欢迎关注我的专栏( つ•̀ω•́)つ【人工智能通识】
【专题】下载器:Python-Tkinter项目编程入门
自定义模块导入
如果我们需要在a.py文件中导入c文件夹下b.py的内容(函数和变量等),比如希望使用from c.b import *这样的语句,那么就需要先在b.py所在的文件夹创建一个init.py文件(即使是空的也可以)。
比如下图,我们在main.py文件同级创建了modules文件夹,然后里面创建了reqs.py文件。
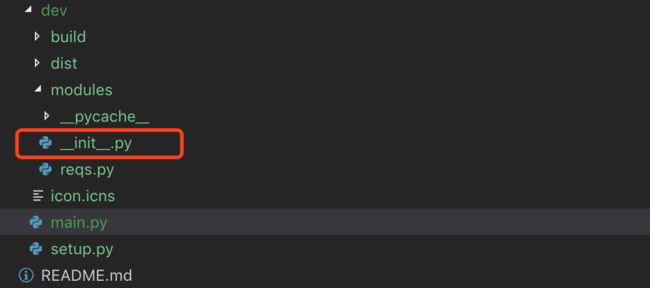
然后我们就可以在main.py内使用下面的代码引入reqs.py的内容了。
from modules.reqs import * # 导入reqs请求函数
这种模式导入的reqs.py中的变量可以直接使用,不需要使用任何处理。
自动计时更新Label文字
我们可以用Tkinter很方便的创建一个标签元素:
info=ttk.Label(root, text = '?/?')
info.grid(row = 3, column = 1, padx = 10, ipady = 10, ipadx = 10, sticky = E)
如何动态改变标签的文字?可以使用Tkinter的StringVar变量字符串,比如先创建一个varStr=StringVar(),然后设定textvariable = varStr这样的代码来代替text='xx',当使用varStr.set('AAA')的时候,标签文字会自动更新为AAA。(可以参考后面关于cookieStr的代码)
如果我们要定时(比如每隔0.5秒)刷新改变这里的text文字,就要用到计时器了。
info.after(500, refreshInfo) #自动循环更新
这里的after是延迟运行的意思,500毫秒之后运行refreshInfo这个函数,这个函数的代码如下(要放在这一行前面才行):
def refreshInfo():
info.config(text=genInfoStr())
info.after(500, refreshInfo)
这里我们看到了自身循环调用自身的用法info.after(500, refreshInfo),这样实现循环。info.config(text=genInfoStr())这是修改标签文字的方法,genInfoStr()是来自reqs.py的函数,它返回一个字符串。
界面布局
初步设计界面包含两个输入框,分别让用户输入Cookie和的账户名,点击按钮开始下载,下载的过程中用黑白格显示进程。

多线程
Tkinter界面程序将默认占用主线程,如果我们要定时刷新下载进度条,那么就必须另外启动一个单独的线程,否则就会阻塞主线程,导致不刷新。
启动一个线程的代码是:
t = Thread(target=getArticles, args=(cookiestr,)) # 多线程,避免锁死界面
t.start()
这里的target是要运行的函数,args是指定给这个函数的参数。
reqs.py文件代码
import time
from threading import Thread
atotal = 32 # 总文章数量
afini = 0 # 已读取的文章数量
cookiestr = '' # cookie全局变量
def genInfoStr(): # 拼接信息字符串
global atotal
global afini
infoStr = '正在获取('+str(afini)+'/'+str(atotal)+'):'
per = int(atotal/15)
fi = int(afini/per)
for _ in range(fi):
infoStr += '■'
for _ in range(15-fi):
infoStr += '□'
return infoStr
def getAll(cookieStr): # 获取全部
t = Thread(target=getArticles, args=(cookiestr,)) # 多线程,避免锁死界面
t.start()
return 'getAll OK!'
def getImages(): # 获取图片列表
return 'getImages OK!'
def getArticles(cookiestr): # 获取文章内容
global afini
for _ in range(10):
afini += 1
time.sleep(1)
return 'getArticles OK!'
def getArticlesList(): # 获取文章列表
return 'getArticlesList OK!'
def getVolums(): # 获取文集列表
return 'getVolums OK!'
这里定义了很多获取文章相关接口的函数,先获取文集getVolums,再获取文章列表getArticlesList,再获取文章内容getArticles,再获取相关图片getImages,而这些的入口是获取全部getAll,这只是个框架,帮助梳理思路,以后再具体调整。
genInfoStr产生信息标签的字符串,它利用atotal总文章数和afini完成文章数计算得到界面上标签的文字内容。
注意我们再getArticles函数中临时设定了计数器自增afini完成的文章数量。
main.py
from tkinter import *
from tkinter import ttk
from modules.reqs import * # 导入reqs请求函数
import time
import random
# 创建窗体
root = Tk()
root.title('MyApp')
root.resizable(width=False, height=False)
root.config(background='#EEE')
root.geometry('500x240')
# 启动获取动作
def run():
getAll(cookieStr)
# 信息的自刷新函数
def refreshInfo():
info.config(text=genInfoStr())
info.after(500, refreshInfo)
# ---创建界面
ttk.Frame(root, height=20).grid()
rown=0
# Cookie输入框
rown+=1
cookieStr = StringVar()
cookieStr.set('请在这里粘贴浏览器中的Cookie字段')
iptCookie = ttk.Entry(root, textvariable=cookieStr)
iptCookie.grid(
row=rown, column=1, pady=10, padx=10, ipady=5, sticky='WE')
# 账户名输入框
rown+=1
nameStr=StringVar()
nameStr.set('请输入您的账户名')
iptName = ttk.Entry(root, textvariable=nameStr)
iptName.grid(
row=rown, column=1, pady=10, padx=10, ipady=5, sticky='WE')
# 运行按钮
rown+=1
bt = ttk.Button(root, text='开始下载', width=30, command=run)
bt.grid(
row=rown, column=1, padx=10, ipady=10, ipadx=10, sticky=E)
# 信息标签
rown+=1
info = ttk.Label(root, text='?/?')
info.grid(row=rown, column=1, padx=10, ipady=10, ipadx=10, sticky=E)
info.after(500, refreshInfo) # 自动循环更新
root.mainloop()
在这里我们直接从run方法呼叫reqs中的getAll方法,这个getAll方法会启动单独线程getArticles,每隔1秒就自增一个afini,同时info.after会每隔0.5秒调用reqs中的genInfoStr函数,而这个genInfoStr函数会根据实时的atotal和afini来拼合文字进度条。
迄今为止,我们实现了简单的界面布局、界面元素触发函数、函数自动化更新界面、多线程调用以及分拆代码文件导入自定义模块等功能。
整体上的框架已经具备了,后续我们正式进入数据下载相关的业务流程代码。
欢迎关注我的专栏( つ•̀ω•́)つ【人工智能通识】
每个人的智能新时代
如果您发现文章错误,请不吝留言指正;
如果您觉得有用,请点喜欢;
如果您觉得很有用,欢迎转载~
END