为什么80%的码农都做不了架构师?>>> 
一个好的 Web 开发框架必然少不了接收 Action 请求这个重要的环节。我们也可以看到市面上不同的框架都有着自己特色的处理方式。当然 Hasor 在处理 Web 请求时也会有自己独特的处理方式。看过之后相信你一定会非常熟悉。
说了这么多,让我们来看看如何使用 Hasor 来处理连入的请求吧。
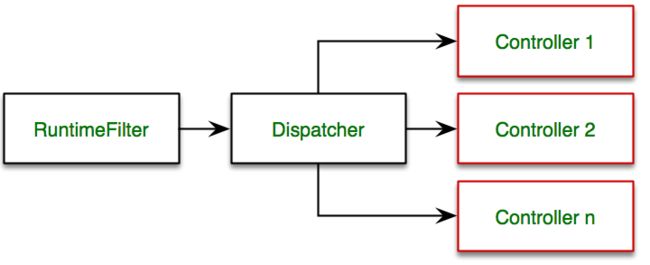
根据上面图可以看出,Hasor 在处理 Web 请求的时候采用了通用的处理方式。请求要首先进入口 Filter,然后 入口 Filter 负责调用 Dispatcher 把请求派发到对应的 Controller 上从而完成真个请求接入的工作。
一、入口
那么 Dispatcher 是如何工作的呢?
在 Hasor 的入口 RuntimeFilter 中可以看到除了做的最多的 init 初始化工作之外,最重要的就是下面这个方法,调用 Dispatcher 进行请求派发。
public class RuntimeFilter implements Filter {
...
public void doFilter(final ServletRequest request, final ServletResponse response, final FilterChain chain) throws IOException, ServletException {
...
this.processFilterPipeline(httpReq, httpRes, chain);
...
}
...
private void processFilterPipeline(final HttpServletRequest httpReq, final HttpServletResponse httpRes, final FilterChain chain) throws IOException, ServletException {
this.filterPipeline.dispatch(httpReq, httpRes, chain);
}
}
二、Dispatcher派发器
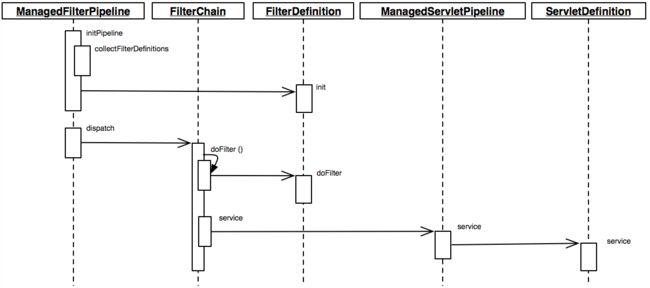
-请求拦截器
FilterPipeline 派发器是一个接口,它的实现类是 ManagedFilterPipeline。派发器最重要的工作就是根据当前请求路径找到最适合的那个 Controller 然后把请求交给这个 Controller。
ManagedFilterPipeline,有两个特别重要的过程一个是 initPipeline ,负责初始化整个基础数据。有了基础数据,接下来在匹配 Controller 时才有的选。另外一个重要的过程就是 dispatch 这个方法负责从众多 Controller 中找到需要的那一个然后执行调用。
先说 init 过程,下面这个就是 init 过程的关键代码。其中我们可以看到 collectFilterDefinitions 方法负责把所有的 Controller 都收集到。然后执行对应的 init 方法。
public class ManagedFilterPipeline implements FilterPipeline {
...
public synchronized void initPipeline(final WebAppContext appContext, final Map filterConfig) throws ServletException {
...
this.filterDefinitions = this.collectFilterDefinitions(appContext);
for (FilterDefinition filterDefinition : this.filterDefinitions) {
filterDefinition.init(appContext, filterConfig);
}
...
}
...
} dispatch,下面这个是主要逻辑。我们可以看到在初始化中得到的 filterDefinitions 并没有按照我们想想中的先筛选出一个子集合,然后在去执行调用。而是直接把请求送进了所有 Controller。其中 FilterChainInvocation 类的作用是充当过滤器链调度器。
public class ManagedFilterPipeline implements FilterPipeline {
...
public void dispatch(HttpServletRequest request, HttpServletResponse response, FilterChain defaultFilterChain) {
...
FilterChainInvocation invocation = new FilterChainInvocation(this.filterDefinitions, this.servletPipeline, defaultFilterChain);
invocation.doFilter(dispatcherRequest, response);
...
}
...
}dispatch 的入口方法中既然没有做筛选,那么一定是在 doFilter 中在执行时做了判断。这样的设计有一个很大的好处。就是节省资源开销。
让我们想象一下,如果每个请求在进入 dispatch 的时都要对所有 Controller 遍历一遍求出最重需要的那一个。最后我们的到了想要的 Controller List 在循环执行一次调用。假设我们有 10 个 Controller 那么最多就要执行 20 次循环。这种方式实在是笨拙既浪费 CPU 不说还浪费内存,如果并发请求量很大的话。这种方式还会成为框架性能的瓶颈。
因此 Hasor 在设计 dispatch 的时候充考虑到了这种情况,为了提升性能把遍历和判断改为一次循环一次判断。既省 CPU 还省内存,每次执行 dispatch 最多产生 10次循环。这样一来即环保又高效。
下面代码中可以看到 matchesUri 方法的返回值直接影响到了 Controller 是否会被执行,如果当前的 Controller 没有命中就会通过 FilterChain 前往下一个。
class FilterDefinition extends AbstractServletModuleBinding {
...
public void doFilter(ServletRequest request, ServletResponse response, FilterChain chain){
HttpServletRequest httpRequest = (HttpServletRequest) request;
String path = httpRequest.getRequestURI().substring(httpRequest.getContextPath().length());
boolean serve = this.matchesUri(path);
//
Filter filter = this.getTarget();
if (serve && filter != null) {
filter.doFilter(request, response, chain);
} else {
chain.doFilter(httpRequest, response);
}
}
...
}
- 调用Controller
前面我们一致都忽略了 Servlet 的处理,这里我们在讨论一下 Servlet。 Hasor 的 Servlet 处理都是封装到 ManagedServletPipeline 类里与 ManagedFilterPipeline 具有同等地位。
不同的是 ManagedServletPipeline 接受的请求是在 ManagedFilterPipeline 执行过程的最后才会调用到它,如果在 Filter 执行过程中有任何一个环节没有继续执行 “chain.doFilter(httpRequest, httpResponse);” 那就表示后面不会执行到 ManagedServletPipeline。
这一点也很好理解,毕竟 Filter 已经拦截了请求并做了相应的处理。后续可能就不需要在执行了。
三、为什么要用循环判断而不用Mapping做映射?
这一节我们从一个小问题出发论一论正确性。
这个问题应该是大家都会普遍问到的问题,首先从功能实现上来讲循环判断和 Mapping 映射都可以实现相同的功能。循环判断要比 Mapping 映射复杂一点,而且要稍微耗时一些。
Mapping 通常是利用 HashMap 或者其它一些 Map 来实现,而这些 Map 都有一个共同的问题那就是 Hash碰撞。
接下来我说一个实际的 Case。记得在开发 RSF 项目中,采用了 String -> Method 这种映射机制做缓存。省了每次都到 Class 中反射查询方法。原本上想增加运行效率,不料在单元测试中,发生了找不到方法的异常。几经排查,最后锁定了问题的元凶。就是那个 String -> Method 的 cache。
在这个 case 中虽然没有产生什么后果,但是如果在线上环境上遇到恰好两遍方法入参、出参又一致。那么就会在你不知情的情况下,调用了一个错误的方法。而这个错误的方法却给出了你一个你认为正确的结果。
进一步想象一下,如果是某个交易场景呢?
可能有同学说了,概率太小了。不要大惊小怪。但是实际中我们不能说风险小就不去管它,一旦遇到风险怎么办呢?
这就好比生一个健康的孩子,医院跟你说你的孩子 99.999% 是没有问题的。换句话说 10万个孩子里只会有一个有问题。 10万分之一的概率是多么小的概率。
但是我要问的是你想做这个 10万分之一么?,又或者你想做 100万分之一那个人么?
程序也是一个道理。风险在小只要它存在,就不能漠视。正确性高于一切!!!