浅析聚集索引
“聚集索引决定了数据的物理顺序”—这是大家都知道的一句话,但是这句话到底是啥意思呢?这里好好说一说。
有一个例子非常形象:
聚集索引:一个汉语字典,我们希望查找“张”,我们可以直接翻到字典的最后,找到zh开头,然后找到张。因为字典内容本身是按照拼音排版的,所以字典内容本身就是一个聚集索引。
非聚集索引:在查找一个不认识的字的时候,我们可以先通过字典的偏旁部首目录,找到字在哪一页,然后通过页码找到“张”。因为字典不是根据偏旁部首排版的,所以需要通过两步才能真正找到。
聚集索引与非聚集索引的区别:
1. 聚集索引底层B+树的叶子节点是数据本身。非聚集索引底层B+树的叶子节点是指向数据的地址(有时是存的聚集索引的值,不同的实现不一样)。--这个很好理解:聚集索引决定了数据的物理顺序,所以可以叶子节点是数据本身,而非聚集索引不可以。如下图。
2. 由于聚集索引决定了物理顺序,所以一张表只会有一个。而非聚集索引可以有多个。

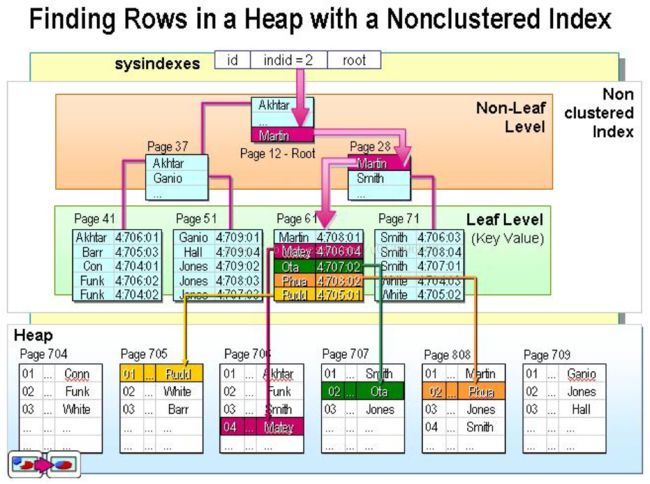
聚集索引的好处是啥?
除了上面说的减少一次寻址过程之外,还有一个好处:
如果我们指定一列xxx(或多列)聚集索引,则如果遇到这种语句select* from table where xxx>’2017’ and xxx<’2018’,则我们就可以直接定位xxx=2017和xxx=2018两行的位置,然后中间的就是结果。如果不是聚集索引,则就会遍历整张表的所有行。
聚集索引的误区
主键就是聚集索引。这种理解是错误的,不同的数据库的实现方式不同,有的数据库MySQL(InnoDB)默认是把主键设为聚集索引,但是这并非一定。且把主键设为聚集索引并不是一个好的做法,因为很少会对主键ID做大于小于这种区间操作,所以将主键设为聚集索引其实是一种浪费。
MySQL的聚集索引
我们知道InnoDB和MyISAM的一个很大的区别就是,InnoDB的组织形式就是聚集索引,而MyISAM不是。
即InnoDB必须有一个聚集索引。而MyISAM没有聚集索引。
MySQL可以主动创建聚集索引吗?
不可以。
MySQL是如何决定一张表的聚集索引是啥的?
引用一段话:
Every InnoDB table hasa special index called the clustered index where the data for the rows isstored. Typically, the clustered index is synonymous with the primary key.
...
· When you define a PRIMARY KEY on your table, InnoDB uses it as the clustered index. Define a primary key for each table that you create.If there is no logical unique and non-null column or set of columns, add a newauto-increment column, whose values are filled in automatically.
· If you do not define a PRIMARY KEY for your table, MySQL locates the first UNIQUEindex where all the key columns are NOT NULL and InnoDB uses it as the clustered index.
· If the table has no PRIMARY KEY or suitable UNIQUE index, InnoDB internally generates a hidden clustered indexon a synthetic column containing row ID values.The rows are ordered by the ID that InnoDB assigns to therows in such a table. The row ID is a 6-byte field that increases monotonicallyas new rows are inserted. Thus, the rows ordered by the row ID are physicallyin insertion order.
很好理解,大致意思就是如果有主键,则主键就是。如果没有,则找到第一个唯一键且NOT NULL的索引。如果还是没有,则生成一个隐藏的索引当做聚集索引。
InnoDB索引和MyISAM索引的区别:
InnoDB聚集索引:

很显然,叶子节点存的就是数据本身。
InnoDB辅助索引:
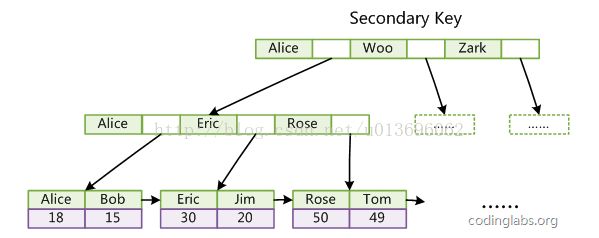
辅助索引基本上可以叫做非聚集索引。注意是基本上,因为还有其他外键索引等。我们先这么叫,以便更好理解。
即通过索引找到聚集索引值,然后再通过聚集索引值,找到真正的数据。
即需要进行两次遍历B+树。
MyISAM聚集索引和非聚集索引都是实现都是一样的:
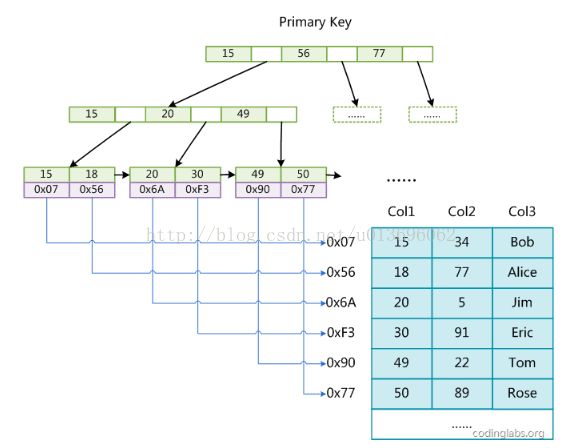
即B+树的叶子节点是数据的地址,找到地址后再去寻址找到真正的数据,