CSAPP: Cache Lab
介绍
本实验帮助我们更好的理解高速缓存对于C语言程序性能的影响
该实验分为2部分,part A主要是实现一个模拟缓存行为的C语言程序,大概行数在200~300多行左右。part B主要是优化特定维的矩阵转置操作,目标是显著能够减少缓存的命中数。
实验准备
下载相关的原始实验包,原始实验包github地址
下载本博客具有解答实验包在如下地址,实验包
为提供帮助,我还将CMU对于该实验辅助材料上传,下面是下载地址。
实验的PDF、实验的指导PPT
注意:Do not let the Windows WinZip program open up your .tar file . Instead, save the file to your Linux directory and use the Linux tar program to extract the files. In general, for this class you should NEVER use any platform other than Linux to modify your files. Doing so can cause loss of data (and important work!).
Part A
根据实验指导PDF中要求,实现模拟缓存行为的C语言命令行程序。
需要注意以下几点:
1. 本次实验要求实现模拟缓存的C程序,而不是真实的缓存,所以不用太害怕
2. 该C语言程序能够根据不同的参数输入,进行不同的计算
3. 该程序的中内存替换策略是LRU(最近最少使用)
本博客中用到的相关重要的C语言函数:
1. getopt()该函数能够帮助程序分析C语言命令行程序输入的参数。相关介绍见实验指导PPT第20页 or google
2. fscanf函数,该函数能够帮助用户处理文本文件中输入的格式化数据,看这个函数就知道类似于scanf,同样想要了解更多google或者看PPT
3. malloc 和free 分配内存和释放
实验中需要用到的数据结构

根据上面的提示我们实现如下数据结构:
typedef struct{
int valid; //有效位
int tag; //标识位
int LruNumber; //LRU算法需要位
} Line;
typedef struct{
Line* lines; //cache set包含的行
} Set;
typedef struct {
int set_num; //组数
int line_num; //行数
Set* sets; //模拟cache
} Sim_Cache;LRU算法的算法实现是基于LruNumber,是一个简易版本的实现。模拟内存对象初始化时所有LruNumber均为0。当某组中的某行hit 或者加载缓存成功时赋值LruNumber为MAGIC_LRU_NUMBER,而该组中的其他行LruNumber全部减一。当eviction 时,选择最小LruNumber的行进行evict。
本次实现中用到的函数列表如下:

具体编码内部实现请参看该文件链接
重点需要解释是L,M,S操作。
L对应loadData,这个操作会可能引发如下几种情况:hit OR miss OR miss eviction。
S对应storeData,这个操作可能引发的情况与L相同,所以实现中直接在storeData函数中调用了loadData函数
M对应modifyData,这个操作实质上是先调用load data then store data,所以可能会出现 2次hit or miss hit or miss evition hit三种情况。
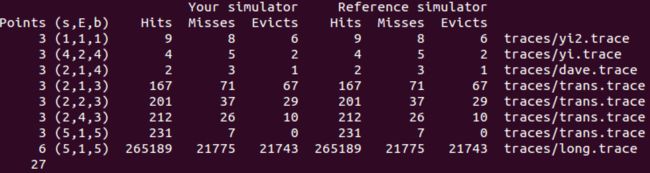
相关实验结果:
Part B(未完待续)
part B主要涉及提升矩阵转置的cache命中率。主要用到的将大矩阵块分解为小的矩阵来计算。
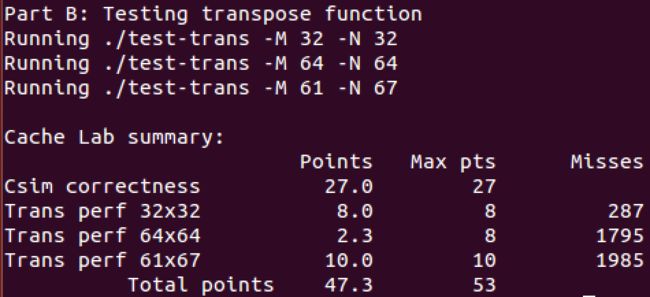
仅在32*32 、61 * 67中拿到了full score。等之后对于64 * 64有解法再来详细补充撰写该部分。
实验撰写的trans.c代码见链接(https://github.com/Davon-Feng/CSAPP-Labs/blob/master/yzf-cachelab-handout/trans.c)
下面是简单的分析:
首先对于测评条件进行分析s=5、E=1、b=5可以得到,内存中有32组,每组块大小为32字节(8个int),而且采用的是直接相连映射。
通过最普通的矩阵转置放方法的测试之后会生成trace.f0数据文件。通过我们之前编写的csim程序模拟输入结果(为什么不用./csim-ref,因为我期望打印出其他有用的信息),我们可以看到A矩阵和B矩阵相同的下标是映射到相同的组中的。
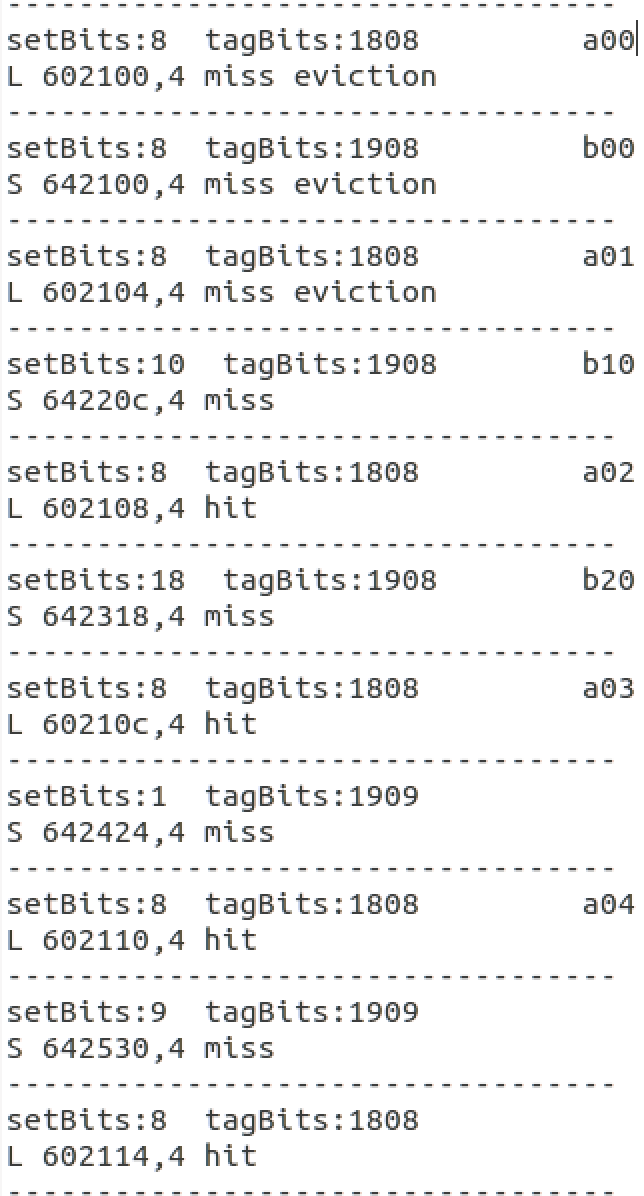
在32 * 32 矩阵中,我们将矩阵分解为8 * 8,为什么是8 8?因为cache一行正好放下8个int数据。该分解的相比于普通的转置方法而言好处在于,8 8矩阵内转置基本只有 cold conflict,而且充分利用了内存中加载行,对其进行充分的操作,而传统的一行一行转换,没有对cache中加载的行进行充分利用 (可以自己手动模拟看看)。
对于对角线上面的元素,可能会出现冲突,因为A行和b行映射到同内存一行中,为了防止这种冲突对于本块中内存数据换进换出的影响,我们在函数每次循环的碰到对角线元素时先存储好,然后在本次循环结束时才处理对角线元素。
在61 * 67矩阵,经过多次测试,用16 * 16矩阵块分割
在64 * 64矩阵,按照32 * 32的思维简单的分析一下用了4 * 4的矩阵块分割,但是效果不是特别理想只得到2.3分
下图是Part A & Part B的打分。可以看到64 * 64 没有拿到满分。