小呆学数据分析——Digit Recognizer字体识别
文章目录
- 0. 问题
- 1. 数据初步分析
- 2. 第一轮学习
- 2.1 数据标准化
- 2.2 模型训练及预测
- 2.2.1 第一次尝试
- 2.2.1.1 k近邻法
- 2.2.1.2 支持向量机
0. 问题
MNIST 数据集来自美国国家标准与技术研究所, National Institute of Standards and Technology (NIST). 训练集 (training set) 由来自 250 个不同人手写的数字构成, 其中 50% 是高中学生, 50% 来自人口普查局 (the Census Bureau) 的工作人员. 测试集(test set) 也是同样比例的手写数字数据.
本题目就是通过带有标签的训练集预测出测试集的字体识别。
项目数据来自:https://www.kaggle.com/c/digit-recognizer/data
1. 数据初步分析
在python中导入数据,并观察
import pandas as pd
df = pd.read_csv(r'H:\DataAnalysis\digitrecognizer\train.csv')
print(df)
print(df[df.isnull().values])
print(df.isnull().any().describe())
label pixel0 pixel1 pixel2 ... pixel780 pixel781 pixel782 pixel783
0 1 0 0 0 ... 0 0 0 0
1 0 0 0 0 ... 0 0 0 0
2 1 0 0 0 ... 0 0 0 0
3 4 0 0 0 ... 0 0 0 0
4 0 0 0 0 ... 0 0 0 0
... ... ... ... ... ... ... ... ... ...
41995 0 0 0 0 ... 0 0 0 0
41996 1 0 0 0 ... 0 0 0 0
41997 7 0 0 0 ... 0 0 0 0
41998 6 0 0 0 ... 0 0 0 0
41999 9 0 0 0 ... 0 0 0 0
[42000 rows x 785 columns]
Empty DataFrame
Columns: [label, pixel0, pixel1, pixel2, pixel3, pixel4, pixel5, pixel6, pixel7, pixel8, pixel9, ...]
Index: []
[0 rows x 785 columns]
count 785
unique 1
top False
freq 785
dtype: object
可以看出数据集中没有缺失值。
2. 第一轮学习
在第一轮学习中,通过sklearn库中的多种机器学习方法进行数据分析。
2.1 数据标准化
数据集的一行(即一个样本)是28x28像素点的组成灰度图片,所以像素点是0-255的整型数值,为了能够更好的进行数据挖掘,需要对其进行标准化转换。
在标准化转换可以选择最大值转换,也可以将其转化成One-Hot编码形式。
def feature(df, op='binary'):
feature = df
if op=='binary':
feature[feature < 1] = 0
feature[feature > 0] = 1
elif op=='scale':
from sklearn.preprocessing import MaxAbsScaler
sc = MaxAbsScaler()
feature = sc.fit_transform(feature)
return feature
2.2 模型训练及预测
第一次尝试中采用K近邻法、支持向量机。
2.2.1 第一次尝试
2.2.1.1 k近邻法
if __name__=='__main__':
# load train dataset
df = pd.read_csv(r'H:\DataAnalysis\digitrecognizer\train.csv')
train = df.values[:, 1:]
train_label = df.values[:, 0]#.reshape(train.shape[0], 1)
train_feature = feature(train, op='binary')
# load test dataset
predict_df = pd.read_csv(r'H:\DataAnalysis\digitrecognizer\test.csv')
test_feature = feature(predict_df, op='binary')
# k-neighbors classifier
knn_clf = KNeighborsClassifier(n_neighbors=5, algorithm='kd_tree', weights='distance', p=2)
knn_clf.fit(train_feature, train_label)
knn_predict_label = knn_clf.predict(test_feature)
submission = np.c_[list(range(1, knn_predict_label.shape[0]+1)), knn_predict_label]
submission = pd.DataFrame(submission, columns=['ImageId', 'Label'])
submission.to_csv(r'H:\DataAnalysis\digitrecognizer\submission3.csv', index=False)
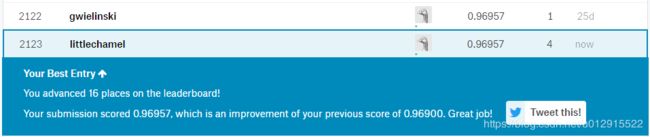
将结果上传到kaggle,准确率得分是96.385%,不是很高。如果将数据标准化用scale,可以提高一些准确率(从96.385%到96.9%)。
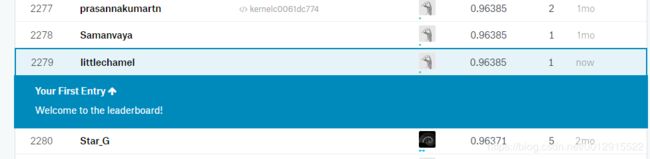
Figure 1: feature option set binary

Figure 2: feature option set scale
2.2.1.2 支持向量机
代码如下
if __name__=='__main__':
# load train dataset
df = pd.read_csv(r'H:\DataAnalysis\digitrecognizer\train.csv')
train = df.values[:, 1:]
train_label = df.values[:, 0]
train_feature = feature(train, op='scale')
# load test dataset
predict_df = pd.read_csv(r'H:\DataAnalysis\digitrecognizer\test.csv')
test_feature = feature(predict_df, op='scale')
# support vector machine
svm_clf = SVC(C=0.5, kernel='rbf', gamma='scale')
svm_clf.fit(train_feature, train_label)
svm_predict_label = svm_clf.predict(test_feature)
submission = np.c_[list(range(1, svm_predict_label.shape[0]+1)), svm_predict_label]
submission = pd.DataFrame(submission, columns=['ImageId', 'Label'])
submission.to_csv(r'H:\DataAnalysis\digitrecognizer\submission_svm_opscale.csv', index=False)
在支持向量机方法中数据标准化采用scale,准确率为96.957%,和k近邻法差不多。