########################################面向对象初识#########################################
面向对象简介
面向对象编程——Object Oriented Programming,简称OOP,是一种程序设计思想。OOP把对象作为程序的基本单元,一个对象包含了数据和操作数据的函数。面向过程的程序设计把计算机程序视为一系列的命令集合,即一组函数的顺序执行。为了简化程序设计,面向过程把函数继续切分为子函数,即把大块函数通过切割成小块函数来降低系统的复杂度。而面向对象的程序设计把计算机程序视为一组对象的集合,而每个对象都可以接收其他对象发过来的消息,并处理这些消息,计算机程序的执行就是一系列消息在各个对象之间传递。
在Python中,所有数据类型都可以视为对象,当然也可以自定义对象。自定义的对象数据类型就是面向对象中的类(Class)的概念;面向对象最重要的概念就是类(Class)和实例(Instance),必须牢记类是抽象的模板。
引子需求
假如你现在是一家游戏公司的开发人员,现在需要你开发一款叫做<人狗大战>的游戏,你就思考呀,人狗作战,那至少需要2个角色,一个是人, 一个是狗,且人和狗都有不同的技能,比如人拿棍打狗, 狗可以咬人,怎么描述这种不同的角色和他们的功能呢?
###创建角色的代码### def person(name,age,sex,job): data = { 'name':name, 'age':age, 'sex':sex, 'job':job } return data def dog(name,dog_type): data = { 'name':name, 'type':dog_type } return data #上面两个方法相当于造了两个模子,游戏开始,你得生成一个人和狗的实际对象吧,怎么生成呢?如下: ###为角色生成具体的对象### d1 = dog("Alex","京巴") p1 = person("严帅",36,"F","运维") p2 = person("林海峰",27,"F","Teacher") #两个角色对象生成了,狗和人还有不同的功能呀,狗会咬人,人会打狗,对不对? 怎么实现呢,。。想到了, 可以每个功能再写一个函数,想执行哪个功能,直接 调用 就可以了,对不? ###定义功能属性### def bark(d): print("dog %s:wang.wang..wang..." % d['name']) def walk(p): print("person %s is walking..." % p['name']) walk(p1) bark(d1) ###整体代码及运行结果### def person(name, age, sex, job): data = { 'name': name, 'age': age, 'sex': sex, 'job': job, # 'walk': walk } return data def dog(name, dog_type): data = { 'name': name, 'type': dog_type, # 'bark': bark } return data def bark(d): print("dog %s:wang.wang..wang..." % d['name']) def walk(p): print("person %s is walking..." % p['name']) d1 = dog("李磊","京巴") p1 = person("严帅",36,"F","运维") p2 = person("林海峰",27,"F","Teacher") walk(p1) bark(d1) """#运行结果: C:\Python35\python.exe D:/Python代码目录/Python_codeing/Python16_code/day06/面向对象.py person 严帅 is walking... dog 李磊:wang.wang..wang... Process finished with exit code 0 """ #上面的功能实现的简直是完美!但是仔细玩耍一会,你就不小心干了下面这件事 bark(p1) #把dog的方法传给了person """#运行结果: dog 严帅:wang.wang..wang... """ #虽然,运行并没出错,但是事实上,人是不能调用狗的功能的,如何在代码级别实现这个限制呢? ###优化版代码#### def person(name, age, sex, job): def walk(p): #添加person的技能 print("person %s is walking..." % p['name']) data = { 'name': name, 'age': age, 'sex': sex, 'job': job, 'walk': walk #引用person的技能 } return data def dog(name, dog_type): def bark(d): #添加dog的技能 print("dog %s:wang.wang..wang..." % d['name']) data = { 'name': name, 'type': dog_type, 'bark': bark #调用dog的 } return data d1 = dog("李磊","京巴") p1 = person("严帅",36,"F","运维") p2 = person("林海峰",27,"F","Teacher") d1['bark'](p1) d1['bark'](d1) p1['walk'](p1) p1['walk'](d1)
面向过程与面向对象
编程方式
提起编程就不得不说到编程范式!编程是 程序 员 用特定的语法+数据结构+算法组成的代码来告诉计算机如何执行任务的过程 , 一个程序是程序员为了得到一个任务结果而编写的一组指令的集合,正所谓条条大路通罗马,实现一个任务的方式有很多种不同的方式, 对这些不同的编程方式的特点进行归纳总结得出来的编程方式类别,即为编程范式。 不同的编程范式本质上代表对各种类型的任务采取的不同的解决问题的思路, 大多数语言只支持一种编程范式,当然也有些语言可以同时支持多种编程范式。 两种最重要的编程范式分别是面向过程编程和面向对象编程。
面向过程编程
面向过程编程(Procedural Programming)依赖 - 你猜到了- procedures,一个procedure包含一组要被进行计算的步骤, 面向过程又被称为top-down languages, 就是程序从上到下一步步执行,一步步从上到下,从头到尾的解决问题 。基本设计思路就是程序一开始是要着手解决一个大的问题,然后把一个大问题分解成很多个小问题或子过程,这些子过程再执行的过程再继续分解直到小问题足够简单到可以在一个小步骤范围内解决。
######典型的面向过程事例######:
def db_conn(): print("connecting db...") def db_backup(dbname): print("导出数据库...",dbname) print("将备份文件打包,移至相应目录...") def db_backup_test(): print("将备份文件导入测试库,看导入是否成功") def main(): db_conn() db_backup('my_db') db_backup_test() if __name__ == '__main__': main() """ 这样做的问题也是显而易见的,就是如果你要对程序进行修改,对你修改的那部分有依赖的各个部分你都也要跟着修改, 举个例子,如果程序开头你设置了一个变量值 为1 , 但如果其它子过程依赖这个值 为1的变量才能正常运行,那如果你改了这个变量,那这个子过程你也要修改,假如又有一个其它子程序依赖这个子过程 , 那就会发生一连串的影响,随着程序越来越大, 这种编程方式的维护难度会越来越高。 所以我们一般认为, 如果你只是写一些简单的脚本,去做一些一次性任务,用面向过程的方式是极好的,但如果你要处理的任务是复杂的,且需要不断迭代和维护 的, 那还是用面向对象最方便了。 """
面向对象编程
编程是利用“类”和“对象”来创建各种模型来实现对真实世界的描述,使用面向对象编程的原因一方面是因为它可以使程序的维护和扩展变得更简单,并且可以大大提高程序开发效率 ,另外,基于面向对象的程序可以使它人更加容易理解你的代码逻辑,从而使团队开发变得更从容。
面向对象的几个核心特性如下:
###Class 类### '''一个类即是对一类拥有相同属性的对象的抽象、蓝图、原型。在类中定义了这些对象的都具备的属性(variables(data))、共同的方法''' ###Object 对象### '''一个对象即是一个类的实例化后实例,一个类必须经过实例化后方可在程序中调用,一个类可以实例化多个对象,每个对象亦可以有不同的属性,就像人类是指所有人,每个人是指具体的对象,人与人之前有共性,亦有不同''' ###Encapsulation 封装### '''在类中对数据的赋值、内部调用对外部用户是透明的,这使类变成了一个胶囊或容器,里面包含着类的数据和方法''' ###Inheritance 继承### '''一个类可以派生出子类,在这个父类里定义的属性、方法自动被子类继承''' ###Polymorphism 多态### '''多态是面向对象的重要特性,简单点说:“一个接口,多种实现”,指一个基类中派生出了不同的子类,且每个子类在继承了同样的方法名的同时又对父类的方法做了不同的实现,这就是同一种事物表现出的多种形态。 编程其实就是一个将具体世界进行抽象化的过程,多态就是抽象化的一种体现,把一系列具体事物的共同点抽象出来, 再通过这个抽象的事物, 与不同的具体事物进行对话。 对不同类的对象发出相同的消息将会有不同的行为。比如,你的老板让所有员工在九点钟开始工作, 他只要在九点钟的时候说:“开始工作”即可,而不需要对销售人员说:“开始销售工作”,对技术人员说:“开始技术工作”, 因为“员工”是一个抽象的事物, 只要是员工就可以开始工作,他知道这一点就行了。至于每个员工,当然会各司其职,做各自的工作。 多态允许将子类的对象当作父类的对象使用,某父类型的引用指向其子类型的对象,调用的方法是该子类型的方法。这里引用和调用方法的代码编译前就已经决定了,而引用所指向的对象可以在运行期间动态绑定'''
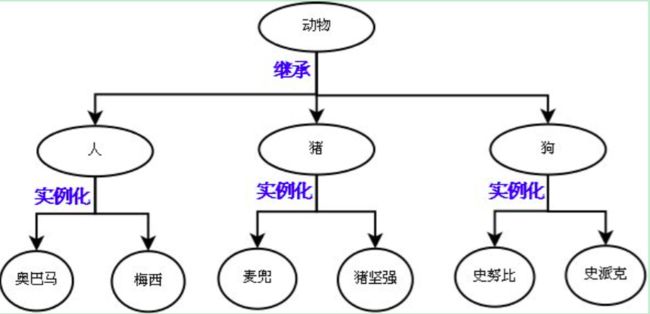
类的声明与调用:
class Person(object): age = 22 #类变量,存在类的内存地址里,可以被所有势力共享引用() def __init__(self,name,type): #__init__用以初始化函数(构造函数) self.name = name #self.name <==>p.name <==> name self.type = type #self.type <==>p.type <==> type self.age = 26 def walk(self): print("[%s] I am a person"%self.name) def eat(self,food): print("[%s] eating [%s]"%(self.name,food)) p = Person("chunge","police") #实例化对象 Person.age = 25 print(p.age) print(p.name,p.type) p.walk() p.eat("apple") """#运行结果: C:\Python35\python.exe D:/Python代码目录/Python_codeing/Python16_code/day06/面向对象之class类.py 26 chunge police [chunge] I am a person [chunge] eating [apple] Process finished with exit code 0 """
类变量|实例变量|公有属性|私有属性
''' 类变量: 作为默认公有属性 全局修改 或增加 实例变量(成员属性): 构造函数的所有变量都是实例变量 每个实例存在自己内存空间里的属性 公有属性 == 类变量 私有属性 self.__sex 代表私有属性,仅能在实例的内部各函数(方法)中调用 隐藏一些功能实现的细节,只给外部暴露结果或可以被调用的接口 ''' class People(object): nationality = "CN" def __init__(self,name,age,job,sex): self.name = name self.age = age self.job = job self.__sex = sex #私有属性定义 def get_sex(self): #让外部仅仅可以查看、调用私有属性 return self.__sex def go_to_wc(self): if self.__sex == "F": print("stand up ...") else: print("shutdown ...") p = People("chunge",22,"IT","F") p1 = People("Viv",22,"IT","F") p2 = People("halen",28,"teacher","N") #print(p.tools) People.tools = "Car" #类变量(所有对象都会有) p1.hobbit = "eating" #实例变量(具体的成员才有) p2.go_to_wc() #私有属性内部调用 print(p.tools, p1.tools, p1.hobbit, p2.get_sex() #获取私有属性(不能修改) ) """#运行结果 C:\Python35\python.exe D:/Python代码目录/Python_codeing/Python16_code/day06/面向对象之class类.py shutdown ... Car Car eating N Process finished with exit code 0 """
继承
'''
面向对象编程 (OOP) 语言的一个主要功能就是“继承”。继承是指这样一种能力:它可以使用现有类的所有功能,并在无需重新编写原来的类的情况下对这些功能进行扩展。通过继承创建的新类称为“子类”或“派生类”。被继承的类称为“基类”、“父类”或“超类”。继承的过程,就是从一般到特殊的过程。要实现继承,可以通过“继承”(Inheritance)和“组合”(Composition)来实现。 一般情况下,一个子类只能有一个基类,要实现多重继承,可以通过多级继承来实现。 继承概念的实现方式主要有2类:实现继承、接口继承。 实现继承:是指使用基类的属性和方法而无需额外编码的能力; 接口继承:是指仅使用属性和方法的名称、但是子类必须提供实现的能力(子类重构爹类方法)
''' ######实例代码###### class SchoolMember(object): members = 0 #用以统计成员数 def __init__(self,name,age,sex): #构造方法 self.name = name self.age = age self.sex = sex SchoolMember.members +=1 #每进行一个成员的实例化,计数就自动加1 print("初始化了一个新学校成员",self.name) def self_msg(self): info = ''' ------info of %s------ name: %s age : %s sex : %s '''%(self.name,self.name,self.age,self.sex) print(info) def __del__(self): #析构方法 print("%s 被删除了"%self.name) SchoolMember.members -= 1 #删除成员后,计数自动减1 class Teacher(SchoolMember): def __init__(self,name,age,sex,salary): SchoolMember.__init__(self,name,age,sex) #手动调用(继承并重构父类【此处传值实例本身self】) #self.name = name #t.name=name self.salary = salary #添加新的属性 def teaching(self,course): print("%s is teaching %s"%(self.name,course)) class Student(SchoolMember): def __init__(self,name,age,sex,grade): SchoolMember.__init__(self,name,age,sex) #self.name = name #t.name=name self.grade = grade def pay_study_money(self,amount): self.pay_study_money = amount print("student %s has paid study money %s"%(self.name,amount)) t = Teacher("chunge",24,"F","12000") #实例化一个teacher s = Student("wu",22,"F","pys16") #实例化一个student s1 = Student("qi",22,"M","pys19") del s #删除一个成员 t.teaching("php") # t.self_msg() print(SchoolMember.members) #打印成员统计数 """ 继承小结: 1)直接调用父类方法 2)继承父类方法并重构父类方法,先重构,在重构的方法里手动调用父类方法 3)可以定义子类自己的方法 4)析构方法 __del__ """
########################################面向对象进阶#########################################
组合
''' 软件重用的重要方式除了继承之外还有另外一种方式,即:组合 组合指的是,在一个类中以另外一个类的对象作为数据属性,称为类的组合 ''' class Teacher: def __init__(self,name,birth,course): self.name = name self.birth = birth #self.birth = Date(1991,1,23) self.course = course #self.course=Course('python',12345,'6mons') class Course: def __init__(self,name,price,period): self.name = name self.price = price self.priiod = period class Date: def __init__(self,year,month,day): self.year = year self.month = month self.day = day t = Teacher("Vgirl",Date(1991,1,23),Course('python',12345,'6mons')) print(t.birth.year, t.birth.month, t.birth.day ) """#运行结果: C:\Python35\python.exe D:/Python代码目录/Python_codeing/Python16_code/day07/类的组合.py 1991 1 23 Process finished with exit code 0 """
接口与归一化设计
接口提取了一群类共同的函数,可以把接口当做一个函数的集合。然后让子类去实现接口中的函数。这么做的意义在于归一化,什么叫归一化,就是只要是基于同一个接口实现的类,那么所有的这些类产生的对象在使用时,从用法上来说都一样。
归一化,让使用者无需关心对象的类是什么,只需要的知道这些对象都具备某些功能就可以了,这极大地降低了使用者的使用难度。
class AllFile: #接口类 def read(self): #接口函数 pass def write(self): pass class Sata(AllFile): def read(self): print('stat read') def write(self): print('stat write')
抽象类与归一化设计
""" 1)什么是抽象类 与java一样,python也有抽象类的概念但是同样需要借助模块实现,抽象类是一个特殊的类,它的特殊之处在于只能被继承,不能被实例化 2)为什么要有抽象类 如果说类是从一堆对象中抽取相同的内容而来的,那么抽象类就是从一堆类中抽取相同的内容而来的,内容包括数据属性和函数属性。比如我们有香蕉的类,有苹果的类,有桃子的类,从这些类抽取相同的内容就是水果这个抽象的类,你吃水果时,要么是吃一个具体的香蕉,要么是吃一个具体的桃子。。。。。。你永远无法吃到一个叫做水果的东西。从设计角度去看,如果类是从现实对象抽象而来的,那么抽象类就是基于类抽象而来的。从实现角度来看,抽象类与普通类的不同之处在于:抽象类中只能有抽象方法(没有实现功能),该类不能被实例化,只能被继承,且子类必须实现抽象方法。 3) 抽象类与接口 抽象类的本质还是类,指的是一组类的相似性,包括数据属性(如all_type)和函数属性(如read、write),而接口只强调函数属性的相似性。抽象类是一个介于类和接口直接的一个概念,同时具备类和接口的部分特性,可以用来实现归一化设计 """ import abc class AllFile(metaclass=abc.ABCMeta): #抽象类 @abc.abstractmethod def read(self): pass @abc.abstractmethod def write(self): pass class Text(AllFile): def read(self): print('text read') def write(self): pass t =Text() #抽象类继承必须重写,(TypeError: Can't instantiate abstract class Text with abstract methods write) a = AllFile() #抽象类本身不能被实例化,只能被用来继承(TypeError: Can't instantiate abstract class AllFile with abstract methods read, write)
多态与多态性
多态:指的是一类事物有多种形态,(一个抽象类有多个子类,因而多态的概念依赖于继承)
多态性:是指具有不同功能的函数可以使用相同的函数名,这样就可以用一个函数名调用不同功能的函数。
#定义一个总的Animal类 class Animal: def talk(self): pass #定义People、Pig、Dog、Cat类,并分别继续Animal类 class People(Animal): def talk(self): print('say hello') class Pig(Animal): def talk(self): print('say aoao') class Dog(Animal): def talk(self): print('say wangwang') class Cat(Animal): def talk(self): print('say miaomiao') #实例化People、Dog、。。对象 peo=People() pig=Pig() dog=Dog() cat=Cat() def func(obj): obj.talk() func(peo) func(pig) func(dog) func(cat)
封装
""" 封装根据字面意思就相当于把某个特征进行隐藏 封装有两个重要意义: 1)封装数据的主要原因是保护隐私 2)封装方法的主要原因是隔离复杂度 封装氛围两个层面: 第一个层面的封装(什么都不用做):创建类和对象会分别创建二者的名称空间,我们只能用类名.或者obj.的方式去访问里面的名字,这本身就是一种封装【对于这一层面的封装(隐藏),类名.和实例名.就是访问隐藏属性的接口】 第二个层面的封装:类中把某些属性和方法隐藏起来(或者说定义成私有的),只在类的内部使用、外部无法访问,或者留下少量接口(函数)供外部访问【在python中用双下划线的方式实现隐藏属性(设置成私有的)】 """ ######第一种封装###### #fengzhuang.py内容 class Foo: x = 1 def __init__(self, name): self.name = name #fengzhaung-test.py内容 from fengzhuang import Foo print(Foo.x) f=Foo('Viv') ######第二种封装###### class Foo: x = 1 def __init__(self,name,money): self.name=name self.__money=money #会变形为self._Foo_money def get_money(self): print(self.__money) #只能在类的内部才能访问到 f=Foo('Viv',1680000) # print(f.__money) #外部调用错误(相当于变相隐藏)【f._Foo__money即可正确得到结果】 f.get_money() print(f.__dict__) # print(Foo.__dict__) #类的字典
"""实例:
class Msg:
def __init__(self,name,age,gender,money):
self.__name=name
self.__age=age
self.__gender=gender
self.__money=money
def show_info(self): #内存才能直接获取
print(self.__name,
self.__age,
self.__gender,
self.__gender
)
m1=Msg('Vgirl',25,'man',11800)
m1.show_info()
"""
类中所有双下划线开头的名称如__x都会自动变形成:_类名__x的形式:
###实例1### class A: __N=0 #类的数据属性就应该是共享的,但是语法上是可以把类的数据属性设置成私有的如__N,会变形为_A__N def __init__(self): self.__X=10 #变形为self._A__X def __foo(self): #变形为_A__foo print('from A') def bar(self): self.__foo() #只有在类内部才可以通过__foo的形式访问到.
''' 这种自动变形的特点: 1)类中定义的__x只能在内部使用,如self.__x,引用的就是变形的结果。 2)这种变形其实正是针对外部的变形,在外部是无法通过__x这个名字访问到的。 3)在子类定义的__x不会覆盖在父类定义的__x,因为子类中变形成了:_子类名__x,而父类中变形成了:_父类名__x,即双下滑线开头的属性在继承给子类时,子类是无法覆盖的。 注意:对于这一层面的封装(隐藏),我们需要在类中定义一个函数(接口函数)在它内部访问被隐藏的属性,然后外部就可以使用了 '''
python要想与其他编程语言一样,严格控制属性的访问权限,只能借助内置方法如__getattr__
变形需要注意的问题


>>> a=A() >>> a._A__N 0 >>> a._A__X 10 >>> A._A__N 0
>>>a = A() >>>a.__dict__ {'_A__X': 10} >>>a.__XYX=1 >>>a.__dict__ {'_A__X': 10, '__XYX': 1}
###正常情况### >>> class A: ... def fa(self): ... print('from A') ... def test(self): ... self.fa() ... >>> class B(A): ... def fa(self): ... print('from B') ... >>> b=B() >>> b.test() from B ###把fa定义成私有的,即__fa### >>> class A: ... def __fa(self): #在定义时就变形为_A__fa ... print('from A') ... def test(self): ... self.__fa() #只会与自己所在的类为准,即调用_A__fa ... >>> class B(A): ... def __fa(self): ... print('from B') ... >>> b=B() >>> b.test() from A
""" python并不会真的阻止你访问私有的属性,模块也遵循这种约定,如果模块名以单下划线开头,那么from module import *时不能被导入,但是你from module import _private_module依然是可以导入的 其实很多时候你去调用一个模块的功能时会遇到单下划线开头的(socket._socket,sys._home,sys._clear_type_cache),这些都是私有的,原则上是供内部调用的,作为外部的你,一意孤行也是可以用的,只不过显得稍微傻逼一点点 python要想与其他编程语言一样,严格控制属性的访问权限,只能借助内置方法如__getattr__, """
特性
特性(property):是一种特殊的属性,访问它时会执行一段功能(函数)然后返回值【用来提供接口与的一种方式】
###特性:用来提供接口的一种方式 import math class Circle: #定义圆的类 def __init__(self,radius): #圆的半径radius self.__radius=radius @property #area = property(area) def area(self): return math.pi * self.__radius**2 #计算圆的面积 @property #perimeter = property(perimeter) def perimeter(self): return 2*math.pi*self.__radius #计算圆的周长 c=Circle(10) print(c.area) print(c.perimeter) '''运行结果 314.1592653589793 62.83185307179586 ''' #将一个类的函数定义成特性以后,对象再去使用的时候obj.name,根本无法察觉自己的name是执行了一个函数然后计算出来的,这种特性的使用方式遵循了统一访问的原则 """ 面向对象的封装有三种方式: 【public】 这种其实就是不封装,是对外公开的 【protected】 这种封装方式对外不公开,但对朋友(friend)或者子类(形象的说法是“儿子”,但我不知道为什么大家 不说“女儿”,就像“parent”本来是“父母”的意思,但中文都是叫“父类”)公开 【private】 这种封装对谁都不公开 """ python并没有在语法上把它们三个内建到自己的class机制中,在C++里一般会将所有的所有的数据都设置为私有的,然后提供set和get方法(接口)去设置和获取,在python中通过property方法可以实现 #####实例: class A: def __init__(self,name): self.__name = name @property def name(self): return self.__name @name.setter def name(self,value): if not isinstance(value,str): raise TypeError('%s must be str'%value) #异常处理 self.__name = value @name.deleter def name(self): print("=======>") raise AttributeError('can not delete') #异常处理,禁止删除 a = A('Viv') print(a.name) # a.name =2 #TypeError: 2 must be str a.name = 'hello' print(a.name) del a.name #AttributeError: can not delete
封装与扩展性
""" 封装在于明确区分内外,使得类实现者可以修改封装内的东西而不影响外部调用者的代码;而外部使用用者只知道一个接口(函数),只要接口(函数)名、参数不变,使用者的代码永远无需改变。这就提供一个良好的合作基础——或者说,只要接口这个基础约定不变,则代码改变不足为虑。 """ ###类的设计者 class Room: def __init__(self,name,owner,width,length,high): self.name=name self.owner=owner self.__width=width self.__length=length self.__high=high def tell_area(self): #对外提供的接口,隐藏了内部的实现细节,此时我们想求的是面积 return self.__width * self.__length ###使用者 >>> r1=Room('卧室','egon',20,20,20) >>> r1.tell_area() #使用者调用接口tell_area 400 ###类的设计者,轻松的扩展了功能,而类的使用者完全不需要改变自己的代码 class Room: def __init__(self,name,owner,width,length,high): self.name=name self.owner=owner self.__width=width self.__length=length self.__high=high def tell_area(self): #对外提供的接口,隐藏内部实现,此时我们想求的是体积,内部逻辑变了,只需求修该下列一行就可以很简答的实现,而且外部调用感知不到,仍然使用该方法,但是功能已经变了 return self.__width * self.__length * self.__high '''对于仍然在使用tell_area接口的人来说,根本无需改动自己的代码,就可以用上新功能''' >>> r1.tell_area() 8000
继承实现的原理(顺序继承)
顺序继承
1)Python的类可以继承多个类,JAVA和C#则只能继承一个类 2)Python的类如果继承了多个类,那么其寻找方法的方式有两种,分别是:深度优先和广度优先 当类为经典类时,多继承情况下,会按照深度优先方式查找 当类是新式类时,多继承情况下,会按照广度优先方式查找 经典类和新式类,从字面上可以看出一个老一个新,新的必然包含了更多的功能,也是之后推荐的方法,从写法上区分的话,如果当前类或则父类继承了object类,那么该类便是新式类,否则便是经典类
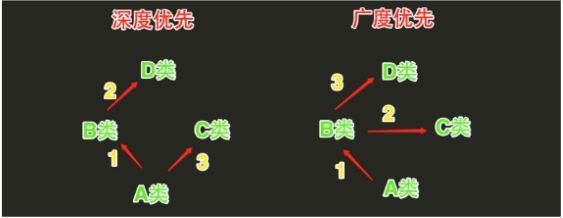

顺序继承实例:
class A(object): def test(self): print('from A') class B(A): def test(self): print('from B') class C(A): def test(self): print('from C') class D(B): def test(self): print('from D') class E(C): def test(self): print('from E') class F(D,E): # def test(self): # print('from F') pass f1=F() f1.test() print(F.__mro__) #只有新式才有这个属性可以查看线性列表,经典类没有这个属性 #新式类继承顺序:F->D->B->E->C->A #经典类继承顺序:F->D->B->A->E->C #python3中统一都是新式类 #pyhon2中才分新式类与经典类
继承原理(Python是如何实现的继承)
""" python到底是如何实现继承的,对于你定义的每一个类,python会计算出一个方法解析顺序(MRO)列表,这个MRO列表就是一个简单的所有基类的线性顺序列表,例如: >>> F.mro() #等同于F.__mro__ [, """, , , , , ] 为了实现继承,python会在MRO列表上从左到右开始查找基类,直到找到第一个匹配这个属性的类为止。 而这个MRO列表的构造是通过一个C3线性化算法来实现的。我们不去深究这个算法的数学原理,它实际上就是合并所有父类的MRO列表并遵循如下三条准则: 1.子类会先于父类被检查 2.多个父类会根据它们在列表中的顺序被检查 3.如果对下一个类存在两个合法的选择,选择第一个父类
子类调用父类方法
子类继承了父类的方法,然后想进行修改,注意了是基于原有的基础上修改,那么就需要在子类中调用父类的方法
两种方式实现子类调用父类方法:
1)父类名.父类方法()
2)super()
class People: def __init__(self,name,age,gender): self.name = name self.age = age self.gender = gender def test(self): print('from A.test') class Teacher(People): def __init__(self,name,age,gender,level): # People.__init__(self,name,age,gender) #super().__init__(name,age,gender) 两者等价 super().__init__(name, age, gender) #推荐写法 self.level=level t = Teacher('Vi',18,'f','高级职称') print(t.level) '''运行结果: C:\Python35\python.exe D:/Python代码目录/Python_codeing/Python16_code/day07/子类调用父类的方法.py 高级职称 Process finished with exit code 0 '''
######第一种:父类名.父类方法() class Vehicle: #定义交通工具类 Country='China' def __init__(self,name,speed,load,power): self.name=name self.speed=speed self.load=load self.power=power def run(self): print('开动啦...') class Subway(Vehicle): #地铁 def __init__(self,name,speed,load,power,line): Vehicle.__init__(self,name,speed,load,power) self.line=line def run(self): print('地铁%s号线欢迎您' %self.line) Vehicle.run(self) line13=Subway('中国地铁','180m/s','1000人/箱','电',13) line13.run() ######第二种:super方式 class Vehicle: #定义交通工具类 Country='China' def __init__(self,name,speed,load,power): self.name=name self.speed=speed self.load=load self.power=power def run(self): print('开动啦...') class Subway(Vehicle): #地铁 def __init__(self,name,speed,load,power,line): #super(Subway,self) 就相当于实例本身 在python3中super()等同于super(Subway,self) super().__init__(name,speed,load,power) self.line=line def run(self): print('地铁%s号线欢迎您' %self.line) super(Subway,self).run() class Mobike(Vehicle):#摩拜单车 pass line13=Subway('中国地铁','180m/s','1000人/箱','电',13) line13.run()
静态方法与类方法
静态方法
通过@staticmethod装饰器即可把其装饰的方法变为一个静态方法
#########静态方法的运用 import time class Date: def __init__(self,year,mon,day): self.year = year self.mon = mon self.day = day @staticmethod def now(): t=time.localtime() return Date(t.tm_year,t.tm_mon,t.tm_mday) d = Date(2017,1,20) d1 = Date.now() print(d1.year,d1.mon,d1.day) """运行结果: 2017 7 19 """
类方法
通过@classmethod装饰器实现,类方法和普通方法的区别是, 类方法只能访问类变量,不能访问实例变量
#########类方法 import time class Date: def __init__(self,year,mon,day): self.year = year self.mon = mon self.day = day @classmethod def now(cls): t=time.localtime() return cls(t.tm_year,t.tm_mon,t.tm_mday) d = Date(2017,1,20) d1 = Date.now() print(d1.year,d1.mon,d1.day) """运行结果: 2017 7 19 """
静态方法与类方法的比较
import time class Date: def __init__(self,year,mon,day): self.year = year self.mon = mon self.day = day @staticmethod def now(): t = time.localtime() return Date(t.tm_year, t.tm_mon, t.tm_mday) ''' 静态方法方式运行的结果: C:\Python35\python.exe D:/Python代码目录/Python_codeing/Python16_code/day07/静态方法和类方法.py <__main__.Date object at 0x00000000006D35C0> Process finished with exit code 0 ''' @classmethod def now(cls): t = time.localtime() return cls(t.tm_year, t.tm_mon, t.tm_mday) """ 类方法方式运行的结果: C:\Python35\python.exe D:/Python代码目录/Python_codeing/Python16_code/day07/静态方法和类方法.py year:2017 mon:7 day:19 Process finished with exit code 0 """ class EuroDate(Date): #子类继承父类 def __str__(self): return 'year:%s mon:%s day:%s' %(self.year,self.mon,self.day) e=EuroDate.now() print(e)
反射
通过字符串映射或修改程序运行时的状态、属性、方法
class Foo: def __init__(self,name): self.name = name def func(self): print('func') ###hasattr:判断有没有货是否包含 print(hasattr(Foo,'func')) #True f=Foo('Viv') print(hasattr(f,'xyz')) #False ###getattr: 获取值 f.x=1 print(getattr(f,'x')) #返回:1 print(getattr(f,'func')) #返回:> if hasattr(f,'func'): aa=getattr(f,'func') aa() #返回:func ###setattr:设置属性 setattr(f,'y',123) print(f.__dict__) #返回:{'name': 'Viv', 'x': 1, 'y': 123}
类的特殊成员方法
__call__
对象后面加括号,触发执行;【注:构造方法的执行是由创建对象触发的,即:对象 = 类名() ;而对于 __call__ 方法的执行是由对象后加括号触发的,即:对象() 或者 类()()】
class Foo: def __init__(self,name): self.name = name def __call__(self, *args, **kwargs): #不加__call__则报错:TypeError: 'Foo' object is not callable print('-----------') f = Foo('hello') #执行__init__ f() #执行__call__
__gettitem__;__settitem__;__delitem__
用于索引操作,如字典。以上分别表示获取、设置、删除数据
class Goo: def __init__(self,name): self.name = name def __getitem__(self, item): print('getitem',self.__dict__) return self.__dict__[item] def __setitem__(self, key, value): print('setimtem') self.__dict__[key] = value def __delitem__(self, key): print('del obj[key]时,我执行') self.__dict__.pop(key) g = Goo('Vgirl') print(g['name']) '''运行结果: getitem {'name': 'Vgirl'} Vgirl ''' g['x']=1 print(g.__dict__) """运行结果: setimtem {'x': 1, 'name': 'Vgirl'} """ del g['x'] print(g.__dict__) '''运行结果: del obj[key]时,我执行 {'name': 'Vgirl'} '''
__doc__
表示类的描述信息
class Foo: '我是描述信息' pass print(Foo.__doc__) class Bar(Foo): pass print(Bar.__doc__) #该属性无法继承给子类
__module__和__class__
__module__ 表示当前操作的对象在那个模块;__class__ 表示当前操作的对象的类是什么
class C: def __init__(self): self.name = ‘SB'
from lib.abc import C obj = C() print obj.__module__ # 输出 lib.aa,即:输出模块 print obj.__class__ # 输出 lib.aa.C,即:输出类
__del__
析构方法,当对象在内存中被释放时,自动触发执行。【此方法一般无须定义,因为Python是一门高级语言,程序员在使用时无需关心内存的分配和释放,因为此工作都是交给Python解释器来执行,所以,析构函数的调用是由解释器在进行垃圾回收时自动触发执行的。】
class Foo: def __del__(self): print('该我执行') f1=Foo() del f1 print('------->') '''运行结果: 该我执行 -------> ''' #####del深坑 class Foo: def __del__(self): print('该我执行') f1=Foo() # del f1 print('------->') '''运行结果: -------> 该我执行 '''
__dict__
查看类或对象中的所有成员
class Province: country = 'China' def __init__(self, name, count): self.name = name self.count = count def func(self, *args, **kwargs): print 'func' # 获取类的成员,即:静态字段、方法、 print(Province.__dict__) # 输出:{'country': 'China', '__module__': '__main__', 'func':, '__init__': obj1 = Province('HeBei', 10000) print(obj1.__dict__) # 获取 对象obj1 的成员 # 输出:{'count': 10000, 'name': 'HeBei'} obj2 = Province('HeNan', 3888) print(obj2.__dict__) # 获取 对象obj1 的成员 # 输出:{'count': 3888, 'name': 'HeNan'}, '__doc__': None}
__str__
如果一个类中定义了__str__方法,则打印对象时,就默认输出该方法的返回值
class Foo: def __str__(self): return 'Viv hero' obj = Foo() print(obj) #返回Viv hero
更多参考:http://www.cnblogs.com/linhaifeng/articles/6204014.html
http://www.cnblogs.com/alex3714/articles/5213184.html
异常处理
异常处理初识
###什么是异常处理### ''' python解释器检测到错误,触发异常(也允许程序员自己触发异常);程序员编写特定的代码,专门用来捕捉这个异常(这段代码与程序逻辑无关,与异常处理有关);如果捕捉成功则进入另外一个处理分支,执行你为其定制的逻辑,使程序不会崩溃,这就是异常处理 ''' ###为什么要进行异常处理### """ python解析器去执行程序,检测到了一个错误时,触发异常,异常触发后且没被处理的情况下,程序就在当前异常处终止,后面的代码不会运行,谁会去用一个运行着突然就崩溃的软件。 所以你必须提供一种异常处理机制来增强你程序的健壮性与容错性 """
if判断处理异常
###正常代码### #code1 num1=input('>>: ') #输入一个字符串试试 int(num1) #code2 num2=input('>>: ') #输入一个字符串试试 int(num2) #code3 num3=input('>>: ') #输入一个字符串试试 int(num3) ###使用if判断进行异常处理### #code1 num1=input('>>: ') #输入一个字符串试试 if num1.isdigit(): int(num1) #我们的正统程序放到了这里,其余的都属于异常处理范畴 elif num1.isspace() or len(num1) == 0: print('输入的是空格,就执行我这里的逻辑') else: print('其他情情况,执行我这里的逻辑') #code2 num2=input('>>: ') #输入一个字符串试试 int(num2) #code3 num3=input('>>: ') #输入一个字符串试试 int(num3) ''' ###问题一: 使用if的方式我们只为第一段代码加上了异常处理,针对第二段代码,你得重新写一堆if,elif等 第三段,你还得在写一遍,当然了,你说,可以合在一起啊,没错,你合起来看看,你的代码还能被看懂吗??? 而这些if,跟你的代码逻辑并无关系,这就好比你在你心爱的程序中到处拉屎,拉到最后,谁都不爱看你的烂代码,为啥,因为可读性差,看不懂 ###问题二: 第一段代码和第二段代码实际上是同一种异常,都是ValueError,相同的错误按理说只处理一次就可以了,而用if,由于这二者if的条件不同,这只能逼着你重新写一个新的if来处理第二段代码的异常 第三段也一样 ''' if貌似可以用来处理程序异常,但是if判断式的异常处理只能针对某一段代码,对于不同的代码段的相同类型的错误你需要写重复的if来进行处理,更重要的是随便复杂一点的异常if就凌乱了。
try...except...
try...except...语句主要是用于处理程序正常执行过程中出现的一些异常情况,如语法错误(python作为脚本语言没有编译的环节,在执行过程中对语法进行检测,出错后发出异常消息)、数据除零错误、从未定义的变量上取值等。
基本语法
try: 被检测的代码块 except 异常类型: try中一旦检测到异常,就执行这个位置的逻辑
f=open('a.txt') g=(line.strip() for line in f) ''' next(g)会触发迭代f,依次next(g)就可以读取文件的一行行内容,无论文件a.txt有多大,同一时刻内存中只有一行内容。 提示:g是基于文件句柄f而存在的,因而只能在next(g)抛出异常StopIteration后才可以执行f.close() ''' f=open('a.txt') g=(line.strip() for line in f) for line in g: print(line) else: f.close() try: f=open('a.txt') g=(line.strip() for line in f) print(next(g)) print(next(g)) print(next(g)) print(next(g)) print(next(g)) except StopIteration: f.close()
异常类只能用来处理指定的异常情况,如果非指定异常则无法处理
### 未捕获到异常,程序直接报错### s1 = 'hello' try: int(s1) except IndexError as e: print(e) except KeyError as e: print(e) except ValueError as e: print(e)
多分支异常
s1 = 'hello' try: int(s1) except IndexError as e: print(e) except KeyError as e: print(e) except ValueError as e: print(e) '''运行结果: C:\Python35\python.exe D:/Python代码目录/Python_codeing/Python16_code/day08/123456.py invalid literal for int() with base 10: 'hello' Process finished with exit code 0 '''
万能异常Exception
###Exception### s1 = 'hello' try: int(s1) except Exception as e: print(e) """ C:\Python35\python.exe D:/Python代码目录/Python_codeing/Python16_code/day08/123456.py invalid literal for int() with base 10: 'hello' Process finished with exit code 0 """ 你可能会说既然有万能异常,那么我直接用上面的这种形式就好了,其他异常可以忽略 你说的没错,但是应该分两种情况去看 1)如果你想要的效果是,无论出现什么异常,我们统一丢弃,或者使用同一段代码逻辑去处理他们,那么骚年,大胆的去做吧,只有一个Exception就足够了。 s1 = 'hello' try: int(s1) except Exception,e: '丢弃或者执行其他逻辑' print(e) #如果你统一用Exception,没错,是可以捕捉所有异常,但意味着你在处理所有异常时都使用同一个逻辑去处理(这里说的逻辑即当前expect下面跟的代码块) 2)如果你想要的效果是,对于不同的异常我们需要定制不同的处理逻辑,那就需要用到多分支了。 s1 = 'hello' try: int(s1) except IndexError as e: print(e) except KeyError as e: print(e) except ValueError as e: print(e) 3)在多分支后来一个Exception s1 = 'hello' try: int(s1) except IndexError as e: print(e) except KeyError as e: print(e) except ValueError as e: print(e) except Exception as e: print(e)
异常的其他机构
s1 = 'hello' try: int(s1) except IndexError as e: print(e) except KeyError as e: print(e) except ValueError as e: print(e) #except Exception as e: # print(e) else: print('try内代码块没有异常则执行我') finally: print('无论异常与否,都会执行该模块,通常是进行清理工作')
自定义异常
#_*_coding:utf-8_*_ __author__ = 'Viv' class MyException(BaseException): def __init__(self,msg): self.msg=msg def __str__(self): return self.msg try: raise MyException('类型错误') except MyException as e: print(e)
主动触发异常
#_*_coding:utf-8_*_ __author__ = 'Linhaifeng' try: raise TypeError('类型错误') except Exception as e: print(e)
try...except...方式比if方式好的理由
try..except这种异常处理机制就是取代if那种方式,让你的程序在不牺牲可读性的前提下增强健壮性和容错性,异常处理中为每一个异常定制了异常类型(python中统一了类与类型,类型即类),对于同一种异常,一个except就可以捕捉到,可以同时处理多段代码的异常(无需‘写多个if判断式’)减少了代码,增强了可读性
归纳如下:
1)把错误处理和真正的工作分开来
2)代码更易组织,更清晰,复杂的工作任务更容易实现;
3)毫无疑问,更安全了,不至于由于一些小的疏忽而使程序意外崩溃了;