为什么叫舞蹈编导,因为舞蹈是由节奏的,节奏是每个点位动作的快慢控制,跳舞时节奏很重要,编舞者控制节奏。视图刷新也是如此,不是说你想刷就能刷,一切要按照底层信号要求的节奏来。
理解屏幕刷新频率
刷新频率:每秒钟刷新屏幕的次数,从缓存中取出每一帧,显示到屏幕上的速度。
帧率:GPU/CPU生成每一帧画面图像,存入缓存中的速度。
一般情况下帧率是大于刷新频率的,每个设备的刷新频率固定,与硬件相关,若帧率是刷新率的两倍,两张图像画面,只能有一个现实到屏幕上,也就是说生产画面的速度要大于显示画面的速度。典型的生产者-消费者模式。
屏幕刷新过程:从左到右刷新一行,然后垂直刷新,再一行..,直到屏幕刷新完毕。每一次刷新,都是这一个过程,刷新一次后,中间有一个期间,刷新率太高,每秒60帧左右,人眼无法感知。
tearing:若帧率大于刷新率,会导致在刷新前一帧还未开始时,缓存已经被新一帧覆盖一部分,那么在刷新前一帧时,现显示的一部分是新一帧内容。会导致画面前后帧上下重叠。这种情况技术上称之tearing,画面撕裂的意思。
解决方案:增加缓存到两个缓存,CPU生成帧存入一个缓存A,屏幕取出帧存入另一个缓存B,解决了一个缓存导致生产者与消费者不同步的问题。增加Vsync同步信号,负责调度将A缓存拷贝到B缓存,显示取出的就是一个完整帧的画面。Vsync信号在一帧刷新完的中间期间产生,A到B的复制(交换地址即可),进入下一次刷新,并通知生产者gpu/cpu继续生产帧,只有收到Vsync信号,生产者才会生产帧。因此,可使帧率与刷新率保持同步,消耗一次才生成一次。
掉帧:若Vsync信号发出时,A缓存正在被生产者锁住生产,gpu绘制生产帧时间超过信号发出时刻一点,此时不会复制。导致B缓存仍是老帧,下一次周期与前一次刷新相同的帧。当gpu生产结束后,此时刷新老数据的刷新周期中,还没有Vsync信号,则gpu空闲。
掉帧解决方案:再增加一个缓存到三个缓存。当有缓存锁住时复制他前面的上一次被锁住的另一个缓存。
Android平台提供两种信号,一种是硬件信号,另一种是软件信号,由SurfaceFlinger进程的一个线程定时发出,硬件信号由硬件发出。
App进程若要通过gpu实现图像绘制,需要在接收到Vsync信号的条件下进行,因此,App进程访问SurfaceFlinger进程获取这个信号,再进行gpu绘制。
Choreographer就是负责获取Vsync同步信号并控制App线程(主线程)完成图像绘制的类。
在Android系统中主要是主线程进行UI绘制,其他线程也可以绘制,比如SurfaceView,本文以主线程UI绘制进行介绍。
每个线程中保存一个Choreographer实例对象。
private static final ThreadLocal sThreadInstance =
new ThreadLocal() {
@Override
protected Choreographer initialValue() {
Looper looper = Looper.myLooper();
if (looper == null) {
//抛出异常。
}
return new Choreographer(looper);
}
};
线程本地存储ThreadLocal变量,Choreographer类型,在主线程中初始化变量时,创建Choreographer对象,绑定主线程Looper。
同一个App的每个窗体旗下ViewRootImpl使用的同一个Choregrapher对象,他控制者整个App中大部分视图的绘制节奏。
安排一次绘制
一次绘制,就是完成一个树形视图的测量、布局、绘制的过程,遍历视图树的每一个节点,当然,可以根据条件判断,省略掉其中一个或几个环节,比如,只刷新绘制,不测量和布局。
void scheduleTraversals() {
if (!mTraversalScheduled) {
mTraversalScheduled = true;
mTraversalBarrier = mHandler.getLooper().getQueue().postSyncBarrier();
mChoreographer.postCallback(
Choreographer.CALLBACK_TRAVERSAL, mTraversalRunnable, null);
...
}
}
ViewRootImpl对象的scheduleTraversals安排一次绘制,安排后,将设置标志位mTraversalScheduled,防止多次安排,发送同步栅栏。
当执行绘制doTraversal方法或unscheduleTraversals方法主动取消绘制时,关掉标志位,取消同步栅栏。委托Choreographer安排绘制,请求信号。
postCallbackDelayedInternal方法,调用postCallbackDelayedInternal。
private void postCallbackDelayedInternal(int callbackType,
Object action, Object token, long delayMillis) {
synchronized (mLock) {
final long now = SystemClock.uptimeMillis();
final long dueTime = now + delayMillis;
mCallbackQueues[callbackType].addCallbackLocked(dueTime, action, token);
if (dueTime <= now) {//没有延迟,以当前时间安排帧。
scheduleFrameLocked(now);
} else {
Message msg = mHandler.obtainMessage(MSG_DO_SCHEDULE_CALLBACK, action);
msg.arg1 = callbackType;
msg.setAsynchronous(true);
mHandler.sendMessageAtTime(msg, dueTime);
}
}
}

CallbackQueue的addCallbackLocked方法,创建一个CallbackRecord,封装dueTime执行时间(当前时间+延迟),任务action和token。插入链表,按照dueTime时间排序,dueTime时间小的在链表头部。
本文只关注CALLBACK_TRAVERSAL类型和TraversalRunnable回调任务,当收到Vsync信号时,将触发任务的doTraversal方法。
没有延迟,scheduleFrameLocked方法立即安排。
有延迟,等待delayMillis时间,在特定时间dueTime,通过Choreographer内部FrameHandler发送消息。
@Override
public void handleMessage(Message msg) {
switch (msg.what) {
...
case MSG_DO_SCHEDULE_CALLBACK:
doScheduleCallback(msg.arg1);
break;
}
}
FrameHandler处理延迟发送的CALLBACK,触发doScheduleCallback方法。
void doScheduleCallback(int callbackType) {
synchronized (mLock) {
if (!mFrameScheduled) {
final long now = SystemClock.uptimeMillis();
if (mCallbackQueues[callbackType].hasDueCallbacksLocked(now)) {
scheduleFrameLocked(now);
}
}
}
}
有延迟时,当到达时间dueTime,在handleMessage方法开始执行,最终实现一次绘制,和没有延迟时一样,触发scheduleFrameLocked方法。注意,经过一段时间的延迟,中间有不确定性,增加两个条件判断。
mFrameScheduled标志,表示此时已经有过一次scheduled,请求一次有回复在doFrame处重置标志。这时,不再scheduled。
当链表头结点的dueTime比当前时间now大,表示当时以(now + delayMillis)插入的CallbackRecord节点已经不在链表中了,否则在(now + delayMillis)时刻执行获取的当前时间一定会<=now,链表每个元素的dueTime都大于now,或者头节点是空,这种情况下不再scheduled。
scheduleFrameLocked方法,schedule一次具体的帧绘制。
private void scheduleFrameLocked(long now) {
if (!mFrameScheduled) {
mFrameScheduled = true;
if (USE_VSYNC) {
if (isRunningOnLooperThreadLocked()) {
scheduleVsyncLocked();
} else {
Message msg = mHandler.obtainMessage(MSG_DO_SCHEDULE_VSYNC);
msg.setAsynchronous(true);
mHandler.sendMessageAtFrontOfQueue(msg);
}
} else {
final long nextFrameTime = Math.max(
mLastFrameTimeNanos / TimeUtils.NANOS_PER_MS + sFrameDelay, now);
...
Message msg = mHandler.obtainMessage(MSG_DO_FRAME);
msg.setAsynchronous(true);
mHandler.sendMessageAtTime(msg, nextFrameTime);
}
}
}
入参now是执行该方法前获取的当前时间,设置mFrameScheduled标志,底层回调后重置标志。
默认USE_VSYNC,当前线程和Choreographer绑定线程一致,直接调用Choreographer的scheduleVsyncLocked方法,线程不同,通过FrameHandler发送消息,在Choreographer线程处理事务消息。
@Override
public void handleMessage(Message msg) {
switch (msg.what) {
...
case MSG_DO_SCHEDULE_VSYNC:
doScheduleVsync();
break;
}
}
同样,在doScheduleVsync会调用scheduleVsyncLocked方法。postCallback方法流程图。

最终统一调用到scheduleVsyncLocked方法, 它通过注册的接收器JNI方法访问底层,请求垂直同步信号。
显示事件接收器基础架构
scheduleVsyncLocked方法,通过DisplayEventReceiver的scheduleVsync实现请求同步信号。
private void scheduleVsyncLocked() {
mDisplayEventReceiver.scheduleVsync();
}
它是FrameDisplayEventReceiver类型,继承DisplayEventReceiver,在编舞者的构造方法中初始化,Java层DisplayEventReceiver构造方法。
public DisplayEventReceiver(Looper looper) {
..//Looper是空抛异常
mMessageQueue = looper.getQueue();
mReceiverPtr = nativeInit(new WeakReference(this), mMessageQueue);
}
DisplayEventReceiver会绑定Choreographer线程消息队列。创建一个弱引用,和消息队列一起,JNI#nativeInit方法初始化传入底层。
static jlong nativeInit(JNIEnv* env, jclass clazz, jobject receiverWeak,
jobject messageQueueObj) {
sp messageQueue = android_os_MessageQueue_getMessageQueue(env, messageQueueObj);
...
sp receiver = new NativeDisplayEventReceiver(env,
receiverWeak, messageQueue);
status_t status = receiver->initialize();
...
receiver->incStrong(gDisplayEventReceiverClassInfo.clazz);
return reinterpret_cast(receiver.get());
}
根据Java层MQ获取底层消息队列,创建一个NativeDisplayEventReceiver,JNI层接收器,继承LooperCallback,将mReceiverPtr指针返回Java层。JNI层接收器封装Java层弱引用receiverWeak、底层消息队列,底层接收器。
JNI层接收器的initialize初始化方法。
status_t NativeDisplayEventReceiver::initialize() {
status_t result = mReceiver.initCheck();
...
int rc = mMessageQueue->getLooper()->addFd(mReceiver.getFd(), 0, Looper::EVENT_INPUT,
this, NULL);
return OK;
}
向Choreographer线程Looper监听底层DisplayEventReceiver对象中BitTube的mReceiverFd描述符。一旦接收到消息,将触发Looper的handleEvent回调方法。
底层DisplayEventReceive的构造方法。
DisplayEventReceiver::DisplayEventReceiver() {
sp sf(ComposerService::getComposerService());
if (sf != NULL) {
mEventConnection = sf->createDisplayEventConnection();
if (mEventConnection != NULL) {
mDataChannel = mEventConnection->getDataChannel();
}
}
}
初始化两个重要指针,IDisplayEventConnection类型(mEventConnection)和BitTube类型(mDataChannel)。
IDisplayEventConnection负责和SurfaceFlinger进程通信,真正向底层发起请求,定义了进程通信的业务接口,IDisplayEventConnection业务层接口方法。
上面代码中sf是App进程ISurfaceComposer业务代理,真实的业务对象是SurfaceFlinger对象,继承BnSurfaceComposer,在SurfaceFlinger进程。ISurfaceComposer业务进程通信。
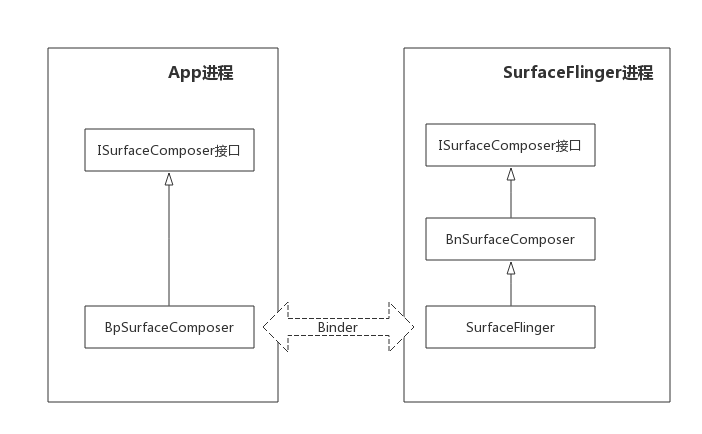
在App进程,ISurfaceComposer代理的createDisplayEventConnection方法,返回IDisplayEventConnection业务代理,继承BpDisplayEventConnection,也就是mEventConnection。然后,App进程就能通过IDisplayEventConnection的三个业务方法, requestNextVsync方法,请求下一次垂直同步信号。 setVsyncRate方法,设置垂直同步帧率。 getDataChannel方法,获取通信管道。
在SurfaceFlinger进程,SurfaceFlinger对象的createDisplayEventConnection方法,创建IDisplayEventConnection业务真实对象Connection,继承BnDisplayEventConnection。和App进程通信时,参数是Binder类型的,Parcal的writeStrongBinder和readStrongBinder方法可以实现Binder对象的传输,内核红黑树创建服务和引用节点,App进程创建出BpDisplayEventConnection业务代理。
SurfaceFlinger进程的createDisplayEventConnection方法。
sp SurfaceFlinger::createDisplayEventConnection() {
return mEventThread->createEventConnection();
}
sp EventThread::createEventConnection() const {
//在创建前会向EventThread注册该连接,加入到mDisplayEventConnections中。
return new Connection(const_cast(this));
}
创建Connection对象,它是EventThread内部类,该类的构造方法。
EventThread::Connection::Connection(const sp& eventThread)
: count(-1), mEventThread(eventThread), mChannel(new BitTube())
{
}
创建数据通道BitTube,内部一对Socket描述符,提供读写方法,用于数据通讯。
IDisplayEventConnection业务进程通信图。
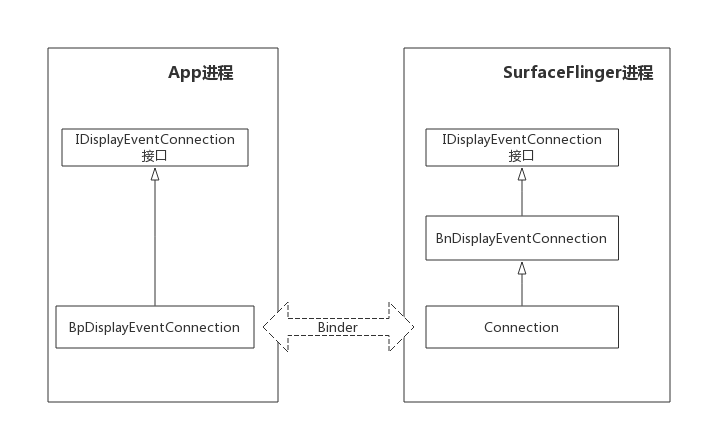
BitTube的构造方法和初始化方法。
BitTube::BitTube()
: mSendFd(-1), mReceiveFd(-1){
init(DEFAULT_SOCKET_BUFFER_SIZE, DEFAULT_SOCKET_BUFFER_SIZE);
}
void BitTube::init(size_t rcvbuf, size_t sndbuf) {
int sockets[2];
if (socketpair(AF_UNIX, SOCK_SEQPACKET, 0, sockets) == 0) {
...
mReceiveFd = sockets[0];
mSendFd = sockets[1];
} else {
mReceiveFd = -errno;
}
}
初始化一对socket发送/接收描述符,提供读/写数据的管道功能。Tube的意思是管,BitTube即字节管道。socket缓存4M,mSendFd用于写入,mReceiveFd用于接收,写入后,接收端mReceivedFd能读取。
App进程,通过BpDisplayEventConnection的getDataChannel方法获取通信管道,SurfaceFlinger进程,通过writeDupFileDescriptor写入mReceivedFd描述符,App进程从Parcel中读取,创建新BitTube对象封装mReceivedFd描述符。
virtual sp getDataChannel() const {
Parcel data, reply;
data.writeInterfaceToken(IDisplayEventConnection::getInterfaceDescriptor());
remote()->transact(GET_DATA_CHANNEL, data, &reply);
return new BitTube(reply);
}
Parcel的writeDupFileDescriptor和readFileDescriptor方法负责FileDescriptor类型读写存储。BitTube的构造方法(带Parcel参数)。
BitTube::BitTube(const Parcel& data)
: mSendFd(-1), mReceiveFd(-1) {
mReceiveFd = dup(data.readFileDescriptor());
if (mReceiveFd < 0) {
mReceiveFd = -errno;
ALOGE("BitTube(Parcel): can't dup filedescriptor (%s)",
strerror(-mReceiveFd));
}
}
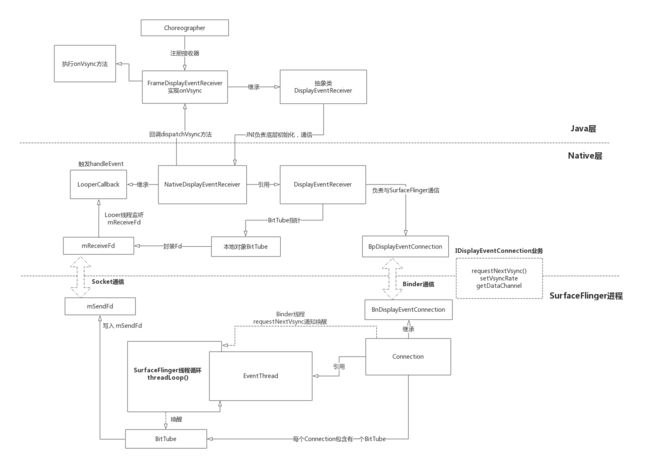
请求垂直同步信号流程
Java层DisplayEventReceiver请求一次垂直同步信号的过程。
前两个方法已经看过了,直接看一下JNI#nativeScheduleVsync方法。
static void nativeScheduleVsync(JNIEnv* env, jclass clazz, jlong receiverPtr) {
sp receiver =
reinterpret_cast(receiverPtr);
status_t status = receiver->scheduleVsync();
...
}
根据Java层receiverPtr指针,获取JNI层的NativeDisplayEventReceiver对象
status_t NativeDisplayEventReceiver::scheduleVsync() {
if (!mWaitingForVsync) {
...
processPendingEvents(&vsyncTimestamp, &vsyncDisplayId, &vsyncCount);
status_t status = mReceiver.requestNextVsync();
...
mWaitingForVsync = true;
}
return OK;
}
JNI层接收器封装底层DisplayEventReceiver,调用requestNextVsync方法。
status_t DisplayEventReceiver::requestNextVsync() {
if (mEventConnection != NULL) {
mEventConnection->requestNextVsync();
return NO_ERROR;
}
return NO_INIT;
}
底层DisplayEventReceiver,内部两个重要指针已经介绍过。
IDisplayEventConnection业务#requestNextVsync方法,和SurfaceFlinger进程通信,该进程实现业务接口的是Connection对象。sf进程Connection的requestNextVsync方法。
void EventThread::Connection::requestNextVsync() {
mEventThread->requestNextVsync(this);
}
Connection内部EventThread的requestNextVsync方法。
void EventThread::requestNextVsync(
const sp& connection) {
Mutex::Autolock _l(mLock);
if (connection->count < 0) {
connection->count = 0;
mCondition.broadcast();
}
}
通知mCondition条件,broadcast方法唤醒SurfaceFlinger进程的一个循环线程mEventThread,该线程在waitForEvent处等待,被唤醒后可利用Connection发送事件。
SurfaceFlinger循环线程EventThread的threadLoop方法
bool EventThread::threadLoop() {
DisplayEventReceiver::Event event;
Vector< sp > signalConnections;
signalConnections = waitForEvent(&event);//等待事件,等待得到的事件保存在event指针处
const size_t count = signalConnections.size();
for (size_t i=0 ; i& conn(signalConnections[i]);
status_t err = conn->postEvent(event);//写入的内容是Event类型
if (err == -EAGAIN || err == -EWOULDBLOCK) {
...
} else if (err < 0) {
removeDisplayEventConnection(signalConnections[i]);
}
}
return true;
}
该循环线程唯一的工作是在waitForEvent方法处等待VSYNC信号,当信号发生时,发送给BitTube#mSendFd句柄。
注意,SurfaceFlinger有两个EventThread线程,运行在各自的循环中。
收到信号时,遍历收到信号的Connection,调用它的postEvent方法。
status_t EventThread::Connection::postEvent(
const DisplayEventReceiver::Event& event) {
ssize_t size = DisplayEventReceiver::sendEvents(mChannel, &event, 1);
return size < 0 ? status_t(size) : status_t(NO_ERROR);
}
DisplayEventReceiver的sendEvents方法。
ssize_t DisplayEventReceiver::sendEvents(const sp& dataChannel,
Event const* events, size_t count) {
return BitTube::sendObjects(dataChannel, events, count);
}
利用Connection内部BitTube(即mChannel),BitTube的sendObjects将触发BitTube#write方法,向mSendFd写入数据,App进程mReceiveFd可收到数据,实现SurfaceFlinger进程到App进程的数据传输。
App进程Choreographer线程监听消息
在接收器架构中,JNI层的NativeDisplayEventReceiver继承LooperCallback,在初始化addFd时,将本身加入Looper回调,当App进程的mReceiveFd描述符收到消息后,Choreographer线程的底层Looper将触发LooperCallback的handleEvent方法。也就是NativeDisplayEventReceiver的handleEvent方法。
调用dispatchVsync方法。
void NativeDisplayEventReceiver::dispatchVsync(nsecs_t timestamp, int32_t
id, uint32_t count) {
JNIEnv* env = AndroidRuntime::getJNIEnv();
ScopedLocalRef receiverObj(env, jniGetReferent(env, mReceiverWeakGlobal));
if (receiverObj.get()) {
env->CallVoidMethod(receiverObj.get(),
gDisplayEventReceiverClassInfo.dispatchVsync, timestamp, id, count);
}
...
}
CallVoidMethod方法将调用Java层DisplayEventReceiver对象dispatchVsync方法。
private void dispatchVsync(long timestampNanos, int builtInDisplayId, int frame) {
onVsync(timestampNanos, builtInDisplayId, frame);
}
在Choreographer类,接收器就是FrameDisplayEventReceiver类型,它重写onVsync方法,被底层Looper监听到的,在Choreographer线程执行。onVsync方法的流程图。

@Override
public void onVsync(long timestampNanos, int builtInDisplayId, int frame) {
...
long now = System.nanoTime();
if (timestampNanos > now) {
timestampNanos = now;
}
...
mTimestampNanos = timestampNanos;
mFrame = frame;
Message msg = Message.obtain(mHandler, this);
msg.setAsynchronous(true);
mHandler.sendMessageAtTime(msg, timestampNanos / TimeUtils.NANOS_PER_MS);
}
特定的时刻发送消息,Message携带任务,而FrameDisplayEventReceiver实现Runnable,因此,最后在特定的时刻运行FrameDisplayEventReceiver的run方法。
@Override
public void run() {
mHavePendingVsync = false;
doFrame(mTimestampNanos, mFrame);
}
触发doFrame方法。
void doFrame(long frameTimeNanos, int frame) {
final long startNanos;
synchronized (mLock) {
if (!mFrameScheduled) {
return; // no work to do
}
long intendedFrameTimeNanos = frameTimeNanos;
startNanos = System.nanoTime();
final long jitterNanos = startNanos - frameTimeNanos;
if (jitterNanos >= mFrameIntervalNanos) {
final long skippedFrames = jitterNanos / mFrameIntervalNanos;
if (skippedFrames >= SKIPPED_FRAME_WARNING_LIMIT) {
Log.i(TAG, "Skipped " + skippedFrames + " frames! "
+ "The application may be doing too much work on its main thread.");
}
final long lastFrameOffset = jitterNanos % mFrameIntervalNanos;
if (DEBUG_JANK) {
Log.d(TAG, "Missed vsync by " + (jitterNanos * 0.000001f) + " ms "
+ "which is more than the frame interval of "
+ (mFrameIntervalNanos * 0.000001f) + " ms! "
+ "Skipping " + skippedFrames + " frames and setting frame "
+ "time to " + (lastFrameOffset * 0.000001f) + " ms in the past.");
}
frameTimeNanos = startNanos - lastFrameOffset;
}
if (frameTimeNanos < mLastFrameTimeNanos) {
if (DEBUG_JANK) {
Log.d(TAG, "Frame time appears to be going backwards. May be due to a "
+ "previously skipped frame. Waiting for next vsync.");
}
scheduleVsyncLocked();
return;
}
mFrameInfo.setVsync(intendedFrameTimeNanos, frameTimeNanos);
mFrameScheduled = false;
mLastFrameTimeNanos = frameTimeNanos;
}
try {
mFrameInfo.markInputHandlingStart();
doCallbacks(Choreographer.CALLBACK_INPUT, frameTimeNanos);
mFrameInfo.markAnimationsStart();
doCallbacks(Choreographer.CALLBACK_ANIMATION, frameTimeNanos);
mFrameInfo.markPerformTraversalsStart();
doCallbacks(Choreographer.CALLBACK_TRAVERSAL, frameTimeNanos);
doCallbacks(Choreographer.CALLBACK_COMMIT, frameTimeNanos);
} finally {
}
}
恢复mFrameScheduled标志,入参代表上一个帧的时间,如果当前时间已经>=frameTimeNanos一个间隔,表示发生了跳帧,根据时间差值/帧间隔计算跳过帧数,重置frameTimeNanos为不发生挑帧时,最近的一个帧时间点。最后,设置mLastFrameTimeNanos值,记录上一帧的时间。
下面的事情就是回调处理每个类型的Callbacks,触发CallbackRecord的run方法,CallbackRecord封装了任务action。对于CALLBACK_TRAVERSAL类型,最终会回调到ViewRootImpl#TraversalRunnable的run方法。
final class TraversalRunnable implements Runnable {
@Override
public void run() {
doTraversal();
}
}
ViewRootImpl的doTraversal方法,实现一次遍历绘制。
总结
1,Java层DisplayEventReceiver通过JNI调用,根据底层垂直同步信号请求,实现帧画面的显示控制,在需要绘制时,发起请求,当底层发出信号时,同步回调到上层执行。底层初始化(nativeInit),发起请求(scheduleVsync),实现回调(dispatchVsync)。
2,请求信号时,利用Binder机制同surfaceflinger进程通信,在surfaceflinger进程的业务对象是Connection,代表和App的一个连接。
3,底层通知上层是通过socketpair建立一对匿名已经连接套接字mReceiveFd与mSendFd,实现SurfaceFlinger与App进程的双向通信管道。在App进程中,有mReceiveFd描述符,监听描述符来自SurfaceFlinger进程mSendFd端的消息。
4,App进程Choreographer线程Looper负责监听来自mReceiveFd描述符。
任重而道远