前后端分离的webgis项目
前后端分离的webgis项目(一)
简单说明:后端django+python开发,apache+wsgi+python部署,前端vue+leaflet。项目主要展示全国5A景区的分布信息,数据从去哪儿网站爬取存MySQL数据库,爬取的数据不太全,由于是个人练手项目没有做进一步处理。后端开发工具pycharm, 前端开发工具webstorm
一. 后端django+python开发,apache+wsgi+python部署
开发环境的搭建这里就不细细说明了,python和pycharm的安装网上教程很多,这里就不作描述了。
- django+python开发
版本说明:python版本3.7.0 django版本2.0
首先打开pycharm,点击File>New Project,然后选择Pure Python,不要选Django新建工程,这样会自动安装最新版的django,后面就不好选择django版本了

然后在pycharm工具左下的Terminal里新建project和app以及安装django等(以下的命令操作都在Terminal)
使用下面的命令新建工程
django-admin.py startproject myproject
然后打开刚才的工程如下所示

使用下面的命令新建应用
python manage.py startapp prjApp
安装指定版本django
pip install django==2.0
初始化sqlite数据库
python manage.py makemigrations
python manage.py migrate
本项目使用mysql数据库,需要安装依赖包配置mysql数据库连接,首先在工程名下面的_init_.py下面添加
import pymysql
pymysql.install_as_MySQLdb()
然后使用下面命令安装mysql依赖包
pip install PyMySQL
在工程名下面的settings.py配置mysql数据库,位置在DATABASES配置如下

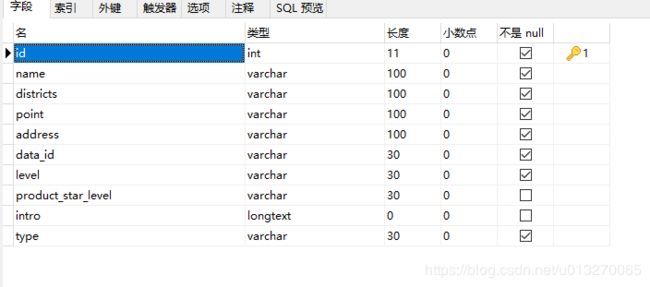
在应用名下面的model.py里创建类,用以接受爬取的数据

使用一下命令将model里创建的类作用到数据库生成表
python manage.py makemigrations
python manage.py migrate
在应用名下面新建xxx.py文件用于爬取数据,爬虫参考的这位老哥,我自己修改了一下,只爬取5A景区并加入了景区图片,爬取速度不快,不同的景区类型只取了部分数据,有的景区包含多个类别。代码如下
# -*- coding: utf-8 -*-
import requests
from bs4 import BeautifulSoup
import random
from time import sleep
import urllib.request
import pymysql
a = 0
# 设置保存图片的路径,否则会保存到程序当前路径
path = r'D:\WatchFileTest\images' # 路径前的r是保持字符串原始值的意思,就是说不对其中的符号进行转义
User_Agent = [
"Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/51.0.2704.106 Safari/537.36",
"Mozilla/5.0 (Macintosh; U; Intel Mac OS X 10_6_8; en-us) AppleWebKit/534.50 (KHTML, like Gecko) Version/5.1 Safari/534.50",
"Mozilla/5.0 (Windows; U; Windows NT 6.1; en-us) AppleWebKit/534.50 (KHTML, like Gecko) Version/5.1 Safari/534.50",
"Mozilla/5.0 (Macintosh; Intel Mac OS X 10.6; rv:2.0.1) Gecko/20100101 Firefox/4.0.1",
"Mozilla/5.0 (Windows NT 6.1; rv:2.0.1) Gecko/20100101 Firefox/4.0.1"]
HEADERS = {
'User-Agent': User_Agent[random.randint(0, 4)],
# 'User-Agent':'Mozilla/5.0 (Windows NT 6.1; WOW64; rv:55.0) Gecko/201002201 Firefox/55.0',
'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8',
'Accept-Language': 'zh-CN,zh;q=0.8,en-US;q=0.5,en;q=0.3',
'Accept-Encoding': 'gzip, deflate, br',
'Cookie': '',
'Connection': 'keep-alive',
'Pragma': 'no-cache',
'Cache-Control': 'no-cache'
}
def download_page(url): # 下载页面
try:
data = requests.get(url, headers=HEADERS, allow_redirects=True).content # 请求页面,获取要爬取的页面内容
return data
except:
pass
# 下载页面 如果没法下载就 等待1秒 再下载
def download_soup_waitting(url):
try:
response = requests.get(url, headers=HEADERS, allow_redirects=False, timeout=5)
if response.status_code == 200:
html = response.content
html = html.decode("utf-8")
soup = BeautifulSoup(html, "html.parser")
return soup
else:
sleep(1)
print("等待ing")
return download_soup_waitting(url)
except:
return ""
def getTypes():
types = ["故居", "宗教", "文化古迹", "自然风光", "公园", "古建筑", "寺庙", "遗址", "古镇", "陵墓陵园"] # 实际不止这些分组 需要自己补充
for type in types:
url = "http://piao.qunar.com/ticket/list.htm?keyword=%E7%83%AD%E9%97%A8%E6%99%AF%E7%82%B9®ion=&from=mpl_search_suggest&subject=" + type + "&page=1"
getType(type, url)
def getType(type, url):
db = pymysql.connect(host='localhost', user='root', passwd='root', db='test') # 连接数据库(地址,用户名,密码,数据库名)
cur = db.cursor() # 取游标
global a
soup = download_soup_waitting(url)
search_list = soup.find('div', attrs={'id': 'search-list'})
sight_items = search_list.findAll('div', attrs={'class': 'sight_item'})
for sight_item in sight_items:
a5spot = '5A'
level = sight_item.find('span', attrs={'class': 'level'})
if level:
if a5spot in level.text: # 判断是否5A景区
name = sight_item['data-sight-name']
districts = sight_item['data-districts']
point = sight_item['data-point']
address = sight_item['data-address']
data_id = sight_item['data-id']
level = sight_item.find('span', attrs={'class': 'level'})
if level:
level = level.text
else:
level = ""
product_star_level = sight_item.find('span', attrs={'class': 'product_star_level'})
if product_star_level:
product_star_level = product_star_level.text
else:
product_star_level = ""
intro = sight_item.find('div', attrs={'class': 'intro'})
if intro:
intro = intro['title']
else:
intro = ""
link = sight_item['data-sight-img-u-r-l']
# 保存图片,以data_id命名防止冲突
urllib.request.urlretrieve(link, path + '\%s.jpg' % data_id) # 使用request.urlretrieve直接将所有远程链接数据下载到本地
print(name, districts, point, address, data_id, level, product_star_level, intro, type, link)
# 插入数据到mysql
sql = "insert into webmap_spot(name, districts, point, address, data_id, level, product_star_level, " \
"intro, type) VALUES ('%s','%s','%s','%s','%s','%s','%s','%s','%s') "
cur.execute(sql % (name, districts, point, address, data_id, level, product_star_level, intro, type))
db.commit() # 执行commit操作,插入语句才能生效
print('成功插入', cur.rowcount, '条数据')
a = a + 1
print(a)
cur.close()
db.close()
next = soup.find('a', attrs={'class': 'next'})
if next:
next_url = "http://piao.qunar.com" + next['href']
getType(type, next_url)
if __name__ == '__main__':
getTypes()
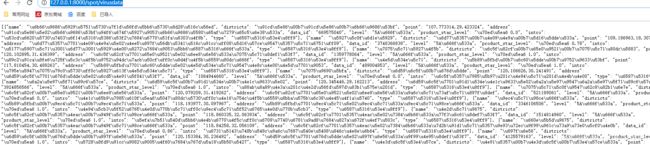
部分数据结果

在应用名下的views.py编写获取数据的方法
from django.shortcuts import render
from django.http import HttpResponse
from django.core import serializers
from .models import Spot
import json
def get_spot_data(request):
if request.method == 'GET':
allData = Spot.objects.all()
allData = allData.values('name', 'districts', 'point', 'address', 'data_id', 'level', 'product_star_level', 'intro', 'type').distinct() # 去除data_id重复的
print(json.dumps(list(allData))) # 使用values进行调用返回的是valueQuerySet字段,而浊QuerySet,所以先转成list然后再使用json.dumps转成json
return HttpResponse(json.dumps(list(allData)), content_type="application/json")
在应用名下的urls.py编写跳转到views,urls相当于路由
from django.contrib import admin
from django.urls import path
#从应用名引入views
from proApp import views
urlpatterns = [
path('', admin.site.urls),
path('spot/virusdata', views.get_spot_data) # views调用刚刚写的方法
]
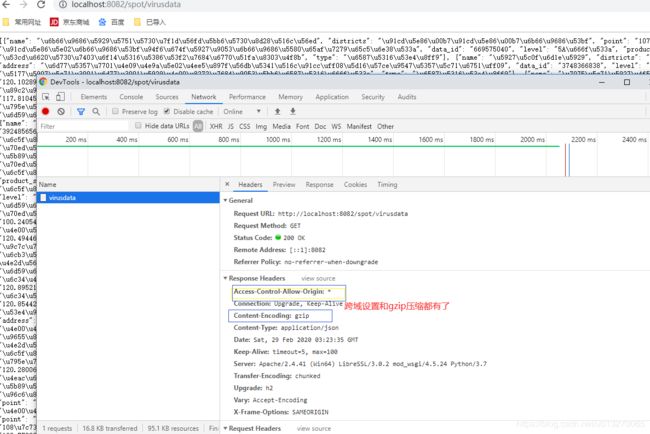
启动项目,在浏览器输入http://127.0.0.1:8000/spot/virusdata,spot/virusdata是刚刚定义的路径,获得json对象结果
- apache+wsgi+python部署
版本说明:Apache2.4.41
参考的这位老哥,很详细我就不写了,注意的是原来的项目依赖包在虚拟环境里,所以部署环境里也要安装。不过我采用的多端口部署,此外,还映射了爬取图片的文件夹位置,为了后面前端读取图片方便,在原来部署的基础上
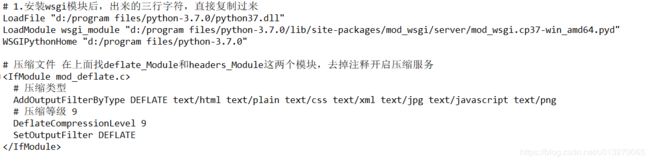
找到httpd-vhosts模块,去掉注释开启服务,同时httpd.conf文件上面添加端口监听

然后打开conf/extra/httpd-vhosts.conf文件,添加对每个项目的参数设置
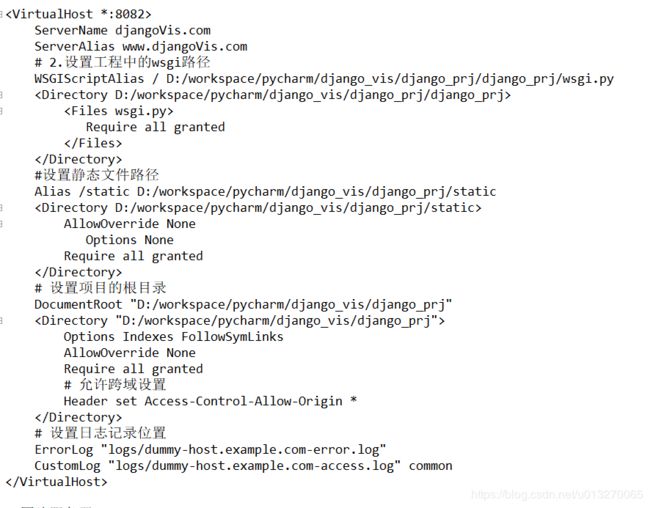
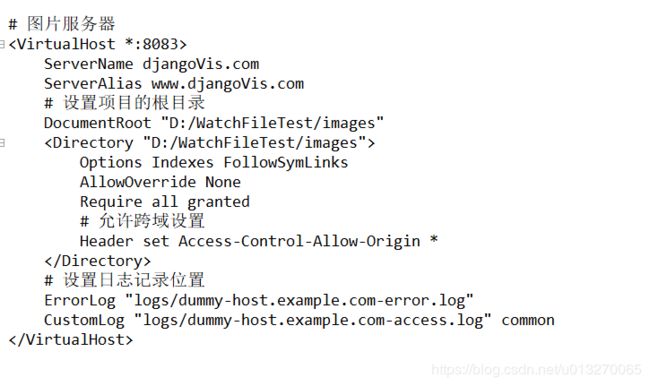
最后修改项目的wsgi.py文件,图片服务不用,添加以下代码
root_path = os.path.abspath(os.path.join(os.path.dirname(__file__), '..'))
sys.path.insert(0, root_path)
注意一定要放在前面,不然没用,如下图

至此,重启apache服务,在浏览器输入http://localhost:8082/spot/virusdata就可以看到数据了,输入http://localhost:8083/37368675.jpg查看图片