【今日CV 计算机视觉论文速览 第135期】Mon, 24 Jun 2019
今日CS.CV 计算机视觉论文速览
Mon, 24 Jun 2019
Totally 16 papers
?上期速览✈更多精彩请移步主页

Interesting:
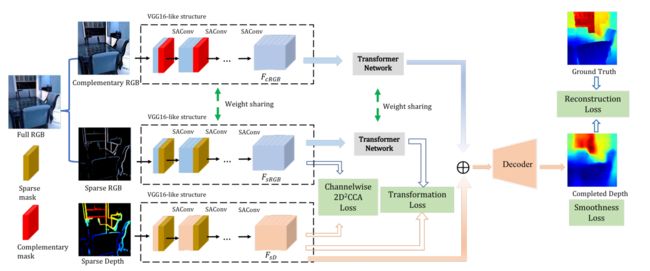
?RGB-D摄像头的稀疏深度图补全, 这篇文章提出了一种基于相关性对稀疏深度图进行补全的网络,充分利用了RGB的信息来进行补充。首先提出了匹配深度和RGB图的方法(2D deep canonical correlation analysis, 2D2CCA),随后将RGB的特征映射到深度空间中去,补偿缺失的深度信息。分别使用了Lidar信息和深度相机的信息进行了实验。(from 南加州大学)
研究中提出的模型如下图所示,分别从深度图和RGB图中利用稀疏mask提取了对应的信息,和互补信息:
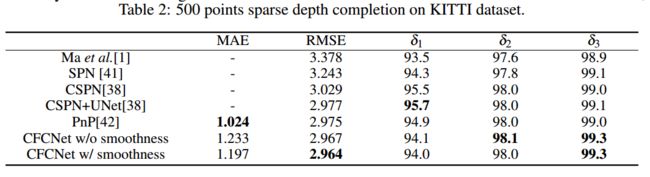
下图显示了稀疏注意力卷积卷积操作和从深度图中采样的操作,分别为均匀采样、立体稀疏器采样和ORB采样:

最终在室外KITTI和cityscape数据集上的效果:

和室内NYUv2的效果:

测评度量以及测评的方法:

ref:SAConv is inspired by local attention mask [31].
三种稀疏采样方法值得学习:
Uniform sparsifier uniformly samples the dense depth map, simulating the scanning effect caused by LiDAR which is nearly uniform.
Stereo sparsifier only samples the depth measurements on the edge or textured objects in the scene to simulate the sparse patterns generated by stereo matching or direct VSLAM.
ORB sparsifier only maintains the depth measurements according to the location of ORB features in the corresponding RGB images. ORB sparsifier simulates the output sparse depth map from feature based VSLAM.
?像素级的深度估计基准方法和数据, 研究人员提出了一个高精度的深度估计算法测评基准,包括了多种天气情况,具有高分辨率50Mcamera和25‘’的角分辨率。(from )

相关方法ref:Monodepth [14] as representative for monocular depth estimation, semi-global matching (SGM) [17] for traditional stereo and PSMnet [4] for deep stereo algorithms, and Sparse2Dense [30] as a depth completion method for lidar measurements using RGB image
data.
Daily Computer Vision Papers
| Fully Decoupled Neural Network Learning Using Delayed Gradients Authors Huiping Zhuang, Yi Wang, Qinglai Liu, Zhiping Lin 使用反向传播BP来训练神经网络需要连续地传递激活和梯度,这迫使网络模块以同步方式工作。这被认为是锁定,即从BP继承的前向,后向和更新锁定。在本文中,我们提出了一种完全解耦的训练方案,使用延迟梯度FDG来打破所有这些锁定。所提出的方法将神经网络分成多个模块,这些模块在不同的GPU中独立地和异步地训练。我们还引入了梯度收缩过程,以减少由延迟梯度引起的陈旧梯度效应。此外,我们证明了所提出的FDG算法保证了训练期间的统计收敛。通过训练深度卷积神经网络来执行实验,以在基准数据集上执行分类任务。所提出的FDG能够训练非常深的网络100层和非常大的网络3500万个参数,具有显着的速度增益,同时优于现有技术方法和标准BP。 |
| Evolution Attack On Neural Networks Authors YiGui Luo, RuiJia Yang, Wei Sha, WeiYi Ding, YouTeng Sun, YiSi Wang 已经进行了许多研究来证明神经网络对敌对范例的脆弱性。训练有素且表现良好的模型可以被视觉上不可察觉的扰动所欺骗,即,在轻微扰动之后,原始正确分类的图像可能被错误分类。在本文中,我们提出了一种使用进化算法攻击此类网络的黑盒策略。首先,我们将对抗性示例的生成形式化为扰动的优化问题,该扰动表示在每个像素处添加到原始图像的噪声。为了以黑盒方式解决这个优化问题,我们发现进化算法完全符合我们的要求,因为它可以在没有任何梯度信息的情况下工作。因此,我们测试各种演化算法,包括简单的遗传算法,参数探索政策梯度,OpenAI演化策略和协方差矩阵自适应演化策略。实验结果表明,协方差矩阵自适应进化策略在该优化问题中表现最佳。此外,我们还进行了几项实验,以探索不同正则化对提高对抗性例子质量的影响。 |
| Acute Lymphoblastic Leukemia Classification from Microscopic Images using Convolutional Neural Networks Authors Jonas Prellberg, Oliver Kramer 当用于流式细胞术的昂贵设备不可用时,检查白血病的血液显微图像是必要的。自动化系统可以减轻医疗专家执行此检查的负担,并且可能对快速筛查大量患者特别有帮助。我们使用具有挤压和激励模块的ResNeXt卷积神经网络提出了一种简单而有效的分类方法。该方法在C NMC在线挑战中进行了评估,并在测试集上获得了88.91的加权F1评分。代码可在 |
| ***Deep RGB-D Canonical Correlation Analysis For Sparse Depth Completion Authors Yiqi Zhong, Cho Ying Wu, Suya You, Ulrich Neumann 在本文中,我们提出了完成网络CFCNet,一个端到端深度模型,用于使用RGB信息进行稀疏深度完成任务。我们首先提出2D深度正则相关分析作为网络约束,以确保RGB和深度编码器捕获最相似的语义。然后,我们将RGB特征转换为深度域。互补RGB信息用于完成缺失的深度信息。我们在室外和室内场景数据集上进行了大量实验。对于室外场景,使用KITTI和Cityscape,分别使用激光雷达和立体相机捕获深度信息。对于室内场景,我们使用具有立体ORB特征稀疏器和SLAM RGBD数据集的NYUv2。实验证明我们的CFCNet优于使用这些数据集的最新技术方法。与SLAM RGBD数据集上的最新方法相比,我们的最佳结果将精确估计的百分比从13.03提高到58.89 394。 |
| **FBK-HUPBA Submission to the EPIC-Kitchens 2019 Action Recognition Challenge Authors Swathikiran Sudhakaran, Sergio Escalera, Oswald Lanz 在本报告中,我们描述了我们提交EPIC Kitchens 2019行动认可挑战的技术细节。为了参与挑战,我们开发了许多CNN LSTA 3和HF TSN 2变体,并提交了来自这两个模型系列编译的集合的预测。我们的提交在公共排行榜上以团队名称FBK HUPBA显示,在S1设置上获得了35.54的前1个动作识别准确度,在S2设置上获得了20.25。 |
| ***Pixel-Accurate Depth Evaluation in Realistic Driving Scenarios Authors Tobias Gruber, Mario Bijelic, Felix Heide, Werner Ritter, Klaus Dietmayer 这项工作提供了深度估计和完成的评估基准,使用高分辨率深度测量,角度分辨率高达25弧秒,类似于每像素深度可用的50万像素摄像头。现有的数据集,例如KITTI基准,仅提供稀疏参考测量,其具有较低角度分辨率的数量级,这些稀疏测量被现有深度估计方法视为地面实况。我们建议在日,夜,雾,雨等不同天气条件下记录的四种特征汽车场景中进行评估。因此,我们的基准测试可以评估深度感应方法对恶劣天气和不同驾驶条件的稳健性。使用提出的评估数据,我们表明当前的立体方法提供了比单眼方法和恶劣天气下激光雷达完成更加稳定的深度估计。 |
| Rules of the Road: Predicting Driving Behavior with a Convolutional Model of Semantic Interactions Authors Joey Hong, Benjamin Sapp, James Philbin 我们关注的是在复杂的真实世界驾驶场景中预测实体未来状态的问题。以前的研究使用低水平信号来预测短时间范围,并没有解决如何利用行业自驾车系统严重依赖的关键资产1大型3D感知工作,提供具有丰富属性的代理的高精度3D状态,2详细准确的环境通道,交通信号灯,人行横道等语义地图。我们提出了一种统一的表示,它在空间网格中编码这种高级语义信息,允许使用深度卷积模型来融合复杂的场景环境。这使得学习实体实体和实体环境交互能够在代理行为的整体时间模型内的每个时间步骤中进行简单的前馈计算。我们提出了使用标准监督学习将未来建模为未来状态分布的不同方法。我们引入了一个新颖的数据集,提供了行业级的丰富感知和语义输入,并且凭经验证明我们可以有效地学习驾驶行为的基本原理。 |
| Predicting Future Opioid Incidences Today Authors Sandipan Choudhuri, Kaustav Basu, Kevin Thomas, Arunabha Sen 根据疾病控制中心疾病预防控制中心的数据,仅在2017年,阿片类药物就已在美国造成72,000多人死亡。尽管在地方,州和联邦层面做出了各种努力,但该流行病的影响正在逐渐恶化,2016年至2017年期间阿片类药物相关死亡人数增加12.5,这一事实证明了这一点。预测分析可以发挥重要作用通过向卫生保健专业人员,决策者和第一响应者等多个层次的利益相关者提供决策工具,在防治艾滋病方面发挥作用。根据过去的数据生成阿片类药物发病率热图,帮助这些利益相关者可视化阿片类药物流行病的深远影响。热图的这种事后创建仅提供回顾性信息,因此,对于当前或未来时间框架中的预防性动作可能不那么有用。在本文中,我们提出了一种新颖的深度神经结构,它可以学习阿片类物质发生率数据中微妙的时空变化,并准确预测未来的热图。我们评估了我们的模型在两个开源数据集上的效果,即Cincinnati Heroin Overdose数据集和ii Connecticut Drug Related Death Dataset。 |
| Backpropagation-Friendly Eigendecomposition Authors Wei Wang, Zheng Dang, Yinlin Hu, Pascal Fua, Mathieu Salzmann 特征分解ED广泛用于深度网络。然而,无论是直接使用ED还是使用Power Iteration方法对其进行近似,其结果的反向传播往往在数值上不稳定,特别是在处理大型矩阵时。虽然可以通过将数据划分为小型和任意组来减轻这种情况,但这样做没有理论依据,并且无法充分利用ED的强大功能。在本文中,我们介绍了一种数值稳定且可微分的方法来利用深度网络中的特征向量。它可以处理大型矩阵而无需拆分它们。我们证明了我们的方法比ZCA白化标准ED和PI更好的稳健性,批量标准化的替代方案,以及PCA去噪,我们将其作为深度网络的新标准化策略引入,旨在进一步降低网络的功能。 |
| Data-Efficient Learning for Sim-to-Real Robotic Grasping using Deep Point Cloud Prediction Networks Authors Xinchen Yan, Mohi Khansari, Jasmine Hsu, Yuanzheng Gong, Yunfei Bai, S ren Pirk, Honglak Lee 为机器人操纵训练深度网络策略是非常昂贵和耗时的,因为它依赖于收集大量的现实世界数据。为了在现实世界中良好地工作,该策略需要查看该任务的许多实例,包括场景中的各种对象布置以及对象几何,纹理,材料和环境照明的变化。 |
| A Fourier Perspective on Model Robustness in Computer Vision Authors Dong Yin, Raphael Gontijo Lopes, Jonathon Shlens, Ekin D. Cubuk, Justin Gilmer 实现分布式转变的稳健性是计算机视觉的长期和具有挑战性的目标。数据增强是一种常用的方法,用于提高健壮性,但是在整个损坏类型中,健壮性增益通常不一致。实际上,在存在随机噪声的情况下提高性能通常会降低其他损坏(例如对比度变化)的性能。了解何时以及为何出现这些类型的权衡取舍是减轻它们的关键一步。为此,我们调查了最近观察到的由高斯数据增强和对抗性训练引起的权衡。我们发现这两种方法都提高了集中在高频域的损坏的鲁棒性,同时降低了集中在低频域的破坏的鲁棒性。这表明通过数据增加来减轻这些权衡的一种方法是使用更多样化的增强集。为此,我们观察到AutoAugment是最近提出的针对清洁精度优化的数据增强策略,它在CIFAR 10 C和ImageNet C基准测试中实现了最先进的稳健性。 |
| SGANVO: Unsupervised Deep Visual Odometry and Depth Estimation with Stacked Generative Adversarial Networks Authors Tuo Feng, Dongbing Gu 最近端到端的无监督深度学习方法已经实现了超出视觉深度和自我运动估计任务的几何方法的效果。这些基于数据的学习方法在一些具有挑战性的场景中表现得更加稳健和准确。编码器解码器网络已广泛用于深度估计,并且RCNN已经在自我运动估计中带来显着改进。此外,最新使用生成性对抗网络GAN的深度和自我运动估计已经证明通过在游戏学习过程中生成图片可以进一步改善估计。本文提出了一种新的无监督网络系统,用于视觉深度和自我运动估计Stacked Generative Adversarial Network SGANVO。它由一堆GAN层组成,其中最低层估计深度和自我运动,而较高层估计空间特征。由于在层上使用循环表示,它还可以捕获时间动态。详情请参见图1。我们选择最常用的KITTI 1数据集进行评估。评估结果表明,我们提出的方法可以产生更好或可比较的深度和自我运动估计结果。 |
| Informative Image Captioning with External Sources of Information Authors Sanqiang Zhao, Piyush Sharma, Tomer Levinboim, Radu Soricut 图像标题应该流畅地呈现给定图像中的基本信息,包括信息性的,细粒度的实体提及以及这些实体交互的方式。然而,当前字幕模型通常经过训练以生成仅包含共同对象名称的字幕,因此不能满足重要的信息量维度。我们提出了一种机制,用于将图像信息与假定由某些上游模型生成的细粒度标签整合到一个标题中,该标题以流畅和信息的方式描述图像。我们介绍了一种基于Transformer的多模式,多编码器模型,它可以摄取图像特征和多个实体标签源。我们证明我们可以学习如何控制输出中这些实体标签的外观,从而产生流畅且信息丰富的字幕。 |
| Synthesizing Images from Spatio-Temporal Representations using Spike-based Backpropagation Authors Deboleena Roy, Priyadarshini Panda, Kaushik Roy 尖峰神经网络SNN为当前的人工神经网络提供了一种有前景的替代方案,以实现低功率事件驱动的神经形态硬件。基于尖峰的神经形态应用需要处理并从时空数据中提取有意义的信息,随着时间的推移表示为一系列尖峰序列。在本文中,我们提出了一种在基于尖峰的环境中从多种模态合成图像的方法。我们使用尖峰自动编码器将图像和音频输入转换为紧凑的时空表示,然后对其进行解码以进行图像合成。为此,我们使用直接训练算法计算输出层膜电位的损失,并通过使用神经元激活函数的S形近似来反向传播它,以实现可微分性。尖峰自动编码器以MNIST和Fashion MNIST为基准,实现了非常低的重建损失,与人工神经网络相当。然后,训练尖峰自动编码器以跨音频和视觉两种模态学习数据的有意义的时空表示。我们通过首先生成,然后利用这种共享的多模态空间时间表示,在基于尖峰的环境中合成来自音频的图像。我们的音频到图像合成模型在将TI 46位音频样本转换为MNIST图像的任务上进行了测试。我们能够以高保真度合成图像,并且该模型实现了针对ANN的竞争性能。 |
| Closing the Accuracy Gap in an Event-Based Visual Recognition Task Authors Bodo R ckauer, Nicolas K nzig, Shih Chii Liu, Tobi Delbruck, Yulia Sandamirskaya 移动和嵌入式应用需要基于神经网络的模式识别系统,以在严格的计算预算下运行良好。与常用的基于帧的同步视觉系统和CNN相比,由基于事件的视觉输入驱动的异步,尖峰神经网络以低延迟响应输入中的稀疏,突出特征,从而在运行时实现高效率。基于事件的数据流的离散性质使得异步神经网络的直接训练具有挑战性。本文研究异步尖峰神经网络,通过从基于帧的数据训练的传统CNN转换获得。作为一个例子,我们考虑CNN训练,以引导机器人跟随移动目标。我们确定了转换的可能缺陷,并演示了所提出的解决方案如何使异步网络的分类准确度仅比原始同步CNN的性能低3,同时要求减少12倍的计算。在应用于简单任务的同时,这项工作是针对机器人应用的低功耗,快速和嵌入式神经网络视觉解决方案迈出的重要一步。 |
| *Automated crater shape retrieval using weakly-supervised deep learning Authors Mohamad Ali Dib, Kristen Menou, Chenchong Zhu, Noah Hammond, Alan P. Jackson 火山口形状确定是一项复杂且耗时的任务,到目前为止已经避免了自动化。我们训练最先进的计算机视觉算法,以识别月球上的陨石坑并检索它们的大小和形状。该模型的计算主干是MaskRCNN,一种实例分割通用框架,可检测图像中的凹坑,同时为每个跟踪其外缘的凹坑生成掩模。然后我们的后处理管道找到与这些掩模最接近的拟合椭圆,允许我们检索火山口椭圆度。我们的模型能够正确识别保留集中的87个已知陨石坑,同时预测我们的训练数据中不存在的数千个额外陨石坑。手动验证这些陨石坑的一部分表明它们中的大多数是真实的,我们将其作为我们模型在学习识别陨石坑时的强度的指标,尽管训练数据不完整。我们的模型预测的火山口大小,椭圆度和深度分布与人类生成的结果一致。该模型允许我们对月球高地和玛丽亚之间的火山口直径和形状分布的差异进行大规模搜索,并且我们排除任何具有高统计显着性的差异。 |
| Chinese Abs From Machine Translation |
Papers from arxiv.org
更多精彩请移步主页
pic from pexels.com