《基于ArcGIS的Python编程秘笈(第2版)》——1.3 Python语言基础
本节书摘来自异步社区《基于ArcGIS的Python编程秘笈(第2版)》一书中的第1章,第1.3节,作者: 【美】Eric Pimpler(派普勒) 更多章节内容可以访问云栖社区“异步社区”公众号查看。
1.3 Python语言基础
了解Python语言的基本架构,有助于读者更有效地编写ArcGIS地理处理脚本。尽管Python语言相对于其他编程语言来说更易学,但要想真正掌握它,也需要花一定的时间来学习和练习。本节将介绍如何创建变量及给变量赋值,可赋值给变量的数据类型,如何使用不同类型的语句和对象,如何读写文件和导入Python第三方模块等内容。
1.3.1 代码注释
编写Python脚本时,一般都需要遵循约定俗成的程序架构。通常在每个脚本的开头是说明部分,用来说明脚本的名称、作者和处理过程的梗概,以帮助程序员快速了解脚本的细节和用途。在Python中,说明部分通常使用注释来实现。注释是脚本中以#或##开头的代码行,#或##后跟随说明代码的文字,用来解释脚本中某些代码或代码块的功能。注释只起到说明代码的作用,在代码运行时Python解释器并不执行它。如图1-11所示,注释是以#为前缀的代码行。要尽量在整个脚本的重要部分添加注释,以使程序更易读,这对更新脚本非常有用。

1.3.2 模块导入
尽管Python语言有很多内置的函数,能够完成不同的功能,但仍然需要经常访问存储在外部模块中的具有特定功能的函数集以完成特定的功能。例如,math模块存储与数值处理有关的特定函数,R模块提供与统计分析有关的函数等。一般说来,函数是一个已命名的代码块,执行时只需调用其名称。模块则是由一系列函数构成的,它可以通过import语句导入。import语句通常是脚本文件中的第1行代码(不包括注释)。在编写ArcGIS地理处理脚本时,需要导入arcpy模块,该模块是访问ArcGIS提供的GIS工具和函数的Python工具包。下面的代码展示了如何导入arcpy模块和os模块,其中os模块提供了与底层操作系统进行交互操作的接口。
import arcpy
import os
1.3.3 变量
一般来说,变量可视为计算机内存中的一块区域,用来存储脚本运行过程中的值。在Python中进行变量定义时,并不需要预先声明变量的类型,只需直接命名和赋值,通过引用变量名就可以在脚本中任意位置访问赋给变量的值。例如,创建一个包含要素类名称的变量,然后通过缓冲区工具引用该变量可以创建一个新的输出数据集。在创建一个变量时只需指定它的名称,通过赋值运算符(=)就可以实现变量的赋值,如下所示。
fcParcels = "Parcels"
fcStreets = "Streets"
表1-1列出了以上代码示例的变量名和赋给变量的值。

创建变量必须遵循如下命名规则。
变量名由字母、数字或下划线组成。
第1个字符必须是字母或下划线(最好避免使用下划线,因为首字符为下划线的变量在Python中有特殊的含义)。
不能使用除下划线以外的其他特殊字符。
不允许使用Python关键字和空格。
命名变量时必须避免使用Python语言的关键字,如class、if、for、while等。在Python语句中,这些关键字通常会以不同的颜色突出显示。
下面是一些合法的变量名。
featureClassParcel
fieldPopulation
field2
ssn
my_name
下面是一些非法的变量名。
class(Python关键字)
return(Python关键字)
$featureClass(非法字符,必须以字母或下划线开头)
2fields(必须以字母或下划线开头)
parcels&Streets(&是非法字符)
Python语言区分大小写,所以要特别注意脚本中的大小写,如变量的命名等。对初学者来说,大小写问题是最常见的错误来源,所以当代码出现错误时要首先考虑大小写问题。来看一个例子,下面是3个变量,虽然每个变量的名字相同,但是由于大小写的不同,实际上创建的是3个不同的变量。
mapsize = "22x34"
MapSize = "8x11"
Mapsize = "36x48"
如果输出这些变量,会得到以下结果。
print(mapsize)
>>> 22x34
print(MapSize)
>>> 8x11 #output from print statement
print(Mapsize)
>>>36x48 #output from print statement
要变量名在整个脚本中保持一致,最好的做法就是采用camel命名法,即变量名的第1个单词全部小写,而后连接的每个单词的首字母大写。如以变量名fieldOwnerName为例来说明这一概念。第1个单词(field)所有字母小写,第2个单词(Owner)和第3个单词(Name)的首字母大写。
fieldOwnerName
Python中的变量是动态的,也就是说不需要预先声明变量的类型,变量赋值时就已经隐式地声明变量的类型了。赋值给变量的常用数据类型如表1-2所示。
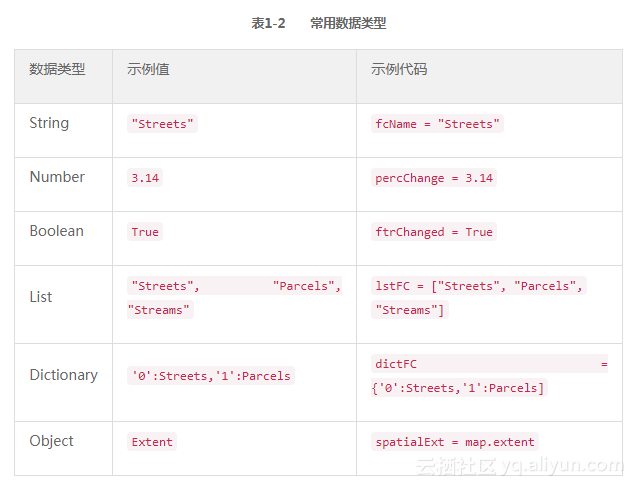
接下来的章节会详细介绍这些数据类型。
在C#中,使用变量之前必须先定义变量的名称和类型,而Python则只需定义变量名,通过赋值就可以使用该变量,变量的具体数据类型由Python后台识别。
下面的C#代码示例创建了一个名为aTouchdown的整型变量,它只能包含整数数据,然后给该变量赋值整数6。
int aTouchdown;
aTouchdown = 6;
在Python中,这个变量可以动态地创建和赋值,如下列代码所示。Python解释器可以动态地判断赋给变量的数据类型。
aTouchdown = 6
有时候需要创建一个变量,但事先并不知道具体为它赋何值,在这种情况下,可以简单地创建一个没有赋值的变量,下面的代码示例就创建了这样一个变量。
aVariable = ''
aVariable = NULL
赋值给变量的数据可以在脚本运行时改变。
变量可以存储不同类型的数据,包括基本数据类型,如字符串和数字,以及更复杂的数据类型,如列表、字典和对象等。接下来介绍可以赋值给变量的不同数据类型以及Python提供的各种操作数据的功能。
1.3.4 内置数据类型
Python有一些内置的数据类型。这里首先介绍string类型,之前已经给出几个string变量的例子,这种变量类型有多种操作方式,下面详细介绍这种数据类型。
1.字符串
字符串是字符的有序集合,用于存储和表示文本信息。当字符串赋值给变量时,要由英文单引号或双引号括起来,它可以是一个名称、要素类名称、where子句或其他任何可编码的文本。
2.字符串操作
在Python中,字符串有多种操作方式,其中字符串连接是比较常用且容易实现的操作方式之一。“+”操作符可以把它两边的字符串变量连接起来形成一个新的字符串变量。
shpStreets = "C:\\GISData\\Streets" + ".shp"
print(shpStreets)
运行上述代码,将得到以下结果。
>>>C:\GISData\Streets.shp
判断字符串是否相等可以使用“==”操作符,就是简单地把两个等号放在一起。读者一定要注意不要混淆相等操作符和赋值运算符:相等操作符有两个等号,而赋值运算符只有一个等号;相等操作符用于判断两个变量是否相等,而赋值运算符用于给变量赋值。
firstName = "Eric"
lastName = "Pimpler"
firstName == lastName
运行上述代码示例会得到以下结果,是因为“firstName”和“lastName”变量不相等。
>>>False
判断变量是否包含某个字符串可以使用“in”操作符,如果第 1 个操作对象包含于第2个操作对象中则返回True。
fcName = "Floodplain.shp"
print(".shp" in fcName)
>>>True
正如前文所述,字符串是字符的有序集合,也就意味着可以访问字符串中的单个字符或一串字符,只要不人为改变,字符的顺序都会保持不变。而有些集合却不能保持设定的顺序,如字典等。在Python中,访问单个字符称为索引,访问一串字符称为切片。
字符串中的单个字符可以通过字符串变量后的方括号内的偏移量来获得,如使用fc[0]可以获得fc变量的第1个字符。Python是一种从零开始的语言,也就是说列表中第1项的索引值是0。负偏移用于从字符串的末尾逆向搜索,在这种情况下,字符串最后一个字符的索引值是−1。索引总是创建一个新变量来保存字符。
fc = "Floodplain.shp"
print(fc[0])
>>>'F'
print(fc[10])
>>>'.'
print(fc[13])
>>>'p'
图1-12说明了字符串是字符的有序集合,第1个字符的索引值是0,第2个字符的索引值是1,接下来的每个连续字符按顺序占用一个索引值。
字符串索引只能获得string变量的单个字符,而字符串切片能够提取字符串的连续序列,其格式和语法与索引类似,但需要引入第二偏移量来指定要截取的字符序列的结束位置,从而获得要返回的子字符串。
下面的代码是一个字符串切片的例子,先把“Floodplain.shp”赋值给“theString”变量,然后使用theString[0 : 5]获得“Flood”切片。
theString = "Floodplain.shp"
print(theString[0:5])
>>>Flood
提示:
Python切片返回的字符开始于第一偏移量,结束于第二偏移量,但不包括第二偏移量。这对于初学者来说特别容易混淆,也是一种经常犯的错误。在上述例子中,返回的变量包含“Flood”字符串,第1个字符的索引值是0,对应字符“F”,最后一个返回的字符索引值是4,对应字符“d”。请注意,索引值5不包括在内,因为Python切片仅返回到第二偏移量的前一个索引值对应的字符。
任一偏移量都可以省略,这实际上是创建了一个通配符。例如,theString[1:]要求Python返回从第2个字符开始到字符串末尾的所有字符;theString[:-1]要求Python返回从第1个字符开始到倒数第2个字符的所有字符。
Python是一门优秀的语言,在字符串操作方面提供了很多函数,可以方便地对字符串进行处理。但是限于篇幅,大多数的字符串操作功能本书并没有介绍,仅仅介绍如下字符串操作功能。
- 计算字符串长度。
- 转换大小写。
- 去除开头和结尾的空白。
- 查找字符串中字符。
- 文本替换。
- 用分隔符把字符串拆分成一系列单词。
- 格式化。
使用Python编写面向ArcGIS的地理处理脚本时,经常需要引用计算机本地或者共享服务器上的数据集,实际上引用数据集就是引用了存储在变量中的路径。在Python中,路径名称需要单独提及。很多编程语言通常用反斜杠来定义路径,但Python中的反斜杠是转义字符和续行符的标志,因此需要使用双反斜杠(\)、单正斜杠(/)或者以r为前缀的单反斜杠()来定义路径。在Python中,路径名一般存储为字符串,如下列代码所示。
以下是非法的路径引用。
fcParcels = "C:\Data\Parcels.shp"
以下是合法的路径引用。
fcParcels = "C:/Data/Parcels.shp"
fcParcels = "C:\\Data\\Parcels.shp"
fcParcels = r"C:\Data\Parcels.shp"
3.数字
Python内置的数值型数据有int、long、float和complex等。把数字赋值给变量的方式与字符串类似,不同之处在于不需要使用引号把值引起来并且它还必须是一个数值。
Python支持所有常用的数字操作,包括加、减、乘、除、取模和求余等,还可以使用函数进行返回绝对值、将字符串转换成数值型数据和四舍五入等操作。
尽管Python提供了一些内置的数学函数,但是如果要访问其他更高级的数学函数则需要使用math模块。当然,在使用这些函数前必须先使用import导入math模块,代码如下。
import math
math模块提供的函数有向上舍入和向下取整函数、绝对值函数、三角函数、对数函数、角转换函数和双曲函数等。值得注意的是,Python并没有提供函数来计算中位数或平均值,需要编程来实现。有关math模块的更多细节可以通过单击“All Programs | ArcGIS | Python 2.7 | Python Manuals”来查看。打开Python Manual后,在目录栏里单击“The Python Standard Library | Numeric and Mathematical Modules”,你就可以查看任何的数据类型、语法、内置函数以及其他想详细了解的内容了,在此不一一赘述。
4.列表
Python提供的第3种内置数据类型是列表。列表是元素的有序集合,它可以存放Python支持的任何一种数据类型,也可以同时存放多种数据类型。这些数据类型可以是数字、字符串、其他列表、字典和对象等。例如,一个列表变量可以同时存放数字和字符串。列表是从零开始的,即列表中第1个元素的索引值是0,如图1-13所示。
之后列表中每个连续对象的索引值依次增加1。此外,列表的长度可以根据需要动态地增长和收缩。
列表是通过在方括号内赋一系列的值来创建的。要提取列表中的值,只需在变量名后的方括号内填写相应的索引值即可,代码如下所示。
fcList = ["Hydrants", "Water Mains", "Valves", "Wells"]
fc = fcList[0] ##first item in the list - Hydrants
print(fc)
>>>Hydrants
fc = fcList[3] ##fourth item in the list - Wells
print(fc)
>>>Wells
通过使用append()方法可以在已有的列表中添加新元素,具体代码如下。
fcList.append("Sewer Pipes")
print(fcList)
>> Hydrants, Water Mains, Valves, Wells, Sewer Pipes
列表可以通过切片返回多个值。下列代码所示为用冒号隔开两个偏移量进行列表切片操作,第一偏移量表示起始索引值,第二偏移量表示终止索引值,注意并不是返回终止索引值对应的值,而是其前一个索引对应的值,前面已经讲述。列表切片返回的是一个新的列表。
fcList = ["Hydrants", "Water Mains", "Valves", "Wells"]
fc = fcList[0:2] ##get the first two items – Hydrants, Water Mains
列表本质上是动态的,即可以在已有的列表中添加元素、删除元素和改变已有的内容,且这些操作不需要创建新的列表副本。改变列表中的值可以通过索引或切片来实现,索引改变的是列表中的单个值,而切片改变的是列表中的多个值。
Python 中有许多操作列表中值的方法,如:sort()方法可以对列表中的内容进行升序或降序排列;append()方法可以在列表的末尾添加元素,而insert()方法可以在列表的任意位置插入元素;remove()方法可以移除列表中第1个与参数匹配的项,而pop()方法可以删除列表中的元素(默认是最后一个)并返回该元素的值;reverse()方法可以对列表中的内容进行反向排序。
5.元组
元组与列表类似,但也有一些明显的区别。与列表一样,元组也是由值的序列组成,这些值可以是任何类型的数据;与列表不同的是,元组的内容是静态的。元组创建后,既不能更改值的顺序,也不能添加或删除值,当一些列表数据需要固定不变时,元组的这一特性恰好满足要求。创建元组很简单,就是把值放在括号内并用逗号分隔开,如下代码所示。
fcTuples = ("Hydrants", "Water Mains", "Valves", "Wells")
读者可能已经注意到创建元组与创建列表非常相似,区别仅在于元组使用圆括号而列表使用方括号。
与列表类似,元组的索引值从0开始,访问存储在元组中的值的方法与列表相同,代码示例如下。
fcTuples = ("Hydrants", "Water Mains", "Valves", "Wells")
print(fcTuples[1])
>>>Water Mains
当列表的内容要求是静态时,通常用元组代替列表,因为列表不能保证这一点,而元组可以。
6.字典
字典是Python中第2类集合对象。它类似于列表,所不同的是字典是对象的无序集合。字典通过键而不是偏移量来存储和获取值,字典中的每个键都有一个关联值,如图1-14所示。
与列表类似,在字典中也可以使用函数来改变字典的长度。下面的代码示例介绍了如何创建字典并为其赋值,以及如何使用键来访问字典中的值。创建字典要使用花括号,花括号内的每个键后面有一个冒号,冒号后是与这个键相关联的值,这些键/值对用逗号分隔开。
##create the dictionary
dictLayers = {'Roads': 0, 'Airports': 1, 'Rail': 2}
##access the dictionary by key
print(dictLayers['Airports'])
>>>1
print(dictLayers['Rail'])
>>>2
常用的字典操作包括获取字典中元素的数量、使用键获取值、确定键是否存在、将键转换成列表以及获取一系列的值等操作。字典对象可以在适当的位置改变、扩大和收缩,也就是说Python不需要创建一个新的字典对象来保存修改过的字典。给字典中的键赋值可以通过在花括号中声明键并设置它等于某个值来实现。
小技巧:
与列表不同,字典不能切片,因为它的内容是无序的。如果需要遍历字典中所有的值,可以使用keys()方法,它能返回一个包含字典中所有键的集合,并且可以单独赋值或取值。
1.3.5 类和对象
类和对象是面向对象编程的基本概念。尽管Python倾向于面向过程的编程,但也支持面向对象的编程。在面向对象编程中,类用于创建对象实例,可以把类视为创建一个或多个对象的模板。每个对象实例具有相同的属性和方法,但对象存储的数据通常是不同的。对象是Python中的复杂数据类型,由属性和方法组成,可以像其他数据类型一样赋值给变量。属性包含与对象相关的数据,而方法是对象可以执行的操作。
下面用一个例子来解释这些概念。在ArcPy中,extent类是通过给出矩形左下角和右上角的地图坐标来指定的矩形。extent类包含一些属性和方法。属性包括XMin、XMax、YMin、YMax、spatialReference等,其中x、y的最大值和最小值属性存储extent矩形的坐标,spatialReference属性存储extent类中spatialReference对象的空间参考系。extent类的对象实例可以通过点记法(.)来设置和获取属性值。这个例子的代码示例如下。
# get the extent of the county boundary
ext = row[0].extent
# print out the bounding coordinates and spatial reference
print("XMin: " + str(ext.XMin))
print("XMax: " + str(ext.XMax))
print("YMin: " + str(ext.YMin))
print("YMax: " + str(ext.YMax))
print("Spatial Reference: " + ext.spatialReference.name)
脚本运行的结果如下。
XMin: 2977896.74002
XMax: 3230651.20622
YMin: 9981999.27708
YMax: 10200100.7854
Spatial Reference:
NAD_1983_StatePlane_Texas_Central_FIPS_4203_Feet
extent类还提供了一些对象可以执行的方法,大多数方法是extent对象和其他几何图形之间的几何运算,如contains()(包含)、crosses()(相交)、disjoint()(不相交)、equals()(相等)、overlaps()(重叠)、touches()(邻接)和within()(包含于)等。
另一个需要掌握的面向对象的概念是点记法,它是一种访问对象的属性和方法的方式,同时也表示了这些属性或方法属于某一个特定的类。
点记法使用的语法是在对象实例后跟一个点,其后是属性或方法的名称。不管是访问属性还是方法,其语法描述都是一样的,但是,如果是访问方法,方法名后要有一个圆括号,括号内可以没有参数也可以有多个参数,如下列代码所示。
Property: extent.XMin
Method: extent.touches()
1.3.6 语句
Python中的每一行代码称为一条语句。Python有许多不同类型的语句,如有创建变量和给变量赋值的语句、有根据测试结果执行分支代码的条件语句和多次执行代码块的循环语句等。在脚本中编写语句时,需要遵循一定的规则。创建变量和赋值语句在前文中已经介绍过,下面介绍其他类型的语句。
1.条件语句
if/elif/else 语句是 Python 中基本的条件判断语句,用来判断给定条件的True/False值,以决定条件后代码分支的执行情况,即使用条件语句可以控制程序的流程。下面给出一个条件判断的示例:如果变量存储了点要素类,则获取它的X、Y坐标;如果要素类名称为“Roads”,则获取Name字段。
在Python中,True值是指任何非零数字或非空对象;False值是指零数字或空对象,往往表示不正确。一般地,比较测试的返回值是1或0(真或假),布尔运算的and/or运算的返回值是真或假。
if fcName == 'Roads':
arcpy.Buffer_analysis(fc, "C:\\temp\\roads.shp", 100)
elif fcName == 'Rail':
arcpy.Buffer_analysis(fc, "C:\\temp\\rail.shp", 50)
else:
print("Can't buffer this layer")
Python的代码编写必须遵循一定的语法规则。语句是一条条顺序执行的,直到遇到分支语句,通常使用的分支语句是if/elif/else语句。此外,也可以使用for和while等循环结构来改变程序流程。Python会自动检测语句和代码块的边界,所以不需要在代码块的边界使用括号或分隔符,而是使用缩进来确定代码块(这一点与C和C#等语言是不同的)。许多编程语言使用分号来结束语句,但Python不是这样。复合语句中需要包含“:”,它的编写规则是:复合语句首行以冒号结束,其后代码块中的语句需要以相同量级逐行缩进在复合语句首行的下方即可。
2.循环语句
循环语句是根据需要可以重复执行的代码行。如果条件表达式的结果为True,while循环体就会重复执行,如果条件表达式的结果为False,Python会跳出循环,执行while循环后的代码。在下面的代码示例中,首先给x变量赋值为10,while循环语句判断x的值是否小于100,如果是,则输出x的当前值并且x的值增加10,然后继续判断while后的条件表达式的值。第2次循环时,x的值变为20仍然小于100,所以条件表达式的值仍为True,然后执行输出x值和累加操作,这个过程一直循环,直到x大于或等于100。当x的值不满足x<100的条件时,此时测试结果为False,循环结束。在编写while语句时要特别注意,必须要有跳出循环的条件,否则会陷入死循环。死循环是计算机程序无限次循环执行指定的代码。无论是由于循环不具有终止条件或尽管有终止条件但不能满足,还是由于有导致循环重新开始的条件,都会陷入死循环。
x = 10
while x < 100:
print(x)
x = x + 10
for循环是一种可按预定的次数执行代码块的循环方式,它有两种情况:一种是计数循环,可以根据预定次数循环代码块;另一种是序列循环,可以遍历序列中的所有对象。在下面的例子中,序列循环依次执行字典中的每个值后就停止了循环。
dictLayers = {"Roads":"Line","Rail":"Line","Parks":"Polygon"}
for key in dictLayers:
print(dictLayers[key])
有时候,需要跳出循环,可以使用break语句或continue语句来实现。break语句跳出最近的封闭循环,即跳出当前的循环代码块;continue语句跳回到当前封闭循环的顶部,根据条件继续执行循环代码块。这两个语句可以在代码块的任何地方出现。
3.try语句
try 语句是用来处理异常的复合语句。异常是一种控制程序的高级手段,它可以截断程序或抛出错误,Python既可以截断程序也可以抛出异常。当代码出现错误时,Python会自动抛出异常,此时需要程序员捕获这个自动抛出的异常,并决定是否处理它。异常也可以通过代码手动抛出,在这种情况下,需要提供一个异常处理程序来捕获这些手动抛出的异常。
try语句有两种基本类型:try/except/else和try/finally。基本的try语句以try为首行,后跟缩进的代码块,之后是一个或多个可选择的except子句,用来命名捕获的异常,最后是一个可选的else子句。
import arcpy
import sys
inFeatureClass = arcpy.GetParameterAsText(0)
outFeatureClass = arcpy.GetParameterAsText(1)
try:
# If the output feature class exists, raise an error
if arcpy.Exists(inFeatureClass):
raise overwriteError(outFeatureClass)
else:
# Additional processing steps
print("Additional processing steps")
except overwriteError as e:
# Use message ID 12, and provide the output feature class
# to complete the message.
arcpy.AddIDMessage("Error", 12, str(e))
try/except/else语句的工作原理如下:当代码执行到try语句时,Python会标记已进入一个try代码块,如果执行try子句时抛出一个异常,程序就会跳转到except语句。如果找到与异常匹配的except语句,就会执行该except子句,此时,try/except/else语句执行完毕,这种情况下不执行else语句。如果没有异常抛出,则try子句中的每个语句都执行,然后代码指针跳到else语句并执行其中的代码,执行完成后跳出整个try代码块,继续执行下一行代码。
try语句的另一种类型是try/finally语句,它可以保证操作的完成。当在try语句中使用finally子句时,不管是否有异常抛出,该子句最后总会执行。
try/finally语句的工作原理如下:如果有异常抛出,Python先执行try子句,然后执行except子句,最后执行finally子句,执行完整个try语句后继续执行后面的代码;如果执行过程中没有异常抛出,则先执行try子句,然后执行finally子句。无论代码是否抛出异常,try/finally语句都可以保证某个操作总会发生。例如,关闭文件或断开数据库连接等清理操作通常放在finally子句中,以确保无论代码是否抛出异常,它们都会被执行。
import arcpy
try:
if arcpy.CheckExtension("3D") == "Available":
arcpy.CheckOutExtension("3D")
else:
# Raise a custom exception
raise LicenseError
arcpy.env.workspace = "D:/GrosMorne"
arcpy.HillShade_3d("WesternBrook", "westbrook_hill", 300)
arcpy.Aspect_3d("WesternBrook", "westbrook_aspect")
except LicenseError:
print("3D Analyst license is unavailable")
except:
print(arcpy.GetMessages(2))
finally:
# Check in the 3D Analyst extension
arcpy.CheckInExtension("3D")
4.with语句
当有两个相关操作需要作为代码块中的一对操作来执行时,可以使用with语句。with语句常用于打开、读取和关闭文件。打开和关闭文件是一对相关操作,而读取文件和对文件内容进行操作是这对相关操作之间执行的操作。当编写ArcGIS地理处理脚本时,with语句常与ArcGIS 10.1新引入的游标对象一起使用。后面的章节将会详细讲解游标对象,在这里仅作简单介绍。游标是要素类或表的属性表中的记录在内存中的副本。游标操作有3种类型:插入游标可以插入新记录;搜索游标可以对记录建立只读的访问权限;更新游标可以编辑或删除记录。游标对象可以用with语句打开和自动关闭,并能以某种方式进行操作。
with语句可自动关闭文件或游标对象,就像是使用try/finally语句一样,但with语句的代码行更少,这使得编码更加简洁和高效。在下面的代码示例中,演示了使用with语句实现创建新的搜索游标、从游标中读取信息以及隐式关闭游标等操作。
import arcpy
fc = "c:/data/city.gdb/streets"
# For each row print the Object ID field, and use the SHAPE@AREA
# token to access geometry properties
with arcpy.da.SearchCursor(fc, ("OID@", "SHAPE@AREA")) as cursor:
for row in cursor:
print("Feature {0} has an area of {1}".format(row[0], row[1]))
5.语句缩进
编写代码时要特别注意语句的缩进,因为它对Python解释代码起着至关重要的作用。Python的复合语句使用缩进来创建代码块,这些复合语句包括if/then、for、while、try和with语句等。Python解释器会根据缩进来检测代码块。复合语句首行以冒号结尾,之后所有的代码行应缩进相同的距离。可以使用任意数量的空格来定义缩进,但每个代码块应使用相同级别的缩进,通常的做法是用〈Tab〉键来进行缩进。当Python解释器遇到代码行的缩进少于上一行时,就会认为该代码块已结束。下面的代码通过try语句说明了这一概念,try语句后的冒号表明后面的语句是复合语句的一部分,应当缩进,这些语句形成一个代码块。
此外,if语句包含在try语句中,这也是一个首行以冒号结尾的复合语句。因此,if语句中的任何语句都应进一步缩进。可以看到,下面的代码中if语句下有一条语句没有缩进,而是和if语句处于同一水平,这表明statement4是try代码块的一部分,而不属于if代码块。
try:
if :
<……>
except:
<……>
except:
<……>
JavaScript、Java和.NET等许多语言使用花括号来确定代码块,但Python使用缩进而不是花括号,这是为了减少代码编写量,增强代码的可读性。包含许多花括号的代码往往难以阅读,任何使用过其他语言的人对这一点都应该深有体会。不过,缩进确实需要一些时间来适应。
1.3.7 文件I/O(输入/输出)
在日常工作中,读者会经常需要在文件中读取或写入信息。Python有一种内置的对象类型,为多种任务提供了访问文件的方法。这里只介绍部分文件操作的功能,其中包括最常用的功能,如打开和关闭文件,在文件中读取和写入数据等。
Python的open()函数能够创建一个文件对象,它可以作为一个链接打开计算机的本地文件。在文件中读取或写入数据之前,必须调用open()函数。open()函数的第1个参数是要打开文件的路径,第2个参数对应一个模式,通常是读模式(r)、写模式(w)或追加模式(a)等。“r”表示对打开文件进行只读操作;“w”表示对打开文件进行写入操作,打开一个已有的文件进行写入操作时,会覆盖文件中原有的数据,所以必须谨慎使用写模式;追加模式(a)在打开一个文件进行写入操作时,不会覆盖原有的数据,而是在文件的末尾追加新的数据。下面是一个使用open()函数以只读方式打开文本文件的代码示例。
with open('Wildfires.txt','r') as f:
注意上述代码示例也使用了with关键字来打开文件,以确保执行完代码后清理文件源。
打开一个文件后,可以使用多种方法读取文件中的数据。最常用的方法是使用readline()方法从文件中一次读取一行数据。readline()函数可以把一次读取的一行数据写入一个字符串变量。可以在Python代码中创建一个循环来逐行读取整个文件。如果要将整个文件读入一个变量,可以使用read()方法,它会读取文件直到遇到文件结束标记(EOF),还可以使用readlines()方法读取文件的全部内容,把每行代码存储为单个字符串,直到遇到EOF。
在下面的代码示例中,先用只读模式打开了“Wildfires.txt”文本文件,并使用 readlines()方法,将文件的全部内容读入一个名为“lstFires”的变量,该变量是一个Python列表,文件的每行存储为列表中的单独字符串。Wildfire.txt文件是一个用逗号分隔的文本文件,包含火灾点的经度和纬度以及每个火灾的置信度。然后循环遍历“lstFires”的每行内容,并使用split()函数根据逗号提取经度、纬度和置信度。最后用经度和纬度创建新的point对象,并使用插入游标将其插入到要素类中。
import arcpy, os
try:
arcpy.env.workspace = "C:/data/WildlandFires.mdb"
# open the file to read
with open('Wildfires.txt','r') as f: #open the file
lstFires = f.readlines() #read the file into a list
cur = arcpy.InsertCursor("FireIncidents")
for fire in lstFires: #loop through each line
if 'Latitude' in fire: #skip the header
continue
vals = fire.split(",") #split the values based on comma
latitude = float(vals[0]) #get latitude
longitude = float(vals[1]) #get longitude
confid = int(vals[2]) #get confidence value
#create new Point and set values
pnt = arcpy.Point(longitude,latitude)
feat = cur.newRow()
feat.shape = pnt
feat.setValue("CONFIDENCEVALUE", confid)
cur.insertRow(feat) #insert the row into featureclass
except:
print(arcpy.GetMessages()) #print out any errors
finally:
del cur
f.close()
与读取文件一样,把数据写入文件的方法也有很多。write()函数是最容易使用的方法,只需要一个字符串参数就可以将其写入文件。writelines()函数可以把列表结构的内容写入文件。在下面的代码示例中,创建了一个名为“fcList”的列表,其中含有一系列的要素类,可以用writelines()方法将这个列表写入文件。
outfile = open('C:\\temp\\data.txt','w')
fcList = ["Streams", "Roads", "Counties"]
outfile.writelines(fcList)