影像大数据:ArcGIS Image Server
AI(人工智能)大概是当前技术圈最火的风向,地理大数据和AI碰撞产生了一个新的概念GeoAI。GeoAI时代,ArcGIS为用户和开发者提供了三个框架:
(1)地理处理框架(GP)
(2)空间大数据计算
(3)机器学习(ArcGIS Pro中自带机器学习工具,10.6版本中集成了微软 CNTK、谷歌TensorFlow等深度学习框架)
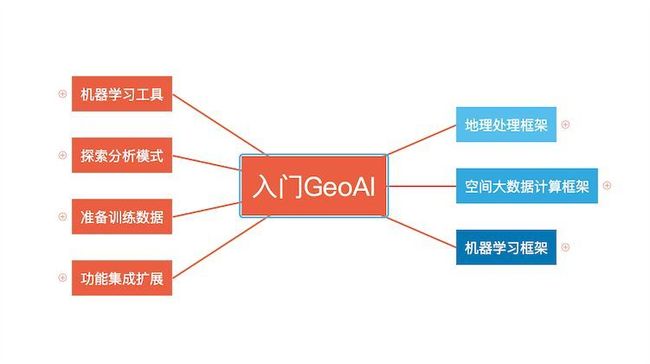
每一个框架都是很复杂的,这里不详细讨论每一个框架,重点讨论ArcGIS的空间大数据计算框架中的RA工具。
1.大数据
大数据的定义很多,通常认为大数据符合5个V特征:Volume(大量)、Velocity(高速)、Variety(多样)、Value(低价值密度)、Varacity(真实性)。大数据技术基本就是为了处理传统的单机尺度无法处理的数据而诞生的。
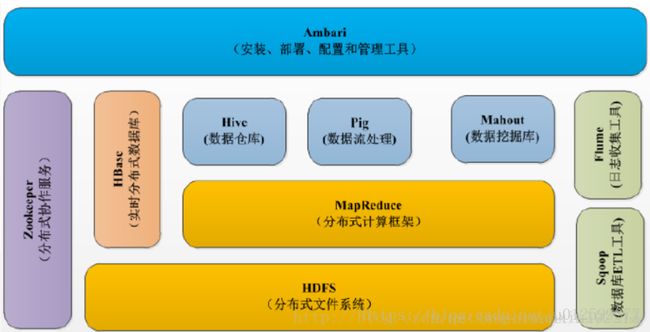
(1)HDFS(Hadoop Distributed FileSystem)
HDFS(Hadoop分布式文件系统)解决的是大数据的存储问题。传统的文件系统部署在单机上,不能跨机器,HDFS的文件被划分为多个独立存储的数据块,通过HDFS,可以将大量的数据集(典型的HDFS文件大小是GB到TB的级别)部署在集群中。
(2)MapReduce/Spark
通过HDFS解决了大数据的存储问题,接下来就是解决数据的处理问题。MapReduce和Spark都是为大规模数据处理而设计的快速通用的计算引擎。
MapReduce共分为两个计算过程:MapTask+ReduceTask。以一个我在CSDN看到的例子说明【参考1】:要求是数出一堆牌中有多少张黑桃,假使使用MapReduce方法,步骤则为:
- 给所有人分配这堆牌
- 让每个人数自己的牌中有多少黑桃,然后返回给你数量
- 你把每个玩家返回的数量相加,得到最后的结论。
当然MapReduce过程远比这个复杂,但是原理是类似的,核心思想是大事化小处理,后合并结果,先拆分再合并。
Spark,拥有Hadoop MapReduce所具有的优点;但不同于MapReduce的是——Job中间输出结果可以保存在内存中,从而不再需要读写HDFS,可以理解为使得MapTask和ReduceTask之间的界限变模糊,数据交换过程更加灵活,因此Spark能更好地适用于数据挖掘与机器学习等需要迭代的MapReduce的算法。
(3)Hive
Hive简直就是非程序员福音,MapReduce程序很复杂,而Hive的任务就是用类似SQL的语言快速实现MapReduce过程(SQL大法好)。
(4)Yarn
上述的(1)(2)(3)大致组成了一个数据仓库的框架,此外还有一些特制的系统组件,如ZooKeeper、独立的KV Store等等,因此需要一个运算资源调度系统(Yarn)去管理这些工具。HDFS、MapReduce以及Yarn则构成了Hadoop的核心组件【参考2】:
2. ArcGIS Image Server
2.1 架构
ArcGIS Image Server是ArcGIS平台实现大规模影像管理、共享与应用的服务器产品,支持基于ArcGIS镶嵌数据集的影像发布能力,支持基于Web端的实时动态处理与分布式的栅格大数据分析,即主要提供动态影像服务和分布式的栅格大数据分析(RasterAnalytics)两大核心能力。
下图是Image Server的系统架构【参考3】:
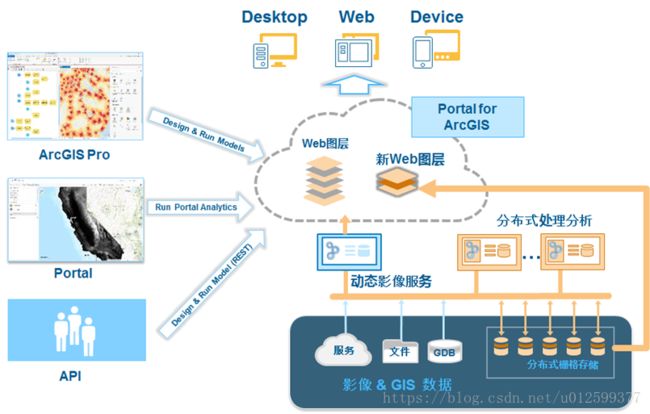
(1)数据层:存储在文件、GDB中的数据都可以通过ArcGIS Image Server发布为动态影像服务;这些数据和服务可以作为RasterAnalytics(RA)分析的数据源,同时还需要分布式的栅格存储存储分布式计算结果;
(2)服务器层:动态影像服务发布和RA分布式计算
(3)客户端:多端调用,目前集成栅格大数据分析工具的客户端包括ArcGIS Pro、Portal for ArcGIS(Map Viewer)、ArcGIS Rest API、ArcGIS Python API。
2.2 配置
具体的配置步骤可以参考我的博客,里面对GA的配置过程比较详细,RA不是很详细:https://blog.csdn.net/u012599377/article/details/81096627。
配置RA栅格分析,依赖3个主要部分:Base ArcGIS Enterprise、ArcGIS Image Server的栅格分析、ArcGIS Image Server的影像托管服务器(其中包含栅格存储,用于存储分布式计算结果)。
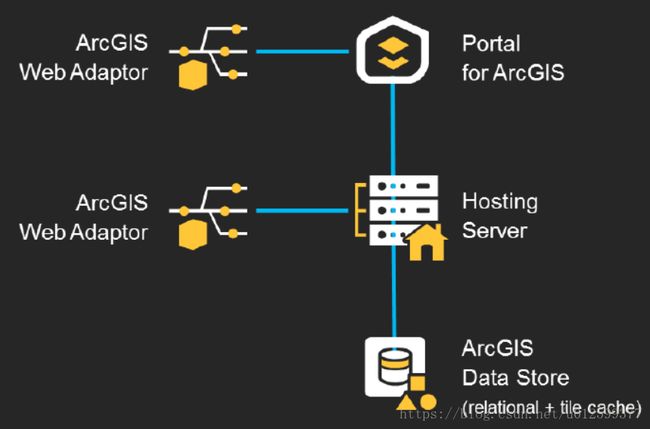
1.Base ArcGIS Enterprise:
包含4个核心组件:ArcGIS Server、Portal、Data Store以及Web Adaptor,具体安装可参考博客Enterprise部分:
2.最小栅格分析系统
官方指导文档上注明了需要3个组件,其中包含Image Server栅格分析服务器以及Image Server影像托管服务器,但是我在尝试安装的时候,发现Image Server栅格分析服务器和影像托管服务器可以使用同一个,因此就构成了一个最小的栅格分析系统:

3.官方指导文档上的栅格分析系统配置:
示例:以我自己的安装为例(Vmware Workstation 14):
(1)安装前设置
①安装4个Windows Server 2016 DataCenter,需要保证配置完全一致(win server2012 R2,安装的时候需要打补丁,会稍微麻烦些)
②设置静态IP,添加hosts映像
③设置共享文件夹(后面会用到UNC路径)
(2)安装过程:
①主机1(server0.esrichina.com):
- 配置Base Enterprise
- Data Store选择关系型和切片缓存
②主机2(server1.esrichina.com):
- 安装Image Server,作为栅格分析服务器
- 配置Web Adaptor,和主机1的Portal进行托管
- Server Manager界面,注册栅格存储(必须注册,否则无法添加栅格分析服务器)
③主机3(server2.esrichina.com):
- 安装Image Server,作为影像托管服务器
- 配置Web Adaptor,和主机1的Portal进行托管
④主机4(server3.esrichina.com):
- 安装Data Store,注册到主机3的Server中,类型选为关系型和切片缓存(关系型必选)
(3)Portal设置
- 设置server1作为Hosting Server
- 设置server2作为栅格分析服务器
- 设置server3作为影像托管服务器
以上是执行栅格分析的总体配置过程,期间会遇到各种问题,只能见招拆招,大致方向对了问题就不大。
2.3 使用RA
分布式栅格计算工具RA支持多端调用,Portal、ArcGIS Pro、Rest api等,也可以作为一个安装是否成功的验证。
1. ArcGIS Pro调用RA
【分析】->【栅格分析工具】或者右边栏地理处理中的【门户】->【栅格分析工具】 
2. Portal调用RA
【主页】->【我的地图】->【分析】->【栅格分析】
(3)Rest api
地址:https://localhost/arcgis/rest/services/System/RasterAnalysisTools/GPServer
(4)ArcGIS api for Python
ArcGIS api for Python不同于ArcMap中的Arcpy,他的定位更倾向于Web端,但是目前我了解还不够深,相对应用也比较少,目前还没有什么心得,等后期学习了单写一篇pyhton api。
2.4 安装过程中遇到的坑
ArcGIS Image Server作为ArcGIS新推出的大数据产品,相关文档非常非常非常非常少,安装过程中遇到各种各样的问题,大概记录了一些我还记得的问题,希望能有所帮助。
1.Windows Server 2016 Data Center安装Web Adaptor,Web Adaptor安装完会自动弹出设置窗口,但是返回404
解决:默认打开的网址是:https://localhost/arcgis/webadaptor,将localhost修改为主机名,比如将localhost替换成server1.esrichina.com即可解决。
2.推荐使用Chrome,有时候IE会打不开页面
3.Data Store存储类型选错,重新配置Data Store时,需要先解绑Server和Data Store
解决:登录https://自己的登录名/arcgis/admin/login,解绑Data Store
4.Portal添加Server时,报错不通过 Web Adaptor 访问门户时,将禁用联合服务器

解决:去掉网址中的端口,例如server0.esrichina.com:7443改成server0.esrichina.com,重新登录即可。
5.Portal绑定server错误,重新绑定报错
解决:需要先解绑,再重新绑定,解绑地址:
https://自己的登录地址/arcgis/portaladmin/federation/servers
……还有一些问题,等整理好了再补充。
2.5 结尾
大数据、云计算、AI、区块链……技术在不停的发展,传统的地理学和信息技术碰撞迸发出大量的火花,新技术正在给地理学带来变革,不时刻保持学习,早晚会被淘汰。
路漫漫其修远兮,吾将上下而求索。
欢迎关注我的微信公众号,基本不更新:gis小僧
