【今日CV 计算机视觉论文速览 第137期】Fri, 28 Jun 2019
今日CS.CV 计算机视觉论文速览
Fri, 28 Jun 2019
Totally 35 papers
?上期速览✈更多精彩请移步主页

Interesting:
?启发式的对抗图像生成, 研究人员提出了一种新方法来探索GANs隐空间,为艺术家提供更好的图像创意生成方式。这篇文章提出了一种新策略,使得创意工作者可以通过选择的数据集和优化控制方法来学习并启发创作过程。研究人员设计了简单的优化方法来寻找超参数使得生成的结果与输入的启发图像最为接近。(from facebook ai research)
研究人员提出的优化方法,使得搜索到的隐变量最为接近来生成与参考图像接近的结果:
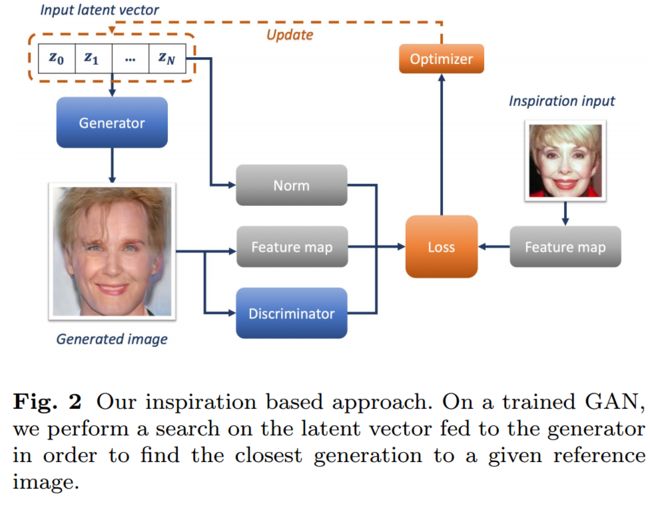
一些通过引导得到的结果:


dataset: Describable Textures Dataset,RTW dataset described in [38],Celeba-HQ dataset ,FashionGen dataset [36]
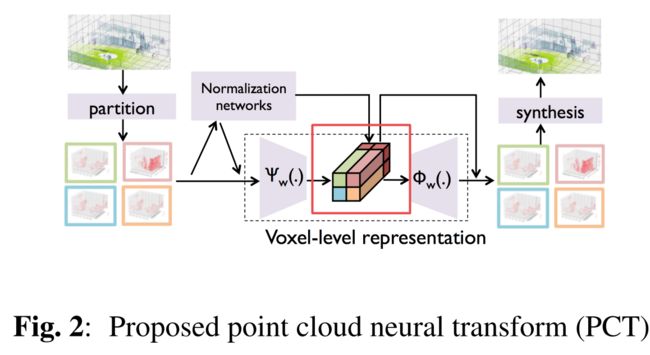
?点云自然变换PCT,一种基于图网络有效表达大规模点云的方法, 结合了体素和学习的方法将三维空间在体素中表示并提出了图网络方法来表示每个点,同时克服了体素表示带来的离散误差和学习表示难以捕捉大规模场景全局方差的缺点。对于大场景下的三维点云表示类似2D图像下的离散余弦变换,可以有效表示点云的全局与细节特征。(from CMU)
点云自然变换的示意图,包括了切分、归一化表示、体素级表示和最后的合成度量过程:
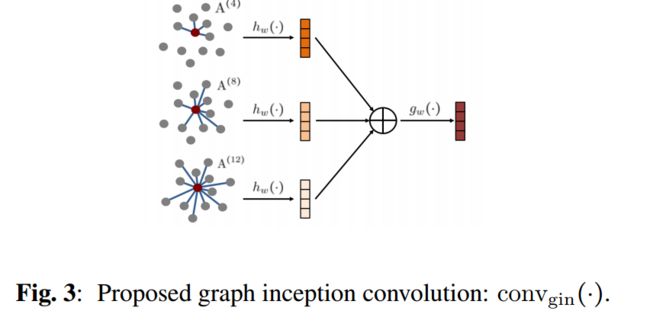
研究人员在模型中提出了图构建卷积的结构,用于从体素中学习编码和嵌入(K最邻近3D点,多个K值来确定最邻近选择数量)。:
ref:
http://www.merl.com/people/schen
https://users.ece.cmu.edu/~sihengc/
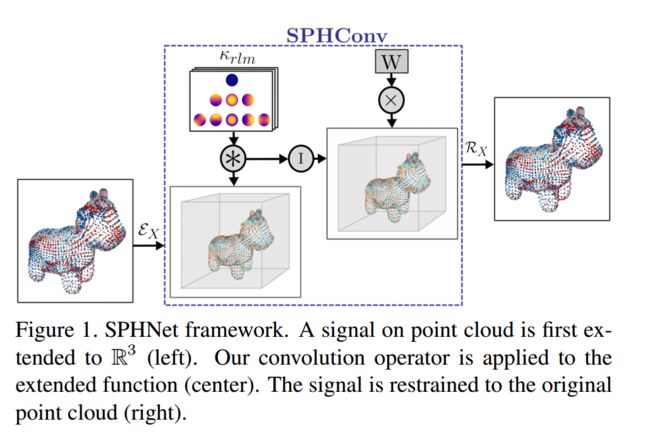
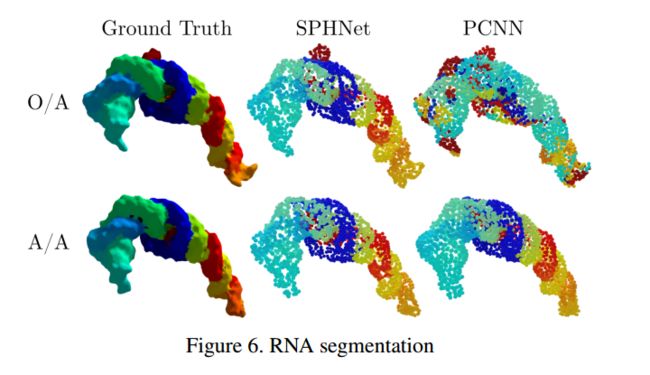
?SPHNet基于球面谐波函数核的旋转不变性点云表示, 提出了一种可以直接操纵点云的选择不变性架构,包括全局、局域都具有不变性,对非刚体十分有用。通过将球谐函数和应用于不同的网络层,来保证刚体运动的不变性,并基于空间剖分的数据结构来引入更有效的池化操作。这种方法对于复杂结构可以灵活高效地处理。(from LIX, Ecole Polytechnique巴黎综合理工)
下图中可以看到,球写函数卷积将信号限制在了Rx空间中(原来的信号空间中):
基于这一方法提出的分类和分割的综述:


针对生物领域RNA分子分割的应用:
注意看这个的relatedwork,包括点云学习和变化不变性的综述。
dataset:D-FAUST dataset,contains scans of 10 different subjects completing various sequences of motions given as meshes with the same structure and indexing.
RNAs (5srRNAs), downloaded from the PDB database [3]
ref: https://www.lix.polytechnique.fr/
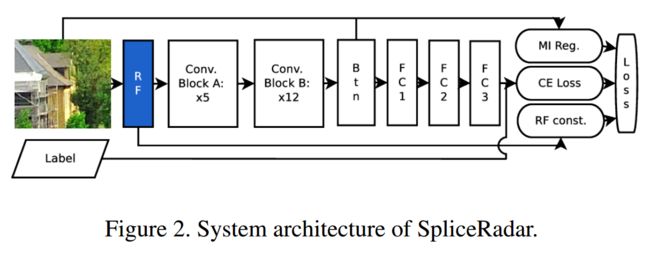
?SpliceRadar一种检测图像被修改过的方法, (from Verisk AI, Verisk Analytics,VAST)
用于检测出图像中被修改的部分:

这一方法的架构,包括了rich filter,语义边缘抑制等方法:
site:http://www.grip.unina.it/research/83-image-forensics/100-splicebuster.html
https://arxiv.org/pdf/1906.11663.pdf
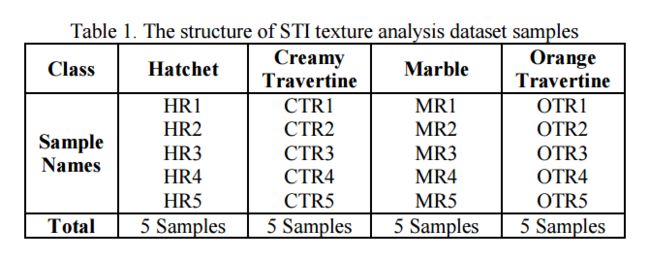
?表面纹理缺陷检测的数据集, (from Islamic Azad University)






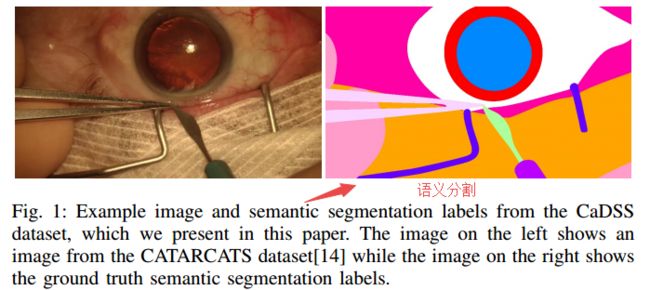
?CaDSS白内障语义分割的数据集, (from Digital Surgery Ltd UCL)
https://cataracts.grand-challenge.org/
Daily Computer Vision Papers
| A Generalized Framework for Agglomerative Clustering of Signed Graphs applied to Instance Segmentation Authors Alberto Bailoni, Constantin Pape, Steffen Wolf, Thorsten Beier, Anna Kreshuk, Fred A. Hamprecht 我们提出了一种新颖的理论框架,将层次凝聚聚类的算法推广到加权图,其中节点之间具有吸引力和排斥性的相互作用。该框架定义了GASP,一种用于签名图分区的通用算法,并允许我们探索不同链接标准的许多组合,并且不能链接约束。我们证明了现有聚类方法与其中一些组合的等价性,并为未经研究的组合引入了新算法。进行广泛的比较以在图像中的实例分割的背景下评估聚类算法的性质,包括对噪声和效率的鲁棒性。我们展示了我们框架中提出的一种新算法如何优于所有先前已知的有符号图的凝聚方法,包括竞争性CREMI 2016 EM分割基准和CityScapes数据集。 |
| Detection of small changes in medical and random-dot images comparing self-organizing map performance to human detection Authors John Wandeto, Henry Nyongesa, Yves Remond, Birgitta Dresp Langley 放射科医师使用时间序列的医学图像来监测患者病情的进展。他们比较从图像序列中收集的信息,以获得对病变进展或缓解的了解,从而评估患者病情的进展或对治疗的反应。确定一系列图像与另一系列图像之间的差异的可视方法可以是主观的或者不能检测非常小的差异。我们建议使用从自组织映射获得的量化误差进行图像内容分析。我们用MRI图像测试了这种技术,我们逐渐增加了合成病变。我们使用了一种全局方法,该方法考虑整个图像的变化,而不仅仅是分割病变区域的变化。我们声称这种方法不受分割所施加的限制,这可能会影响结果。结果显示量化误差随着图像上病变的增加而增加。结果也与先前使用替代方法的研究一致。然后,我们将我们的方法的可检测性能力与人类新手观察者的可检测能力进行比较,这些观察者必须检测随机点图像中非常小的局部差异在减去假阳性率猜测率之后,与正确的正率相比,SOM输出的量化误差显着增加,并且局部点尺寸的小幅增加是人类无法检测到的。我们得出结论,我们的方法检测到复杂图像中的非常小的变化,并建议可以实现它以帮助人类操作员进行基于图像的决策。 |
| Evolving Robust Neural Architectures to Defend from Adversarial Attacks Authors Danilo Vasconcellos Vargas, Shashank Kotyan 深度神经网络显示错误分类略微修改的输入图像。最近,已经提出了许多防御措施,但没有一个能够始终如一地改善神经网络的稳健性。在这里,我们建议使用攻击作为功能评估来自动搜索能够抵御此类攻击的架构。从文献中对神经结构搜索算法的实验表明,尽管它们的结果准确,但它们无法找到稳健的体系结构。大多数原因在于它们有限的搜索空间。通过创建一个新的神经架构搜索,其中包含密集层的选项以与卷积层连接,反之亦然,以及在搜索空间中添加乘法,加法和连接层,我们能够在对抗性上发展出一种精确的体系结构样本。有趣的是,演化架构的这种固有的稳健性可以与最先进的防御技术相媲美,例如对抗训练,同时仅在训练数据集上进行训练。此外,进化的体系结构利用了一些特殊的特征,这些特征可能对开发更强大的特性有用。因此,这里的结果表明存在更强大的体系结构,并为使用自动体系结构搜索开发和探索深度神经网络开辟了一系列新的可能性。 |
| SpliceRadar: A Learned Method For Blind Image Forensics Authors Aurobrata Ghosh, Zheng Zhong, Terrance E Boult, Maneesh Singh 随着图像编辑软件的易访问性,图像处理(如拼接)的检测和定位变得越来越重要。虽然检测生成图像的判定,但它不能提供对操作的深入了解。本地化有助于通过识别已经被篡改的图像的像素来解释正检测。我们提出了一种基于深度学习的拼接定位方法,而无需事先了解测试图像的相机模型。它包括一种用于学习丰富滤波器和抑制图像边缘的新方法。此外,我们在相机模型识别的替代任务上训练我们的模型,这使我们能够利用大型且广泛可用的,未经操作的,相机标记的图像数据库。在推理过程中,我们假设拼接和主体区域来自不同的相机模型,我们使用高斯混合模型对这些区域进行分割。在三个测试数据库上的实验证明了与现有技术水平相当或更高的结果以及对未知数据集的良好泛化能力。 |
| Inspirational Adversarial Image Generation Authors Morgane Riviere, Olivier Teytaud, J r my Rapin, Yann LeCun, Camille Couprie 图像生成的任务开始受到艺术家和设计师的一些关注,以在新的创作中激发他们的灵感。然而,鉴于缺乏现有工具,利用诸如Generative Adversarial Networks等深度生成模型的结果可能是漫长而乏味的。在这项工作中,我们提出了一个简单的策略,鼓励创造者从他们选择的数据集中学习新一代,同时提供对它们的一些控制。我们设计了一种简单的优化方法,以找到对应于任何输入励志图像的最近一代的最佳潜在参数。具体而言,我们允许通过执行若干优化步骤从模型的潜在空间恢复最佳参数来给出用户选择的鼓舞人心的图像。我们测试了几种探索方法,从经典梯度下降开始,到梯度自由优化器。许多梯度自由优化器只需要比另一个图像更好的比较,这样它们甚至可以在没有数字标准的情况下使用,没有鼓舞人心的图像,但只有人类偏好。因此,通过迭代一个偏好,我们可以制作强大的面部复合或时尚生成算法。使用逐步增长的GAN获得所产生的设计世代的高分辨率。我们对面部,时尚图像和纹理的四个数据集的结果表明,在大多数情况下可以有效地检索出令人满意的图像。 |
| Mind2Mind : transfer learning for GANs Authors Ya l Fr gier, Jean Baptiste Gouray 我们提出了一种使用GAN架构进行传输学习的方法。通常,转移学习使得能够利用有限的计算和数据资源来训练用于分类任务的深度网络。然而,在生成任务的特定背景中缺少类似的方法。这部分是由于GAN的两个网络的极值层(应该在转移过程中学习)位于两个相对侧。这需要通过两个网络反向传播信息,这在计算上是昂贵的。我们开发了一种通过传递所有中间层来直接训练这些极值层的方法。对于Wasserstein GAN,我们也严格证明了一个确定转移GAN学习收敛的定理。最后,我们将我们的方法与最先进的方法进行比较,并表明我们的方法收敛得更快,并且需要更少的数据。 |
| Dealing with Topological Information within a Fully Convolutional Neural Network Authors Etienne Decenci re, Santiago Velasco Forero, Fu Min, Juanjuan Chen, H l ne Burdin, Gervais Gauthier, Bruno La , Thomas Bornschloegl, Th r se Baldeweck 完全卷积神经网络具有有限大小的接收域,因此不能利用诸如拓扑信息之类的全局信息。基于使用测地线算子的预处理,本文提出了一种解决该问题的解决方案。它适用于通过整体幻灯片成像获得的色素重建表皮的组织学图像的分割。 |
| CaDSS: Cataract Dataset for Semantic Segmentation Authors Evangello Flouty, Abdolrahim Kadkhodamohammadi, Imanol Luengo, Felix Fuentes Hurtado, Hinde Taleb, Santiago Barbarisi, Gwenole Quellec, Danail Stoyanov 视频信号提供了大量有关外科手术的信息,是外科医生的主要感官提示。视频处理和理解可用于授权计算机辅助干预CAI以及开展外科手术干预的详细术后分析。这种能力的基本构建块是能够理解视频并将其分割成语义标签,从而区分和定位组织类型和不同的仪器。近年来,深度学习大大提高了语义分割技术,但从根本上依赖于用于训练模型的标记数据集的可用性。在本文中,我们介绍了一个高质量的语义分割数据集,用于在可用视频上注释的白内障手术 |
| A shallow residual neural network to predict the visual cortex response Authors Anne Ruth Jos Meijer, Arnoud Visser 了解人类大脑的视觉皮层如何真正起作用仍然是当今科学的一个开放性问题。更好地理解自然智能也可以使基于卷积神经网络的对象识别算法受益。在本文中,我们展示了使用浅残差神经网络完成此任务的资产。这种方法的好处是可以准确地训练网络的早期阶段,这允许我们在早期阶段添加更多层。通过这个附加层,视觉大脑活动的预测从10.4块1改善到15.53最后完全连接层。通过对网络进行超过10个时期的培训,这种改进可以变得更大。 |
| A PolSAR Scattering Power Factorization Framework and Novel Roll-Invariant Parameters Based Unsupervised Classification Scheme Using a Geodesic Distance Authors Debanshu Ratha, Eric Pottier, Avik Bhattacharya, Alejandro C. Frery 我们提出了用于极化合成孔径雷达PolSAR数据的通用散射功率因数分解框架SPFF,以直接获得N个散射功率分量以及每个像素的残余功率分量。使用基本目标和广义随机体积模型将每个散射功率分量分解为相似性或不相似性。使用4次4真实Kennaugh矩阵对之间的测地距离导出相似性度量。在基于标准模型的分解方案中,3次3埃尔米特正半协方差或相干矩阵表示为遵循固定分层过程的散射目标的加权线性组合。相反,在所提出的框架下,执行单位的凸分裂以获得权重,同时保持散射分量的优势。具有这些权重的总功率Span的乘积提供非负散射功率分量。此外,沿着测地距离的框架有效地用于获得特定的滚动不变参数,然后将其用于设计无监督的分类方案。使用旧金山的C波段RADARSAT 2和L波段ALOS 2图像评估SPFF,滚动不变参数和分类结果。 |
| A New Benchmark Dataset for Texture Image Analysis and Surface Defect Detection Authors Shervan Fekri Ershad 纹理分析在许多图像处理应用中起着重要作用来描述图像内容或对象。另一方面,视觉表面缺陷检测是计算机视觉中的高度研究领域。表面缺陷是指表面纹理的异常。因此,本文提出了一种双目标基准数据集,用于纹理图像分析和表面缺陷检测,标题为石材纹理图像STI数据集。建议的基准数据集由4种不同类型的石质纹理图像组成。建议的基准数据集具有一些独特的属性,使其非常接近实际应用程序。局部旋转,不同的缩放率,不平衡的类,大小的纹理变化是建议的数据集的一些属性。在结果部分中,一些描述符应用于此数据集,以评估与其他最先进数据集相比较的建议STI数据集。 |
| Effective Rotation-invariant Point CNN with Spherical Harmonics kernels Authors Adrien Poulenard, Marie Julie Rakotosaona, Yann Ponty, Maks Ovsjanikov 我们提出了一种直接在点云数据上运行的新型旋转不变架构。我们演示了如何将旋转不变性注入最近提出的基于点的PCNN架构,在网络的所有层,实现全局形状变换的不变性,以及补丁或部件级别上的局部旋转,在处理非刚性时非常有用对象。我们通过在网络的不同层采用基于球谐波的内核来实现这一点,这保证了对刚性运动不变。我们还使用空间分区数据结构为PCNN引入了更有效的池化操作。这导致灵活,简单和有效的架构,在包括分类和分段在内的具有挑战性的形状分析任务上获得准确的结果,而不需要通常由非不变方法使用的数据增强。 |
| Automated Segmentation of Hip and Thigh Muscles in Metal Artifact-Contaminated CT using Convolutional Neural Network-Enhanced Normalized Metal Artifact Reduction Authors Mitsuki Sakamoto, Yuta Hiasa, Yoshito Otake, Masaki Takao, Yuki Suzuki, Nobuhiko Sugano, Yoshinobu Sato 在全髋关节置换术中,术后医学图像分析对于评估手术结果非常重要。由于计算机断层扫描CT是整形外科手术中最常见的模式,我们的目的是分析CT图像。在这项工作中,我们专注于金属植入物引起的术后CT中的金属伪影,这降低了分割的准确性,特别是在植入物附近。我们的目标是在术后CT图像中开发骨骼和肌肉的自动分割方法。我们提出了一种方法,它结合了归一化金属伪像减少NMAR,它是最先进的金属伪影减少方法之一,和基于卷积神经网络的分割使用两个U网络架构。第一个U网改善了NMAR的结果,肌肉分割由第二个U网进行。我们使用20名患者的模拟图像和3名患者的真实图像进行实验,以评估19个肌肉的分割准确性。在模拟研究中,所提出的方法在19个肌肉中的14个肌肉的平均对称表面距离ASD度量中显示出统计学上显着的改善p 0.05,并且所有肌肉的平均ASD从1.17 0.543 mm平均std超过所有患者到1.10 0.509 mm。以前的方法。使用臀大肌和中间肌的手动痕迹的真实图像研究显示ASD为1.32±0.25mm。我们未来的工作包括以金融伪影减少和肌肉分割的端到端方式训练网络。 |
| Deep Siamese Multi-scale Convolutional Network for Change Detection in Multi-temporal VHR Images Authors Hongruixuan Chen, Chen Wu, Bo Du, Liangpei Zhang 非常高分辨率的VHR图像提供丰富的地面细节和空间分布信息。多时相VHR图像中的变化检测在城市扩展和区域内部变化分析中起着重要作用。然而,传统的变化检测方法既不能充分利用空间背景信息,也不能应对VHR图像的复杂内部异质性。在本文中,我们提出了一个功能强大的多尺度特征卷积单元MFCU,用于VHR图像中的变化检测。所提出的单元能够在同一层中提取多尺度特征。基于该单元,设计了两种新型深暹罗卷积网络,深暹罗多尺度卷积网络DSMS CN和深暹罗多尺度全卷积网络DSMS FCN,用于多时相VHR图像中的无监督和监督变化检测。对于无监督变化检测,我们实现自动预分类以获得训练补丁样本,并且DSMS CN通过多尺度特征提取模块和深度连体结构拟合来自补片样本的变化和未变化区域的统计分布。对于监督变化检测,端到端深度完全卷积网络DSMS FCN在任何大小的多时间VHR图像中被训练,并直接输出二进制变化图。另外,为了解决不准确的定位问题,将完全连接的条件随机场FC CRF与DSMS FCN组合以细化结果。具有挑战性数据集的实验结果证实,两种提出的架构比现有技术方法表现更好。 |
| A Convolutional Decoder for Point Clouds using Adaptive Instance Normalization Authors Isaak Lim, Moritz Ibing, Leif Kobbelt 自动合成高质量的3D形状是一个持续且具有挑战性的研究领域。虽然已经提出了几种利用神经网络生成3D形状的数据驱动方法,但它们都没有达到图像深度学习合成方法提供的质量水平。在这项工作中,我们提出了一种卷积点云解码器生成器的方法,该方法利用了图像合成领域的最新进展。也就是说,我们使用自适应实例规范化,并提供直觉,说明为什么它可以改进培训。此外,我们建议扩展自动编码点云的常用倒角距离的最小化。此外,我们还表明,仔细采样对于输入几何和我们的点云生成过程都很重要,可以改善结果。结果在自动编码设置中评估,以提供定性和定量分析。所提出的解码器通过广泛的消融研究来验证,并且能够在许多实验中胜过当前的现有技术水平。我们展示了我们的方法在点云上采样,单视图重建和形状合成领域的适用性。 |
| Automatically Extract the Semi-transparent Motion-blurred Hand from a Single Image Authors Xiaomei Zhao, Yihong Wu 当我们使用视频聊天,视频游戏或其他视频应用程序时,经常出现运动模糊的手。准确地提取这些手对于视频编辑和行为分析非常有用。然而,现有的运动模糊对象提取方法或者需要用户交互,例如用户提供的三维图和涂鸦,或者需要附加信息,例如背景图像。本文提出了一种能够根据原始RGB图像自动提取半透明运动模糊手的新方法。所提出的方法将提取任务分成两个子任务alpha遮罩预测和前景预测。这两个子任务由基于Xception的编码器解码器网络实现。可以通过将预测的alpha遮罩和前景图像相乘来计算提取的运动模糊手图像。对合成和真实数据集的实验表明,该方法具有良好的性能。 |
| Abnormal Colon Polyp Image Synthesis Using Conditional Adversarial Networks for Improved Detection Performance Authors Younghak Shin, Hemin Ali Qadir, Ilangko Balasingham 结肠镜检查期间自动息肉检测的主要障碍之一是缺乏标记的息肉训练图像。在本文中,我们提出了一个条件对抗网络框架,通过生成合成息肉图像来增加训练样本的数量。使用仅表示息肉位置作为输入条件图像的正常二进制形式的息肉掩模,实际息肉图像生成在生成性对抗网络方法中是困难的任务。我们提出了基于边缘滤波的组合输入条件图像来训练我们提出的网络。这使得能够实现真实的息肉图像生成,同时保持结肠镜检查图像帧的原始结构。更重要的是,我们提出的框架从正常结肠镜检查图像生成合成息肉图像,其具有相对容易获得的优点。网络架构基于在我们的生成器网络的每个编码部分中使用多个扩散卷积来考虑大的感知域并且避免特征映射大小的许多收缩。用于在解码层中进行上采样的卷积调整大小的图像被认为是防止生成的图像上的伪像。我们证明生成的息肉图像不仅定性逼真,而且有助于提高息肉检测性能。 |
| Loss Switching Fusion with Similarity Search for Video Classification Authors Lei Wang, Du Q. Huynh, Moussa Reda Mansour 从视频流到安全和监控应用,视频数据在我们今天的日常生活中发挥着重要作用。但是,管理大量视频数据并为用户检索最有用的信息仍然是一项具有挑战性的任务。在本文中,我们提出了一种有益于场景理解任务的新型视频分类系统。我们将分类问题定义为使用相同的室外场景特征表示对背景和前景运动进行分类。这意味着特征表示需要足够健壮并且能够适应不同的分类任务。我们提出了一种轻量级丢失交换融合网络LSFNet,用于融合时空描述符和具有软投票的相似性搜索方案,以提高分类性能。所提出的系统具有各种潜在的应用,例如基于内容的视频聚类,视频滤波等。两个私有行业数据集的评估结果表明,我们的系统在分类不同的背景运动和从这些背景运动中检测人类运动方面都是健壮的。 |
| Automatic Colon Polyp Detection using Region based Deep CNN and Post Learning Approaches Authors Younghak Shin, Hemin Ali Qadir, Lars Aabakken, Jacob Bergsland, Ilangko Balasingham 结肠息肉的自动检测仍然是一个未解决的问题,因为息肉在形状,质地,大小和颜色方面的变化很大,并且在结肠镜检查期间存在各种类似息肉的模拟物。在这项研究中,我们应用最近基于区域的卷积神经网络CNN方法来自动检测从结肠镜检查获得的图像和视频中的息肉。我们使用深度CNN模型Inception Resnet作为检测系统中的转移学习方案。为了克服息肉检测障碍和少量息肉图像,我们研究了用于训练深度网络的图像增强策略。我们进一步提出了两种有效的后学习方法,例如自动假阳性学习和离线学习,这两种方法都可以与基于区域的检测系统结合用于可靠的息肉检测。使用大尺寸的结肠镜检查数据库,实验结果表明,与文献中的其他系统相比,所建议的检测系统显示出更好的性能。此外,我们使用提议的结肠镜检查后学习方案显示出改进的检测性能。 |
| Region Refinement Network for Salient Object Detection Authors Zhuotao Tian, Hengshuang Zhao, Michelle Shu, Jiaze Wang, Ruiyu Li, Xiaoyong Shen, Jiaya Jia 尽管进行了深入研究,但错误的预测和不明确的边界仍然是突出物体检测的主要问题。在本文中,我们提出了区域细化网络RRN,它反复过滤冗余信息并明确地模拟边界信息以进行显着性检测。与现有的细化方法不同,我们提出了区域细化模块RRM,其通过在中间细化阶段中结合监督的注意掩模来优化显着区域预测。该模块仅带来模型尺寸的轻微增加,但显着减少了背景的错误预测。为了进一步细化边界区域,我们提出了边界细化损失BRL,它增加了额外的监督,以便更好地区分前景和背景。 BRL无参数且易于训练。我们进一步观察到BRL通过改进边界有助于保持预测的完整性。关于显着性检测数据集的大量实验表明,我们的细化模块和损失可以显着改善基线,并且可以轻松应用于不同的框架。我们还证明了我们提出的模型很好地概括了纵向分割和阴影检测任务。 |
| Hard Pixels Mining: Learning Using Privileged Information for Semantic Segmentation Authors Zhangxuan Gu, Li Niu, Liqing Zhang 语义分割已经取得了重大进展,但由于复杂的场景,对象遮挡等原因仍然具有挑战性。一些研究工作试图使用诸如深度信息之类的额外信息来帮助基于RGB的语义分割。但是,测试图像通常无法获得额外信息。受到学习使用特权信息的启发,在本文中,我们仅在训练阶段利用训练图像的深度信息作为特权信息。具体地,我们依靠深度信息来识别难以分类的硬像素,通过使用我们提出的深度预测误差DPE和深度依赖分割误差DSE。通过更加关注已识别的硬像素,我们的方法在两个基准数据集上实现了最先进的结果,甚至优于使用测试图像的深度信息的方法。 |
| ELKPPNet: An Edge-aware Neural Network with Large Kernel Pyramid Pooling for Learning Discriminative Features in Semantic Segmentation Authors Xianwei Zheng, Linxi Huan, Hanjiang Xiong, Jianya Gong 语义分割一直是各个研究领域的热门话题。随着深度卷积神经网络的成功,语义分割在城市场景解析和室内语义分割方面都取得了很大的成就和改进。然而,大多数现有技术模型在辨别特征学习中仍然面临挑战,这限制了模型检测多尺度对象并保证一个对象内的语义一致性或区分具有相似外观的不同相邻对象的能力。本文提出了一种实用有效的边缘感知神经网络进行语义分割。这种端到端可训练引擎包括一个新的编码器解码器网络,一个大的内核空间金字塔池LKPP块和一个边缘感知损失函数。编码器解码器网络被设计为平衡结构,以缩小多级特征聚合中的语义和分辨率差距,而LKPP块构造有用于多尺度特征提取和融合的密集扩展的感受域。此外,提出了新的强大的边缘感知损失函数,以直接从语义分割预测中细化边界,以获得更强大和有辨别力的特征。使用Cityscapes,CamVid和NYUDv2基准数据集证明了所提出模型的有效性。 ELKPPNet中两个结构的性能和边缘感知损失功能在Cityscapes数据集上得到验证,而完整的ELKPPNet在CamVid和NYUDv2数据集上进行了评估。在相同条件下与现有技术方法的比较分析证实了所提算法的优越性。 |
| Few-Shot Video Classification via Temporal Alignment Authors Kaidi Cao, Jingwei Ji, Zhangjie Cao, Chien Yi Chang, Juan Carlos Niebles 人们越来越有兴趣学习一种能够识别新类别的模型,只需要几个标记的例子。在本文中,我们提出了时间对齐模块TAM,这是一种新颖的镜头学习框架,可以学习如何对以前看不见的视频进行分类。虽然大多数先前的作品忽略了长期时间排序信息,但是我们提出的模型通过时间对齐明确地利用视频数据中的时间排序信息。这导致很少的镜头学习的强大数据效率。具体而言,TAM通过沿着其对齐路径平均每帧距离来计算查询视频相对于新类代理的距离值。我们引入了对TAM的连续放松,因此可以以端到端的方式学习模型,以直接优化少数镜头学习目标。我们在两个具有挑战性的现实世界数据集Kinetic和Something Something V2上评估TAM,并表明我们的模型可以在广泛的竞争基线上显着改善少数镜头视频分类。 |
| Emergence of Exploratory Look-Around Behaviors through Active Observation Completion Authors Santhosh K. Ramakrishnan, Dinesh Jayaraman, Kristen Grauman 标准计算机视觉系统假设访问智能捕获的输入,例如来自人类摄影师的照片,但是自主地捕获良好的观察结果本身就是一个主要挑战。我们解决了学习环顾四周代理如何学习获取信息性视觉观察的问题我们提出了一种强化学习解决方案,其中代理人因为减少其对环境中未被观察到的部分的不确定性而获得奖励。具体地,训练代理以选择短的一系列瞥见,之后它必须推断其完整环境的外观。为了应对稀疏奖励的挑战,我们进一步介绍了sidekick策略学习,它利用了训练和测试时间之间可观察性的不对称性。所提出的方法学习观察策略,其不仅执行它们被训练的完成任务,而且还概括为展示对一系列主动感知任务的行为的有用外观。 |
| Developing an App to interpret Chest X-rays to support the diagnosis of respiratory pathology with Artificial Intelligence Authors Andrew Elkins, Felipe F. Freitas, Veronica Sanz 在本文中,我们介绍了我们的工作,以改善可能缺乏优质医疗服务的偏远地区的诊断。我们开发新的机器学习方法,以便部署到移动设备上,以帮助使用X射线图像早期诊断许多危及生命的情况。通过使用快速和便携式人工智能环境的最新发展,我们使用人工神经网络开发智能手机应用程序,以帮助医生进行诊断。 |
| More chemical detection through less sampling: amplifying chemical signals in hyperspectral data cubes through compressive sensing Authors Henry Kvinge, Elin Farnell, Julia R. Dupuis, Michael Kirby, Chris Peterson, Elizabeth C. Schundler 压缩感知CS是一种采样方法,它允许某些类别的信号即使在采样不足时也能以高精度重建。在本文中,我们探索了一种现象,其中高光谱数据立方体随后重建的带状CS采样实际上可以导致立方体中包含的化学信号的放大。也许最令人惊讶的是,化学信号放大通常似乎随着采样水平的降低而增加。在一些示例中,化学信号在从10 CS采样重建的数据立方体中比在原始的100采样数据立方体中明显更强。我们在两个真实世界的数据集中探索这种现象,包括Physical Sciences Inc. Fabry P rot干涉仪传感器多光谱数据集和基于约翰霍普金斯应用物理实验室FTIR的长波红外传感器高光谱数据集。这些数据集中的每一个都包含化学模拟物的释放,例如冰醋酸,磷酸三乙酯和六氟化硫,并且在所有情况下,我们使用自适应相干估计器ACE来检测高光谱数据立方体中的目标信号。我们通过提出一些理论上的理由来结束这篇论文,为什么化学信号会在CS采样和重建的高光谱数据立方体中被放大,并讨论一些实际意义。 |
| Latent Optimization for Non-adversarial Representation Disentanglement Authors Aviv Gabbay, Yedid Hoshen 姿势和内容之间的纠缠是人工智能的关键任务,并引起了很多研究兴趣。目前的解缠结方法包括对抗训练和引入周期约束。在这项工作中,我们提出了一种新的解缠方法,它不使用对抗训练,达到最先进的性能。我们的方法使用从样式转移中借用的体系结构的潜在优化,以强制分离姿势和内容。我们通过一种新颖的两阶段方法克服了潜在优化的测试泛化问题。在广泛的实验中,我们的方法显示出比使用相同监督水平的对抗性和非对抗性方法更好的解缠结性能。 |
| Using Intuition from Empirical Properties to Simplify Adversarial Training Defense Authors Guanxiong Liu, Issa Khalil, Abdallah Khreishah 由于复杂分布具有令人惊讶的良好表示能力,神经网络NN分类器广泛用于许多任务,包括自然语言处理,计算机视觉和网络安全。在最近的作品中,人们注意到存在对抗性的例子。这些对抗性的例子打破了NN分类器的假设,即环境是无攻击的,并且很容易误导完全训练的NN分类器而没有明显的变化。在防御性方法中,对抗性训练是一种流行的选择。然而,使用单步对抗实例Single Adv的原始对抗训练无法抵御迭代对抗性示例。尽管使用迭代对抗示例Iter Adv的对抗训练可以抵御迭代对抗性示例,但它消耗了太多的计算能力,因此无法扩展。在本文中,我们分析了Iter Adv技术并确定了它们的两个经验属性。基于这些属性,我们提出了一些修改,它们可以增强Single Adv作为Iter Adv的竞争力。通过初步评估,我们证明了所提出的方法提高了最先进的SOTA Single Adv防御方法对迭代对抗性例子的测试准确度高达16.93,同时将其训练成本降低了28.75。 |
| Curriculum Learning for Deep Generative Models with Clustering Authors Deli Zhao, Jiapeng Zhu, Zhenfang Guo, Bo Zhang 训练生成模型,如生成对抗网络GAN和规范化流程,对于噪声数据具有挑战性。本文提出了一种与聚类相关的新型课程学习算法来解决这一问题。课程构建基于数据点中底层集群的中心性。高度集中的数据点优先在训练期间被输入生成模型。为了使我们的算法可扩展到大规模数据,设计活动集,在某种意义上,每轮训练仅在包含一小部分已经训练的数据和较低中心性的增量数据的活动子集上进行。此外,还提出了几何分析来解释生成模型的集群课程的必要性。猫和人脸数据的实验验证了我们的算法能够学习最佳的生成模型,例如ProGAN和Glow针对噪声数据的指定质量指标。一个有趣的发现是,最优的集群课程与本文制定的几何渗透过程的临界点密切相关。 |
| DeepVIO: Self-supervised Deep Learning of Monocular Visual Inertial Odometry using 3D Geometric Constraints Authors Liming Han, Yimin Lin, Guoguang Du, Shiguo Lian 本文提出了一种名为DeepVIO的单眼视觉惯性测距自监督深度学习网络。 DeepVIO通过直接合并2D光流特征OFF和惯性测量单元IMU数据来提供绝对轨迹估计。具体来说,首先利用立体序列估计每个场景的深度和密集三维点云,然后获得三维几何约束,包括三维光流和6个DoF姿势作为监控信号。注意,这种3D光流显示出对动态对象和无纹理环境的鲁棒性和准确性。在DeepVIO训练中,2D光流网络受其相应3D光流投影的约束,LSTM型IMU预积分网络和融合网络通过最小化自我运动约束下的损失函数来学习。此外,我们采用IMU状态更新方案,通过更新额外的陀螺仪和加速度计偏差来改善IMU姿态估计。 KITTI和EuRoC数据集的实验结果表明,DeepVIO在准确性和数据适应性方面优于最先进的学习方法。与传统方法相比,DeepVIO减少了不准确的相机IMU校准,不同步和丢失数据的影响。 |
| Clustering by the way of atomic fission Authors Shizhan Lu 聚焦于相似元素的分组和分类的聚类分析被广泛用于各种研究领域。受原子裂变现象的启发,本文提出了一种新的基于密度的聚类算法,称为裂变聚类FC。它侧重于挖掘数据集的密集族,并利用距离矩阵的信息将聚类数据集裂缝成子集。当我们面对具有围绕密集族群的几个点的数据集时,应用K个最近邻居局部密度指示符来区分和去除稀疏区域的点,以便获得由密集的群集族构成的密集子集。 。许多常用的数据集用于测试这种聚类方法的性能,并将结果与算法的结果进行比较。发现所提出的算法在速度和准确性方面优于其他算法。 |
| Accelerating Large-Kernel Convolution Using Summed-Area Tables Authors Linguang Zhang, Maciej Halber, Szymon Rusinkiewicz 扩展感知领域以捕获大规模上下文是在密集预测任务(例如人体姿势估计)中获得良好性能的关键。虽然许多现有技术的完全卷积体系结构通过使用跨步卷积或汇集层来降低分辨率来扩大感受野,但最直接的策略是采用大型滤波器。然而,由于参数数量和乘法运算的二次增加,这是昂贵的。在这项工作中,我们探索使用可学习的盒式过滤器来允许任意大的内核大小的卷积,同时保持每个过滤器的参数数量不变。此外,我们使用预先计算的求和区域表来使卷积的计算成本与滤波器大小无关。我们将盒式滤波器作为完全卷积神经网络中的可微分模块进行调整和整合,并展示其在人类姿态估计任务的流行基准测试中的竞争性能。 |
| Large-scale 3D point cloud representations via graph inception networks with applications to autonomous driving Authors Siheng Chen, Sufeng. Niu, Tian Lan, Baoan Liu 我们提出了一种新的基于图形神经网络的系统,以有效地表示大规模3D点云与自动驾驶的应用。许多以前的工作研究了基于两种方法的3D点云的表示,体素化导致离散化误差和学习,这很难捕获大规模场景中的巨大变化。在这项工作中,我们结合了体素化和学习,我们将3D空间离散化为体素,并提出新颖的图形初始网络来表示每个体素中的3D点。这种组合使系统避免了离散化错误,适用于大规模场景。用于大规模3D点云的整个系统就像2D图像的阻塞离散余弦变换一样,因此我们将其称为点云神经变换PCT。我们进一步应用拟议的PCT来代表自动驾驶汽车产生的实时激光雷达扫描,PCT图形初始网络明显优于其竞争对手。 |
| Enhancing temporal segmentation by nonlocal self-similarity Authors Mariella Dimiccoli, Herwig Wendt 未修剪视频和照片流的时间分割是目前计算机视觉和图像处理研究的一个活跃领域。本文提出了一种改进照片流时间分割的新方法。该方法包括通过编码长程时间依赖性来增强图像表示。我们的关键贡献是利用照片流的时间平稳性假设,通过其非局部自相似函数对每个帧进行建模。所提出的方法用于测试EDUB Seg数据集,这是自我中心照片流时间分割的标准基准。从七个不同的基于CNN的图像特征开始,该方法产生事件分割质量的一致改进,导致相对于现有技术的F测量值平均增加3.71。 |
| One Size Does Not Fit All: Quantifying and Exposing the Accuracy-Latency Trade-off in Machine Learning Cloud Service APIs via Tolerance Tiers Authors Matthew Halpern, Behzad Boroujerdian, Todd Mummert, Evelyn Duesterwald, Vijay Janapa Reddi 今天的云服务架构遵循一种适合所有部署策略,其中向最终用户提供相同的服务版本实例化。然而,消费者是广泛的,不同的应用程序具有不同的准确性和响应性要求,正如我们所展示的那样,在实践中呈现一种尺寸适合所有方法的低效率。我们使用生产级语音识别引擎,为数千名用户提供服务,以及基于开源计算机视觉的系统,以解释我们的观点。为了克服一刀切所有方法的局限性,我们建议Tolerance Tiers,其中每个MLaaS层都暴露出准确性响应特性,消费者可以通过编程方式选择一个层。我们评估了基于CPU的自动语音识别ASR引擎和用于在CPU和GPU上部署的图像分类的尖端神经网络的建议。结果表明,我们提出的方法提供了一种MLaaS云服务架构,可以由最终API用户或消费者进行调整,以超越传统的一刀切所有方法。 |
| Chinese Abs From Machine Translation |
Papers from arxiv.org
更多精彩请移步主页
pic from pexels.com