【AI视野·今日CV 计算机视觉论文速览 第172期】Tue, 10 Dec 2019
AI视野·今日CS.CV 计算机视觉论文速览
Tue, 10 Dec 2019
Totally 77 papers
上期速览✈更多精彩请移步主页

Interesting:
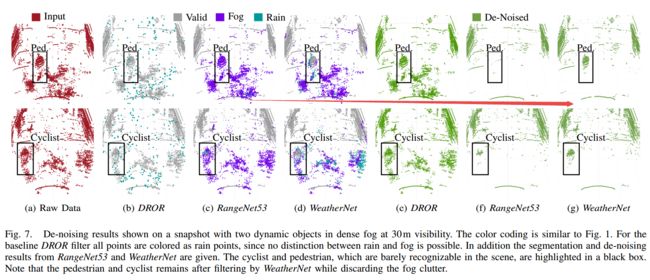
***WeatherNet用于恶劣天气点云去噪的网络模型, (from 奔驰 KIT 德国)
基于[31]的LiLaBlock模块,通过扩张卷积来放大:
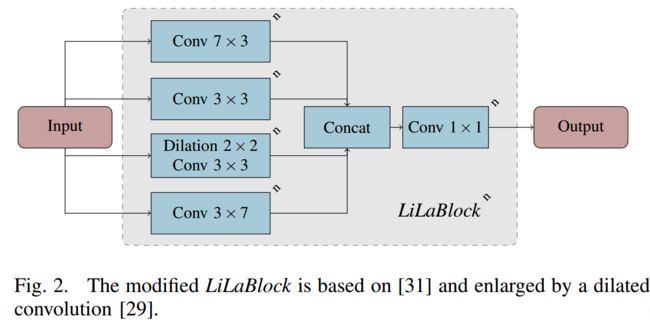
模型的网络结构:

去噪结果,大幅降低了雨雾的干扰:
code:https://github.com/rheinzler/PointCloudDeNoising
datset31:Boosting LIDAR-based ¨ semantic labeling by cross-modal training data generation,CEREMA,dataset
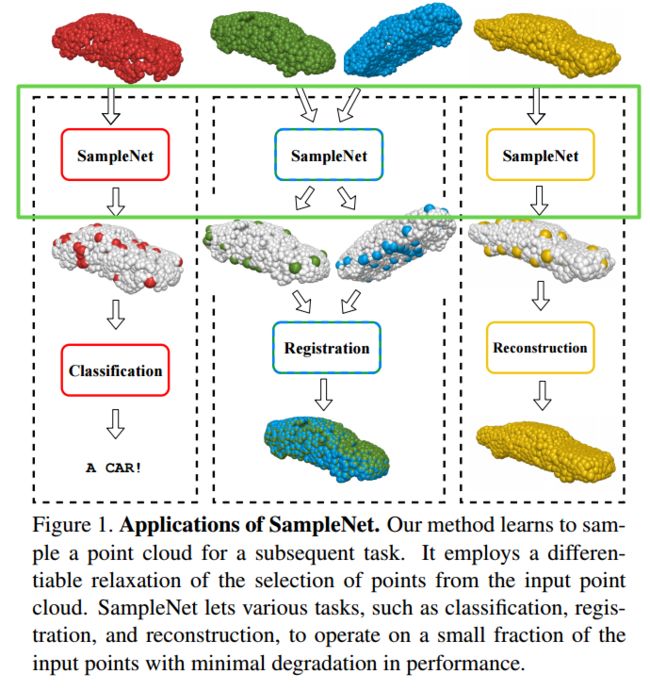
***SampleNet可差分的点云采样方法,提出了一种可差分的方法来简化点云,根据下游任务来对点云抽取方法进行训练,利用软投影操作来从原始点云中抽取,通过温度参数和正则项来控制近似 (from Tel-Aviv University)
基于可差分网络的采样方法samplenet:
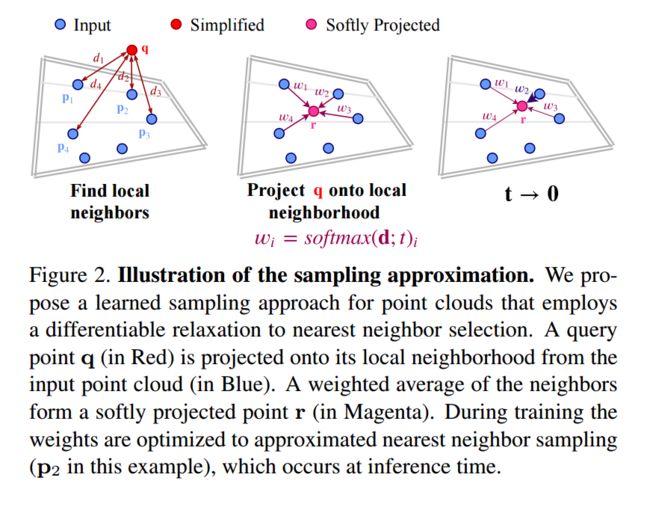
采样网络的近似过程和软投影操作:
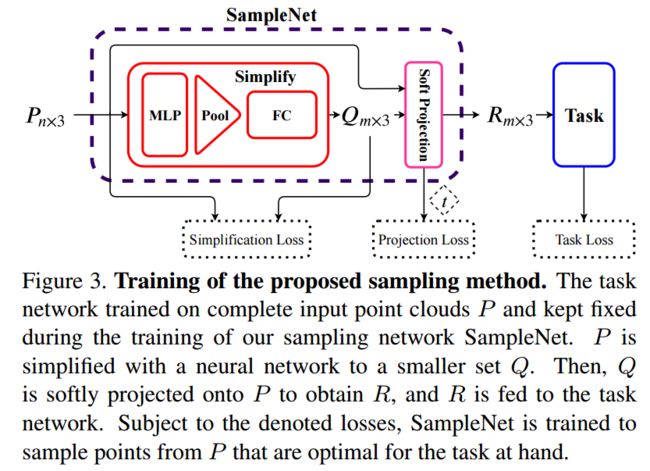
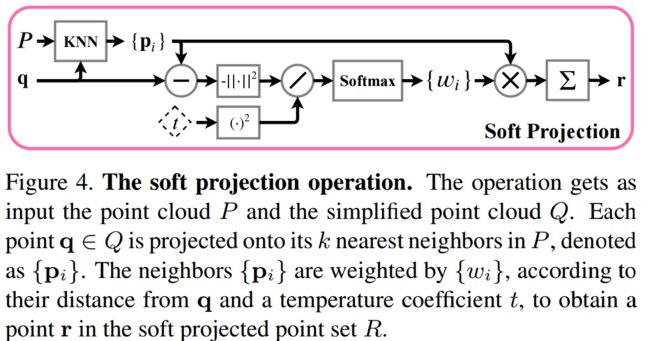
code:https://github.com/itailang/SampleNet
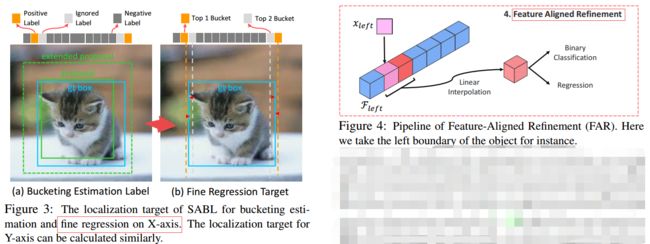
****SABL能意识到边缘的目标检测方法, 提出了一种通过定位bbox的四边与边缘距离的方法来进行目标检测。(from 香港中文 南洋理工 浙大 中科大 商汤)
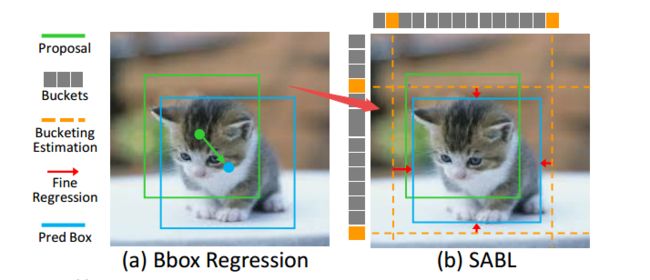
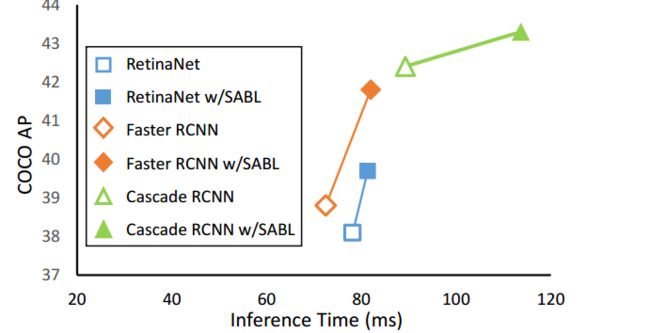
基于边缘的边界预测定位方法:
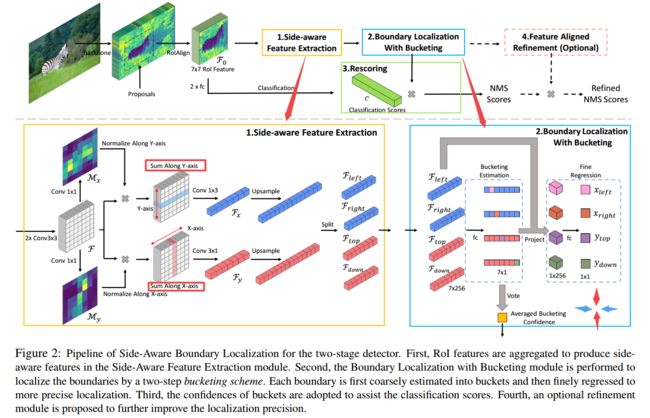
粗定位和和特征匹配优化:
code:https://github.com/open-mmlab/mmdetection
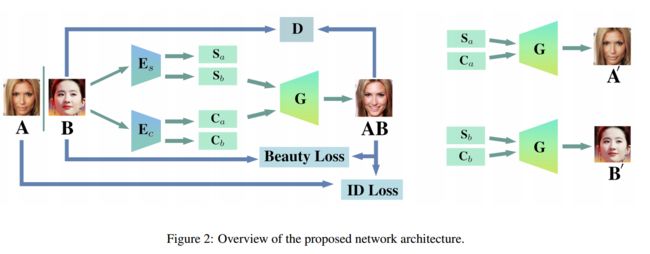
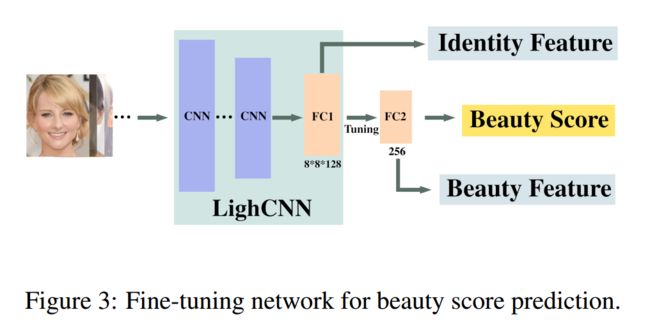
***Face Beautification人脸美化方法, 将目标参考人脸的妆容迁移到输入人脸上进行化妆美颜(from Oben, Inc 西弗吉尼亚大学)
网络迁移架构和精调网络:
ICDAR2019总结及数据集, (from ICDAR)

dataset:https://doi.org/10.5281/zenodo.3262372
1https://bvmm.irht.cnrs.fr/includes/php/rotation.php?vueId=1672647&niveauZoom=grand
2http://monasterium.net/mom/AT-HHStA/LindauCan/AUR 839 IV 21/charter
3https://nbn-resolving.org/urn:nbn:de:bvb:29-bv043513635-8
4http://doi.org/10.7891/e-manuscripta-18277
5https://bvmm.irht.cnrs.fr/
6https://gallica.bnf.fr
7http://digital.bib-bvb.de/R/5AL3NBRJYJV14LG6YC7RDNG4VHURY7SGHC4KASKKMDAH1LATRS-00090?func=collections-result&collection id=2397
8https://www.unibas.ch
9https://www.monasterium.net/mom/home
10https://www.bodleian.ox.ac.uk/
11https://bvmm.irht.cnrs.fr/
12Paris, Beaune, Angers, Metz, Auxerre, Versailles, Arras, Fecamp, Douai,etc.
13http://cudl.lib.cam.ac.uk/
14https://www.e-codices.unifr.ch
15https://gallica.bnf.fr
16Besanc¸on, Bourges, Angers, Rouen, Louviers
17https://library.harvard.edu/
18http://library.stanford.edu/
19https://www.monasterium.net/mom/home
20https://github.com/anguelos/wi19 evaluate/tree/master/srslbp
21https://github.com/masyagin1998/robin
Bundle Adjustment Revisited, 对于BA方法的回顾的改进,包括提高效率的分布式计算方法。(from 北大 图形交互实验室)
SolarNet,检测卫星图像中的太阳能电池板 (from 微众银行)
太阳能发电厂检测以及全国太阳能电场分布:

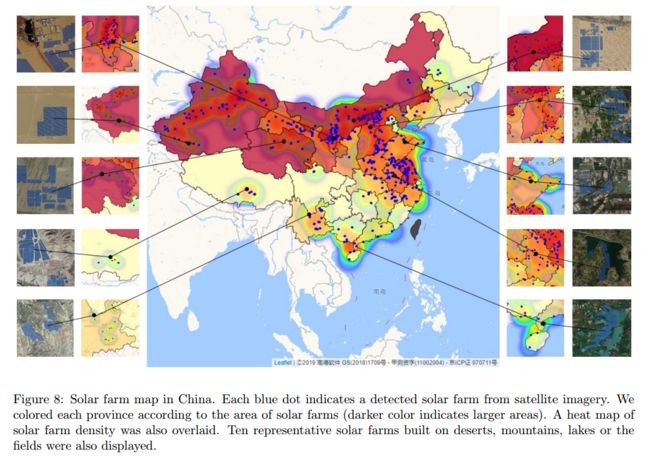
datset:our dataset deepsolar dataset our+deepsolar dataset
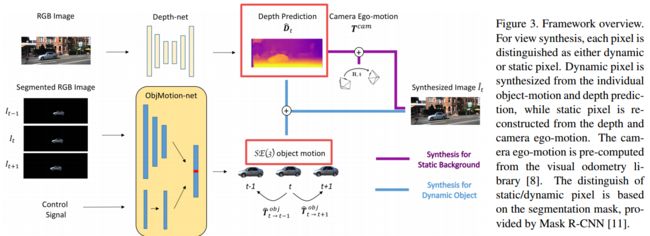
从视频中估计运动和深度的自监督方法, (from ETH Zurich)
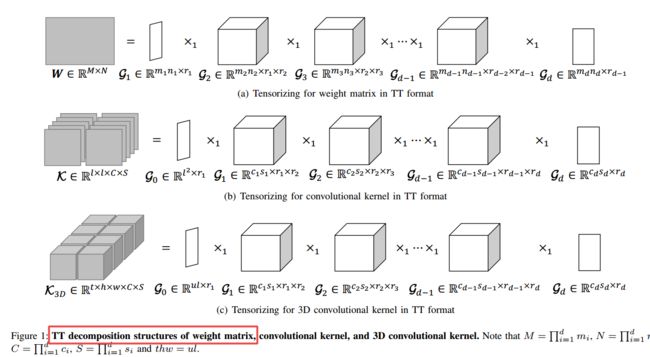
基于张量训练解耦的3DCNN的模型压缩方法, (from 西安交大 )
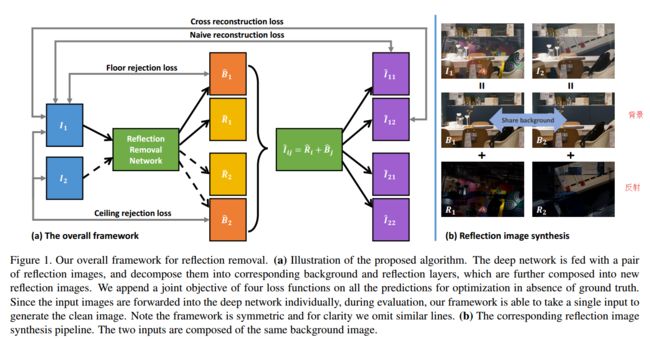
**Deep Reflection Prior, 基于反射的统计先验来进行图像中的反射去除。(from 斯坦福)
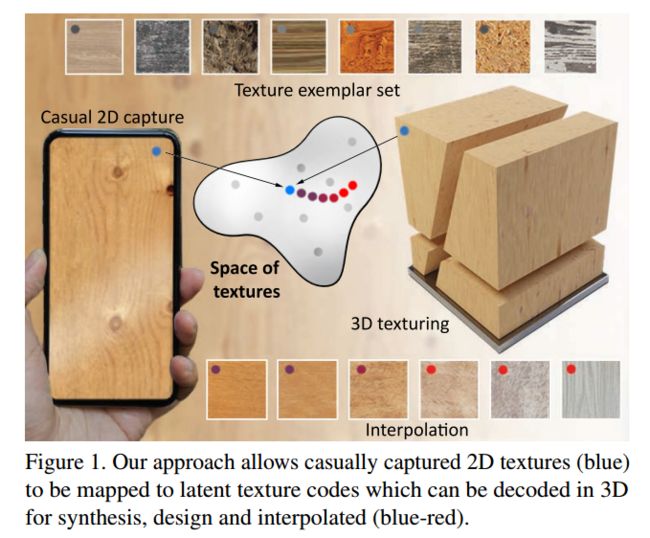
从二维图像抽取三维纹理,利用生成模型从二维图像种抽取出纹理编码,并在三维形状中解码、合成与插值。 (from 伦敦大学学院 adobe)
Project website: geometry.cs.ucl.ac.uk/projects/2019/neuraltexture
FaultNet, 检测铁路上的各种阀门(from A*STAR, Singapore)

dataset:Singapore Mass Rapid Transit (SMRT) dataset
检测X光安检机中的危险品, (from Center for Cyber-Physical Systems (C2PS))

dataset:GDXray dataset
相机参数对网络泛化性影响, (from 斯坦福)
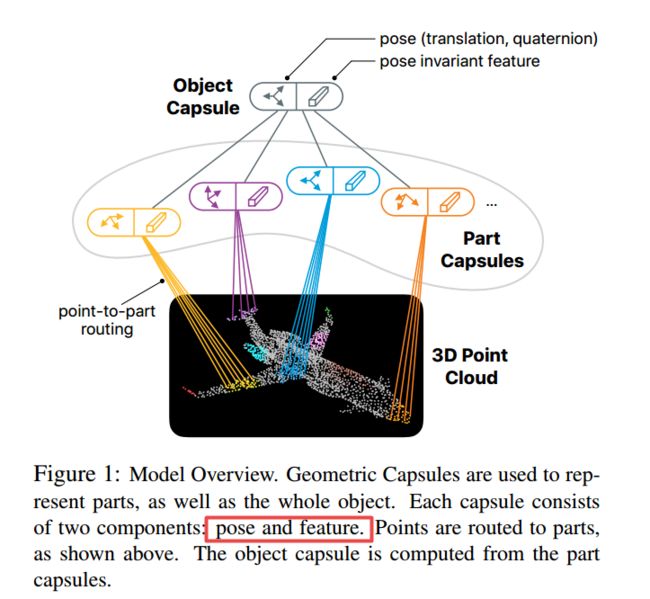
用于点云表示的胶囊网络,(from apple)
Daily Computer Vision Papers
| Side-Aware Boundary Localization for More Precise Object Detection Authors Jiaqi Wang, Wenwei Zhang, Yuhang Cao, Kai Chen, Jiangmiao Pang, Tao Gong, Jianping Shi, Chen Change Loy, Dahua Lin 当前的对象检测框架主要依靠边界框回归来定位对象。尽管近年来取得了长足的进步,但包围盒回归的精度仍然不能令人满意,因此限制了对象检测的性能。我们观察到精确定位需要仔细放置边界框的每一侧。但是,专注于预测中心和大小的主流方法并不是完成此任务的最有效方法,尤其是当锚点和锚杆之间存在较大差异的位移时。 |
| An Empirical Study on Position of the Batch Normalization Layer in Convolutional Neural Networks Authors Moein Hasani, Hassan Khotanlou 在本文中,我们研究了如何通过更改批归一化BN层的位置来影响卷积神经网络CNN的训练。我们的实验选择了三种不同的卷积神经网络。这些网络是AlexNet,VGG 16和ResNet20。我们证明,通过将BN层使用其他位置而不是原始论文建议的位置,可以提高BN算法提供的训练速度。此外,我们讨论了处于特定位置的BN层如何帮助训练一个网络而不是另一个网络。在这项研究中已经研究了BN层的三个不同位置。这些位置是在卷积层和非线性激活函数之间的BN层,在非线性激活函数之后的BN层,最后是在每个卷积层之前的BN层。 |
| Deep CMST Framework for the Autonomous Recognition of Heavily Occluded and Cluttered Baggage Items from Multivendor Security Radiographs Authors Taimur Hassan, Salman H. Khan, Samet Akcay, Mohammed Bennamoun, Naoufel Werghi 自过去的二十年以来,行李扫描已成为全球首要的航空安全问题之一。手动检查行李物品是一个繁琐,主观且效率低下的过程,许多研究人员为此目的开发了基于X射线图像的自主系统。但是,据我们所知,到目前为止,还没有一种框架能够识别X射线扫描中严重堵塞和混乱的行李物品,而与采集设备或扫描方式无关。本文提出了一个基于深层级联多尺度结构张量的框架,该框架可以自动提取和识别正常项目以及可疑项目,无论它们来自多厂商X射线扫描的位置和方向如何。所提出的框架是独一无二的,因为它通过迭代地选择来自不同方向的基于轮廓的过渡信息来智能地提取每个对象,并且仅使用单个前馈卷积神经网络进行识别。所提出的框架已经在两个公开可用的数据集上进行了严格的测试,该数据集包含1,067,381个x射线扫描的累积数据,通过达到0.9689的平均工会交集,其曲线下的面积最大为,大大优于现有的现有解决方案。 0.9950,精度高达0.9955,平均平均精度得分高达0.9453,可检测正常和可疑行李物品。此外,与流行的物体检测器相比,所提出的框架已经实现了15.78更好的时间性能。 |
| Self-supervised Object Motion and Depth Estimation from Video Authors Qi Dai, Vaishakh Patil, Simon Hecker, Dengxin Dai, Luc Van Gool, Konrad Schindler 我们提出了一个自我监督的学习框架,以估计视频中单个物体的运动和单眼深度。我们将物体运动建模为6自由度刚体变换。实例分割掩码用于引入对象信息。与预测像素级光流图以模拟运动的方法相比,我们的方法显着减少了要估计的值的数量。此外,我们的系统通过采用预先计算的相机自我运动和左右光度一致性,消除了预测的比例模糊性。在KITTI驾驶数据集上进行的实验表明,我们的系统无需外部注释即可捕获物体运动,并有助于动态区域中的深度预测。我们的系统在3D场景流预测方面优于早期的自我监督方法,并在光流估计方面产生可比的结果。 |
| DCIL: Deep Contextual Internal Learning for Image Restoration and Image Retargeting Authors Indra Deep Mastan, Shanmuganathan Raman 最近,人们对开发独立于训练样本的方法产生了极大的兴趣,例如深层图像先验,零镜头学习和内部学习。尽管固有的技术多样性,以上方法基于最大化从单个图像学习图像特征的共同目标。在这项工作中,我们弥合了上述各种无监督方法之间的差距,并提出了图像恢复和图像重新定向的通用框架。我们使用上下文特征学习和内部学习来改进源图像和目标图像之间的结构相似性。我们在以下设置中执行图像调整大小的应用程序:使用超分辨率的经典图像调整大小,低分辨率图像包含噪点的具有挑战性的图像调整大小,以及使用图像重新定向的内容感知图像调整大小。我们还提供了与相关技术水平的比较。 |
| FaultNet: Faulty Rail-Valves Detection using Deep Learning and Computer Vision Authors Ramanpreet Singh Pahwa, Jin Chao, Jestine Paul, Yiqun Li, Ma Tin Lay Nwe, Shudong Xie, Ashish James, Arulmurugan Ambikapathi, Zeng Zeng, Vijay Ramaseshan Chandrasekhar 定期检查铁路阀门和发动机是确保全球铁路网络安全和高效的重要任务。在过去的十年中,基于计算机视觉和模式识别的技术已被广泛应用于此类检查和缺陷检测任务。自动化的端到端培训系统可以潜在地提供低成本,高吞吐量和廉价替代这些组件的手动外观检查的方法。但是,这样的系统需要大量的缺陷图像以供网络理解复杂缺陷。在本文中,提出了一种基于多阶段深度学习的技术来对轨道阀进行准确的故障检测。我们的方法使用两步法对轨道阀进行高精度图像分割,从而实现了像素级的精确分割。此后,使用计算机视觉技术来识别故障阀门。我们证明,与用于故障检测的最新技术现状相比,所提出的方法可提高检测性能。 |
| Shared Visual Abstractions Authors Tom White 本文介绍了由神经网络创建的抽象艺术,该抽象艺术在各种计算机视觉系统中得到广泛认可。触发特定标签的抽象形式独立于神经体系结构或训练集而存在,表明卷积神经网络为它们理解的类别建立共享的视觉表示。遇到这些图纸的计算机视觉分类器在极端情况下对特定标签的响应通常要强于来自验证集中的所有示例。通过调查人类对象,我们确认这些抽象作品也可以被人们广泛识别,这表明由这些图形触发的视觉表示在人类和计算机视觉系统之间是共享的。 |
| Learning a Neural 3D Texture Space from 2D Exemplars Authors Philipp Henzler, Niloy J. Mitra, Tobias Ritschel 我们提出了具有多样性,视觉逼真度和高计算效率的2D和3D自然纹理生成模型。这可以通过一系列方法实现,这些方法将思想从经典的随机过程纹理化Perlin噪声扩展到学习的,深度的,非线性的。关键思想是一个硬编码,可调谐和可微分的步骤,该步骤将多个转换后的随机2D或3D字段馈送到可以在无限域中采样的MLP。我们的模型对来自不同纹理集的所有样本进行编码,而无需为每个样本进行重新训练。应用包括纹理插值和从2D示例中学习3D纹理。 |
| Estimation of Muscle Fascicle Orientation in Ultrasonic Images Authors Regina Pohle Fr hlich, Christoph Dalitz, Charlotte Richter, Benjamin St udle, Kirsten Albracht 我们比较了四种不同的算法,这些算法可根据超声图像自动估计肌肉束角度,包括血管分布滤波器,Radon变换,投影轮廓法和灰度共生矩阵GLCM。将算法结果与三位不同专家在不同运动类型下录制的两个视频的425个图像帧上生成的地面真实数据进行比较。与地面真相数据的最佳一致性是通过结合使用容器过滤器进行预处理并使用投影轮廓法测量角度来实现的。通过将算法应用于具有高梯度的子区域并通过这些估计执行LOESS拟合,可以提高估计的鲁棒性。 |
| DeepFuse: An IMU-Aware Network for Real-Time 3D Human Pose Estimation from Multi-View Image Authors Fuyang Huang, Ailing Zeng, Minhao Liu, Qiuxia Lai, Qiang Xu 在本文中,我们提出了一个两阶段的全3D网络,即textbf DeepFuse,通过融合人体穿戴的惯性测量单元IMU数据和多视图图像来估计3D空间中的人体姿势。第一阶段设计用于纯视觉估计。为了保留多视图输入的数据原始性,视觉阶段使用多通道体积作为数据表示,并使用3D soft argmax作为激活层。第二个阶段是IMU改进阶段,该阶段引入了IMU骨层,以便在数据级别更早地融合IMU和视觉数据。无需先验地给出给定的骨架模型,在协议1下,我们在TotalCapture数据集上的平均关节误差为28.9 mm,在Human3.6M数据集上的平均关节误差为13.4 mm,从而大大提高了SOTA结果。最后,我们通过实验讨论了完全3D网络对3D姿态估计的有效性,这可能会有益于未来的研究。 |
| Synthetic Humans for Action Recognition from Unseen Viewpoints Authors G l Varol, Ivan Laptev, Cordelia Schmid, Andrew Zisserman 我们在这项工作中的目标是通过使用综合训练数据来提高训练过程中看不见的观点的人类动作识别性能。尽管已显示合成数据对诸如人体姿势估计之类的任务是有益的,但相对来说,尚未开发将其用于RGB人体动作识别。我们利用单眼3D人体重构的最新进展,从真实动作序列中自动生成动作标签的合成训练视频。 |
| ShadingNet: Image Intrinsics by Fine-Grained Shading Decomposition Authors Anil S. Baslamisli, Partha Das, Hoang An Le, Sezer Karaoglu, Theo Gevers 通常,固有图像分解算法将阴影解释为一个统一的组件,包括所有光度效应。由于阴影过渡通常比反照率变化更平滑,因此这些方法可能无法将强投射阴影与反照率变化区分开。反过来,这可能会泄漏到反照率地图预测中。因此,在本文中,我们建议将阴影分量分解为直接照明和间接阴影环境光和阴影。目的是从反射率变化中区分出强烈的阴影。提出了两个端到端监督的CNN模型ShadingNets,它们利用了细粒度的着色模型。此外,表面的法线特征是由提出的CNN网络共同学习的。表面法线有望协助分解任务。室外自然环境的场景级别合成图像的大规模数据集提供了固有图像地面真相。大规模实验表明,我们使用细粒度阴影分解的CNN方法优于使用统一阴影的最新技术。 |
| Deep Neural Network for Fast and Accurate Single Image Super-Resolution via Channel-Attention-based Fusion of Orientation-aware Features Authors Du Chen, Zewei He, Yanpeng Cao, Jiangxin Yang, Yanlong Cao, Michael Ying Yang, Siliang Tang, Yueting Zhuang 近年来,卷积神经网络CNN已成功地用于解决不适定单图像超分辨率SISR问题。提高基于CNN的SISR模型性能的常用策略是部署非常深的网络,这不可避免地会带来许多明显的缺点,例如,大量的网络参数,繁重的计算量以及难以进行的模型训练。在本文中,我们旨在通过开发性能更好的特征提取和融合技术来构建更准确,更快的SISR模型。首先,我们提出了一种新颖的定向感知特征提取和融合模块OAM,其中包含1D和2D卷积核的混合物,即5 x 1,1 x 5和3 x 3,用于提取定向感知特征。其次,我们采用信道注意机制作为一种有效的技术,以自适应地融合从不同方向提取的特征以及在分层堆叠的卷积阶段中提取的特征。基于这两个重要的改进,我们通过基于信道注意的定向感知功能SISR CA OA的融合,提出了一个基于紧凑但功能强大的CNN的高质量SISR模型。大量的实验结果验证了所提出的SISR CA OA模型的优越性,在恢复精度和计算效率方面均优于最先进的SISR模型。源代码将公开提供。 |
| Environment reconstruction on depth images using Generative Adversarial Networks Authors Lucas P. N. Matias, Jefferson R. Souza, Denis F. Wolf 强大的感知系统对于自动驾驶汽车的安全至关重要。为了在复杂的城市环境中导航,需要具有可靠数据的精密传感器。对于智能车辆而言,了解周围环境的任务本身很困难,由于车辆的高速行驶,这一任务尤为重要。为了在城市环境中成功导航,感知系统必须快速接收,处理和执行动作,以确保乘客和行人的安全。立体声相机收集许多级别的环境信息,例如深度,颜色,纹理,形状,这些信息可以确保您对周围环境有足够的了解。即便如此,当与人类相比时,计算方法仍缺乏处理缺失信息即遮挡的能力。对于许多感知任务,由于环境信息不完整,数据的缺乏可能会成为障碍。在本文中,我们解决了这个问题并讨论了处理遮挡区域推断的最新方法。然后,我们介绍一个专注于视差和环境深度数据重建的损失函数,以及一个能够处理被遮挡的信息推断的创生对抗网络GAN架构。我们的结果提出了深度图上的连贯重建,估计了被不同障碍物遮挡的区域。我们的最终贡献是针对视差数据的损失函数,以及能够通过修补视差图像来提取深度特征并估算深度数据的GAN。 |
| Efficient Object Detection in Large Images using Deep Reinforcement Learning Authors Burak Uzkent, Christopher Yeh, Stefano Ermon 传统上,将对象检测器应用于感兴趣场景的每个部分,并且其精度和计算成本随着高分辨率图像的增加而增加。然而,在诸如遥感的某些应用领域中,购买高空间分辨率图像是昂贵的。为了减少与使用高空间分辨率图像相关的大量计算和金钱成本,我们提出了一种增强学习代理,该学习代理自适应地选择提供给检测器的每个图像的空间分辨率。特别是,我们在双重奖励设置中训练代理,以选择当图像被大物体支配时要通过粗略检测器运行的低空间分辨率图像,而当图像是由大物体支配时选择要通过精细检测器运行的高空间分辨率图像由小物体主导。这减少了对构建坚固的检测器的高空间分辨率图像的依赖性,并提高了运行时间效率。我们对包含大型图像的xView数据集进行了实验,将运行时间效率提高了50倍,仅使用了30次高分辨率图像,同时保持了与仅使用高分辨率图像的检测器相似的准确性。 |
| Bi-Semantic Reconstructing Generative Network for Zero-shot Learning Authors Xu Shibing, Gao Zishu 零射击学习ZSL的许多最新方法试图利用生成模型从语义描述和随机噪声中生成看不见的视觉样本。因此,ZSL问题成为传统的监督分类问题。然而,大多数基于生成模型的现有方法仅关注训练阶段合成样本的质量,而忽略了零镜头识别阶段的重要性。在本文中,我们考虑了以上两点,并提出了一种新颖的方法。特别是,我们选择“生成对抗网络” GAN作为我们的生成模型。为了提高合成样本的质量,考虑语义空间中语义描述的内部关系以及可见和不可见的视觉信息属于不同领域这一事实,我们提出了一个双向语义重构BSR组件,其中包含两个不同的语义重建回归器来领导GAN的训练。由于语义描述在训练阶段可用,为了进一步提高分类器的能力,我们结合视觉样本和语义描述来训练分类器。在识别阶段,我们自然地利用BSR组件来传递视觉特征和语义描述,并将它们连接起来进行分类。实验结果表明,在一些ZSL基准数据集上,我们的方法优于最新技术,并且有明显的改进。 |
| CNN-based Lidar Point Cloud De-Noising in Adverse Weather Authors Robin Heinzler, Florian Piewak, Philipp Schindler, Wilhelm Stork 激光雷达传感器常用于自动驾驶汽车和移动机器人的环境感知,以补充摄像头,雷达和超声传感器。不利的天气条件会引起不希望的测量点,进而影响缺失的检测和误报,从而严重影响基于激光雷达的场景理解性能。在大雨或浓雾中,水滴可能被误解为车辆前方的物体,从而使移动机器人停下来。在本文中,我们提出了第一个基于CNN的方法来理解和过滤点云数据中的这种不利天气影响。使用在受控天气环境中获得的大数据集,我们证明了我们的方法相对于涉及几何过滤的最新技术的显着性能改进。数据位于 |
| Learning a Layout Transfer Network for Context Aware Object Detection Authors Tao Wang, Xuming He, Yuanzheng Cai, Guobao Xiao 我们提出一种基于上下文的对象检测方法,该方法基于检索和变换场景布局模型。给定一个输入图像,我们的方法首先从典型布局模板的代码本中检索出粗糙的场景布局。为了处理较大的布局变化,我们使用空间转换器网络的变体来变换和完善检索到的布局,从而生成一组可解释且语义上有意义的对象位置和比例尺特征图。上面的步骤被实现为布局传输网络,我们将其集成到Faster RCNN中,以实现对象检测和场景布局估计的联合推理。在三个公共数据集上进行的大量实验证明,我们的方法可对交通监控和自动驾驶领域中各种挑战性任务的最新对象检测基准提供一致的性能改进。 |
| Bundle Adjustment Revisited Authors Yu Chen, Yisong Chen, Guoping Wang 从中型到中型再到大规模,这20年一直在发展3D重建。众所周知,束调整在3D重建中起着重要作用,主要在Motion SfM的结构以及同时定位和映射SLAM中发挥作用。虽然捆绑调整是优化相机参数和3D点的最终步骤,但最终步骤却是不可忽略的,但它在大型重建中会遇到内存和效率方面的要求。在本文中,我们详细研究了常规方法和分布式方法中束调节的发展。本文还给出了详细的推导和伪代码。 |
| Shape-Aware Organ Segmentation by Predicting Signed Distance Maps Authors Yuan Xue, Hui Tang, Zhi Qiao, Guanzhong Gong, Yong Yin, Zhen Qian, Chao Huang, Wei Fan, Xiaolei Huang 在这项工作中,我们建议解决当前基于深度学习的器官分割系统中存在的问题,即它们经常产生的结果无法捕获目标器官的整体形状,并且常常缺乏平滑度。由于从对象边界轮廓计算出的符号距离图SDM与二进制分割图之间存在严格的映射,因此我们利用了直接从医学扫描中学习SDM的可行性。通过将分割任务转换为预测SDM,我们证明了我们提出的方法保留了出色的分割性能,并具有更好的平滑度和形状连续性。为了在传统的分割训练中利用补充信息,我们引入了近似的Heaviside函数通过同时预测SDM和分割图来训练模型。我们通过对海马分割数据集和公开的具有多个器官的MICCAI 2015头颈自动分割挑战数据集进行广泛的实验,验证了我们提出的模型。尽管我们精心设计的骨干3D分割网络与当前技术水平相比将Dice系数提高了5倍以上,但所建议的SDM学习模型可产生更平滑的分割结果,且Hausdorff距离和平均表面距离更小,从而证明了我们方法的有效性。 |
| Learning Structure-Appearance Joint Embedding for Indoor Scene Image Synthesis Authors Yuan Xue, Zihan Zhou, Xiaolei Huang 先进的图像合成方法可以为人脸,鸟类,卧室等生成逼真的照片。但是,这些方法没有明确地建模和保留基本的结构约束,例如结,平行线和平面。在本文中,我们研究了用于设计应用的结构化室内图像生成问题。我们利用一个小规模的数据集,其中包含各种室内场景的图像及其对应的地面真相线框注释。虽然在数据集上训练的现有图像合成模型不足以保持结构完整性,但我们提出了一种基于从图像和线框中学习到的结构外观关节嵌入的新型模型。在我们的模型中,通过学习共享编码器网络中的联合嵌入来明确实施结构约束,该编码器必须支持图像和线框的生成。我们证明了联合嵌入学习方案在室内场景线框上进行图像翻译任务的有效性。虽然线框作为输入包含的语义信息少于其他传统图像翻译任务的输入,但是我们的模型可以生成高保真度的室内场景渲染,这些渲染与输入线框非常匹配。在线框场景数据集上的实验表明,我们提出的转换模型在生成图像的视觉质量和结构完整性方面均明显优于现有的现有方法。 |
| Selective Synthetic Augmentation with Quality Assurance Authors Yuan Xue, Jiarong Ye, Rodney Long, Sameer Antani, Zhiyun Xue, Xiaolei Huang 在自动化医学图像分析系统的监督训练中,通常需要大量难以收集的专家注释。此外,对于罕见疾病,跨不同类别的可用数据比例可能高度不平衡。为了缓解这些问题,我们研究了一种新颖的数据增强管道,该管道有选择地添加了由条件对抗网络cGAN生成的新合成图像,而不是直接使用合成图像扩展训练集。我们引入到合成增强管道的选择机制是出于以下观察的动机:尽管cGAN生成的图像可以在视觉上吸引人,但不能保证它们包含用于改进分类性能的基本功能。通过基于合成图像的分配标签的置信度以及它们与真实标记图像的特征相似度来选择合成图像,我们的框架通过确保将所选合成图像添加到训练集中将改善性能,从而为合成增强提供质量保证。我们在医学组织病理学数据集和两个自然图像分类基准CIFAR10和SVHN上评估我们的模型。这些数据集上的结果表明,通过利用cGAN生成的图像进行选择性增强,可以分别以6.8、3.9、1.6的更高准确度显着提高分类性能。 |
| Amora: Black-box Adversarial Morphing Attack Authors Run Wang, Felix Juefei Xu, Xiaofei Xie, Lei Ma, Yihao Huang, Yang Liu 如今,随着生成的对抗网络GAN在图像合成中取得空前的成功,数字面部内容操纵已变得无处不在和现实。不幸的是,由于面部图像操纵,面部识别FR系统遭受严重的安全问题。在本文中,我们研究并介绍了一种通过操纵面部内容来逃避FR系统的新型对抗攻击,即对抗变形攻击(又名Amora)。与通过添加人类不可察觉的噪声来扰动像素强度值的对抗性噪声攻击相反,我们提出的对抗性变态攻击是一种以连贯的方式在空间上扰动像素的语义攻击。为了解决黑匣子攻击问题,我们设计了一种简单而有效的学习管道来为每次攻击获取专有的光流场。我们已经定量和定性地证明了在两个流行的FR系统中,在具有微笑的面部表情操纵的情况下,不同形态强度下的对抗性形态进攻的有效性。实验结果表明,基于局部变形的新型黑匣子对抗攻击是可能的,这与基于加性噪声的攻击有很大的不同。这项工作的发现可能为更深入地了解和调查基于图像的对抗性攻击和防御方式铺平了新的研究方向。 |
| Patch Aggregator for Scene Text Script Identification Authors Changxu Cheng, Qiuhui Huang, Xiang Bai, Bin Feng, Wenyu Liu 在多语言的健壮阅读系统中,野外脚本识别非常重要。源自同一语言家族的脚本共享大量字符,这使得脚本标识成为细粒度的分类问题。现有的大多数方法都努力通过制作加权平均或其他聚类方法来学习结合局部特征的单个表示,这可能会降低每个脚本中一些重要部分对冗余特征的干扰的辨别力。在本文中,我们提出了一个名为Patch Aggregator PA的新颖模块,该模块通过考虑局部补丁的预测得分来学习更具区分性的脚本识别表示。具体来说,我们设计了一个基于CNN的方法,该方法由标准CNN分类器和PA模块组成。实验表明,所提出的PA模块相对于基准CNN模型带来了显着的性能提升,在三个基准数据集上实现了脚本识别SIW 13,CVSI 2015和RRC MLT 2017的最新结果。 |
| Universal Material Translator: Towards Spoof Fingerprint Generalization Authors Rohit Gajawada, Additya Popli, Tarang Chugh, Anoop Namboodiri, Anil K. Jain 欺骗检测器是经过训练的分类器,用于区分欺骗指纹和真实指纹。但是,最新的欺骗检测器不能很好地推广到看不见的欺骗材料上。这项研究提出了一种基于样式转移的增强包装器,该包装器可以在任何现有的欺骗检测器上使用,并且可以动态地提高我们对数据非常低的欺骗材料的欺骗检测系统的鲁棒性。我们的方法是一种从一些欺骗示例中合成新的欺骗图像的方法,该示例将欺骗示例的样式或材质属性转换为真实指纹的内容,以生成大量示例以训练分类器。我们在公开可用的LivDet 2015数据集中证明了我们的方法对材料的有效性,并表明了所提出的方法对目标材料的指纹欺骗具有鲁棒性。 |
| Dually Supervised Feature Pyramid for Object Detection and Segmentation Authors Fan Yang, Cheng Lv, Yandong Guo, Longin Jan Latecki, Haibin Ling 特征金字塔体系结构已广泛应用于对象检测和分割中,以解决多尺度问题。但是,在本文中,我们表明由于监管信息的利用不足,因此尚未充分探索该体系结构的功能。这种不充分的利用是由于反向传播中的监视信号劣化引起的。因此,我们提出了一种双重监督方法,称为双重监督FPN DSFPN,以增强训练特征金字塔网络FPN时的监督信号。特别是,DSFPN是通过将额外的预测(即检测头或分段头)附加到FPN的自底向上子网来构造的。因此,在转发到后续网络之前,可以通过其他头对功能进行优化。此外,辅助头可以用作正则项以促进模型训练。另外,为了增强DSFPN中的检测头处理两个不均匀任务即分类和回归的能力,通过解耦分类和回归子网来分隔最初共享的隐藏特征空间。为了证明所提出方法的通用性,有效性和效率,将DSFPN集成到四个具有代表性的检测器中:Faster RCNN,Mask RCNN,Cascade RCNN和Cascade Mask RCNN并在MS COCO数据集上进行了评估。通过广泛的实验证明了有希望的精度提高,先进的性能以及可忽略的额外计算成本。将提供代码。 |
| Adversarial Pyramid Network for Video Domain Generalization Authors Zhiyu Yao, Yunbo Wang, Xingqiang Du, Mingsheng Long, Jianmin Wang 本文介绍了视频域泛化视频DG的一个新研究问题,其中由于缺乏对发散分布的目标域的暴露,大多数最先进的动作识别网络都在退化。虽然视频理解的最新进展集中于捕获长期视频上下文的时间关系,但我们观察到全局时间特征在视频DG设置中的通用性较低。原因是来自其他看不见的域的视频可能会出现时间关系的意外缺失,未对齐或比例转换,这被称为时域移位。因此,视频DG比图像DG更具挑战性,由于空间和时间域偏移的缠结,图像DG也正在探索中。 |
| ICDAR 2019 Competition on Image Retrieval for Historical Handwritten Documents Authors Vincent Christlein, Anguelos Nicolaou, Mathias Seuret, Dominique Stutzmann, Andreas Maier 这项比赛调查了根据写作风格对历史文献图像进行大规模检索的性能。基于文化遗产机构和数字图书馆提供的大图像数据集,总共提供了约20000张文档图像,代表约10000名作家,分为i手稿,ii信,iii宪章和法律文件三种类型的作家。我们专注于自动图像检索的任务,以模拟人文研究的常见场景,例如作者检索。大多数团队提交了不使用深度学习技术的传统方法。竞争结果表明,方法的组合优于单个方法。此外,字母比手稿难找得多。 |
| SolarNet: A Deep Learning Framework to Map Solar Power Plants In China From Satellite Imagery Authors Xin Hou, Biao Wang, Lei Yin, Haishan Wu 太阳能等可再生能源对于应对日益严重的气候变化至关重要。中国是全球领先的太阳能电池板安装商,并且建造了许多太阳能发电厂。在本文中,我们提出了一个名为SolarNet的深度学习框架,该框架旨在对大规模卫星图像数据执行语义分割以检测太阳能场。 SolarNet已成功在中国测绘了439个太阳能发电场,覆盖了近2000平方公里,相当于整个深圳市或纽约市的两个半。据我们所知,这是我们第一次使用深度学习来揭示中国太阳能发电场的位置和规模,这可以为太阳能发电公司,市场分析师和政府提供见识。 |
| VM-Net: Mesh Modeling to Assist Segmentation in Volumetric Data Authors Udaranga Wickramasinghe, Graham Knott, Pascal Fua 现在,基于CNN的用于标记单个体素的体积方法在生物医学分割领域占据主导地位。在本文中,我们证明了同时执行分割和恢复对表面进行建模的3D网格可以提高性能。 |
| Domain-adaptive Crowd Counting via Inter-domain Features Segregation and Gaussian-prior Reconstruction Authors Junyu Gao, Tao Han, Qi Wang, Yuan Yuan 最近,使用监督学习进行人群计数取得了显着进步。尽管如此,大多数计数器仍依赖大量手动标记的数据。随着合成人群数据的发布,一种潜在的替代方案是无需任何人工标签即可将知识从它们转移到真实数据。但是,没有方法可以有效地抑制转移过程中的畴隙和输出精细的密度图。为了解决上述问题,本文提出了一种域自适应人群计数DACC框架,该框架由域间特征分离IFS和高斯先验重建GPR组成。具体来说,IFS将合成数据转换为逼真的图像,其中包含域共享特征提取和独立于域的特征修饰。然后,对粗略计数器进行翻译后数据的训练,并将其应用于现实世界。此外,根据粗略的预测,GPR生成伪标记以提高实际数据的预测质量。接下来,我们使用这些伪标签重新训练最终计数器。对六个现实世界数据集的适应性实验表明,所提出的方法优于最新方法。此外,代码和预先训练的模型将尽快发布。 |
| Detection of False Positive and False Negative Samples in Semantic Segmentation Authors Matthias Rottmann, Kira Maag, Robin Chan, Fabian H ger, Peter Schlicht, Hanno Gottschalk 近年来,深度学习方法在图像识别方面已经胜过其他方法。这激发了人们对深度学习技术潜在应用的想象力,其中包括安全相关的应用,例如医学图像的解释或自动驾驶。从人类决策者的协助到越来越多的自动化系统的转变,增加了正确处理深度学习模块的故障模式的需求。在此贡献中,我们回顾了一组基于不确定性量化的机器学习算法自我监控技术。特别地,我们将其应用于语义分割任务,其中机器学习算法根据语义类别分解图像。我们在实例级别讨论了错误肯定和错误否定错误模式,并回顾了作者最近提出的用于检测此类错误的技术。我们还对未来的研究方向进行了展望。 |
| Feature-aware Adaptation and Structured Density Alignment for Crowd Counting in Video Surveillance Authors Junyu Gao, Qi Wang, Yuan Yuan 随着深度神经网络的发展,人群计数和逐像素密度估计的性能不断得到更新。尽管如此,该领域仍然存在两个具有挑战性的问题1当前的监督学习需要大量的训练数据,但是很难对其进行收集和注释2现有的方法不能很好地推广到看不见的领域。最近发布的综合人群数据集缓解了这两个问题。但是,现实世界的数据与合成图像之间的领域差距降低了模型的性能。为了缩小差距,本文提出了一种领域适应风格的人群计数方法,该方法可以有效地将模型从合成数据适应特定的现实世界场景。它由多级特征感知适应MFA和结构化密度图对齐SDA组成。具体来说,MFA增强了模型以从多层提取域不变特征。 SDA保证网络在实际域上输出合理分布的精细密度图。最后,我们在四个主要的监视人群数据集上评估了所提出的方法,这些数据集包括:上海技术B部分,WorldExpo 10,Mall和UCSD。大量实验证明,对于相同的跨域计数问题,我们的方法优于最新方法。 |
| SampleNet: Differentiable Point Cloud Sampling Authors Itai Lang, Asaf Manor, Shai Avidan 直接在点云上运行的任务越来越多。随着点云大小的增加,这些任务的计算需求也随之增加。一种可能的解决方案是先对点云进行采样。经典采样方法(例如,最远点采样FPS)不考虑下游任务。最近的一项工作表明,学习任务特定的采样可以显着改善结果。但是,提出的技术并未处理采样操作的不可微性,而是提供了一种解决方法。 |
| Bidirectional Scene Text Recognition with a Single Decoder Authors Maurits Bleeker, Maarten de Rijke 场景文本识别STR是在裁剪的单词图像中识别正确的单词或字符序列的问题。为了获得更鲁棒的输出序列,已经引入了双向STR的概念。到目前为止,已经通过使用两个单独的解码器来实现双向STR,一个用于左至右解码,一个用于右至左解码器。从计算和优化的角度来看,具有两个单独的解码器来完成几乎相同的任务且具有相同的输出空间是不希望的。我们介绍了双向场景文本变压器Bi STET,这是一种新颖的带有单个解码器的双向STR方法,用于双向文本解码。通过其单个解码器,Bi STET优于使用两个单独的解码器进行双向解码的方法,同时还比那些方法更有效。此外,我们在Bi STET的所有STR基准测试中都达到或超越了最新的SOTA方法。最后,我们提供有关Bi STET性能的分析和见解。 |
| ILS-SUMM: Iterated Local Search for Unsupervised Video Summarization Authors Yair Shemer, Daniel Rotman, Nahum Shimkin 近年来,人们对构建视频摘要工具的兴趣日益浓厚,其目的是自动创建可正确代表原始内容的输入视频的简短摘要。我们考虑基于镜头的视频摘要,其中摘要由可以不同长度的视频镜头的子集组成。使镜头子集的代表性最大化的一种直接方法是最小化镜头与其最近选择的镜头之间的总距离。我们将视频汇总的任务表述为一个优化问题,该问题具有对总汇总持续时间的背包式约束。先前的研究提出了贪婪算法来近似解决该问题,但是没有实验可以衡量这些方法获得总距离短的解决方案的能力。确实,我们在视频汇总数据集上的实验表明,当前方法在获得总距离较小的结果方面的成功仍然有很大的改进空间。在本文中,我们开发了ILS SUMM,这是一种新颖的视频汇总算法,用于解决背包约束下的子集选择问题。我们的算法基于众所周知的元启发式优化框架Iterated Local Search ILS(迭代局部搜索ILS),以避免弱局部最小值并获得良好的近似全局最小值的能力而闻名。大量实验表明,我们的方法找到的解决方案比以前的方法具有更好的总距离。此外,为了表明ILS SUMM的高度可扩展性,我们引入了一个新的数据集,其中包含各种长度的视频。 |
| Lossless Compression for 3DCNNs Based on Tensor Train Decomposition Authors Dingheng Wang, Guangshe Zhao, Guoqi Li, Lei Deng, Yang Wu 三维卷积神经网络3DCNN已应用于视频或3D点云识别的许多任务。但是,由于卷积核的维数较大,因此3DCNN的空间复杂度通常大于传统的二维卷积神经网络2DCNN的空间复杂度。为了使3DCNN小型化以在受限环境(例如嵌入式设备)中进行部署,神经网络压缩是一种有前途的方法。在这项工作中,我们采用张量训练TT分解(一种最紧凑和最简单的Emph原位训练压缩方法)来缩小3DCNN模型。我们给出TT格式的3D卷积核的张量,并研究如何为TT格式的张量选择合适的秩。根据基于VIVA挑战和UCF11数据集的多次对比实验,我们得出结论,TT分解可以以高达121倍的比率压缩冗余3DCNN,而准确性几乎没有提高。此外,我们在VIVA挑战数据集81.83上获得了TT 3DCNN的最新结果。 |
| SaLite : A light-weight model for salient object detection Authors Kitty Varghese, Sauradip Nag 突出对象检测是一种普遍的计算机视觉任务,其应用范围从异常检测到异常处理。上下文建模是显着性检测领域中的重要标准。全局上下文通过对比场景的全局视图中的其他对象来帮助确定给定图像中的显着对象。但是,局部上下文特征可以在给定区域中以更高的精度检测显着对象的边界。为了融合两个方面的优势,我们提出的SaLite模型同时使用了全局和局部上下文特征。它是基于编码器解码器的体系结构,其中编码器使用轻量级的SqueezeNet,解码器使用卷积层建模。有权进行显着性检测的现代深度模型基于大量参数,很难在嵌入式系统上进行部署。本文尝试使用SaLite解决上述问题,这是一种在不影响性能的情况下显着检测目标物体的较轻方法。我们的方法在DUTS,MSRA10K和SOC这三个可公开获得的数据集上得到了广泛评估。实验结果表明,我们提出的SaLite在现有技术方法方面具有显着而一致的改进。 |
| Capsule-Based Persian/Arabic Robust Handwritten Digit Recognition Using EM Routing Authors Ali Ghofrani, Rahil Mahdian Toroghi 本文解决了手写数字识别的问题。但是,基础语言是波斯阿拉伯语,与此任务相关的系统是胶囊网络CapsNet的出现比其祖先CNN卷积神经网络更先进。使用Hoda数据集对体系结构进行培训,该数据集已为波斯语阿拉伯手写数字提供。该系统的输出明显优于其祖先以及其他先前提出的识别算法所获得的结果。 |
| View-invariant Deep Architecture for Human Action Recognition using late fusion Authors Chhavi Dhiman, Dinesh Kumar Vishwakarma 人类行为识别未知的观点是一项艰巨的任务。我们提出了一种视图不变的深度人类动作识别框架,该框架是两个重要的动作线索运动和形状时态动力学STD的新颖集成。运动流将动作的运动内容封装为RGB动态图像RGB DI,这些RGB DI由微调的InceptionV3模型处理。 STD流使用基于人体姿势模型HPM的视图不变特征来学习动作的长期视图不变形状动力学,该观点不变特征是从基于结构相似性指标矩阵SSIM的关键深度人类姿势帧中提取的。为了预测测试样品的分数,将三种后期融合最大值,平均值和乘积技术应用于各个流分数。为了验证所提出的新颖框架的性能,在三个公共基准NUCLA多视图数据集,UWA3D II活动数据集和NTU RGB D活动数据集上,使用跨主题和跨视图验证方案进行了实验。我们的算法在准确性,接收器工作特性ROC曲线和曲线AUC下面积方面均表现出明显优于现有技术的优势。 |
| Face Beautification: Beyond Makeup Transfer Authors Xudong Liu, Ruizhe Wang, Chih Fan Chen, Minglei Yin, Hao Peng, Shukhan Ng, Xin Li 面部表情在我们的社交生活中起着重要作用。对女性美丽的主观感知取决于与面部相关的各种因素,例如皮肤,形状,头发和环境,例如化妆,照明,角度因素。类似于物理世界中的整容手术,虚拟面部美化是一个新兴领域,有许多未解决的问题需要解决。受到基于样式的合成和面部美容预测的最新进展的启发,我们提出了面部美化的新颖框架。对于具有较高美容分数的给定参考脸部,我们基于GAN的体系结构能够将查询的面部转换为具有参考美容风格和目标美容分数值的一系列美化面部图像。为了实现这一目标,我们建议将从参考脸部提取的基于样式的美容表示与在SCUT FBP数据库上训练的美容分数预测集成到美化过程中。与化妆转移不同,我们的方法针对的是多对多翻译,而不是一对一翻译,在这种翻译中,可以通过不同的参考文献或不同的美容分数来定义多个输出。据报道,大量的实验结果证明了所提出的面部美化框架的有效性和灵活性。 |
| VoronoiNet: General Functional Approximators with Local Support Authors Francis Williams, Daniele Panozzo, Kwang Moo Yi, Andrea Tagliasacchi Voronoi图是用于各种图形应用程序的高度紧凑的表示形式。在这项工作中,我们将展示如何通过新颖的深度架构将其不同版本嵌入到生成性深度网络中。通过这样做,我们实现了高度紧凑的潜在嵌入,能够为各种形状在2D和3D中提供更详细的重建。在此技术报告中,我们介绍了我们的表示形式,并提供了一组初步结果,将其与最近提出的隐式占用网络进行了比较。 |
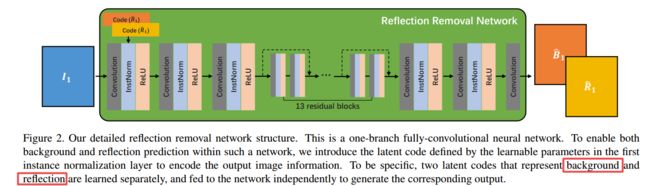
| Deep Reflection Prior Authors Qingnan Fan, Yingda Yin, Dongdong Chen, Yujie Wang, Angelica Aviles Rivero, Ruoteng Li, Carola Bibiane Schnlieb, Dani Lischinski, Baoquan Chen 反射是我们日常摄影中非常普遍的现象,它使人们的注意力从玻璃后面的场景中转移开。去除反射伪像的问题很重要,但由于其不适性而具有挑战性。最近的基于学习的方法已证明在消除反射方面有重大改进。但是,这些方法受到限制,因为它们需要大量的合成反射清洁图像对进行监控,但存在过度拟合合成图像域的风险。在本文中,我们提出了一种基于学习的方法,该方法先捕获反射统计信息,然后再去除单个图像反射。我们的算法是通过在训练阶段通过在多个输入图像之间增强联合约束来优化目标来驱动的,但是能够消除仅来自单个输入的反射以进行评估。我们的框架允许通过一个分支的深度神经网络来预测背景和反射,该神经网络由指示背景或反射输出的可控潜在代码实现。我们在各种真实世界的图像上展示了优于最新方法的性能。我们还将在学到的潜在代码后面提供有见地的分析,这可能会激发更多的未来工作。 |
| Zero-shot Recognition of Complex Action Sequences Authors Jonathan D. Jones, Tae Soo Kim, Michael Peven, Jin Bai, Zihao Xiao, Yi Zhang, Weichao Qiu, Alan Yuille, Gregory D. Hager 使用类似于基于图像的对应方法的方法,即通过定义用于区分类别的图像派生属性,已在很大程度上探索了用于细粒度活动识别的零镜头视频分类。但是,这样的方法不能捕获活动的基本动态,因此仅限于仅静态图像内容就足以对活动进行分类的情况。例如,诸如进出汽车之类的可逆动作通常是无法区分的。 |
| Learning Sparse 2D Temporal Adjacent Networks for Temporal Action Localization Authors Songyang Zhang, Houwen Peng, Le Yang, Jianlong Fu, Jiebo Luo 在此报告中,我们介绍了HACS 2019临时行动本地化挑战赛的获胜者方法。临时行动本地化具有挑战性,因为目标提案可能与未整理视频中的其他几个候选提案相关。现有的方法不能很好地解决这一挑战,因为临时提议被单独考虑并且它们的临时相关性被忽略了。为了解决这个问题,我们提出了稀疏的2D时间相邻网络来对候选提议之间的时间关系进行建模。该方法基于最近提出的2D TAN方法。 2D TAN中的采样策略引入了不平衡的上下文问题,与长提案相比,短提案可以感知更多的上下文。因此,我们进一步提出了一个稀疏的2D时间相邻网络S 2D TAN。它可以为长期建议包含更多上下文信息,并可以从中进一步学习区分功能。通过将我们的S 2D TAN与简单的动作分类器相结合,我们的方法在测试集上的mAP达到了23.49,这在HACS挑战赛中获得了第一名。 |
| Individual predictions matter: Assessing the effect of data ordering in training fine-tuned CNNs for medical imaging Authors John R. Zech, Jessica Zosa Forde, Michael L. Littman 我们用固定的超参数和50个不同的随机种子再现了CheXNet的结果,以确定在X线胸片中发现14个发现。由于CheXNet会微调预训练的DenseNet,因此随机种子会影响训练数据批次的排序,但不会影响初始化的模型权重。我们发现,在整个模型运行中,同一张X射线片的预测中存在很大的变异性,即均值ln最大概率最小概率2.45,变异系数0.543。在大型测试集上,这种个体射线照相水平的变异性并未完全反映在AUC的变异性中。 10个模型的平均预测将变异性降低了近70个,平均变异系数从0.543降低至0.169,t检验为15.96,p值为0.0001。我们鼓励研究人员注意CNN的潜在变异性以及来自多个模型的整体预测,以最大程度地减少这种变异性在临床上部署后可能对个别患者的护理产生的影响。 |
| Neural Network Generalization: The impact of camera parameters Authors Zhenyi Liu, Trisha Lian, Joyce Farrell, Brian Wandell 我们对经过训练以识别汽车的卷积神经网络CNN的推广进行量化。首先,我们进行了一系列实验,使用一个合成的图像数据或来自相机的图像数据集训练网络,然后在另一个图像数据集上进行测试。我们表明,使用不同相机获得的图像之间的概括与来自相机的图像与光线跟踪的多光谱合成图像之间的概括大致相同。其次,我们使用ISETAuto(一种软原型工具),该工具可以创建光线跟踪的相机图像多光谱模拟,以模拟具有一系列像素大小,滤色器,采集和采集后处理的传感器图像。这些实验揭示了特定相机参数和图像处理操作的变化如何影响CNN泛化。我们发现像素大小会影响一般性,b去马赛克会严重影响浅8位深的深度的性能和泛化,但不会影响10位深的深度,并且c使用10位像素的未去马赛克的原始传感器数据,网络性能会很好。 |
| Learning 2D Temporal Adjacent Networks for Moment Localization with Natural Language Authors Songyang Zhang, Houwen Peng, Jianlong Fu, Jiebo Luo 我们解决了通过查询语句从未修剪的视频中检索特定时刻的问题。这是一个具有挑战性的问题,因为目标时刻可能与未修剪视频中的其他瞬时时刻有关。现有方法无法很好地解决这一挑战,因为它们会单独考虑时间矩,而忽略了时间依赖性。在本文中,我们通过二维映射对视频时刻之间的时间关系进行建模,其中一维指示时刻的开始时间,另一维指示结束时间。该2D时间图可以代表不同的视频时长,同时代表它们的相邻关系。基于2D地图,我们提出了时间相邻网络2D TAN,这是一个用于矩定位的单发框架。它能够对相邻的时间关系进行编码,同时学习区分特征,以使视频时刻与参考表达相匹配。我们在三个具有挑战性的基准上评估了拟议的2D TAN,即Charades STA,ActivityNet Captions和TACoS,其中我们的2D TAN优于最新技术。 |
| Feature Augmentation Improves Anomalous Change Detection for Human Activity Identification in Synthetic Aperture Radar Imagery Authors Hannah J. Murphy, Christopher X. Ren, Matthew T. Calef 异常变化检测ACD方法将常见的,无趣的变化与在不同时间点收集的共同注册图像的罕见,显着变化分开。在本文中,我们评估了以户外音乐节为目标,以提高ACD在SAR图像中检测人类活动的性能的方法。我们的结果表明,与较简单的方法(例如图像差分)相比,SAR数据的低维性导致ACD的性能较差,但通过合并局部空间信息来增强输入特征空间的维数会导致性能提高。 |
| Long Term Temporal Context for Per-Camera Object Detection Authors Sara Beery, Guanhang Wu, Vivek Rathod, Ronny Votel, Jonathan Huang 在静态监控摄像机中,有用的上下文信息可能会远远超出典型的视频理解模型可能会看到的对象在数天之内表现出相似行为且背景对象保持静态的几秒钟之内。但是,由于功率和存储的限制,采样频率很低,通常不快于每秒一帧,并且有时由于使用运动触发而不规则。为了在此设置下表现良好,模型必须对不规则采样率具有鲁棒性。在本文中,我们提出了一种基于注意力的方法,该模型可使我们的模型索引到基于每个摄像机构建的长期存储库中,并汇总来自其他帧的上下文特征,以提高当前帧的对象检测性能。我们将模型应用于以下两种设置:1使用摄像机陷阱数据进行物种检测,该数据基于运动触发以低的可变帧速率进行采样并用于研究生物多样性; 2在交通摄像机中进行车辆检测,帧速率同样较低。我们表明,在所有设置中,我们的模型都可以使性能指标超过严格的基准。此外,我们表明,增加存储库的时间范围可以改善结果。当应用于Snapshot Serengeti数据集中的相机陷阱数据时,我们的最佳模型可以利用长达一个月的图像的上下文在0.5 IOU时的性能优于单帧基线17.9 mAP,并且比S3D的11.2 mAP性能优于基于3d卷积的基线。 |
| A Real-time Global Inference Network for One-stage Referring Expression Comprehension Authors Yiyi Zhou, Rongrong Ji, Gen Luo, Xiaoshuai Sun, Jinsong Su, Xinghao Ding, Chia wen Lin, Qi Tian 引用表达理解REC是计算机视觉中一个新兴的研究热点,它指的是在给定文本描述的情况下检测图像中的目标区域。大多数现有的REC方法遵循多级流水线,这在计算上是昂贵的,并且极大地限制了REC的应用。在本文中,我们提出了一种针对实时REC的单阶段模型,称为实时全球推断网络RealGIN。 RealGIN通过两种创新设计,即自适应特征选择AFS和全球关注解决方案部门GARAN,解决了REC中的多样性和复杂性问题。 AFS自适应融合不同语义级别的功能,以处理表达式的各种内容。 GARAN使用文本功能作为枢纽,从所有区域收集与表达相关的视觉信息,然后有选择地将这些信息传播回所有区域,这为建模表达中的复杂语言条件提供了足够的上下文。在五个基准数据集(即RefCOCO,RefCOCO,RefCOCOg,ReferIt和Flickr30k)上,拟议的RealGIN优于大多数以前的工作,并且与最先进的方法(即MAttNet)相比具有非常有竞争力的性能。最重要的是,在相同的硬件下,RealGIN可以将处理速度提高到现有方法的约10倍。 |
| Dynamic Convolution: Attention over Convolution Kernels Authors Yinpeng Chen, Xiyang Dai, Mengchen Liu, Dongdong Chen, Lu Yuan, Zicheng Liu 轻量级卷积神经网络的CNN性能低下,因为它们的低计算预算限制了CNN的卷积层深度和通道宽度数量,从而限制了表示能力。为了解决这个问题,我们提出了动态卷积,一种新的设计,可以在不增加网络深度或宽度的情况下增加模型的复杂性。动态卷积不是基于每层使用单个卷积内核,而是根据它们的注意力动态聚合多个并行卷积内核,这些依赖于输入。组装多个内核不仅由于内核尺寸小而在计算上很有效,而且由于这些内核通过注意力以非线性方式聚合,因此具有更大的表示能力。通过简单地将动态卷积用于最先进的MobilenetV3 Small体系结构,ImageNet分类的前1个精度仅增加了4个额外的FLOP即可提高2.3,而在COCO关键点检测上可实现2.9 AP增益。 |
| Digital Twin: Acquiring High-Fidelity 3D Avatar from a Single Image Authors Ruizhe Wang, Chih Fan Chen, Hao Peng, Xudong Liu, Oliver Liu, Xin Li 我们提出一种从单个图像生成具有高分辨率UV纹理贴图的高保真3D面部头像的方法。为了估计人脸的几何形状,我们使用深度神经网络直接根据给定图像预测3D人脸模型的顶点坐标。通过非刚性变形过程进一步完善了3D脸部几何形状,以便在纹理投影之前更准确地捕获脸部界标。我们方法的一个关键新颖之处是,在使用高质量渲染引擎综合生成的面部图像上训练形状回归网络。此外,我们的形状估算器充分利用了从数百万张脸部图像中获悉的深层脸部识别特征的判别能力。我们进行了广泛的实验,以证明我们优化的2D到3D渲染方法的优越性,尤其是其在现实世界中自拍图像上的出色泛化特性。我们提出的从2D图像渲染3D化身的系统具有广泛的应用,从虚拟增强现实VR AR和远程精神病学到人机交互和社交网络。 |
| DAVID: Dual-Attentional Video Deblurring Authors Junru Wu, Xiang Yu, Ding Liu, Manmohan Chandraker, Zhangyang Wang 盲视频去模糊可以从模糊序列中恢复清晰的帧,而无需任何先验。这是一项具有挑战性的任务,因为由于相机抖动,物体移动和散焦造成的模糊在时间和空间维度上都是异质的。传统方法在具有单一模糊水平的合成数据集上进行训练,因此无法在各个模糊水平上很好地概括。为了解决这一挑战,我们提出了一种双重注意机制,以动态聚合时间线索以进行端到端可训练网络结构的去模糊处理。具体而言,内部注意模块自适应地选择最佳时间尺度以恢复清晰的中心帧。外部注意模块从几个针对不同模糊级别设计的内部注意模块中,自适应地聚合和优化多个清晰的帧估计。为了训练和评估更多不同的模糊严重性级别,我们提出了一个具有挑战性的DVD数据集,该数据集是通过合并具有不同时间窗口的帧从原始DVD视频集生成的。我们的框架在这个更具挑战性的数据集上始终获得了更好的性能,同时在原始DVD基准上获得了具有竞争力的结果。广泛的烧蚀研究和定性可视化进一步证明了我们的方法在处理真实视频模糊方面的优势。 |
| Spatio-Temporal Pyramid Graph Convolutions for Human Action Recognition and Postural Assessment Authors Behnoosh Parsa, Athma Narayanan, Behzad Dariush 识别人类行为以及与对象和环境的关联交互是计算机视觉中的一个重要问题,因为它在各种领域中都有潜在的应用。最通用的方法可以推广到各种环境,并处理混乱的背景,遮挡和视点变化。其中,基于图卷积网络的从骨架中提取特征的方法表现出了令人鼓舞的性能。在本文中,我们提出了一种新颖的时空金字塔图卷积网络ST PGN,用于人体工学风险评估的在线动作识别,可以使用骨架特征层次中所有级别的特征。所提出的算法优于在两个通常用于姿势评估TUM和UW IOM的公共基准数据集中测试的最新动作识别算法。我们还介绍了通过在线动作识别技术增强姿势评估方法的渠道。最后,所提出的算法与传统的人体工学风险指数REBA集成在一起,以证明其在职业安全中评估肌肉骨骼疾病的潜在价值。 |
| Improved Few-Shot Visual Classification Authors Peyman Bateni, Raghav Goyal, Vaden Masrani, Frank Wood, Leonid Sigal 很少有镜头学习是计算机视觉中的一项基本任务,它有望减轻对详尽标记数据的需求。迄今为止,大多数镜头学习方法都集中在逐渐复杂的神经特征提取器和分类器适应策略上,以及对任务定义本身的改进。在本文中,我们探索一种假设,即基于简单类协方差的距离度量(即Mahalanobis距离)已被应用到最先进的镜头学习方法中,而CNAPS本身可以带来显着的性能改善。我们还发现,有可能学习自适应特征提取器,该提取器允许从令人惊讶的少量样本中对该度量所需的高维特征协方差进行有用的估计。我们工作的结果是新的简单CNAPS体系结构,其可训练参数比CNAPS少多达9.2,并且在标准的少量镜头图像分类基准数据集上的性能比最新技术好6.1。 |
| Self-Supervised 3D Keypoint Learning for Ego-motion Estimation Authors Jiexiong Tang, Rares Ambrus, Vitor Guizilini, Sudeep Pillai, Hanme Kim, Adrien Gaidon 对于基于特征的SLAM和SfM,生成可靠的照明和视点不变关键点至关重要。基于现有技术的学习方法通常依赖于通过采用单应性适配来创建2D合成视图的方式生成训练样本。尽管这样的方法琐碎地解决了视图之间的数据关联,但是它们无法有效地从真实照明和非平面3D场景中学习。在这项工作中,我们提出了一种完全自我监督的方法,通过结合可区别的姿势估计模块来完全从未标记的视频中学习深度感知关键点文本,该模块联合优化了关键点及其在“运动结构”设置中的深度。我们介绍了3D多视图自适应,这是一种利用视频中的时间上下文以点对点可区分方式自我监控关键点检测和匹配的技术。最后,我们展示了如何将完全自我监督的关键点检测和描述网络作为前端简单地合并到强大而准确的最新视觉里程表框架中。 |
| Deep Distance Transform for Tubular Structure Segmentation in CT Scans Authors Yan Wang, Xu Wei, Fengze Liu, Jieneng Chen, Yuyin Zhou, Wei Shen, Elliot K. Fishman, Alan L. Yuille 医学图像中的管状结构分割,例如在CT扫描中分割血管,是使用计算机协助筛查相关疾病早期阶段的重要步骤。但是由于对比度差,噪声和背景复杂等问题,CT扫描中的自动管状结构分割是一个具有挑战性的问题。管状结构通常具有圆柱状的形状,可以通过其骨架半径和横截面半径刻度很好地表示。受此启发,我们提出了一种几何感知的管状结构分割方法“深距离变换DDT”,该方法结合了用于骨架化的经典距离变换和现代深度分割网络的直觉。 DDT首先学习多任务网络,以预测管状结构和距离图的分割蒙版。图中的每个值表示从每个管状结构体素到管状结构表面的距离。然后,通过利用从距离图重新构造的形状来细化分割蒙版。我们将DDT应用于六个医学图像数据集。实验表明,1 DDT可以显着提高管状结构的分割性能,例如,通过DSC进行的胰管分割可改善13倍以上的改善,而2 DDT还可提供管状结构的几何尺寸,这对于临床诊断非常重要,例如横截面胰管的规模可能是胰腺癌的指标。 |
| Sparse and redundant signal representations for x-ray computed tomography Authors Davood Karimi 图像模型是所有图像处理任务的核心。没有强大的模型,数字图像处理的巨大进步将无法实现,而模型本身会随着时间而发展。在过去的十年中,基于补丁的模型已经成为自然图像最有效的模型之一。在许多图像处理任务中,基于补丁的方法优于其他竞争方法。这些发展之时正值强大的计算资源的日益普及和对电离辐射对健康风险的日益关注促使对计算机断层CT CT图像处理算法进行研究的时候。本文的目的是解释基于补丁的方法的原理,并回顾它们在CT中的最新应用。我们回顾了基于补丁的图像处理中的核心概念,并解释了一些最新的算法,重点是与CT更相关的方面。然后,我们回顾一些基于补丁的方法在CT中的最新应用。 |
| Bilinear Models for Machine Learning Authors Tayssir Doghri, Leszek Szczecinski, Jacob Benesty, Amar Mitiche 在这项工作中,我们定义并分析了双线性模型,该模型替代了许多机器学习ML构建块中使用的常规线性运算。主要思想是设计适合其所处理对象的ML算法。在单色图像的情况下,我们表明双线性运算比忽略像素之间空间关系的常规线性运算更好地利用了图像的结构。这转化为产生相同性能所需的参数数量明显减少。我们在MNIST数据集中显示了分类的数值示例。 |
| ClusterFit: Improving Generalization of Visual Representations Authors Xueting Yan, Ishan Misra, Abhinav Gupta, Deepti Ghadiyaram, Dhruv Mahajan 在一些计算机视觉任务中,具有弱监督和自我监督策略的预训练卷积神经网络正变得越来越流行。然而,由于缺乏强的判别信号,这些学习的表示可能过度适合于预训练目标,例如,标签预测,并且不能很好地推广到下游任务。在这项工作中,我们提出了一个简单的策略ClusterFit CF,以提高训练前学习的视觉表示的鲁棒性。给定一个数据集,我们使用k均值从预先训练的网络中提取其特征进行聚类,然后使用聚类分配作为伪标签从该数据集的头开始重新训练新的网络。我们根据经验表明,聚类有助于从提取的特征中减少训练前任务的特定信息,从而最大程度地减少对其的过度拟合。我们的方法可以扩展到弱和自我监督的不同预训练框架,模态图像和视频以及预训练任务的对象和动作分类。通过对11个不同词汇和粒度的不同目标数据集进行的广泛迁移学习实验,我们证明,与最先进的大规模亿万亿弱监督图像和视频模型以及自我监督图像模型相比,ClusterFit显着提高了表示质量。 |
| A Neural Network Based on the Johnson $S_\mathrm{U}$ Translation System and Related Application to Electromyogram Classification Authors Hideaki Hayashi, Taro Shibanoki, Toshio Tsuji 肌电图肌电图分类是基于肌电图的控制系统中的一项关键技术。现有的EMG分类方法未考虑分布具有偏斜度和峰度的EMG特征的特征,从而导致诸如需要超参数调整的缺点。在本文中,我们提出了一种基于Johnson S mathrm U翻译系统的神经网络,该系统能够表示偏度和峰度的分布。 Johnson系统是一种规范化转换,可将非正态数据转换为正态分布,从而能够表示各种分布。在这项研究中,基于对数Johnson Johnson S mathrm U翻译系统的判别模型使用对数线性化转换为系数和输入向量的线性组合。然后将其合并到神经网络结构中,从而允许计算每个类别的输入向量的后验概率,并确定模型参数作为网络的权重系数。从理论上保证了网络学习融合的唯一性。在实验中,使用人工生成的数据评估了所建议网络对包括偏度和峰度的分布的适用性。还通过EMG分类实验评估了其对实际生物学数据的适用性。结果表明,所提出的网络无需超参数优化即可实现较高的分类性能。 |
| cGANs with Multi-Hinge Loss Authors Ilya Kavalerov, Wojciech Czaja, Rama Chellappa 我们提出了一种新的算法,通过对常用铰链损失的多类归纳将类条件信息纳入GAN的判别器中。我们的方法与大多数GAN框架形成对比,因为我们针对具有1个损失函数的K 1类训练单个分类器,而不是真正的假鉴别器或鉴别器分类器对。我们表明,在监督和半监督的环境中,同时学习单个好的分类器和最新的生成器状态是可能的。通过我们对多铰链损耗的修改,我们能够将最新的CIFAR10 IS FID提升至9.58 6.40,将CIFAR100 IS FID提升至14.36 13.32,将STL10 IS FID提升至12.16 17.44。用PyTorch编写的代码可在以下位置获得 |
| Parallel Total Variation Distance Estimation with Neural Networks for Merging Over-Clusterings Authors Christian Reiser, J rg Schl tterer, Michael Granitzer 我们考虑数据集被过度划分为k个聚类的初始情况,并寻求一种独立于域的方式来合并这些初始聚类。我们确定总变化距离TVD适合此目标。通过利用TVD与贝叶斯精度的关系,我们展示了如何使用神经网络并行估计所有成对集群之间的TVD。至关重要的是,通过将所需的输出神经元数量从k 2减少到k,减少了所需的存储空间。通过对ImageNet子集的聚类进行实际获得的结果表明,与依赖于最新的无监督表示形式获得的合并决策相比,我们的TVD估计得出的合并决策更好。通过在点云数据集上对其进行评估,可以验证该方法的通用性。 |
| Naive Gabor Networks Authors Chenying Liu, Jun Li, Lin He, Antonio J. Plaza, Shutao Li, Bo Li 在本文中,我们介绍了朴素的Gabor网络或Gabor网络,这在文献中是第一次以Gabor滤波器的形式严格设计和学习卷积核,旨在减少参数数量并限制卷积神经的解空间。网络CNN。与其他基于Gabor的方法相比,Gabor Nets利用正弦谐波的相位偏移来控制Gabor核的频率特性,从而能够根据频率角度的数据调整卷积核。此外,还实现了Gabor核的快速一维分解,从而使二维卷积的原始二次计算复杂度变为线性。我们在两个遥感高光谱基准上评估了我们最新开发的Gabor网络,表明我们的模型架构可以显着提高CNN的收敛速度和性能,尤其是在训练样本非常有限的情况下。 |
| InfoCNF: An Efficient Conditional Continuous Normalizing Flow with Adaptive Solvers Authors Tan M. Nguyen, Animesh Garg, Richard G. Baraniuk, Anima Anandkumar 连续归一化流由于CNF具有可逆性和精确的似然估计能力,因此它们已成为有前景的深度生成模型,可用于各种任务。但是,由于模型生成的高维潜码(需要与输入数据具有相同的大小),因此根据条件信号生成和下游预测任务对目标信号进行CNF调整效率很低。在本文中,我们提出了InfoCNF,这是一种有效的条件CNF,它将潜在空间划分为特定于类的监督代码和在所有类之间共享的无监督代码,以有效利用标记信息。由于划分策略略微增加了功能评估NFE的数量,因此InfoCNF还采用门控网络来学习其常微分方程ODE求解器的容错能力,以提高速度和性能。我们凭经验表明,InfoCNF可以提高基准测试的准确性,同时产生可比的可能性评分并减少CIFAR10上的NFE。此外,在InfoCNF中对时间序列数据应用相同的分区策略有助于提高外推性能。 |
| Video Motion Capture from the Part Confidence Maps of Multi-Camera Images by Spatiotemporal Filtering Using the Human Skeletal Model Authors Takuya Ohashi, Yosuke Ikegami, Kazuki Yamamoto, Wataru Takano, Yoshihiko Nakamura 本文讨论了视频运动捕获,即从多摄像机图像对人体运动进行3D重建。从每个摄像机图像计算出零件置信度图后,将所提出的时空滤波器应用于为人体运动分析提供准确且平滑的人体运动数据。时空滤波器使用人体骨骼,并在两个时间逆运动学计算中混合了时间平滑。实验结果表明,常规运动的平均每个关节位置误差为26.1mm,反向运动的平均为38.8mm。 |
| AI2D-RST: A multimodal corpus of 1000 primary school science diagrams Authors Tuomo Hiippala, Malihe Alikhani, Jonas Haverinen, Timo Kalliokoski, Evanfiya Logacheva, Serafina Orekhova, Aino Tuomainen, Matthew Stone, John A. Bateman 本文介绍AI2D RST,这是一个包含1000种英语图表的多模式语料库,代表了小学自然科学中的主题,例如食物网,生命周期,月相和人类生理学。该语料库基于Allen Institute for AI人工智能图AI2D数据集,该图是带有人群来源描述的图的集合,其最初是为诸如自动图理解和视觉问题解答之类的计算任务而开发的。 AI2D RST语料库以AI2D中的图布局分割为基础,提供了一个新的多层注释模式,该模式提供了对其多峰结构的丰富描述。由受过训练的专家注释,这些层描述1将图元素划分为感知单元,2将由图元素(如箭头和线条)建立的连接,以及3用修辞结构理论RST描述的图元素之间的话语关系。 AI2D RST中的每个注释层均使用图形表示。该语料库可免费用于研究和教学。 |
| Less Confusion More Transferable: Minimum Class Confusion for Versatile Domain Adaptation Authors Ying Jin, Ximei Wang, Mingsheng Long, Jianmin Wang 域自适应DA将学习模型从标记的源域转移到遵循不同分布的未标记的目标域。存在多种受标签集和域配置约束的DA方案,包括封闭集和部分集DA以及多源和多目标DA。值得注意的是,现有的DA方法通常仅针对特定方案而设计,而对于不适合它们的方案可能表现不佳。朝着一种通用的DA方法,应该探索除域对准以外的更通用的电感偏置。在本文中,我们深入研究了现有方法类混淆的缺失部分,即分类器混淆了目标示例正确和歧义类之间的预测的趋势。我们揭露,在所有上述情况下,更少的类混淆明确表明更多的类可区分性,并隐含更多的域可转让性。 |
| 6-DOF Grasping for Target-driven Object Manipulation in Clutter Authors Adithyavairavan Murali, Arsalan Mousavian, Clemens Eppner, Chris Paxton, Dieter Fox 在混乱的环境中抓握是一项基本但具有挑战性的机器人技能。它既需要对看不见的物体部分进行推理,又需要与机械手潜在的碰撞。大多数现有的数据驱动方法通过将自己限制为自上而下的平面抓取来避免此问题,这对于许多实际场景来说是不够的,并且极大地限制了可能的抓取。我们提出了一种从局部点云观测中为杂乱场景中的任何所需对象计划6自由度抓取的方法。我们的方法获得了80.3的成功抓取成功,性能比基线方法高17.6,并且在一个真实的机器人平台上清除了9个混乱的桌子场景,这些场景包含23个未知对象和51个拾取项。通过使用学习到的冲突检查模块,我们甚至可以推理出有效的抓取顺序来检索无法立即访问的对象。补充视频可以在下面找到 |
| Deep Learning-Based Feature-Aware Data Modeling for Complex Physics Simulations Authors Qun Liu, Subhashis Hazarika, John M. Patchett, James Paul Ahrens, Ayan Biswas 数据建模和现场还原非常重要。用于原位数据分析和归纳的特征驱动方法是未来百亿亿次计算机的优先事项,因为此类方法目前很少。我们研究了基于深度学习的工作流,该工作流使用自动编码器来针对原位数据处理。我们提出了在残差密集块RRDB中集成残差自动编码器以获得更好的性能。我们提出的框架将测试数据从每3D体积时间2.1 MB压缩到66 KB。 |
| Privacy-Preserving Inference in Machine Learning Services Using Trusted Execution Environments Authors Krishna Giri Narra, Zhifeng Lin, Yongqin Wang, Keshav Balasubramaniam, Murali Annavaram 这项工作提出了Origami,它通过结合安全区执行,加密盲法和散布基于加速器的计算,为大型深度神经网络DNN模型提供了隐私保护推断。折纸将ML模型划分为多个分区。第一分区在SGX安全区域内接收加密的用户输入。安全区对输入解密,然后对输入数据和模型参数应用加密盲法。加密盲是一种增加噪声以混淆数据的技术。折纸会将混淆后的数据发送到不受信任的GPU CPU进行计算。 SGX飞地将盲目性和去盲目性因素保持私有状态,从而在计算被卸载到GPU CPU时,可以防止任何对手对数据进行消噪处理。计算出的输出返回到飞地,飞地使用专用于SGX内存储的非致盲因子对噪声数据进行解码。像在先前的工作Slalom中所做的那样,可以为每个DNN层重复此过程。 |
| Comparison of Neuronal Attention Models Authors Mohamed Karim Belaid 用于图像处理的最新模型使用卷积神经网络CNN,该网络需要对输入图像进行逐像素分析。此方法效果很好。但是,如果我们有大图像,那会很费时间。为了提高性能,通过改善训练时间或准确性,我们需要一种尺寸无关的方法。作为解决方案,我们可以添加神经元注意力模型NAM。这种新方法的强大之处在于它可以有效地从初始图像中选择几个小区域进行聚焦。本文的目的是解释和测试NAM的每个参数。 |
| Temporal Wasserstein non-negative matrix factorization for non-rigid motion segmentation and spatiotemporal deconvolution Authors Erdem Varol, Amin Nejatbakhsh, Conor McGrory 自然图像的运动分割通常依赖于密集的光流来产生屈服点轨迹,这些屈服点轨迹可以通过包括光谱聚类或最低成本的多次切割在内的各种方式归为一组。但是,在诸如荧光显微镜或钙成像的生物成像场景中,信噪比受到损害并且强度发生波动,光流可能难以估算。为此,我们提出了一种基于最佳传输的运动分割方法,该方法将视频帧建模为表示为直方图的时变质量。因此,我们将运动分割作为具有Wasserstein度量损失的时间非线性矩阵分解问题。该分解的字典元素可将运动分割为相干对象,而加载系数允许捕获运动对象随时间变化的强度信号。我们证明了拟议的范式在模拟的多电极漂移情况下的使用,以及线虫秀丽隐杆线虫C.elegans的钙指示荧光显微镜视频。后者的应用具有在自由进行的行为中提取动物神经活动的附加效用。 |
| Cascaded Deep Neural Networks for Retinal Layer Segmentation of Optical Coherence Tomography with Fluid Presence Authors Donghuan Lu, Morgan Heisler, Da Ma, Setareh Dabiri, Sieun Lee, Gavin Weiguang Ding, Marinko V. Sarunic, Mirza Faisal Beg 光学相干断层扫描OCT是一种非侵入性成像技术,可以提供眼睛内部结构的微米分辨率横截面图像。它被广泛用于诊断具有视网膜改变的眼科疾病,例如层变形和积液。在本文中,提出了一种新颖的框架来分割存在液体的视网膜层。这项研究的主要贡献有两个方面1我们开发了一个级联网络框架以合并现有的结构知识2我们提出了一种基于U Net和完全卷积网络的新型深度神经网络,称为LF UNet。交叉验证实验证明,与现有方法相比,所提出的LF UNet具有更好的性能,并且不管网络如何,结合相对距离图结构先验信息都可以进一步提高性能。 |
| Principal Component Properties of Adversarial Samples Authors Malhar Jere, Sandro Herbig, Christine Lind, Farinaz Koushanfar 已经发现,用于图像分类的深度神经网络容易受到对抗性样本的攻击,对抗性样本包括添加到良性图像中的次知觉噪声,这些噪声容易使愚弄训练有素的神经网络,从而对其商业部署构成重大风险。在这项工作中,我们通过镜头分析对抗性样本对每个图像主要成分的贡献,这与以前的作者在整个数据集中执行PCA的工作不同。我们研究了在ImageNet上训练的许多最先进的深度神经网络,以及针对每个网络的几种攻击。我们的结果从经验上证明,几次攻击中的对抗性样本对神经网络输入的主要成分的贡献具有相似的属性。我们提出了一种用于神经网络的新度量,以衡量其对对抗性样本的鲁棒性,称为k,p点。对于在ImageNet上训练的模型,我们利用此指标在检测对抗样本时达到93.36的准确性,而与结构和攻击类型无关。 |
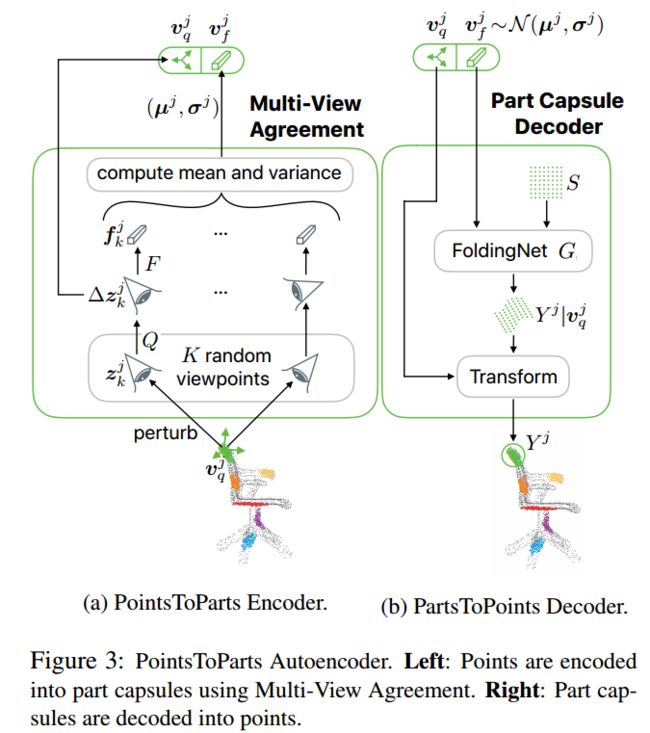
| Geometric Capsule Autoencoders for 3D Point Clouds Authors Nitish Srivastava, Hanlin Goh, Ruslan Salakhutdinov 我们提出了一种使用3D点云学习对象表示的方法,该方法使用几何可解释的隐藏单元束(称为几何胶囊)来进行学习。每个几何囊表示一个视觉实体,例如一个对象或一个零件,并由一个姿势和一个特征两个部分组成。姿势编码实体的位置,而特征编码实体的位置。我们使用这些胶囊来构造几何胶囊自动编码器,该编码器学会以无监督的方式将3D点分组为局部小的局部曲面,然后将这些局部分组为整个对象。我们新颖的多视图协议投票机制用于发现对象的规范姿势及其姿势不变特征向量。使用ShapeNet和ModelNet40数据集,我们分析了所获学习表示的属性,并显示了获得多张选票同意的好处。我们对任意旋转的对象执行对齐和检索,以评估模型的对象识别和规范的姿态恢复能力,并获得有见地的结果。 |
| Chinese Abs From Machine Translation |
Papers from arxiv.org
更多精彩请移步主页

pic from pexels.com