self.fc2 = tf.keras.layers.Dense(vocab_size)
self.attention = BahdanauAttention(self.units)
def call(self, x, features, hidden):
# defining attention as a separate model
context_vector, attention_weights = self.attention(features, hidden)
# x shape after passing through embedding == (batch_size, 1, embedding_dim)
x = self.embedding(x)
# x shape after concatenation == (batch_size, 1, embedding_dim + hidden_size)
x = tf.concat([tf.expand_dims(context_vector, 1), x], axis=-1)
# passing the concatenated vector to the GRU
output, state = self.gru(x)
# shape == (batch_size, max_length, hidden_size)
x = self.fc1(output)
# x shape == (batch_size * max_length, hidden_size)
x = tf.reshape(x, (-1, x.shape[2]))
# output shape == (batch_size * max_length, vocab)
x = self.fc2(x)
return x, state, attention_weights
def reset_state(self, batch_size):
return tf.zeros((batch_size, self.units))
encoder = CNN_Encoder(embedding_dim)
decoder = RNN_Decoder(embedding_dim, units, vocab_size)
optimizer = tf.keras.optimizers.Adam()
loss_object = tf.keras.losses.SparseCategoricalCrossentropy(
from_logits=True, reduction='none')
def loss_function(real, pred):
mask = tf.math.logical_not(tf.math.equal(real, 0))
loss_ = loss_object(real, pred)
mask = tf.cast(mask, dtype=loss_.dtype)
loss_ *= mask
return tf.reduce_mean(loss_)
Checkpoint
checkpoint_path = "./checkpoints/train"
ckpt = tf.train.Checkpoint(encoder=encoder,
decoder=decoder,
optimizer = optimizer)
ckpt_manager = tf.train.CheckpointManager(ckpt, checkpoint_path, max_to_keep=5)
start_epoch = 0
if ckpt_manager.latest_checkpoint:
start_epoch = int(ckpt_manager.latest_checkpoint.split('-')[-1])
# restoring the latest checkpoint in checkpoint_path
ckpt.restore(ckpt_manager.latest_checkpoint)
Training
- You extract the features stored in the respective
.npyfiles and then pass those features through the encoder. - The encoder output, hidden state(initialized to 0) and the decoder input (which is the start token) is passed to the decoder.
- The decoder returns the predictions and the decoder hidden state.
- The decoder hidden state is then passed back into the model and the predictions are used to calculate the loss.
- Use teacher forcing to decide the next input to the decoder.
- Teacher forcing is the technique where the target word is passed as the next input to the decoder.
- The final step is to calculate the gradients and apply it to the optimizer and backpropagate.
# adding this in a separate cell because if you run the training cell
# many times, the loss_plot array will be reset
loss_plot = []
@tf.function
def train_step(img_tensor, target):
loss = 0
# initializing the hidden state for each batch
# because the captions are not related from image to image
hidden = decoder.reset_state(batch_size=target.shape[0])
dec_input = tf.expand_dims([tokenizer.word_index['' ]] * target.shape[0], 1)
with tf.GradientTape() as tape:
features = encoder(img_tensor)
for i in range(1, target.shape[1]):
# passing the features through the decoder
predictions, hidden, _ = decoder(dec_input, features, hidden)
loss += loss_function(target[:, i], predictions)
# using teacher forcing
dec_input = tf.expand_dims(target[:, i], 1)
total_loss = (loss / int(target.shape[1]))
trainable_variables = encoder.trainable_variables + decoder.trainable_variables
gradients = tape.gradient(loss, trainable_variables)
optimizer.apply_gradients(zip(gradients, trainable_variables))
return loss, total_loss
EPOCHS = 20
for epoch in range(start_epoch, EPOCHS):
start = time.time()
total_loss = 0
for (batch, (img_tensor, target)) in enumerate(dataset):
batch_loss, t_loss = train_step(img_tensor, target)
total_loss += t_loss
if batch % 100 == 0:
print ('Epoch {} Batch {} Loss {:.4f}'.format(
epoch + 1, batch, batch_loss.numpy() / int(target.shape[1])))
# storing the epoch end loss value to plot later
loss_plot.append(total_loss / num_steps)
if epoch % 5 == 0:
ckpt_manager.save()
print ('Epoch {} Loss {:.6f}'.format(epoch + 1,
total_loss/num_steps))
print ('Time taken for 1 epoch {} sec\n'.format(time.time() - start))
Epoch 1 Batch 0 Loss 1.9826
Epoch 1 Batch 100 Loss 1.0766
Epoch 1 Batch 200 Loss 0.9828
Epoch 1 Batch 300 Loss 0.8334
Epoch 1 Loss 1.020535
Time taken for 1 epoch 867.4559998512268 sec
Epoch 2 Batch 0 Loss 0.7846
Epoch 2 Batch 100 Loss 0.8916
Epoch 2 Batch 200 Loss 0.8349
Epoch 2 Batch 300 Loss 0.7427
Epoch 2 Loss 0.788438
Time taken for 1 epoch 843.4099998474121 sec
Epoch 3 Batch 0 Loss 0.6797
Epoch 3 Batch 100 Loss 0.7635
Epoch 3 Batch 200 Loss 0.6965
Epoch 3 Batch 300 Loss 0.7608
Epoch 3 Loss 0.720219
Time taken for 1 epoch 848.2360002994537 sec
Epoch 4 Batch 0 Loss 0.6467
Epoch 4 Batch 100 Loss 0.7126
Epoch 4 Batch 200 Loss 0.7006
Epoch 4 Batch 300 Loss 0.6498
Epoch 4 Loss 0.676800
Time taken for 1 epoch 22754.36899995804 sec
Epoch 5 Batch 0 Loss 0.6208
Epoch 5 Batch 100 Loss 0.6752
Epoch 5 Batch 200 Loss 0.6238
Epoch 5 Batch 300 Loss 0.6855
Epoch 5 Loss 0.640652
Time taken for 1 epoch 858.4920001029968 sec
Epoch 6 Batch 0 Loss 0.5635
Epoch 6 Batch 100 Loss 0.6076
Epoch 6 Batch 200 Loss 0.6626
Epoch 6 Batch 300 Loss 0.5826
Epoch 6 Loss 0.610045
Time taken for 1 epoch 842.7669997215271 sec
Epoch 7 Batch 0 Loss 0.5946
Epoch 7 Batch 100 Loss 0.6060
Epoch 7 Batch 200 Loss 0.6191
Epoch 7 Batch 300 Loss 0.5734
Epoch 7 Loss 0.580250
Time taken for 1 epoch 843.3290002346039 sec
Epoch 8 Batch 0 Loss 0.5511
Epoch 8 Batch 100 Loss 0.5445
Epoch 8 Batch 200 Loss 0.5524
Epoch 8 Batch 300 Loss 0.5542
Epoch 8 Loss 0.552673
Time taken for 1 epoch 845.6169998645782 sec
Epoch 9 Batch 0 Loss 0.6551
Epoch 9 Batch 100 Loss 0.5655
Epoch 9 Batch 200 Loss 0.5432
Epoch 9 Batch 300 Loss 0.5003
Epoch 9 Loss 0.523320
Time taken for 1 epoch 849.5820000171661 sec
Epoch 10 Batch 0 Loss 0.5314
Epoch 10 Batch 100 Loss 0.5120
Epoch 10 Batch 200 Loss 0.5442
Epoch 10 Batch 300 Loss 0.4810
Epoch 10 Loss 0.497177
Time taken for 1 epoch 851.8239998817444 sec
Epoch 11 Batch 0 Loss 0.4835
Epoch 11 Batch 100 Loss 0.4318
Epoch 11 Batch 200 Loss 0.4375
Epoch 11 Batch 300 Loss 0.5080
Epoch 11 Loss 0.472056
Time taken for 1 epoch 853.6370003223419 sec
Epoch 12 Batch 0 Loss 0.4322
Epoch 12 Batch 100 Loss 0.4029
Epoch 12 Batch 200 Loss 0.4707
Epoch 12 Batch 300 Loss 0.4289
Epoch 12 Loss 0.443257
Time taken for 1 epoch 856.2819998264313 sec
Epoch 13 Batch 0 Loss 0.4076
Epoch 13 Batch 100 Loss 0.4457
Epoch 13 Batch 200 Loss 0.4189
Epoch 13 Batch 300 Loss 0.3959
Epoch 13 Loss 0.417531
Time taken for 1 epoch 856.5480000972748 sec
Epoch 14 Batch 0 Loss 0.4144
Epoch 14 Batch 100 Loss 0.3627
Epoch 14 Batch 200 Loss 0.3675
Epoch 14 Batch 300 Loss 0.3782
Epoch 14 Loss 0.393826
Time taken for 1 epoch 859.1970000267029 sec
Epoch 15 Batch 0 Loss 0.4028
Epoch 15 Batch 100 Loss 0.3860
Epoch 15 Batch 200 Loss 0.3518
Epoch 15 Batch 300 Loss 0.3650
Epoch 15 Loss 0.368864
Time taken for 1 epoch 858.981999874115 sec
Epoch 16 Batch 0 Loss 0.4157
Epoch 16 Batch 100 Loss 0.3487
Epoch 16 Batch 200 Loss 0.3358
Epoch 16 Batch 300 Loss 0.3508
Epoch 16 Loss 0.347152
Time taken for 1 epoch 861.2170000076294 sec
Epoch 17 Batch 0 Loss 0.3484
Epoch 17 Batch 100 Loss 0.3189
Epoch 17 Batch 200 Loss 0.3410
Epoch 17 Batch 300 Loss 0.3325
Epoch 17 Loss 0.326838
Time taken for 1 epoch 863.018000125885 sec
Epoch 18 Batch 0 Loss 0.3417
Epoch 18 Batch 100 Loss 0.3062
Epoch 18 Batch 200 Loss 0.2976
Epoch 18 Batch 300 Loss 0.3102
Epoch 18 Loss 0.307557
Time taken for 1 epoch 857.856999874115 sec
Epoch 19 Batch 0 Loss 0.3166
Epoch 19 Batch 100 Loss 0.2877
Epoch 19 Batch 200 Loss 0.3147
Epoch 19 Batch 300 Loss 0.2578
Epoch 19 Loss 0.288329
Time taken for 1 epoch 865.0030000209808 sec
Epoch 20 Batch 0 Loss 0.2787
Epoch 20 Batch 100 Loss 0.3141
Epoch 20 Batch 200 Loss 0.2866
Epoch 20 Batch 300 Loss 0.2517
Epoch 20 Loss 0.270503
Time taken for 1 epoch 861.1440000534058 sec
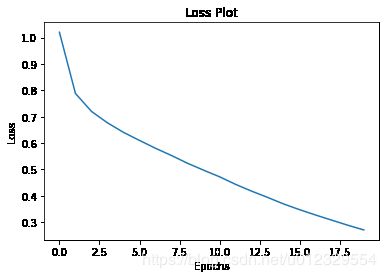
plt.plot(loss_plot)
plt.xlabel('Epochs')
plt.ylabel('Loss')
plt.title('Loss Plot')
plt.show()
Caption!
- The evaluate function is similar to the training loop, except you don’t use teacher forcing here. The input to the decoder at each time step is its previous predictions along with the hidden state and the encoder output.
- Stop predicting when the model predicts the end token.
- And store the attention weights for every time step.
def evaluate(image):
attention_plot = np.zeros((max_length, attention_features_shape))
hidden = decoder.reset_state(batch_size=1)
temp_input = tf.expand_dims(load_image(image)[0], 0)
img_tensor_val = image_features_extract_model(temp_input)
img_tensor_val = tf.reshape(img_tensor_val, (img_tensor_val.shape[0], -1, img_tensor_val.shape[3]))
features = encoder(img_tensor_val)
dec_input = tf.expand_dims([tokenizer.word_index['' ]], 0)
result = []
for i in range(max_length):
predictions, hidden, attention_weights = decoder(dec_input, features, hidden)
attention_plot[i] = tf.reshape(attention_weights, (-1, )).numpy()
predicted_id = tf.random.categorical(predictions, 1)[0][0].numpy()
result.append(tokenizer.index_word[predicted_id])
if tokenizer.index_word[predicted_id] == '' :
return result, attention_plot
dec_input = tf.expand_dims([predicted_id], 0)
attention_plot = attention_plot[:len(result), :]
return result, attention_plot
def plot_attention(image, result, attention_plot):
temp_image = np.array(Image.open(image))
fig = plt.figure(figsize=(10, 10))
len_result = len(result)
for l in range(len_result):
temp_att = np.resize(attention_plot[l], (8, 8))
ax = fig.add_subplot(len_result//2, len_result//2, l+1)
ax.set_title(result[l])
img = ax.imshow(temp_image)
ax.imshow(temp_att, cmap='gray', alpha=0.6, extent=img.get_extent())
plt.tight_layout()
plt.show()
# captions on the validation set
rid = np.random.randint(0, len(img_name_val))
image = img_name_val[rid]
real_caption = ' '.join([tokenizer.index_word[i] for i in cap_val[rid] if i not in [0]])
result, attention_plot = evaluate(image)
print ('Real Caption:', real_caption)
print ('Prediction Caption:', ' '.join(result))
plot_attention(image, result, attention_plot)
Real Caption: a young man has sprawled out on a bed with a large wooden headboard
Prediction Caption: a bed laying on a bed beside a box on top of it

Try it on your own images
For fun, below we’ve provided a method you can use to caption your own images with the model we’ve just trained. Keep in mind, it was trained on a relatively small amount of data, and your images may be different from the training data (so be prepared for weird results!)
image_url = 'https://tensorflow.org/images/surf.jpg'
image_extension = image_url[-4:]
image_path = tf.keras.utils.get_file('image'+image_extension,
origin=image_url)
result, attention_plot = evaluate(image_path)
print ('Prediction Caption:', ' '.join(result))
plot_attention(image_path, result, attention_plot)
# opening the image
Image.open(image_path)
Prediction Caption: a person in glasses stands behind a laptop screen


Next steps
Congrats! You’ve just trained an image captioning model with attention. Next, take a look at this example Neural Machine Translation with Attention. It uses a similar architecture to translate between Spanish and English sentences. You can also experiment with training the code in this notebook on a different dataset.