socket和IO流
socket
加一个程序,java默认是双字节编码,它是utf-16be编码,中英文都占两个字节
/**
*解析java字符串,有中文英文,把它以多种编码方式解析成字节序列( s.getBytes()),
* 再来分析 中文英文 所占用的字节数。。。。。,看编码的区别
*/
public class EncodeDemo {
public static void main(String[] args) throws Exception{
String s = "慕课ABC";
byte[] bytes1 = s.getBytes();//转成字节数组,这里用的是项目默认的编码
for (byte b : bytes1) {
//把字节转换成了int,以16进制的方式显示
//byte --> int(4个byte) 后八位前面添24个0,变成32位。
// 但是前24个0没有意义,没有必要显示出来,所以这里 & 0xfff ,去掉24个0只留下后8位
//这个方法返回的字符串表示的无符号整数参数所表示的值以十六进制(基数为16)
// System.out.print(b);
System.out.print(Integer.toHexString(b & 0xfff)+ " "); //用16进制的方式来看每一个字节
//fe6 f85 f95 fe8 faf fbe 41 42 43 (A B C)41 42 43
}
System.out.println();
//结论:GBK编码中文占用2个字节,英文占用一个字节
byte[] bytes2 = s.getBytes("gbk");
for (byte b : bytes2) {
System.out.print(Integer.toHexString(b & 0xfff)+ " ");
}
System.out.println();
//结论:utf-8编码中文占用3个字节,英文占用一个字节
byte[] bytes3 = s.getBytes("utf-8");
for (byte b : bytes3) {
System.out.print(Integer.toHexString(b & 0xfff)+ " ");
}
System.out.println();
//java是双字节编码,它是utf-16be编码
//结论:utf-16be编码 中文英文都占用2个字节
byte[] bytes4 = s.getBytes("utf-16be");
for (byte b : bytes4) {
System.out.print(Integer.toHexString(b & 0xfff)+ " ");
}
System.out.println();
/**
*当你的字节序列是某种编码时,这个时候想把字节序列变成字符串,
* 也需要用这种编码方式,否则会出现乱码
*/
String str1 = new String(bytes4); //这里项目编码和bytes4编码不一致,这样就乱码了
System.out.println(str1);
String str2 = new String(bytes4,"utf-16be"); //这里项目编码和bytes4编码不一致,这样就乱码了
System.out.println(str2);
/**
* 所以说了这么多,结论:
* 文本文件 就是字节序列
* 可以是段任意编码的字节序列
* 如果我们在中文机器上直接创建文本文件,那么该文本文件只认识asni编码。。
* 不是创建而是从其他地拷贝,那它是认识任意编码的
*
*/
}
}一、概念
网络编程:关注的是底层数据的传输
网页编程:关注的是与客户的交互,获取数据并展现出来

一些概念

- 地址确定了电脑,端口确定了哪个软件进来,这时候资源就可以进来了,然后就涉及到数据的传输了
- tcp、udp属于不同协议
- 1024是给知名的厂商预留的端口,就像你家里电话不能设成110,预留给公共服务的
- URI是标识的,URL在URI的基础上除了标识还能定位
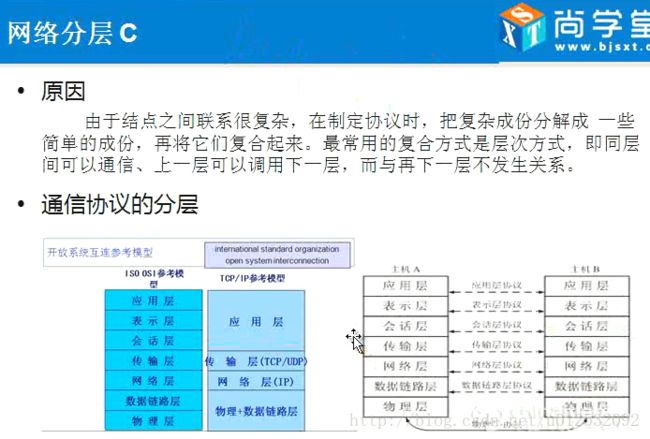
- jsp\servlet等是研究应用层,现在这个章节研究的是传输层和网络层,(物理+数据链路层)不用管,这个交给操作系统
- http协议就是用tcp协议封装写的,封装的应用层
接下来看java中那些封装好的类
数据传输的过程中,底层还是流
二、地址及端口
域名解析(DNS):翻译网址的
InetAddress这个类没有显示的构造器,那如何实例化? 就用它提供的静态方法,返回的是这个类的对象。类似于单例,但这个类不是单例。
/**
* 没有封装端口
* @author Administrator
*
*/
public class InetDemo01 {
/**
*/
public static void main(String[] args) throws UnknownHostException{
//使用getLocalHost方法创建InetAddress对象
InetAddress addr = InetAddress.getLocalHost();
System.out.println(addr.getHostAddress()); //返回:192.168.1.100
System.out.println(addr.getHostName()); //输出计算机名 Notebook
//根据域名得到InetAddress对象
addr = InetAddress.getByName("www.163.com");
System.out.println(addr.getHostAddress()); //返回 163服务器的ip:61.135.253.15
System.out.println(addr.getHostName()); //输出:www.163.com
//根据ip得到InetAddress对象
addr = InetAddress.getByName("61.135.253.15");
System.out.println(addr.getHostAddress()); //返回 163服务器的ip:61.135.253.15
//输出ip而不是域名。如果这个IP地 址不存在或DNS服务器不允许进行IP地址和域名的映射,getHostName方法就直接返回这个IP地址。
System.out.println(addr.getHostName());
}
}/**
* 封装端口:在InetAddress基础上+端口
有了端口就可以区分软件
* @author Administrator
*
*/
public class InetSockeDemo01 {
/**
* @param args
* @throws UnknownHostException
*/
public static void main(String[] args) throws UnknownHostException {
InetSocketAddress address = new InetSocketAddress("127.0.0.1",9999);
address = new InetSocketAddress(InetAddress.getByName("127.0.0.1"),9999);
System.out.println(address.getHostName()); //localhost
System.out.println(address.getPort()); //9999
InetAddress addr =address.getAddress();
System.out.println(addr.getHostAddress()); //返回:地址
System.out.println(addr.getHostName()); //输出计算机名
}
}三、三次握手

四、慕课网OKHTTP
现在广泛使用的是HTTP1.1
Charles— 这个抓包工具十分强大,可以跨平台使用。
这里不会去纠结协议每一位是什么意思,我们站在程序员的角度去HTTP协议的结构,主要分四个部分去看:请求头,请求体,响应头,响应体

方法是get还是post


响应体是返回的的JSON数据。。。。
慕课网IO /NIO
对象的存和读取,还有在网络中传输对象,这些就要用到对象的序列化和反序列化问题。

讲解见码云IO包里
下面关于序列化的一些知识点:
3.对象的序列化,反序列化 ---- 对象在网络上传输是以字节为单位的
1)对象序列化,就是将Object转换成byte序列,反之叫对象的反序列化 。白话:就是把对象保存起来。
2)序列化流(ObjectOutputStream),是过滤流----writeObject()方法
反序列化流(ObjectInputStream)---readObject
3)序列化接口(Serializable)
对象必须实现序列化接口 ,才能进行序列化,否则将出现异常
这个接口,没有任何方法,只是一个标准(标记性接口)
4) transient关键字
private void writeObject(java.io.ObjectOutputStream s)
throws java.io.IOException
private void readObject(java.io.ObjectInputStream s)
throws java.io.IOException, ClassNotFoundException
为啥有的属性要用transient修饰呢,为啥非要自己序列化,? 因为有的时候可以提高性能,看下面
分析ArrayList源码中序列化和反序列化的问题
ArrayList的属性:
transient Object[] elementData; // non-private to simplify nested(嵌套的) class access 不用默认的序列化,因为可能没有放满
private int size; size是默认序列化的
但是在实际使用当中elementData是要序列化的(自己实现),如何实现:
private void writeObject(java.io.ObjectOutputStream s)
throws java.io.IOException{
// Write out element count, and any hidden stuff
int expectedModCount = modCount;
s.defaultWriteObject(); //把默认可以序列化的元素都序列化了
// Write out size as capacity for behavioural compatibility with clone()
s.writeInt(size); //把size序列化一遍。。有效元素的个数
// Write out all elements in the proper order.
for (int i=0; i//数组有效元素的序列化,自己实现的。。。。,因为数组不一定存满了,
}
if (modCount != expectedModCount) {
throw new ConcurrentModificationException();
}
}
为什么rrayList要这么做。
原因:ArrayList底层虽然是数组,但是数组不一样放满了,没有放满的那些数组元素是不需要序列化的,所以必须要自己完成序列化。
反序列化也一样:把每个元素拿出来readObject(),然后生成一个新的数组。
总之:就是把有效元素序列化,无效的元素就不序列化了,可以提高性能。前面加transient不代表不想序列化,而是自己去做序列化的优化。。
流

- JAVA流 : 管道
输入输出:都是站在程序的角度来说。比如FileInputStream的read是读到程序在内存中分配的那块区域里去了。
字节流就是带stream的:最原始的方式读出来是 010101(一个字节等于8位)
字符流:一个个字符往外读(一个字符等于2个字节)
比如:FileInputStream 从文件往外读数据的,ByteArrayInputStream 从字节数组往外读数据,ObectInputStream 读一个对象出来,也就是序列化
先看看常见的几个节点流:
怼在文件上,怼在内存里的数组上,怼在一个string上,怼在一个管道上(线程间的通信)。
stream基本方法
带stream的都是字节流、读一个字节并返回一个整数。
int read(byte[] buffer) throws Excepton: 读一个字节数组出来,也就是缓冲区。。
缓冲区:桶。。 . buffer(这个字节数组)就是桶。所谓桶:在内存中装满一桶水,再一次性的读或者写。实际可能只装了半桶。。 读一(半)桶水
flush:良好的编程习惯:先flush再close




reader/writer基本方法
一个一个字符往外读,读是向程序中输入。。
类似地:int read() 读一个字符出来
int read(char[] cbuf) 读一个字符数组出来,也就是缓冲区 ,一桶水。。
int read(char[] cbuf,int offset ,int length) 读一个字符数组的一部分,也就是缓冲区,半桶水。。


Writer和reader类似:写一个字符,写一个字符数组,写一个字符数组的一部分。
区别在于多了个:直接写一个字符串,或者写一个字符串的一部分。。原理是一样的,调的是string的char[] toCharArray,先把string转成一个字符数组了。

package com.io;
import java.io.FileInputStream;
import java.io.FileNotFoundException;
import java.io.FileOutputStream;
import java.io.IOException;
/**
* FileOutputStream 没有文件,它会新建一个文件。。。 但是它只会建文件,不会建目录。
*
*
* 这个小程序相当于文件的复制。。
*/
public class TestFileOutputStream {
public static void main(String[] args){
FileInputStream fileInputStream = null;
FileOutputStream fileOutputStream = null;
int b = 0;
try{
fileInputStream = new FileInputStream("E:\\git\\testGit\\girl4mayun\\src\\main\\java\\com\\io\\TestFileOutputStream.java");
fileOutputStream = new FileOutputStream("F:\\fileoutputstream.java");
while ((b=fileInputStream.read()) != -1){
fileOutputStream.write(b);
}
}catch (FileNotFoundException e){
e.printStackTrace();
}catch (IOException e){
e.printStackTrace();
}finally {
try{
fileInputStream.close();
fileOutputStream.close();
}catch (IOException e){
e.printStackTrace();
}
}
}
}节点流/处理流 见下图:
节点流:管道直接怼到数据源上。。。
处理流:就是节点流的管道上再包一层。。(包了一层就是做了处理撒。。。)
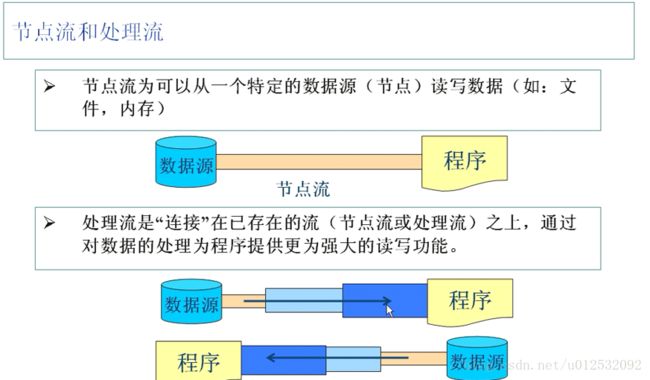
处理流:
第一个处理流——缓冲流:JDK提供了4种
BufferedReader 的 readLine() 特别好用,把一行内容当作字符串读出来,以前是一个字符一个字符往外读,现在是一行行的读
记一个:往文件里面写用FileWriter BufferedWriter


/**
* 先写再 读。。。 写是往文件里写
*/
public class TestBufferedStream {
public static void main(String[] args){
BufferedWriter bufferedWriter = null;
BufferedReader bufferedReader = null;
String s;
try{
bufferedWriter = new BufferedWriter(new FileWriter("F:\\bufferedWriter.java")); //先往文件里面写
bufferedReader = new BufferedReader(new FileReader(("F:\\bufferedWriter.java")));
for(int i=0;i<100;i++){
bufferedWriter.write(String.valueOf(Math.random()));
bufferedWriter.newLine(); //写一个随机数,换一行
}
bufferedWriter.flush(); //重要,把缓冲区的内容全部flush到硬盘
while( (s = bufferedReader.readLine()) != null){
System.out.println(s);
}
}catch (FileNotFoundException e){
e.printStackTrace();
}catch (IOException e){
e.printStackTrace();
}finally {
try{
bufferedWriter.close();
bufferedReader.close();
}catch (IOException e){
e.printStackTrace();
}
}
}
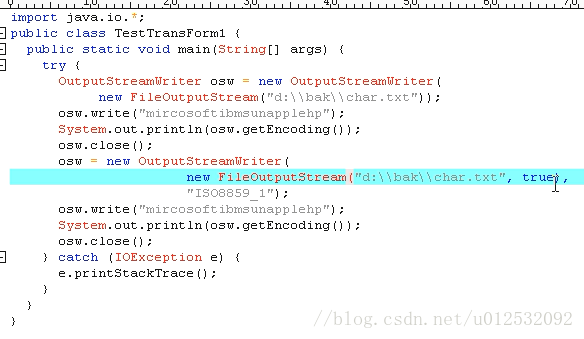
}第二个处理流 —– 转换流
可以把字节流转换成字符流。套接一下。
转换流可以一个字符串一个字符串的读写,还可以指定编码。。。 没有指定编码就用系统默认的编码:GBK。。
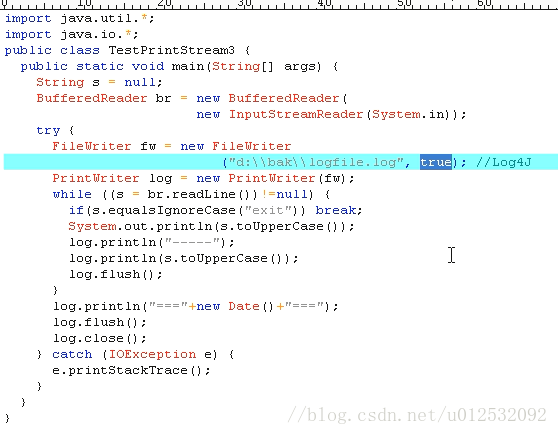
构造方法后面跟上true,表示在文件中继续写。具体见下面代码。

这里用最外层包的管道BufferedReader的readlLine方法,可以一行一行的读,用起来比字节字符都方便
System.in 等待着标准输入,wait在那里,是一种阻塞式等待,线程里还会用到。
常用的BufferedReader包一个InputStreamReader,InputStreamReader包一个InputStream
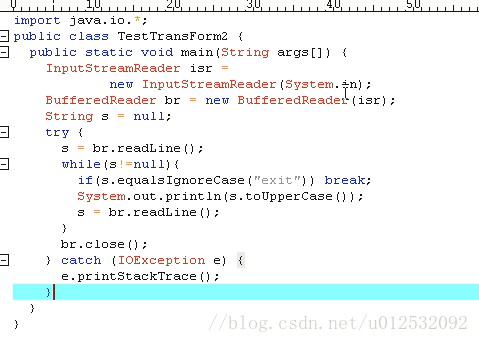
第三个处理流:数据流

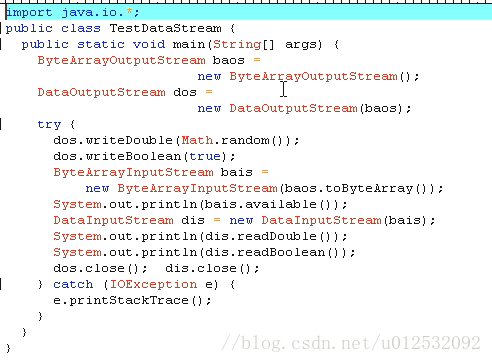
第四个处理流:打印流。这里就只有输出了。
不会抛异常,这个好用,JSP里面会用到。。。。
printWriter的print() 和 BufferWriter wirte()类似,经常用printWriter和BufferReader搭配使用也是很方便的

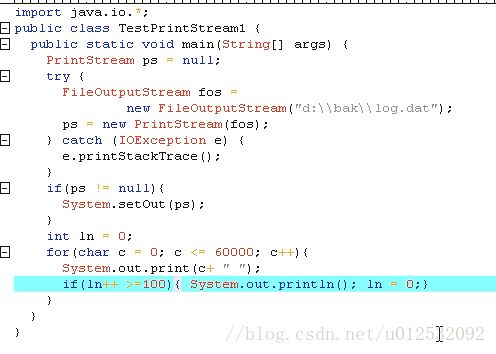
读文件内容并输出到控制台:
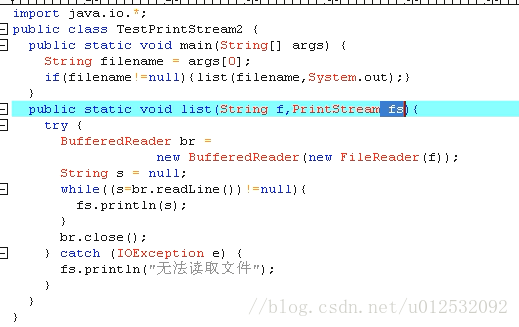
日志操作:
第五个流:Object流
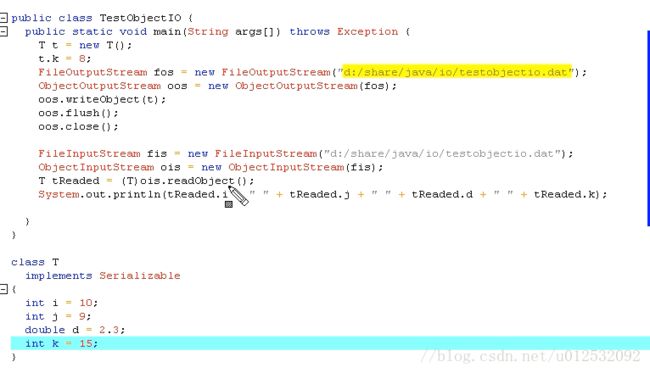
什么叫序列化:把一个Object直接转成字节流写到硬盘,或者写到网络上。
在网络上传输也是以 字节为单位 进行传输的。。

- Serializable接口:
想把一个对象写到硬盘或者网络上,也就说想序列化成一个字节流,那必须实现Serializable接口,这个接口叫标记性接口(就是给类打一个标记给编译器看,编译起看到之后就知道这个类可以被序列化),没有定义方法。
- transient关键字:
透明的,可以修饰成员变量。相当于这个成员变量在序列化的时候不予考虑。 修饰了之后,往硬盘上写就不写它了。
- externalizable接口:
自己可以控制序列化过程。建议不要自己控制,因为JDK已经帮你控制了 类的 序列化。。。
以下例子:先把T写到文件,再从文件中读出来
编码的问题
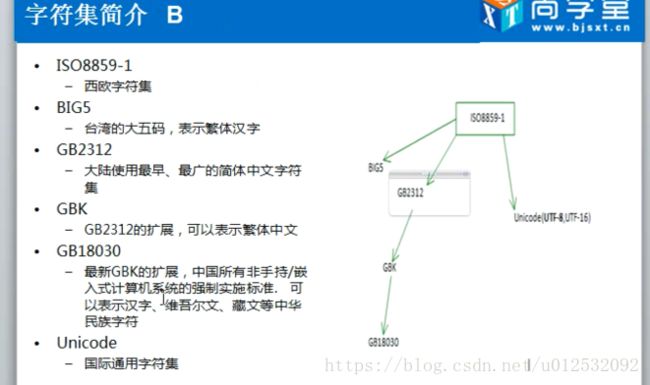
一个字节8位,最多能表示2的8次方个字符(256个)。那一个字节表示不了中国所有文字,也表示不了其他国家的文字,因为256个不够,这个时候就有了各种各样的编码方案。中文的编码是GBK,
java字符采用的是unicode编码(所以可以表示全世界所有的文字),unicode其实又分为两种:一种是utf8 一种是utf16,java采用的是utf16,一个字符占用2个字节,哪怕是一个字母占用的也是2个字节。
2个字节就是16位嘛,所以可以用十六进制编码形式表示。
十六进制:0-15 最大是15。
如何表示:10是A,11是B,15是F。
2进制转16进制:四位一变。四位转成10进制,再转成16进制。

再补充:
unicode–universe通用的意思,顾名思义表示通用的字符集,既然是通用的就可以表示全球所有的字符。所以的汉字都可以表示,它用两个字节表示一个字符。
两个字节就是16位,16位是2的16次方(65536),可以表示65536种字符,对于全世界的文字这个足够了。

乱码产生:1、字符的编码解码要用同一个编码格式,否则会乱码。
2、用不能表示中文的编码去 编码,也会中文乱码。
NIO

尚学堂的NIO
举个例子,有个认识:
很多地方用到了netty。
比如共享桌面,直播软件,实时地把二进制包发给你,就能看到桌面啊,视频啊,听到声音了。
滴滴打车啊,你上车之后什么价格实时增加啊,距离实时变化啊。这就是你的手机端和服务器一直处于连接中,NETTY的长连接。服务器会不断的把数据推送给你 。
1、网络编程
HTTP协议是TCP协议的一个封装。
这里涉及到的三次握手,四次挥手,自己去百度搞懂。

BIO和NIO的区别:简单的说就是阻塞和非阻塞
BIO:完全依赖于网络,网络传的慢程序就阻塞了。
NIO:依赖于一个中间的缓冲区,先把数据放到缓冲区(channel),准备好之后一次性把数据刷给你。
NIO和AIO的区别:同步和非同步
NIO1.0的实现就是下图(同步时)的描述。
AIO(NIO2.0)的实现就是下图(异步时)的描述。 (这还是概念的理解,具体理解,去看代码)

1.3传统的BIO编程
简单来说:(可以参考代码)
服务端:
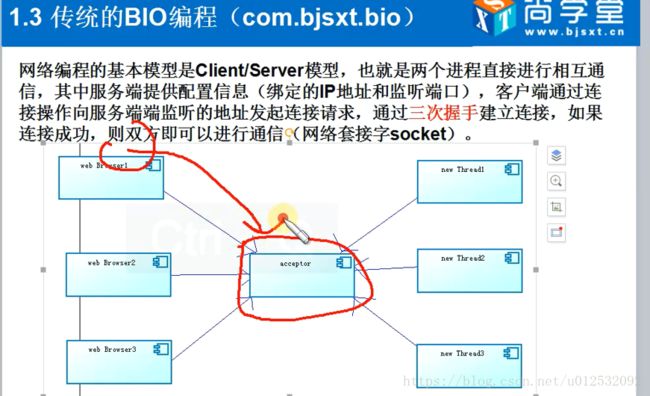
S启动起来就阻塞(accepted)着,有一个C端给S建立一个连接后,这个阻塞就通过了,S就启动一个线程去执行CS间交互的工作。
客户端:要寻址吧(TCP的方式都得寻址),IP+端口号确定一个唯一的S主机。
总之:二者是通过套接字(socket)进行通信的。 S启动时程序阻塞在那, 然后C把一个socket对象传给S,S拿到这套接字对象,通过getInputStream和getOutPutStream进行双向通信。
如何运行:S先run起来,在那等着。C发一个socket过去,S收到之后在serverHandler里面通过socket.getInputStream得到这个请求(可以把这个打印出来),然后用out再往回写(out也是通过socket.getOutPutStream写回去的)一根管道怼在客户端发过来的socket上面。。
1.4 引出伪异步IO
这种BIO的弊端:一方面网络不好,程序就阻塞不动了。
另一方面:S端会产生大量的线程。(一般地普通Windows机器创1000多个线程就极限了)。
所以就有了伪异步IO,线程池的方式。。具体做法如下图:
那这么多线程池模型,用哪个好呢。(fixed,single,cache等)用fixed方式好,能限制线程数。
但是这种方式不是最好的, 只是以前没有分布式的概念,用这个方式来缓解下BIO的缺点。
和之前的BIO相比,只是S端多了一个线程池来缓解,C端还是不变。好处就是不至于线程过多,直接把服务器撑爆了。
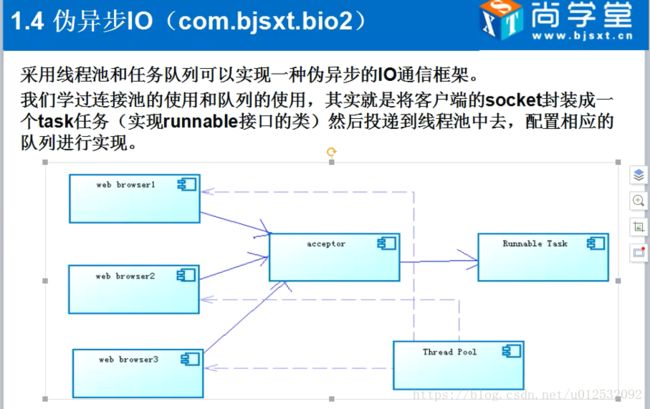
2.1 说一句,NIO的框架就是netty
JDK1.5之后 提出了NIO。。 Non-Block IO 非阻塞式IO
原始是通过TCP去连的,现在是channel(也叫通道,对TCP连接的再一次抽象)。它不通过握手去建立连接了。
先注册到server的选择器上,然后server再去轮询注册在选择器上的channel,看不同的channel的状态再去做不同的事。
注册只是一个抽象的过程,不是真正去建立TCP连接。
但是NIO是同步的,为什么是同步呢? 因为选择器一直去轮询注册在它身上的channel(通道)。
是非阻塞的。为什么呢?因为只要通道写好了,数据准备就绪了,那就直接去通道获取数据了。而不是通过TCP的方式。
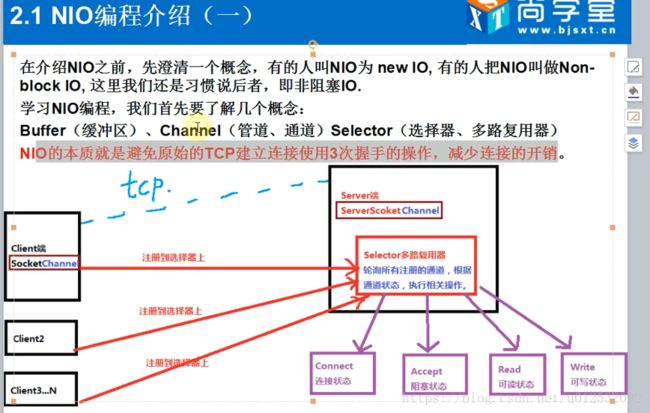

2.3 channel
这个管道是C端直接挂在S端的一个管道(注意和之前的流那个管道不是一个概念)。
channel是一个双向的,读写都是一个管道。而之前的IO流都是单向的,要么去写要么去读。

2.4 selector
像一个管家一样,去管理各种各样的通道。

首先是C把数据写到管道并注册,然后S去轮询通道的数据,如果这个通道的数据已经就绪了(已经准备好),那直接去读写就行了。这就是非阻塞的:已经准备就绪了,再去IO读写操作的。之前的TCP方式是建立连接后才开始读写操作。
详细过程见下图第二段描述:
分配一个key值,这个很重要。

其实在NIO中,最麻烦的是buffer。
下面看看buffer的常用API,是如何操作的:
关键点:往里放完元素,在读之前一定要执行一个复位的方法。buffer.flip();
再看看C和S端 是如何写的。。也就是NIO是怎么实现的。
NIO理解还好,但是实现起来很麻烦。因为它C和S 两端都要做 多路复用器的 监听操作,还有很多琐碎的操作很麻烦。如果再加上复杂的业务逻辑,那简直不能忍。
3.1 AIO
AIO恰恰和NIO相反,它是概念难理解,但是实现起来简单。。