SVM算法
不准备很详细的或者很有条理的谈论SVM,因为如果要详细的讨论,内容太多了。且按照我的感受来谈谈,浅显的说说。
前面谈到的有Logistics回归,感知机没有介绍,其实感知机是最原始最基础的机器学习算法,对它的理解有助于理解其它的算法,包括神经网络、深度学习。扯远了。。。 Logistics回归、感知机、SVM都是使用分离超平面来对数据的特征空间进行划分来进行分类,我的理解是Logistic和SVM都是在感知机的基础上进行的改进。怎样个改进法呢?
感知机寻求的是一个能够将数据集分割开的超平面,在二维平面上就是寻找一条直线能够将数据集划分成两部分。但是,这条直线的选取会有多种,多不是1、2、3,而是无数条,可能有些夸张,不过确实是这样,只不过取值范围加了限制而已。这么多条选择,理论上存在一条最优的,那么肯定其它的都是在这条线上的偏移产生的。虽然这条线成果的分离了数据集,但是,是不是就代表已经真的充分的利用了数据集所包含的信息呢?当然不是,不然也不会有Logistic和SVM这些折腾的算法,因为有改善提升空间,所以出现了Logistics和SVM算法。为了解释这个提升空间,举个例子吧:老虎不发威,你当我是病猫呀,老虎和猫其实是很像的,可能它们小时候是差不多的,但是当你看到一只成年虎,你敢说这还是猫吗?它的体型已经明显可以判断它不是猫而是老虎,因为猫不可能长得有成年虎那么大。对应到分类器上,就是离分离超平面远且已经正确分类的点,其实它的重要性已经不那么高了,或者说相对于距离近的点重要性要低,因为微调分类超平面对这些点的分类已经不会产生影响。而此时,应该更加关注的是距离近的点,因为分类超平面可能稍有偏误,那么这些点分类结果就会发生反转,影响非常大。也就说,距离远的点它们的分类可信度较高,距离近的点分类可信度较高。那么显然,就会有一种想法,让这条线或者分类超平面距离所有的点都尽可能的远。
Logistics和SVM正是基于此的两种方法,Logistics回归的方法是,对每个点到超平面的距离计算一个代价,在正确分类的求情况下,这个距离越大,代价越小,距离越小,代价越高,分类错误的代价极大,这和前面的思想很符合,对这个代价函数求最优化就是Logistics的损失函数最优化过程。SVM的做法是,在所有已经正确分类的点中,找到距离分类超平面最近点,这些点有个特别的名字“支持向量”(个人理解的是,它们决定了最终的分类超平面,所以是支持,而这些空间点,其实可以理解为从原点发出的空间向量,所以叫做支持向量),然后优化使分类超平面距离这些点尽可能的远。前面谈Logistics时候也说过,SVM通常性能是比Logistics回归的,因为所给的数据分布和原始数据的分布不能保证完全一致,还有正负样本的数据,不可能保持你一个我一个,而且还是你一个距离为l的点我也一个距离l的点,只有这种对称分布才不会影响最中的分类超平面,Logistics这种考虑来自全部样本点的策略,必然会受到很强的样本数据的分布的影响,偏离真正的决策平面。SVM选取最近的点,将这个相对于感知机微调过程的参考范围缩小,这个缩小过程很大程度减少了样本分布或者正负比例分布对最终的分类间隔的影响。
上面就是关于和SVM的一些思想。下面来推导一下SVM的求解过程:
设分类超平面的法向量为w,截距为b,分类超平面可以表示为:y=wx+b,按照书上的,会介绍一个函数间隔,也就是
![]()
其中,这个值对于同一模型的不同点之前可以进行距离比较,比如哪个点距离分离超平面更近,但是对模型会一直修正,这过程模型是变化的,如果使用这个来比较哪个模型更好,那显然是不行的。因此真正用到的是集合距离,把点、分类超平面映射到特征空间中,这个点到特征空间的几何距离。要了解上面是几何间隔,先介绍距离,点到分隔面的距离为:

上面这个式子可以通过几何只是推导出来,点距离分类超平面的距离为点以原点为起点的向量在分离超平面的法向量上的投影长度。两个向量的夹角余弦值为:

而这个投影即为:

未了统一正类负类分类错误和正确的情况,乘上对应的点类别,这样分类正确符号即为正,分类错误符号即为负。得到的就是几何间隔,式子如下:
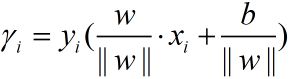
现在知道了每个点到超平面的距离,那么现在要走的就是在这里面找到距离超平面最近的点,使得所有的点的几何间隔都大于或者等于这个最小间隔:
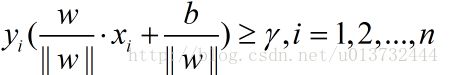
那么需要优化的问题即为:

但是,会发现,其实这个问题并不好求w和b,优化的是个最大值,而这个最大值并没有一个明确的表达式,所以对其进行转换等价形式:
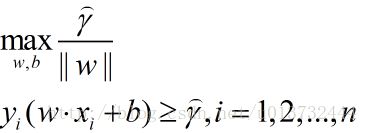
这个是使用函数距离和法向量来表示几何距离,这就是为什么要引入这个函数距离。通过对几何距离公式观察可以发现,同一个函数间隔可以对应到不同超平面,即这个函数间隔和超平面的位置是没有关系的。既然这样,为了化简问题,直接取这个函数间隔为1,那么这个向量的范数在分母位置,对这个求最大,等价于向量L2范数在分子位置上求极小,同时,为了后期化简的需要,乘一个1/2,得到下面的式子:
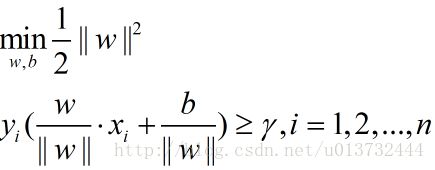
问题一下子就明朗了,通过对这个进行优化就行了。同时,也明白了函数间隔的用处,起到了很关键的作用(这个函数间隔一名,可能是为了解释这个中间过程参考几何间隔取的,仔细想想挺合理的 哈哈哈)。接下来,构建拉格朗日不等式,如下:
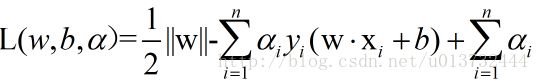
使用上式分别对w和b求导,使用a和样本点来表示w,b,可以得到如下:

代入原式就可以得到最终需要优化的式子:

对上面求最优化,得到ai,然后使用ai求得w,选取一个ai不为0的点,用这个点求得b值,则可得到最后的决策函数。

这些式子看着很难,其实了解了思路,动手推一推其实也不难。这是参考的《统计学习方法》,按理说,这是线性可分的情况,后面还有线性不可分的情况,只不过在原来的基础上修改了一下。而核函数的添加则是把xi点乘xj换成了一个核函数,输入为两个样本向量,在低维进行运算,在高维空间进行分类。还有重要的序列最小最优化求解方法,巧妙之处在于,将大问题化成小问题,每次选两个样本对应的a值进行优化,这样看上去会计算很多次,每次两个是不是太慢了? 不过这两个的计算是可以用解析式求解,即有一个对应的等式求解,这样就会大大加快速度。
SVM算法是一个直接使用就会得到比较好的效果的算法,但是SVM为了达到最优性能,需要太多的参数需要调。SVM的效果受核函数的影响非常大,而核函数的种类非常多,不同领域会用到不同的核函数,实际中只能凭借经验选取核函数,或者调试选择最优的核函数,没有一个固定的模式。