由于最近复习最优化考试,为了防止考完即忘,这里做个笔记用于备忘,本文讲解一下无约束优化问题中的最速下降法。
一、解决的问题
最速梯度下降法解决的问题是无约束优化问题,而所谓的无约束优化问题就是对目标函数的求解,没有任何的约束限制的优化问题,比如求下方最小值:
其中的函数.
求解这类的问题可以分为两大类:一个是最优条件法和迭代法。
- 最优条件法是是指当函数存在解析形式,能够通过最优性条件求解出显式最优解。对于无约束最优化问题,如果f(x)在最优点x*附近可微,那么x*是局部极小点的必要条件为:我们常常就是通过这个必要条件去求取可能的极小值点,再验证这些点是否真的是极小值点。当上式方程可以求解的时候,无约束最优化问题基本就解决了。
- 实际中,这个方程往往难以求解。这就引出了第二大类方法:迭代法。
今天我们来看一种迭代法,最速梯度下降法!
二、最速梯度下降法
下面先给出最速梯度下降法的计算步骤:

由以上计算步骤可知,最速下降法迭代终止时,求得的是目标函数驻点的一个近似点。
其中确定最优步长的方法如下:

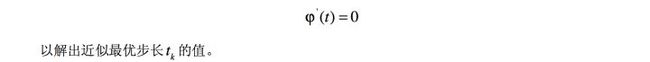
三、最速梯度下降法直观理解
在上面给出了最速梯度下降法的计算步骤,这里给出它的一些直观理解。
第一步:

第一步就是迭代法的初始点选择。
第二步:

可能有童鞋问这里的第二步的迭代终止条件为什么是?
这是因为根据下面这个定理:

也就是说,我们最终如果到达了局部最优解的话,求出来的梯度值是为0的,也就是说该点梯度为0是该点是局部最优解的必要条件。
所以我们的终止条件就是到达某处的梯度为0,在一些条件不是太苛刻的情况下,我们也可以不让它严格为0,只是逼近于0即可。这就是第二步的解释。
第三步:

这步在是在选取迭代方向,也就是从当前点迭代的方向。这里选取当前点的梯度负方向,为什么选择这个方向,是因为梯度的负方向是局部下降最快的方向,这里不详细证明,可以参考我以前的一个回答:为什么梯度反方向是函数值局部下降最快的方向?
第四步:

第四步也是非常重要的,因为在第三步我们虽然确定了迭代方向,并且知道这个方向是局部函数值下降最快的方向,但是还没有确定走的步长,如果选取的步长不合适,也是非常不可取的,下面会给出一个例子图,那么第四步的作用就是在确定迭代方向的前提上,确定在该方向上使得函数值最小的迭代步长。
下面给出迭代步长过大过小都不好的例子图:
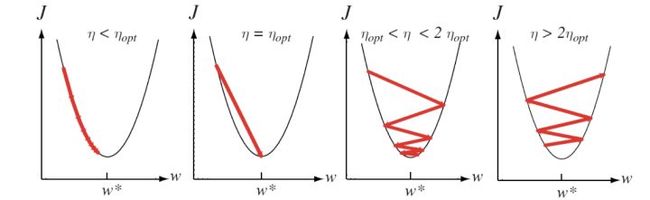
从上图可以看出,选择一个合适的步长是非常最重要的,这直接决定我们的收敛速度。
四、最速梯度下降法实例


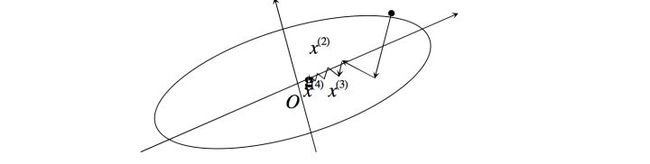
因此我们找到了近似最优解:,然后将带入中,即可得到要求的最小值。
五、最速下降法的缺点
需要指出的是,某点的负梯度方向,通常只是在该点附近才具有这种最速下降的性质。
在一般情况下,当用最速下降法寻找极小点时,其搜索路径呈直角锯齿状(如下图),在开头 几步,目标函数下降较快;但在接近极小点时,收敛速度长久不理想了。特别适当目标函数的等值 线为比较扁平的椭圆时,收敛就更慢了。

因此,在实用中常用最速下降法和其他方法联合应用,在前期使用最速下降法,而在接近极小值点时,可改用收敛较快的其他方法。
六、最速下降法代码实现
import numpy as np
from sympy import * import math import matplotlib.pyplot as plt import mpl_toolkits.axisartist as axisartist # 定义符号 x1, x2, t = symbols('x1, x2, t') def func(): # 自定义一个函数 return 2 * pow(x1, 2) + pow(x2, 2) + 2 * x1 * x2 - x2 + x1 def grad(data): # 求梯度向量,data=[data1, data2] f = func() grad_vec = [diff(f, x1), diff(f, x2)] # 求偏导数,梯度向量 grad = [] for item in grad_vec: grad.append(item.subs(x1, data[0]).subs(x2, data[1])) return grad def grad_len(grad): # 梯度向量的模长 vec_len = math.sqrt(pow(grad[0], 2) + pow(grad[1], 2)) return vec_len def zhudian(f): # 求得min(t)的驻点 t_diff = diff(f) t_min = solve(t_diff) return t_min def main(X0, theta): f = func() grad_vec = grad(X0) grad_length = grad_len(grad_vec) # 梯度向量的模长 k = 0 data_x = [0] data_y = [0] while grad_length > theta: # 迭代的终止条件 k += 1 p = -np.array(grad_vec) # 迭代 X = np.array(X0) + t * p t_func = f.subs(x1, X[0]).subs(x2, X[1]) t_min = zhudian(t_func) X0 = np.array(X0) + t_min * p grad_vec = grad(X0) grad_length = grad_len(grad_vec) print('grad_length', grad_length) print('坐标', X0[0], X0[1]) data_x.append(X0[0]) data_y.append(X0[1]) print(k) # 绘图 fig = plt.figure() ax