CSAPP: Architecture Lab
介绍
本实验是将CSAPP家庭作业后面的几个问题组合成实验作业。在实验中,我们需要修改处理器的HCL描述来增加新的指令、修改循环策略等,修改后的处理器能够被模拟,并通过运行自动化测试检测。
在本实验中,我们需要掌握Y86相关汇编语言的操作、以及对于Y86 HCL描述,并且对于流水线、程序的优化有一定的了解。
实验准备
下载实验包:archlab-handout.tar
(1)相关实验包可以到以下地址下载,里面还包含详细的答案,原始tar在CSAPP Lab original tar 文件夹下https://github.com/Davon-Feng/CSAPP-Labs。本文解答的内容在yzf-archlab_handout文件夹中
https://github.com/Davon-Feng/CSAPP-Labs/tree/master/yzf-archlab-handout(2)载入tar文件后,需要运用
tar xvf archlab-handout.tar将文件解压。里面包含README, Makefile, sim.tar, archlab.ps, archlab.pdf, and simguide.pdf.(3)然后运用tar命令解压sim.tar文件,进入sim文件夹执行以下命令
unix > cd sim unix > make clean ; make
在make过程中遇到以下问题:(1).usr/bin/ld: cannot find -lfl (2).make: bison:命令未找到 (3) .make: flex:命令未找到
对于第(1)个问题,运用sudo apt-get install libfl.so解决
对于第(2、3)个问题,运用sudo apt-get install bison flex解决
2.学习和掌握《深入理解计算机系统》第二版中第4章、第五章
Part A
该实验中的任务为在sim/misc文件夹中,运用Y86指令撰写并且模拟example.c文件中的三个函数的功能。并且运用YAS进行编译,运用YIS进行运行。Y86汇编程序的编写规则见CSAPP书本的P237页,Y86程序
本博主实现代码文件,见之前链接下载文件中sim/misc文件夹下的如下所示文件
相关编译运行代码如下
unix > ./yas A-sum.ys
unix > ./yis A-sum.yo
- 对下面的链接Sample linked list数据进行操作,实现sum_list()函数的功能
# Sample linked list 实验数据
.align 4
ele1:
.long 0x00a
.long ele2
.long 0x0b0
.long ele3
ele3:
.long 0
ele2:
.long 0xc00
/* linked list element */ 链表的定义
typedef struct ELE {
int val;
struct ELE *next;
} *list_ptr;
对于该实验要求作出的解答如下:
# 函数执行开始地址为0
.pos 0
init: irmovl Stack, %esp
irmovl Stack, %ebp
call Main
halt
# Sample linked list 函数操作中需要运用到的数据定义
.align 4
ele1:
.long 0x00a
.long ele2
ele2:
.long 0x0b0
.long ele3
ele3:
.long 0xc00
.long 0
#定义Main函数,调用sum_list函数
Main: pushl %ebp
rrmovl %esp, %ebp
irmovl ele1 , %eax
pushl %eax
call sumlist
rrmovl %ebp , %esp
popl %ebp
ret
# int sum_list(list_ptr ls) 相关sum_list 函数的实现
sumlist:
pushl %ebp
rrmovl %esp ,%ebp
xorl %eax,%eax #the return val = 0
mrmovl 8(%ebp) , %edx
andl %edx , %edx #ls == 0 ?
je End
Loop: mrmovl (%edx) , %ecx #ls->val ==> %ecx
addl %ecx , %eax #val += ls->val
irmovl $4 , %edi
addl %edi , %edx #next ==> edx
mrmovl (%edx), %esi
rrmovl %esi , %edx #ls->next ==>edx
andl %edx , %edx #set condition codes
jne Loop #if ls != 0 goto Loop
End: rrmovl %ebp , %esp
popl %ebp
ret
#定义栈的起始地址
.pos 0x100
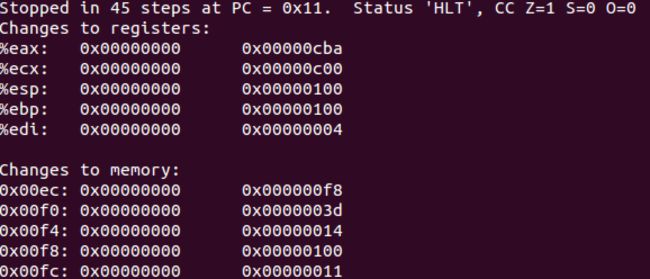
Stack:运行结果如下,正确答案在%eax寄存器中
2.模拟example函数里面的rsum_list函数,是sum_list函数的递归版本,初始,数据,Mian函数和栈代码与sum_list的均相同。下面仅显示rsum_list的实现。相关运行命令行,和运行结果与sum_list相同
rsum_list:
pushl %ebp
rrmovl %esp , %ebp
pushl %ebx
irmovl $4 , %esi
subl %esi , %esp
xorl %eax , %eax
mrmovl 8(%ebp),%edx
andl %edx , %edx
je End
mrmovl (%edx) , %ebx
irmovl $4 , %esi
addl %esi , %edx
mrmovl (%edx) , %edi
rmmovl %edi , (%esp)
call rsum_list
addl %ebx , %eax
End:
addl %esi , %esp
popl %ebx
popl %ebp
ret3.copy_block函数,拷贝源地址数据到目标地址,并且计算所有数据Xor值,相关实现代码如下所示。
.pos 0
init: irmovl Stack, %esp
irmovl Stack, %ebp
call Main
halt
.align 4
# Source block
src:
.long 0x00a
.long 0x0b0
.long 0xc00
# Destination block
dest:
.long 0x111
.long 0x222
.long 0x333
Main: pushl %ebp
rrmovl %esp , %ebp
irmovl $12 , %esi
subl %esi , %esp
irmovl src , %eax
rmmovl %eax , (%esp)
irmovl dest , %eax
rmmovl %eax , 4(%esp)
irmovl $3, %eax
rmmovl %eax, 8(%esp)
call copy_block
irmovl $12 , %esi
addl %esi , %esp
popl %ebp
ret
copy_block:
pushl %ebp
rrmovl %esp, %ebp
xorl %eax , %eax
mrmovl 12(%ebp) , %edx #edx <==>dest
mrmovl 8(%ebp) , %esi #esi <==> src
mrmovl 16(%ebp),%ecx #ecx <==> len
andl %ecx, %ecx
je End
Loop: mrmovl (%esi) , %ebx
rmmovl %ebx , (%edx) #copy src value to dest
xorl %ebx , %eax #compute the value ^= val
irmovl $4 , %edi
addl %edi , %edx #dest++
addl %edi , %esi #src++
irmovl $1,%edi
subl %edi , %ecx #len--
jne Loop
End: popl %ebp
ret
.pos 0x100
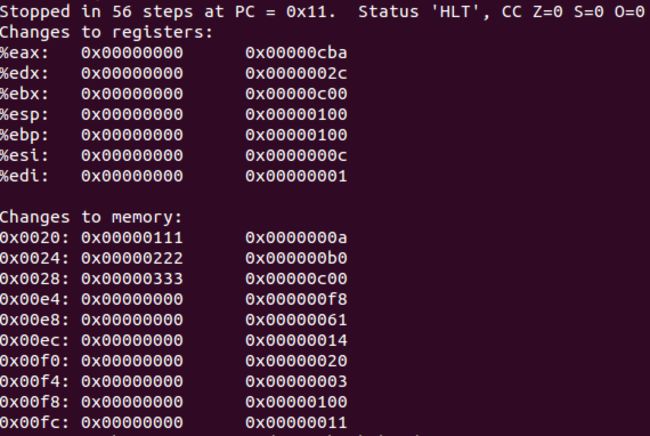
Stack:相关运行结果:关注寄存器%eax中和0x00000111 ~ 0x000000333存储器中的答案
Part B
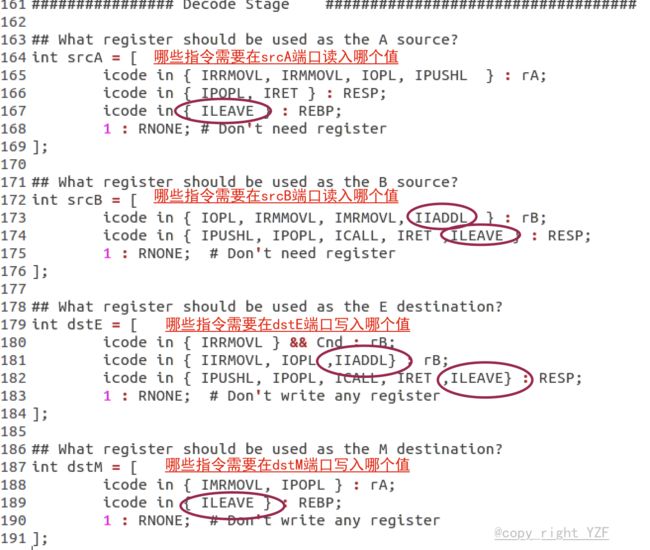
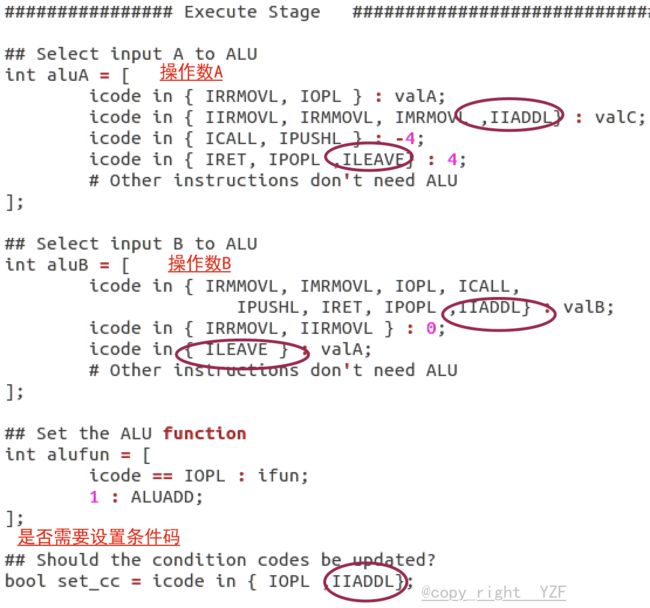
本实验的工作目录在sim/seq文件夹下,修改seq-full.hcl文件,添加新指令。
实验要求:相关指令的实现需求见《深入理解计算机系统》P310
(1)实现 iaddl指令 要求见练习题4.48、4.50,可以参考irmovl、opl的实现
(2)实现 leave指令 要求见练习题4.47、4.49,可以参考popl的实现
首先修改seq-full.hcl文件需要于都CSAPP处理器体系结构相关章节内容。实验的评分要求中,还需要写出iaddl、leave在顺序实现中的计算过程。
结合irmovl、opl的计算过程,通过分析,我们得到iaddl的计算过程如下:
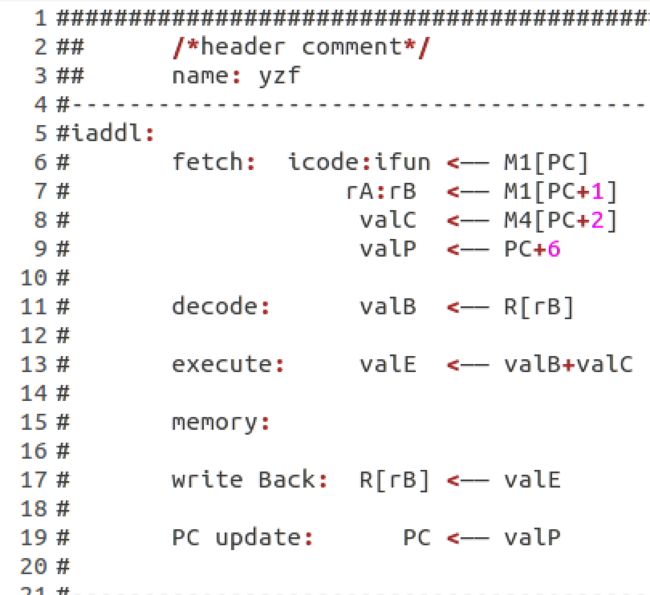
结合popl的,结合leave指令分析分析得到:
%ebp-new = (%ebp-old) (新ebp指向的地址等于原ebp指针指向的存储器地址中的内容)
%esp-new = %ebp-old+4 (新esp指向的地址为原ebp指向的地址+0x4)
结合分析得到如下的计算过程

相关seq-full文件的修改如下所示:相关文件见下载链接中的seq-full.hcl文件
取指阶段:

译码与写回阶段:
- 执行阶段:
- 访存阶段:

- pc更新:未作修改
相应修改的结果通过了实验规定的测试。
注意编译时,可能遇到tcl not found;tk not found;libtcl not found;libtk not found问题
解决方法1: 将Make里面的注释“Comment this out if you don’t have Tcl/Tk.”下的行注释或删除
解决方法2:
tcl和tk文件:sudo apt-get install tk8.5-dev cl-8.5-dev
(一定要版本小于等于8.5,8.6版本有些属性已经被删除)
libtk和libtcl:sudo ln -s /usr/lib/x86_64-linux-gnu/libtk8.5.so /usr/lib/libtk.so
sudo ln -s /usr/lib/x86_64-linux-gnu/libcl8.5.so /usr/lib/libtcl.so
Part C
实验C主要在sim/pipe文件夹下,任务为修改ncopy.ys和pipe-full.hcl 文件使得ncopy.ys 的运行速度越快越好。
pipe-full.hcl 推荐实现iaddl指令。在仅实现iaddl并且将ncopy.ys中的相应指令替换为iaddl后,时间由原来的16.44 提升到了13.96。相应iaddl在pip-full.hcl中的实现方法与partB中的实现类似,实现的结果见下载链接文件。
其中该部分实验最主要实现的是优化ncopy.ys函数。本解法主要涉及到的是CSAPP第五章的优化方法中的“循环展开方法”和第4章中的“加载使用冒险”
对于ncopy.ys中的ncopy函数进行了4次的循环展开。并且在原始的函数中存在加载使用冒险,如下所示,mrmovl从存储器中读入src到esi,rmmovl从esi存储到dest中,期间因为加载使用冒险所以需要暂停一个周期,针对这个进行改进。
mrmovl (%ebx), %esi # read val from src
rmmovl %esi, (%ecx) # store src[0] to dest[0]主要改进的方法在这两条指令中插入另一条mrmovl指令,避免了冒险节省时间,也为后面的循环展开提前获取到了值。
ncopy.ys相应改进部分实现如下所示:
# You can modify this portion
# Loop Header
xorl %eax , %eax
iaddl $-4 , %edx #len = len -4
andl %edx , %edx
jl remian
Loop: mrmovl (%ebx) , %esi
mrmovl 4(%ebx),%edi
rmmovl %esi , (%ecx)
andl %esi ,%esi
jle LNpos1
iaddl $1 , %eax
LNpos1: rmmovl %edi , 4(%ecx)
andl %edi , %edi
jle LNpos2
iaddl $1, %eax
LNpos2:mrmovl 8(%ebx) , %esi
mrmovl 12(%ebx),%edi
rmmovl %esi ,8 (%ecx)
andl %esi ,%esi
jle LNpos3
iaddl $1 , %eax
LNpos3: rmmovl %edi , 12(%ecx)
andl %edi , %edi
jle nextLoop
iaddl $1, %eax
nextLoop:
iaddl $16,%ebx
iaddl $16,%ecx
iaddl $-4,%edx
jge Loop
# maybe just remain less than 3
remian: iaddl $4 , %edx # Restore the true len
iaddl $-1, %edx
jl Done
mrmovl (%ebx) , %esi
mrmovl 4(%ebx),%edi
rmmovl %esi , (%ecx)
andl %esi ,%esi
jle rNpos
iaddl $1 , %eax
rNpos:
iaddl $-1, %edx
jl Done
rmmovl %edi , 4(%ecx)
andl %edi , %edi
jle rNpos1
iaddl $1, %eax
rNpos1:
iaddl $-1 , %edx
jl Done
mrmovl 8(%ebx) , %esi
rmmovl %esi , 8(%ecx)
andl %esi ,%esi
jle Done
iaddl $1 , %eax
##################################################################
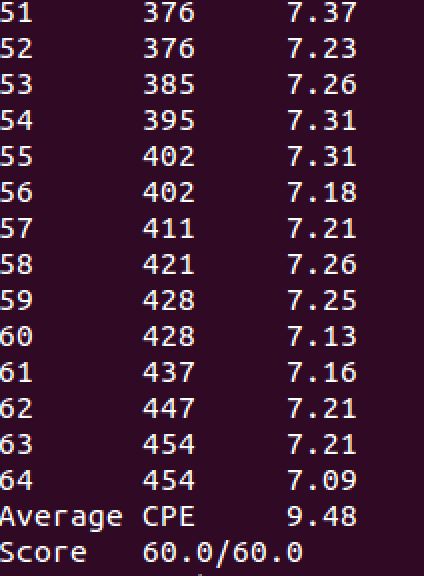
最后的实现结果如下所示:
通过./correctness.pl 命令验证了不同长度数据的操作的正确性
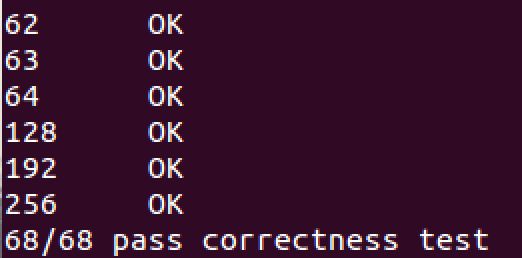
通过./benchmark.pl 命令检验了CPE时间,Average CPE < 10.0得满分