基于MNist数据集进行DeepLearning学习
什么是MNist
MNist手写数据集,大多数示例使用手写数字的MNIST数据集[1]。该数据集包含60000个用于训练的示例和10,000个用于测试的示例。这些数字已经过尺寸标准化并位于图像中心,图像是固定大小(28x28像素),其值为0到1。
为简单起见,每个图像都被平展并转换为784(28 * 28)个特征的一维numpy数组。
大概是这样:
我们可以通过pip或者离线安装方式加载该数据集
在这里,我是直接用TensorFlow2了,很多操作都相对方便,本文的代码也是基于TensorFlow2的
为什么会用到这个数据集?
以我看来,学会训练这个数据集,不仅可以用来识别日常中的手写数字,这个简直就是深度学习中的Hello world,学了这个,可以说进入了深度学习的ABC了
调用流程
文字描述比较麻烦,我做了一张流程图直接看: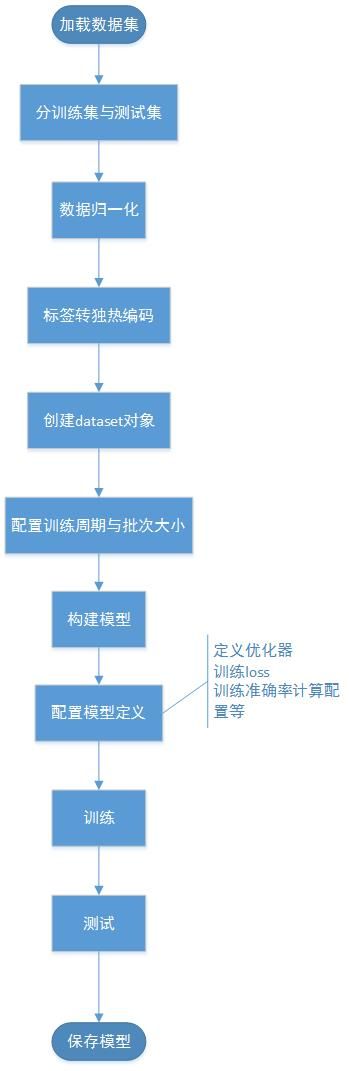
流程解析
在开发流程中,我们需要将数据集,分解成训练集和测试集,(有时候还有验证集)
顾名思义,训练集就是投入到训练过程中,将训练出一套模型后,用测试集的数据进行校验,来测算准确率。
由于数据集中是简单的数据集,文字识别类的,每个像素可以视为非黑即白,所以,我们可以对每个像素点,进行
归一化操作
什么是归一化操作?就是把目标值全部转化为1,非目标值转化成0,这样我们就可以把数据集中的每组numpy数据的每个像素点,都识别为0或者1,来降低训练难度,可以理解成以下样子:
|
|
同样的,为方便标签的识别,我们可以进行
把标签转独热编码
何为独热编码?
独热编码即 One-Hot 编码,又称一位有效编码,其方法是使用N位状态寄存器来对N个状态进行编码,每个状态都由他独立的寄存器位,并且在任意时候,其中只有一位有效。
|
我们在这里拿MNist数据集举例,0-9有十位数字,所以独热编码位有10位,我们就可以把1独热为
|
把3独热为
|
这样看,就清晰了很多
构建Dataset对象和模型的过程中
我们需要用repeat和batch分别对训练集和测试集配置训练周期和批次大小(一次训练多少个数据)
这里我们要有一个认知,我们在拥有测试集的时候,我们后续要用测试集进行验证,我们就得对测试集做与训练集配置相同的操作,这样可以计算统计出最终的准确率,当然如果你连测试集都没有,那就无需多言
构建模型的时候,我们这里采用keras自带的模型
|
因为我们输入的每张图片的numpy值为28*28像素,所以前面的归一化操作出来的数据也是28*28,所以输入的神经元个数即:input_shape=(28,28),通过Flatten进行数据扁平化成784个数值
之后我们定义其为输出位10个神经元的全连接层
关于优化器
什么是优化器?
在机器学习中,有很多优化方法来试图寻找模型的最优解。比如神经网络中可以采取最基本的梯度下降法。
梯度下降法是最基本的一类优化器,目前主要分为三种梯度下降法:标准梯度下降法(GD, Gradient Descent),随机梯度下降法(SGD, Stochastic Gradient Descent)及批量梯度下降法(BGD, Batch Gradient Descent)。
在这里我们采用随机梯度下降法,关于这一个知识点,后续可能会出一个专门解读,或者大家可以去百度一下,先进行自我学习。
以下是几种梯度下降法寻找最低值的立体三维解析:
后续博文会慢慢解释,大家先看着了解一二,或者百度学习更深的算法,咱们一起探讨学习。
训练模型
|
|
以上是两个函数的定义,重点要注意的是我们这里采用均方差损失函数(即二次代价函数)来计算误差,从而进一步调整权值,计算训练过程中的模型准确率
除了二次代价函数外,还有交叉熵损失函数,大家有兴趣后续可以使用交叉熵的方式,来计算误差,而后对比结果关系。
我个人用的环境是vscode+anaconda(配置python3.6—64)
我的运行结果如下: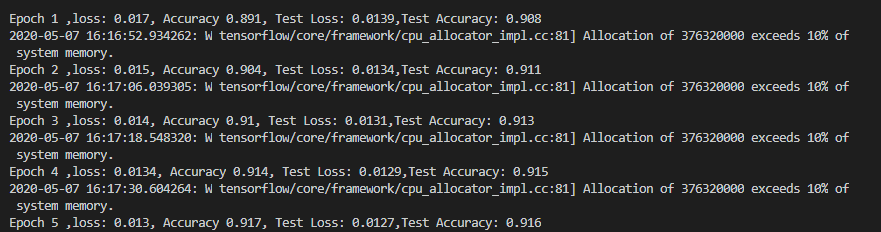
可以看到
1.由于我使用的CPU版本的TensorFlow来训练,所以训练速度相对比较久,所以有条件有显卡的童鞋,建议使用GPU版本,速度不是提升一点点
2.在训练过程中,训练集的准确率和测试集的准确率都有提高的趋势,这都归功于我们前面配置的优化器,以及每个训练过程中权值调整,我推荐大家去修改这些值,或者屏蔽这些值,来进一步了解这些带来的变化。
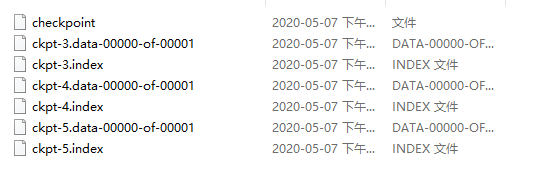
模型的保存
模型的保存有很多种方式,我们这里采用Checkpoint的方式,保存最优三个模型:
|
之后在每个训练周期进行save()模型保存即可
模型的载入:
|
写一个demo
写一个demo来试试结果
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 |
import tensorflow as tf
from tensorflow.keras.optimizers import SGD
from tensorflow import keras
# 载入数据集
mnist = keras.datasets.mnist
# 训练集和测试集
(x_train,y_train),(x_test,y_test) = mnist.load_data()
# 归一化操作
x_train,x_test = x_train / 255.0,x_test / 255.0
print(x_train.shape,x_test.shape)
# 把标签转成独热编码
y_train = tf.keras.utils.to_categorical(y_train,num_classes=10)
y_test = tf.keras.utils.to_categorical(y_test,num_classes=10)
# 创建dataset对象
mnist_train = tf.data.Dataset.from_tensor_slices((x_train,y_train))
# 训练周期
mnist_train = mnist_train.repeat(1)
# 批次大小 一次32个数据
mnist_train = mnist_train.batch(32)
# 创建detaset对象
mnist_test = tf.data.Dataset.from_tensor_slices((x_test,y_test))
# 训练周期
mnist_test = mnist_test.repeat(1)
# 批次大小
mnist_test = mnist_test.batch(32)
# 构建模型
model = keras.models.Sequential([
keras.layers.Flatten(input_shape=(28,28)), # 数据扁平化 784 个数值
keras.layers.Dense(10,activation='softmax') # 激活函数为softmax输出为10个神经元的全连接
])
# 优化器定义
optimizer = tf.keras.optimizers.SGD(0.1)
# 训练loss
train_loss = tf.keras.metrics.Mean(name='train_loss')
# 训练准确率计算
train_accuracy = tf.keras.metrics.CategoricalAccuracy(name='train_accuracy')
# 测试loss
test_loss = tf.keras.metrics.Mean(name="test_loss")
# 测试准确率计算
test_accuracy = tf.keras.metrics.CategoricalAccuracy(name="test_accuracy")
# 训练模型
def train_step(data,label):
with tf.GradientTape() as tape:
# 传入数据预测结果
predictions = model(data)
# 计算loss
loss = tf.keras.losses.MSE(label,predictions) # 二次代价函数
# 计算权值调整
gradients = tape.gradient(loss,model.trainable_variables)
# 进行权值调整
optimizer.apply_gradients(zip(gradients,model.trainable_variables))
# 计算平均loss
train_loss(loss)
# 计算平均准确率
train_accuracy(label,predictions)
# 模型测试
def test_step(data,label):
# 传入数据预测结果
predictions = model(data)
# 计算loss
t_loss = tf.keras.losses.MSE(label,predictions)
# 计算平均loss
test_loss(t_loss)
# 计算平均准确率
test_accuracy(label,predictions)
# 定义模型保存
ckpt = tf.train.Checkpoint(step=tf.Variable(1), # 训练的次数从1开始
optimizer=optimizer,model=model)
manager = tf.train.CheckpointManager(ckpt,'tf2_ckpts',max_to_keep=3) # 文件夹中最多保存3个模型
EPOCHS = 5
# 训练5个周期
for epoch in range(EPOCHS):
# 循环60000/32 = 1875次 一共有60000个数据,一次取32个数据
for image,label in mnist_train:
# 训练模型
train_step(image,label)
# 循环10000/32 = 312.5 ———> 313次
for test_image,test_label in mnist_test:
# 测试模式
test_step(test_image,test_label)
# 打印结果
template = 'Epoch {} ,loss: {:.3}, Accuracy {:.3}, Test Loss: {:.3},Test Accuracy: {:.3}'
print(template.format(epoch + 1,
train_loss.result(),
train_accuracy.result(),
test_loss.result(),
test_accuracy.result()))
# 保存模型
manager.save()
# 模型载入
ckpt = tf.train.Checkpoint(step=tf.Variable(1),optimizer=optimizer,model=model)
ckpt.retore(tf.train.latest_checkpoint('tf2_ckpts/')) # 在文件夹中取出最新的模型 |
我也在学习阶段,这一篇是我近期学习所得,也只能说自己接触了这一块的深度学习的hello world了吧,后续继续学习更多的东西,和大家多做学习交流探讨。最后
我的原微博地址:http://halfofpoetry.github.io/2020/05/07/%E5%9F%BA%E4%BA%8EMNist%E6%95%B0%E6%8D%AE%E9%9B%86%E8%BF%9B%E8%A1%8CDeepLearning%E5%AD%A6%E4%B9%A0/