【今日CV 计算机视觉论文速览 第145期】Fri, 19 Jul 2019
今日CS.CV 计算机视觉论文速览
Fri, 19 Jul 2019
Totally 33 papers
?上期速览✈更多精彩请移步主页

Interesting:
?水下图像增强综述, 主要就深度学习用于水下处理的方法和数据集进行了深入的整理和分析,包括水下成像模型、数据合成以及网络的设计,从网络架构、参数、训练数据、损失函数以及训练配置等方面进行了分析。并总结了算法常用的度量标准和评价方法。最后指出了目前数据集和评价方法存在的问题,并给出了一些这一领域的开放问题和未来的研究方向。(from 澳大利亚国立 香港城市大学)
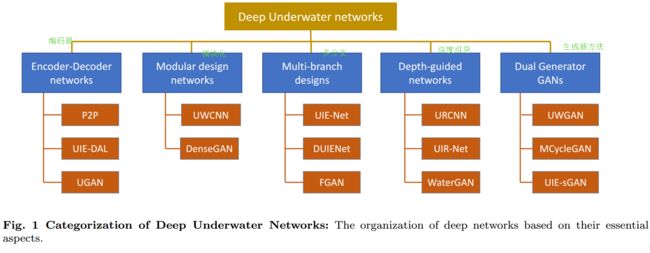
目前水下图像处理的架构:


| 数据集 | Fish4Knowledge | ULFID | MARIS | Haze-line Dataset | UIEBD | |
|---|---|---|---|---|---|---|
| 度量标准 | MSE | PSNR | SSIM | PCQI | UCIQE | UIQM |
| 未来方向 | Datasets | Objective functions | evaluation metrics | Prior knowledge | Unsupervised learning | Real vs. Synthetic |
一些水下图像增强的结果:

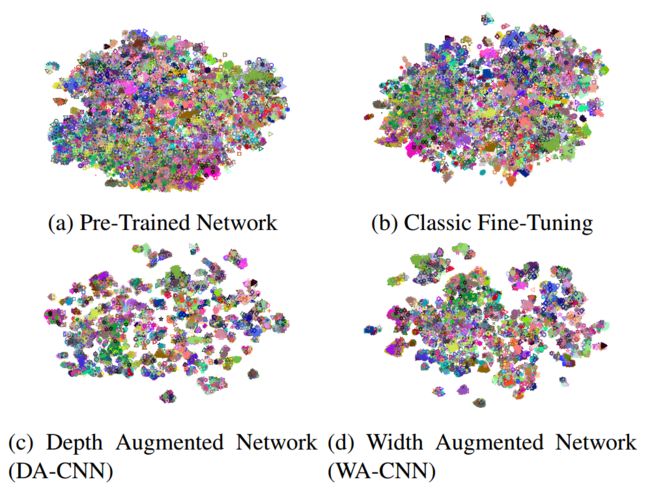
?Growing a Brain通过增加模型容量来进行网络精调,容量扩增调优法, 研究人员分析了在迁移学习调优过程中元件和参数变化引起的性能变化,并发现增加模型容量和使得调优更自然适应。研究人员最后提出了一种可以利用额外的单元,在宽度或者深度上增长CNN的方法来提高fine-tune的效果。新增的单元必须有适合的归一化才能与现有单元进行步调一致的学习。(from CMU RI)

不同的容量扩增调优方法:

增强后的结果具有更好的可分辨性:
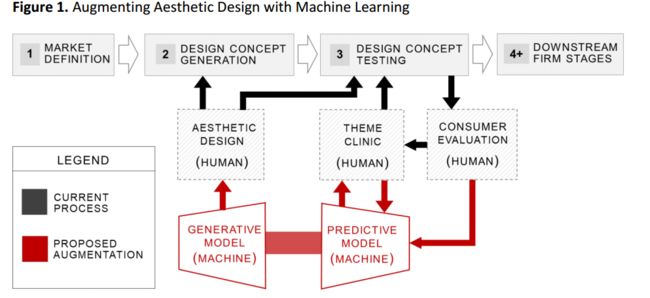
?人机互动下的产品美学设计, 研究人员提出了一种基于变分自编码器和生成对抗网络辅助人类进行产品设计的新模型,通过自动化生成与设计,并与人类进行交互来实现更富有美学的新产品设计。(from MIT)
主要的设计流程如下,包括市场定义、设计概念生成与验证等:
研究人员提出的增强模型方法结合了标记数据、非标记数据和新图像进行生成:

一些算法辅助设计的结果:

ref:https://vimeo.com/334094197
author:http://www.aburnap.com/ https://github.com/aburnap
data:We train our model with data from an automotive partner—7,000 images evaluated bytargeted consumers and 180,000 high-quality unrated images.
?MF-TAPNet基于运动流对手术器械进行分割, (from 香港中文)
下图是模型MF-TAPNet的流程,其中先借助上一帧分割和运动流得到下一帧的初始分割,而后优化(损失一)并通过反向的流与生成上一步掩膜,并与原先掩膜进行比较(损失二)。
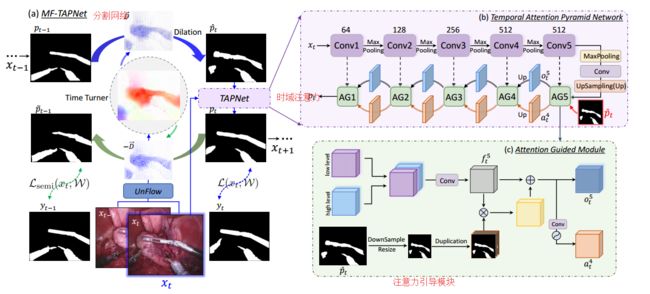
dataset:public dataset of Robotic Instrument Segmentation from the 2017 MICCAI EndoVis Challenge [2].
?GRIP基于图机制来感知交通流中的交互并预测车辆轨迹, 利用图的方法来表示邻近物体间的交互,并利用图卷积模块来抽取特征,并使用自编码LSTM来进行轨迹预测(from 里海大学)

code and datasete:https://github.com/nachiket92/conv-social-pooling
Daily Computer Vision Papers
| On the Evaluation of Conditional GANs Authors Terrance DeVries, Adriana Romero, Luis Pineda, Graham W. Taylor, Michal Drozdzal 条件生成对抗网络cGAN在许多应用领域中得到越来越广泛的应用。尽管取得了显着进步,但对此类模型的定量评估通常涉及多个不同的指标,以评估不同的理想属性,如图像质量,内部条件多样性和条件一致性,使模型基准测试具有挑战性在本文中,我们提出了Frechet Joint Distance FJD,它隐含地在单个度量中捕获上述属性。 FJD定义为图像和条件的联合分布的Frechet距离,使其对通常受限的每个条件样本大小不敏感。因此,它可以更加优雅地扩展到更强的调节形式,例如像素或多模式调节。我们在dSprite数据集的修改版本以及大规模COCO Stuff数据集上评估FJD,并且与当前建立的指标相比,始终突出其优势。此外,我们使用新引入的指标来比较现有的基于cGAN的模型,具有不同的调节强度,并表明FJD可以用作模型基准测试的有前途的单一指标。 |
| Autonomous Driving in the Lung using Deep Learning for Localization Authors Jake Sganga, David Eng, Chauncey Graetzel, David B. Camarillo 肺癌是全球癌症相关死亡的主要原因,早期诊断对于改善患者预后至关重要。为了诊断癌症,训练有素的肺病专家必须将灵活的支气管镜深入肺部分支结构进行活组织检查。活组织检查无法对26 33例患者的目标组织进行采样,这主要是因为术前CT图谱记录不良。为了改善术中注册,我们开发了两种深度学习方法,用于实时基于支气管镜视频的术前CT图定位支气管镜,称为AirwayNet和BifurcationNet。网络完全基于来自患者特异性CT的模拟图像进行训练。当在幻影肺中记录支气管镜检查视频时,AirwayNet的表现优于其他深度学习定位算法,其精确回忆曲线的面积为0.97。使用AirwayNet,我们仅基于视频反馈演示了幻像肺中的自主驾驶。在95个试验中,机器人在左右肺中达到四个目标。在8个人类尸体肺部的录制视频中,AirwayNet在精确回忆曲线范围内实现了从0.82到0.997的区域。 |
| Discriminative Embedding Autoencoder with a Regressor Feedback for Zero-Shot Learning Authors Ying Shi, Wei Wei, Zhiming Zheng 零射击学习ZSL旨在使用类别的语义表示来识别新颖的对象类别,并且关键思想是探索新颖类如何在语义上与熟悉的类相关的知识。一些典型的模型是学习图像特征空间和语义空间之间的适当嵌入,同时学习判别特征并包括粗到精的图像特征和语义信息是很重要的。在本文中,我们提出了一种判别嵌入自动编码器,它具有ZSL的回归反馈模型。编码器学习从图像特征空间到判别嵌入空间的映射,其通过边缘调节所学习的特征之间的类间和类内距离,使得学习的特征对于对象识别是有区别的。回归反馈学习将重建的样本映射回判别嵌入和语义嵌入,帮助解码器提高样本的质量并为看不见的类提供推广。所提出的模型在四个基准数据集SUN,CUB,AWA1,AWA2上得到了广泛的验证,实验结果表明我们提出的模型优于现有技术模型,特别是在广义零射击学习GZSL中,实现了显着的改进。 |
| ++星桥网络Video Prediction for Precipitation Nowcasting Authors Yuan Cao, Qiuying Li, Lei Chen, Junping Zhang, Leiming Ma 视频预测,旨在合成现有视频之后的新连续帧。但是,它的表现受到未来不确定性的影响。作为视频预测的潜在天气应用,短时降水临近预报比其他任务更具挑战性,因为其不确定性受温度,大气,风,湿度等的影响很大。为了解决这个问题,我们提出了星桥神经网络StarBriNet。具体来说,我们首先为RNN构建一个简单但有效的星形信息桥,以跨时间步传递特征。我们还提出了一种新的损失函数,用于降水临近预报任务。此外,我们利用组规范化来优化我们网络的预测性能。移动数字数据集和天气预报数据集中的实验表明,我们的模型优于用于视频预测和降水临近预报的最先进算法,实现了令人满意的天气预报性能。 |
| Analysis of "User-Specific Effect" and Impact of Operator Skills on Fingerprint PAD Systems Authors Giulia Orr , Pierluigi Tuveri, Luca Ghiani, Gian Luca Marcialis 指纹活体检测或呈现攻击检测PAD,即检测提交给电子捕获设备的指纹是真实的还是由一些人造材料组成的能力,提高了科学界的注意力以及最近基于的机器学习方法深层网络打开了新的场景。由于公众可以获得大量数据,特别是在国际指纹实时检测竞赛LivDet期间发布的数据,这是一个重要的进步。其中,2017年进行的第五版向参与者提出了另外两项挑战,这些挑战在官方报告中没有详细说明。在本文中,我们希望通过关注它们来扩展该报告,第一个旨在探索将PAD集成到指纹验证系统中的情况,其中用户模板也可用,并且设计者不限于参考仅针对PAD设置的通用用户群。第二个面临着提供假货的攻击者的开发能力,以及这种能力如何影响最终表现。这两个挑战可以共同确定指纹呈现攻击在何种程度上是一种实际威胁,以及如何利用其他信息来提高PAD的效率。 |
| Self-supervised Training of Proposal-based Segmentation via Background Prediction Authors Isinsu Katircioglu, Helge Rhodin, Victor Constantin, J rg Sp rri, Mathieu Salzmann, Pascal Fua 虽然监督对象检测方法获得了令人印象深刻的准确性,但它们对于外观与其训练数据明显不同的图像概括不佳。为了在注释数据过于昂贵的情况下解决这个问题,我们引入了一种自我监督的对象检测和分割方法,能够处理使用移动相机捕获的单眼图像。我们的方法的核心在于观察分割和背景重建是相互关联的任务,并且由于我们观察结构化场景,背景区域可以从其周围环境重新合成,而描绘该对象的区域不能。因此,我们将这种直觉编码为自我监督的损失函数,我们利用它来训练基于提议的分割网络。为了解释对象提案的离散性,我们开发了一种基于蒙特卡罗的培训策略,使我们能够探索大量的对象提案。我们的实验表明,我们的方法可以在图像中产生准确的检测和分割,这些检测和分割在视觉上与标准基准测试不同,优于现有的自我监督方法,并接近利用大型注释数据集的弱监督方法。 |
| Real-Time Driver State Monitoring Using a CNN Based Spatio-Temporal Approach Authors Neslihan Kose, Okan Kopuklu, Alexander Unnervik, Gerhard Rigoll 许多交通事故是由于司机分心造成的。今天,驾驶员监控对于最新的自动驾驶车辆来说是必不可少的,以警告分散注意力的驾驶员,以便在紧急情况下接管车辆的控制。在本文中,应用空间时间方法来使用卷积神经网络CNN对驾驶员分心水平和运动决策进行分类。我们将此问题作为动作识别来处理,以便除了空间信息之外还受益于时间信息。我们的方法依赖于使用预先训练的BN初始网络从动作的稀疏选择帧中提取的特征。实验表明,我们的方法优于分散驱动数据集96.31的最新结果,10类分类的准确度为99.10,同时提供实时性能。我们还使用RGB和光流模式以及最近的数据级融合策略分析了融合的影响。 Distracted Driver和Brain4Cars数据集的结果表明,这些模态的融合进一步提高了准确性。 |
| Automated Gleason Grading of Prostate Biopsies using Deep Learning Authors Wouter Bulten, Hans Pinckaers, Hester van Boven, Robert Vink, Thomas de Bel, Bram van Ginneken, Jeroen van der Laak, Christina Hulsbergen van de Kaa, Geert Litjens Gleason评分是前列腺癌患者最重要的预后标志物,但患有显着的观察者间变异性。我们开发了一种全自动深度学习系统来对前列腺活检进行分级。该系统使用来自1243名患者的5834个活组织检查进行开发。半自动标记技术用于避免病理学家对完整手动注释的需要。开发的系统与参考标准达成了高度一致。在一项单独的观察实验中,深度学习系统的表现优于15位病理学家中的10位。该系统具有通过充当第一或第二读者来改善前列腺癌预后的潜力。 |
| Locality-constrained Spatial Transformer Network for Video Crowd Counting Authors Yanyan Fang, Biyun Zhan, Wandi Cai, Shenghua Gao, Bo Hu 与基于单个图像的人群计数相比,视频提供了人群的空间时间信息,这将有助于提高人群计数的稳健性。但是人的平移,旋转和缩放导致相邻帧之间的头部密度图的改变。同时,在动态场景中走出或被遮挡的人会导致人数的变化。为了缓解视频人群计数中的这些问题,提出了局部约束空间变换器网络LSTN。具体而言,我们首先利用卷积神经网络来估计每个帧的密度图。然后,为了关联相邻帧之间的密度图,引入局部约束空间变换器LST模块来估计下一帧的密度图与当前帧的密度图。为了便于性能评估,收集了一个大规模的视频人群统计数据集,其中包含15K帧,从13个不同场景中捕获约394K个注释头。据我们所知,它是最大的视频人群统计数据集。对我们的数据集和其他人群计数数据集进行的大量实验验证了我们的LSTN对人群计数的有效性。 |
| A Computer Vision Application for Assessing Facial Acne Severity from Selfie Images Authors Tingting Zhao, Hang Zhang, Jacob Spoelstra 我们与雀巢皮肤健康SHIELD皮肤健康,创新,教育和长寿发展,NSH合作开发了一种深度学习模型,能够评估自拍图像的痤疮严重程度,与皮肤科医生一样准确。该模型作为移动应用程序部署,为患者提供了一种评估和跟踪痤疮治疗进展的简便方法。 NSH为这项研究获得了4,700张自拍图像,并招募了11名内部皮肤科医生将它们分为五类:1种清除,2种几乎清除,3种轻度,4种中度,5种严重。我们开发了面部标志和OneEye OpenCV模型的耦合方法,以从自拍图像中提取皮肤斑块,以最小化不相关的背景。为了解决CNN模型的空间敏感性问题,我们设计了一种创新的图像滚动方法,使痤疮病变出现在训练图像的更多位置。这种数据增强方法解决了标签不平衡问题,并改进了CNN模型在测试图像上的推广。我们通过使用ResNet 152预训练模型提取图像特征来应用转移学习方法,然后添加并训练完全连接的层以接近期望的严重等级。我们的模型在测试图像上优于初级人类皮肤科医生。据我们所知,这是第一个使用自拍图像进行痤疮评估的基于深度学习的解决方案。 |
| Incorporating Temporal Prior from Motion Flow for Instrument Segmentation in Minimally Invasive Surgery Video Authors Yueming Jin, Keyun Cheng, Qi Dou, Pheng Ann Heng 视频中的自动仪器分割是机器人辅助微创手术的基本但具有挑战性的问题。在本文中,我们提出了一种新的框架来利用仪器运动信息,通过在注意金字塔网络之前结合导出的时间来进行精确分割。我们推断的先验可以提供仪器位置和形状的可靠指示,其根据帧间运动流从前一帧传播到当前帧。该先验被注入到编码器解码器分段网络的中间,作为关注模块的金字塔的初始化,以明确地将分段输出从粗略引导到精细。通过这种方式,时间动态和关注网络可以有效地相互补充和互利。作为额外的用法,我们的时间先验使得能够通过反向执行来实现具有周期性未标记视频帧的半监督学习。我们在2017年MICCAI EndoVis机器人仪器分段挑战数据集上广泛验证了我们的方法,其中包含三个不同的任务。我们的方法在很大程度上超过了所有三个任务的最新结果。我们的半监督变体也显示出降低临床实践中注释成本的潜力。 |
| ++钞票识别欧盟A feasibility study of deep neural networks for the recognition of banknotes regarding central bank requirements Authors Julia Schulte, Daniel Staps, Alexander Lampe 本文包含深度神经网络在欧洲钞票分类方面的可行性研究,涉及ATM和高速分拣行业的中央银行要求。我们不是像着名的ImageNet挑战那样专注于大量课程的准确性,而是集中于几个类别的条件和拒绝图像的要求,这些图像清楚地属于所有训练的类别,即所谓的0类中的分类。这些特殊要求是中央银行定义为欧洲中央银行的框架的一部分,并由现有的ATM和高速分拣机器满足。我们还考虑了最先进的GPU硬件的培训和分类时间。该研究集中于钞票识别,而钞票类依赖的真实性和健康检查是其自身的主题,在本工作中不予考虑。数据集Diebold Nixdorf AG:https://www.dieboldnixdorf.com/en-us |
| A Strong Feature Representation for Siamese Network Tracker Authors Zhipeng Zhou, Rui Zhang, Dong Yin 对象跟踪在个性化监控的辅助技术中具有重要的应用。最近的追踪者选择AlexNet作为提取功能的主干,取得了巨大的成功。然而,AlexNet太浅而无法形成强大的特征表示,与最先进的算法相比,基于Siamese网络的跟踪器具有精确度差距。为了解决这个问题,本文提出了一种名为SiamPF的跟踪器。首先,经过修改的预先训练的VGG16网络被微调为骨干网。其次,在第三卷积层之后添加类似AlexNet的分支,并与骨干网络的响应映射合并,以形成初步的强特征表示。然后,通道注意块被设计为自适应地选择贡献特征。最后,修改APCE以处理响应图以减少干扰并将跟踪器聚焦在目标上。我们的SiamPF仅使用ILSVRC2015 VID进行培训,但它在OTB 2013 OTB 2015 VOT2015 VOT2017上实现了出色的性能,同时在GTX 1080Ti上保持了41FPS的实时性能。 |
| ++震后建筑损伤评估Post-Earthquake Assessment of Buildings Using Deep Learning Authors Dhananjay Nahata, Harish Kumar Mulchandani, Suraj Bansal, G Muthukumar 从安全角度和修理工作来看,建筑物在地震事件中遭受的破坏程度的分类至关重要。在这项研究中,作者提出了基于CNN的自动损伤检测模型。超过1200个不同类型的建筑物1000用于训练和200个用于测试的图像根据所遭受的损坏程度分为4类。类别是,没有损害,轻微损坏,重大损害和崩溃。通过应用具有不同学习速率的各种算法测试训练有素的网络。应用VGG16转移学习模型得到最优的结果,学习率为1e 5,因为它的训练精度为97.85,验证准确度高达89.38。开发的模型在发生地震时具有实时应用。 |
| Diving Deeper into Underwater Image Enhancement: A Survey Authors Saeed Anwar, Chongyi Li 深度学习的强大表现能力使得水下图像增强社区不可避免地利用其潜力。深水下图像增强网络的探索随着时间的推移而不断增加,因此全面的调查是小时的需要。在本文中,我们的主要目标是双重,1提供深入学习的水下图像增强的全面和深入的调查,涵盖从算法到开放问题的各种观点,以及2进行定性和定量比较各种数据集上的深层算法作为基准,以前几乎没有被探索过。具体而言,我们首先介绍了水下图像形成模型,它是深度网络训练数据综合和设计的基础,也有助于理解水下图像退化的过程。然后,我们回顾了深层水下图像增强算法,并提供了当前网络的一些方面的一瞥,包括网络架构,网络参数,训练数据,损失函数和训练配置。我们还总结了评估指标和水下图像数据集。接着,进行系统的实验比较,分析深度算法的鲁棒性和有效性。同时,我们指出了当前基准数据集和评估指标的缺点。最后,我们讨论了几个未解决的未决问题,并提出了可行的研究方向我们希望本文所做的一切努力可以作为未来研究的综合参考,并呼吁开发基于深度学习的水下图像增强。 |
| Understanding Video Content: Efficient Hero Detection and Recognition for the Game "Honor of Kings" Authors Wentao Yao, Zixun Sun, Xiao Chen 为了理解内容并自动提取国王荣誉游戏的视频标签,有必要在游戏视频中检测并识别称为英雄的角色及其营地。在本文中,我们提出了一种有效的两阶段算法来检测和识别游戏视频中的英雄。首先,我们根据血条模板匹配方法检测视频帧中的所有英雄,并根据他们的营地自己的朋友敌人进行分类。然后我们使用一个或多个深度卷积神经网络识别每个英雄的名字。我们的方法几乎不需要在识别阶段标记培训和测试样品。实验证明了它在游戏视频中英雄检测和识别任务的效率和准确性。 |
| Growing a Brain: Fine-Tuning by Increasing Model Capacity Authors Yu Xiong Wang, Deva Ramanan, Martial Hebert CNN通过学习具有大量注释训练集的高容量模型的能力,对计算机视觉产生了不可否认的影响。它们的一个显着特性是能够将知识从大型源数据集转移到通常较小的目标数据集。这通常通过在新目标数据上微调固定大小的网络来实现。实际上,几乎每个当代视觉识别系统都利用微调来从ImageNet传输知识。在这项工作中,我们分析微调期间哪些组件和参数发生了变化,并发现增加模型容量可以通过微调实现更自然的模型适应。通过对发展学习的类比,我们证明通过扩大现有层或加深整个网络来增加CNN和其他单元,明显优于传统的微调方法。但是为了正确地发展网络,我们表明必须对新增加的单元进行适当的标准化,以便实现与现有单元一致的学习速度。我们在几个基准数据集上凭经验验证了我们的方法,产生了最先进的结果。 |
| EEG-Based Emotion Recognition Using Regularized Graph Neural Networks Authors Peixiang Zhong, Di Wang, Chunyan Miao 在本文中,我们提出了一个基于EEG的情绪识别的正则化图神经网络RGNN。 EEG信号通过附着在其上的电极测量不同脑区域的神经元活动。现有研究没有有效地利用脑电信号的拓扑结构。我们的RGNN模型具有生物学支持,可捕获本地和全球的渠道间关系。此外,我们提出了两个正则化器,即NodeDAT和EmotionDL,以提高我们的模型在记录期间对抗交叉主题EEG变化和噪声标签的稳健性。为了彻底评估我们的模型,我们在两个公共数据集SEED和SEED IV上进行了主题依赖和主题独立分类设置的广泛实验。我们的模型在大多数任务中获得了比SVM,DBN,DGCNN,BiDANN和最先进的BiHDM等竞争基线更好的性能。我们的模型分析表明,我们提出的生物学支持的邻接矩阵和两个正则化器为我们的模型的性能贡献了一致和显着的增益。对神经元活动的调查显示,前额叶,顶叶和枕叶区域可能是情绪识别中信息最丰富的区域。另外,FP1,AF3,F6,F8和FP2,AF4之间的本地信道间关系也可以提供有用的信息。 |
| Unsupervised Task Design to Meta-Train Medical Image Classifiers Authors Gabriel Maicas, Cuong Nguyen, Farbod Motlagh, Jacinto C. Nascimento, Gustavo Carneiro 经验证明,元训练是用于医学图像分类器的少数镜头学习的最有效的预训练方法,即,用小训练集建模的分类器。然而,元培训的有效性依赖于合理数量的手工设计的分类任务的可用性,这些任务的获取成本很高,因此很少可用。在本文中,我们提出了一种新的方法来无监督地设计大量的分类任务到元训练医学图像分类器。我们评估了我们在乳房动态对比增强磁共振成像DCE MRI数据集上的方法,该数据集已被用于对医学图像分类器的几种射击训练方法进行基准测试。我们的研究结果表明,对元训练医学图像分类器提出的无监督任务设计建立了一个预训练模型,经过微调后,产生比其他无监督和监督预训练方法更好的分类结果,以及依赖于元训练的竞争结果。手工设计的分类任务。 |
| GRIP: Graph-based Interaction-aware Trajectory Prediction Authors Xin Li, Xiaowen Ying, Mooi Choo Chuah 如今,自动驾驶汽车已经商业化。然而,自动驾驶汽车的安全性仍然是一个尚未得到充分研究的具有挑战性的问题。运动预测是自动驾驶汽车的核心功能之一。在本文中,我们提出了一种名为GRIP的新方案,旨在有效地预测自动驾驶汽车周围的交通代理人的轨迹。 GRIP使用图表来表示近距离物体的相互作用,应用几个图形卷积块来提取特征,然后使用编码器解码器长期短期记忆LSTM模型进行预测。两个众所周知的公共数据集的实验结果表明,我们提出的模型将现有技术解决方案的预测精度提高了30。 GRIP的预测误差比现有方案短一米。这种改进可以帮助自动驾驶汽车避免许多交通事故。此外,拟议的GRIP运行速度比现有技术方案快5倍。 |
| Real-Time Highly Accurate Dense Depth on a Power Budget using an FPGA-CPU Hybrid SoC Authors Oscar Rahnama, Tommaso Cavallari, Stuart Golodetz, Alessio Tonioni, Thomas Joy, Luigi Di Stefano, Simon Walker, Philip H. S. Torr 从立体图像实时获得高度准确的深度在计算机视觉和机器人技术中有许多应用,但在某些情况下,功耗的上限限制了可嵌入平台(如FPGA)的可行硬件。虽然已经在这些平台上部署了各种立体算法,但通常缩减以更好地匹配嵌入式架构,更高级算法的某些关键部分,例如,那些依赖于不可预测的存储器访问或者本质上是高度迭代的那些,难以在FPGA上有效地部署,因此可以实现的深度质量是有限的。在本文中,我们利用FPGA CPU芯片提出了一种新颖,复杂的立体方法,该方法结合了基于SGM和ELAS的方法的最佳特性,可实时计算高精度的密集深度。我们的方法在超过50 FPS的挑战性KITTI 2015数据集上实现了8.7的错误率,功耗仅为5W。 |
| ++生成未知物体侧面顶面用于抓取Robust and fast generation of top and side grasps for unknown objects Authors Brice Denoun, Beatriz Leon, Claudio Zito, Rustam Stolkin, Lorenzo Jamone, Miles Hansard 在这项工作中,我们提出了一种基于几何的抓取算法,该算法能够使用单视图RGB D相机有效地生成未知对象的顶部和侧面抓取,并选择最有希望的一个。我们展示了我们的方法在真实机器人平台上的拣选方案的有效性。我们的方法已被证明比通过将成功的抓握尝试增加六倍而在抓握稳定性方面被认为是基线7的另一近期基于几何的方法更可靠。 |
| Automatic Grading of Individual Knee Osteoarthritis Features in Plain Radiographs using Deep Convolutional Neural Networks Authors Aleksei Tiulpin, Simo Saarakkala 膝关节骨性关节炎OA是世界上最常见的肌肉骨骼疾病。在初级保健中,膝关节OA通过临床检查和放射学评估来诊断。骨关节炎研究学会国际OARSI OA放射学特征图谱允许对膝骨赘,关节间隙变窄和其他膝关节特征进行独立评估。与黄金标准和最常用的Kellgren Lawrence KL综合评分相比,这提供了膝关节的细粒度OA严重程度评估。然而,OARSI和KL分级系统都受到中等程度的协议,因此,使用计算机辅助方法可以帮助提高过程的可靠性。在这项研究中,我们开发了一种强大的自动方法,可同时预测膝关节X线片中的KL和OARSI等级。我们的方法基于深度学习,并利用50层深度残余网络集合,挤压激励和ResNeXt块。在这里,我们使用ImageNet的转移学习,对整个Osteoarthritis Initiative OAI数据集进行了微调。在整个多中心骨关节炎研究MOST数据集上进行了对我们模型的独立测试。我们的多任务方法得出KL级的Cohen s kappa系数为0.82,股骨骨赘,胫骨骨赘和关节间隙分别为0.79,0.84,0.94,0.83,0.84,0.90。此外,我们的方法在ROC曲线下的面积为0.98,平均精度为0.98,用于检测射线照相OA KL geq 2的存在,这比现有技术更好。 |
| +发声器官Automatic vocal tract landmark localization from midsagittal MRI data Authors Mohammad Eslami, Christiane Neuschaefer Rube, Antoine Serrurier 通过改变围绕声道的发音器的形状和位置来获得语言的各种语音。分析它们的可变性对于理解语音产生,诊断言语和吞咽障碍以及建立直观的康复应用至关重要。磁共振成像MRI是目前用于此目的的最无害的强大成像模式。识别其上的关键解剖标志是进一步分析的先决条件。考虑到演讲者之间的高度可变性以及发音器之间的相互作用,这是一项具有挑战性的任务。本研究旨在首次自动解决此问题。为此目的,考虑了9个发声器的中间矢状解剖MRI,其支持62个关节并且注释了21个关键解剖标志的位置。包括深度学习方法在内的四种现有技术方法从文献中改编,用于面部标志定位和人体姿势估计并进行评估。此外,提出了一种基于每个界标位置的描述作为存储在嵌入所有界标的单个多通道图像的通道中的热图图像的方法。通过两个深度学习网络测试来自输入MRI图像的这种多通道图像的生成,一个取自文献,一个是在本研究中有意设计的平面网络。结果表明,扁平网方法优于其他方法,导致在扬声器上留一个程序获得的整体均方根误差为3.4像素0.34厘米。所有代码都可以在GitHub上公开获得。 |
| Event-based Feature Extraction Using Adaptive Selection Thresholds Authors Saeed Afshar, Ying Xu, Jonathan Tapson, Andr van Schaik, Gregory Cohen 无监督特征提取算法构成了机器学习系统中最重要的构建块之一。这些算法通常适用于基于事件的域,以在神经形态硬件中执行在线学习。然而,不是为此目的而设计的,这种算法通常在实现期间需要显着的简化以满足硬件约束,从而产生性能折衷。此外,传统的特征提取算法不是设计用于生成有用的中间信号,这些信号仅在神经形态硬件限制的情况下是有价值的。在这项工作中,提出了一种新的基于事件的特征提取方法,侧重于这些问题。该算法通过简单的自适应选择阈值进行操作,该阈值允许比以前的工作更简单地实现网络稳态,其通过以超出选择阈值的错过事件的形式折衷少量信息丢失。选择阈值的行为和整个网络的输出被示出为提供指示网络权重收敛的唯一有用信号,而无需访问网络权重。提出了一种新的网络规模选择启发式方法,利用噪声事件及其特征表示。显示选择阈值的使用产生网络激活模式,其预测分类准确性,允许快速评估和优化系统参数,而无需回退末端分类器。在N MNIST基准数据集和通过视野的飞机数据集上测试特征提取方法。测试具有不同分类器的多个配置,其结果量化在每个处理阶段的结果性能增益。 |
| A fully 3D multi-path convolutional neural network with feature fusion and feature weighting for automatic lesion identification in brain MRI images Authors Yunzhe Xue, Meiyan Xie, Fadi G. Farhat, Olga Boukrina, A. M. Barrett, Jeffrey R. Binder, Usman W. Roshan, William W. Graves 脑MRI图像由以连续空间间隔堆叠的多个2D图像组成,以形成3D结构。因此,使用具有3D卷积核的卷积神经网络似乎是自然的,其将自动地还解释切片之间的空间依赖性。然而,由于训练数据不足导致过度拟合,3D模型在实践中仍然是一个挑战。例如,在2D模型中,我们通常每个患者平面具有150个300个切片,而在3D设置中,这减少到仅一个点。在这里,我们提出了一个完全3D多路径卷积网络,其中包含定制设计的组件,以更好地利用多种模态的功能。特别地,我们的多路径模型具有用于不同模态的独立编码器,其包含残余卷积块,来自不同模态的加权多路径特征融合,以及用于组合编码器和解码器特征的加权融合模块。我们为不同的组件提供直观的推理以及经验证据,以证明它们有效。与现有的3D CNN(如DeepMedic,3D U Net和AnatomyNet)相比,我们的网络在220名患者的大型ATLAS基准测试中实现了60.5的最高统计学显着交叉验证准确度。我们还在凯斯勒基金会和威斯康星医学院的多模态图像上测试我们的模型,并获得65的统计上显着的交叉验证准确度,明显优于多模式3D U Net和DeepMedic。总体而言,我们的模型提供了一种有原则的,可扩展的多路径方法,其优于多通道替代方案,并在现有基准测试中实现了高骰子精度。 |
| OmniNet: A unified architecture for multi-modal multi-task learning Authors Subhojeet Pramanik, Priyanka Agrawal, Aman Hussain Transformer是一种广泛使用的神经网络架构,尤其适用于语言理解。我们引入了一个扩展的统一架构,可用于涉及各种模态的任务,如图像,文本,视频等。我们提出了一种空间缓存机制,除了对应的隐藏状态外,还可以学习输入的空间维度。时间输入序列。所提出的架构进一步使单个模型能够支持具有多个输入模态的任务以及异步多任务学习,因此我们将其称为OmniNet。例如,OmniNet的单个实例可以同时学习执行词性标注,图像字幕,视觉问答和视频活动识别的任务。我们证明,将这四个任务一起训练可以产生大约三倍的压缩模型,同时保持性能,而不是单独训练它们。我们还表明,使用这种预先训练过某些模态的神经网络有助于学习一项看不见的任务。这说明了自我关注机制对OmniNet中存在的空间时间缓存的泛化能力。 |
| Design and Evaluation of Product Aesthetics: A Human-Machine Hybrid Approach Authors Alex Burnap, John R. Hauser, Artem Timoshenko 在许多产品类别中,美学对于市场接受度至关重要。特别是在汽车工业中,改进的美学设计可以将销售额提高30或更多。公司在设计和测试新产品美学方面投入了大量资金。一个汽车主题诊所的费用在100,000到1,000,000之间,每年有数百个。在设计和测试新产品美学时,我们使用机器学习来增强人类的判断力。该模型结合了概率变分自动编码器VAE和来自生成对抗网络GAN的对抗性组件,以及解决公司采用的管理要求的建模假设。我们使用来自汽车合作伙伴的数据训练我们的模型,目标消费者评估7,000张图像,以及180,000张高质量的未评级图像。我们的模型很好地预测了新美学设计的吸引力相对于基线和相对于传统机器学习模型和预训练深度学习模型的实质性改进。新的汽车设计以可控的方式生成,供设计团队考虑,我们也经验验证这些设计对消费者有吸引力。这些结果将人力和机器输入结合起来用于实际管理使用,这表明机器学习为增强美学设计提供了重要机会。 |
| Patient-specific Conditional Joint Models of Shape, Image Features and Clinical Indicators Authors Bernhard Egger, Markus D. Schirmer, Florian Dubost, Marco J. Nardin, Natalia S. Rost, Polina Golland 我们提出并展示了解剖形状,图像特征和临床指标的联合模型,用于统计形状建模和医学图像分析。关键思想是采用copula模型将联合依赖结构与感兴趣变量的边际分布分开。这种分离为建模过程中的假设提供了灵活性。所提出的方法可以处理二元,离散,序数和连续变量。我们演示了一种将二元,离散和序数变量包含在建模中的简单而有效的方法。我们基于观察到的基于捕获依赖结构的高斯过程的部分临床指标,特征或形状来构建贝叶斯条件模型。我们将所提出的方法应用于中风数据集,以共同模拟侧脑室的形状,与脑室周围白质病相关的白质高信号的空间分布和临床指标。所提出的方法产生可解释的用于数据探索的关节模型和用于医学图像分析的患者特定统计形状模型。 |
| End-to-end sensor modeling for LiDAR Point Cloud Authors Khaled Elmadawi, Moemen Abdelrazek, Mohamed Elsobky, Hesham M. Eraqi, Mohamed Zahran 先进的传感器是实现自动驾驶汽车技术的关键。激光扫描仪传感器LiDAR,光探测和测距成为一个基本选择,因为它具有远距离和低光驾驶条件的稳健性。设计用于自动驾驶汽车的控制软件的问题是在基于规则的系统中明确制定的复杂任务,因此最近的方法依赖于可以从数据学习这些规则的机器学习。这种方法的主要问题是推广机器学习模型所需的训练数据量很大,另一方面,与其他汽车传感器相比,LiDAR数据注释成本非常高。精确的LiDAR传感器模型可以应对这种问题。此外,它的价值超出了这个范围,因为现有的LiDAR开发,验证和评估平台和流程成本非常高,虚拟测试和开发环境在物理属性表示方面仍然不成熟。在这项工作中,我们提出了一种基于深度学习的新型LiDAR传感器模型。该方法使用深度神经网络模拟传感器回波,使用Polar Grid Maps PGM对从实际数据中学习的回波脉冲宽度进行建模。我们将模型性能与全面的真实传感器数据进行对比,并实现了非常有希望的结果,为未来的工作奠定了基准。 |
| Deep Multi-View Learning via Task-Optimal CCA Authors Heather D. Couture, Roland Kwitt, J.S. Marron, Melissa Troester, Charles M. Perou, Marc Niethammer 典型相关分析CCA广泛用于多模态数据分析,最近,用于多视图学习等判别任务,但它不使用类标签。最近的CCA方法已经开始解决这个弱点,但是受到限制,因为它们不能同时优化用于区分的CCA投影和CCA投影本身,或者它们仅是线性的。我们通过以端到端方式同时优化基于CCA和任务目标来解决这些缺陷。总之,这两个目标学习了一个非线性CCA投影到一个高度相关和区别的共享潜在空间。我们的方法显示出对先前技术水平的显着改进,包括用于交叉视图分类的深度监督方法,具有第二视图的正则化,以及对实际数据的半监督学习。 |
| CU-Net: Cascaded U-Net with Loss Weighted Sampling for Brain Tumor Segmentation Authors Hongying Liu, Xiongjie Shen, Fanhua Shang, Fei Wang 本文提出了一种用于脑肿瘤分割的新型级联U网。受脑肿瘤分层结构的独特启发,我们设计了一个级联的深层网络框架,其中首先对整个肿瘤进行分割,然后进一步分割肿瘤内部子结构。考虑到级联结构带来的网络深度的增加导致更深层中精确定位信息的丢失,我们构建了许多跳过连接以在相同分辨率下链接特征,并将详细信息从浅层传输到更深层。然后,我们提出了一种损失加权采样LWS方案,以消除网络训练期间不平衡数据的问题。 BraTS 2017数据的实验结果表明,我们的架构框架优于现有的分割算法,特别是在分割灵敏度方面。 |
| Lung Nodules Detection and Segmentation Using 3D Mask-RCNN Authors Evi Kopelowitz, Guy Engelhard 准确评估肺结节是放射科医师解释工作中耗时且容易出错的成分。自动化3D体积检测和分割可以改善工作流程以及患者护理。以前的工作重点是从全CT扫描中检测肺结节或从小ROI中分割它们。我们采用最先进的架构进行2D物体检测和分割,MaskRCNN,处理3D图像,并用它来检测和分割CT扫描的肺结节。我们报告了LUNA16数据集上肺结节检测的竞争结果。我们的方法的附加值是除了肺结节检测之外,我们的框架产生检测到的结节的3D分割。 |
| Chinese Abs From Machine Translation |
Papers from arxiv.org
更多精彩请移步主页
pic from pexels.com