zookeeper与HDFS
在2.0之前HDFS中只有一个NameNode,但对于在线的应用只有一个NameNode是不安全的,故在2.0中对NameNode进行抽象,抽象成NamService其下包含有多个NameNode,但只有一个运行在活跃状态,因此需要zookeeper进行选举和自动转换。一旦active当掉之后zookeeper会自定进行切换将standby切换为active。
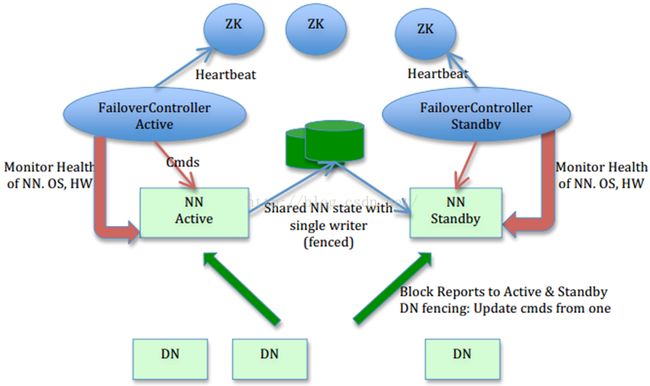
图片来源:HDFS-1623设计文档
图片作者: Sanjay Radia, Suresh Srinivas
如上图,每一个运行NameNode的机器上都会运行一个FailoverController Active进程,用于监控NameNode,即FailoverController与NameNode 二者是运行在同一台节点上的。
1】、如上,系统中Active NameNode一旦数据发生变化,Active NameNode会将变化(edits文件)写入到介质中,通常介质使用:
1、NFS网络文件系统;
2、依赖于zookeeper的JournalNode,当机器不是很多时可以使用JournalNode存储edits,而一旦介质中数据发生变化,Standby的NameNode会实时同步介质中的数据,因此ActiveNameNode与处于Standby的NameNode是实时数据同步的,
2】、FailoverController Active进程会实时监控Active的NameNode并把他的信息汇报给zookeeper(由此不难理解为什么要将FailoverController与NameNode 安装在同一个节点上了吧,因为FailoverController需要实时的监控NameNode将二者放在同一个节点上),若active NameNode没有发生故障,FailoverController Active进程会每隔一段时间将监控Actice NameNode的状态,并将Active NameNode的信息发送给zookeeper。若一旦监控到Active NameNode出现问题,就会将信息汇报给zookeeper,而另一个Standby FailoverController进程与active FailoverController进程是数据同步的(通过zookeeper实现)因此,Standby FailoverController进程会同时知道Active NameNode当掉了,此时会给它监控的Standby NameNode节点发送信息,使其成为Active NameNode。
CDH5.7.1版本的hdfs在zookeeper的目录为:/hadoop-ha/nameservice1/{ActiveBreadCrumb/ActiveStandbyElectorLock}
hadoop-ha/Namespace(集群当前为nameservice1 -- 对应hdfs的NameNode Nameservice配置);nameservice1 目录下有:ActiveBreadCrumb ActiveStandbyElectorLock 其内容均为nameservice1 - hadoop6 (hadoop6为当前activeNameNode hadoop7为standbyNameNode)
yarn在zookeeper上的节点:/yarn-leader-election/yarnRM/{ActiveBreadCrumb/ActiveStandbyElectorLock} 记载resourceManager的Active节点服务器地址
/rmstore/ZKRMStateRoot/{RMAppRoot,AMRMTokenSecretManagerRoot,EpochNode,RMDTSecretManagerRoot,RMVersionNode} 其中RMAppRoot保留了所有历史的提交到yarn上的应用程序的元数据。
/hbase/[...rs,master,balancer,namespace,hbaseid,table ...]
rs保留了region server的入口 其子节点对应region server 的 regionServer:60030/rs-status 中 的 RegionServer描述-ServerName(一般来说DataNode节点上都会安装region server 移动计算而不是移动数据)
balancer记录了其负载数据 namespace 记录了hbase的命名空间 一个命名空间包含default和hbase,命名空间内创建hbase表
hbaseid记录着hbase cluster id,table里的子节点为hbase上的表。table-lock 上锁的table表
与kafka的结合 -- kafka目录的配置在 kafka-配置的Zookeeper Root -- zookeeper.chroot 如果为空在默认在zookeeper的根目录下直接创建admin等节点,如果添加/kafka的话,则在/kafka的节点下创建一系列节点。
/kafka/{admin,isr_change_notification,controller_epoch,consumers,brokers,config,controller} 为kafka提供服务其中admin节点包含deletetopics其子节点为所有删除过得topic。isr_change_notification实现kafka分区同步监听任务。consumers记录了当前的消费者。brokers包含{ids,topics,seqid},ids包含子节点为brokerid 此时为170 --对应着kafka配置中的Kafka Broker 的Broker ID -- broker.id (当前kafka集群只有一个broker 其brokerid为170). brokerid为170,该节点的内容为{"jmx_port":"9393","timestamp","","endpoints":["PLAINTEXT://10.2.5.64:9092"],"host":"10.2.5.64","version":2,"port":9092} topics下面的节点对应的是有多少个topic,每个topic的子节点为partitions,partitions的子节点为分区编号{0,1,2,...},每个分区编号子节点为state,state节点下没有子节点了。state的数据为{"controller_epoch":25,"leader":170(brokerid),"version":1,"leader_epoch":1,"isr":[170]} isr--对应的是该分区数据处在同步状态副本的brokerid
zookeeper与Hbase
Client客户端、Master、Region都会通过心跳机制(RPC通信)与zookeeper保持联系。
当在Hbase中插入或读取数据时流程如下;
1、在Client中写一个Java类运行,客户端只需要连接zookeeper,客户端会从zookeeper中得到Regionserver的映射信息,之后客户端会直接连接到Region Server,
2、RegionServer在启动之后会向zookeeper汇报信息(通过心跳RPC):本身有多少Region,有哪些数据,当前机器的运行状况等等。
3、master 启动后也会向zookeeper汇报信息,并且从zookeeper中得到Region Server的一些信息。例如当一台Region Server当掉之后,zookeeper会得知,之后Master也会通过zookeeper得到该Region Server当掉的信息。
4、当客户端Client在做DDL(创建,修改,删除表)时,会通过zookeeper获取到Master的地址,而Master中保存了表的元数据信息,之后Client就可以直接与Master进行通信,进行表的DDL操作
5、当Region中数据不断增大,MAster会向Region Serve发送指令,讲分割出来的Region进行转移,
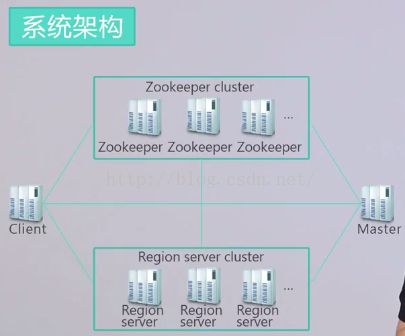
Zookeeper:
1】保证任何时候,集群中只有一个活跃的master,因为为保证安全性会启动多个Master
2】存储所有Region的寻址入口。知道那个Region在哪台机器上。
3】实时监控Region Server的状态,将Region Server的上下线的信息汇报给HMaster。(因为每间隔一段时间,RegionServer与Master都会zookeeper发送心跳信息),Region Server不直接向Master发送信息的原因是为了减少Master的压力因为只有一个活跃的Master,所有的RegionServer同时向他汇报信息,压力太大。而若有100台RegionServer时,Region Server可以分每10台向一个zookeeper汇报信息,实现zookeeper的负载均衡。
4】存储Hbase的元数据(Schema)包括,知道整个Hbase集群中有哪些Table,每个 Table 有哪些column family(列族)
Client
Client包含了访问Hbase的接口,Client维护这些Cache来加快对Hbase的访问,比如Region的位置信息,zookeeper,zookeeper保证了任何时候群众只有一个Master存储所有的Region中的寻址入口还有实时监控RegionServer上的状态,将RegionServer的上线和下线信息实时通知给Master,存储hbase 的Schema,包括有哪些table,每个Table有哪些Column Family
Master
Master有以下特点:
1、为RegionServer分配Region
2、负责RegionServer的负载均衡
3、发现失效的RegionServer并重新分配其上的Region
4、HDFS上的垃圾文件回收
5、处理Schema更新请求
RegionServer有以下几点:
1、RegionServer维护Master分配给他的 Region,处理对这些Region的IO请求
2、RegionServer负责切分在运行过程中变得过大的Region,
因此可看出,Client访问Hbase上的数据的过程并不需要Master的参与(寻址访问zookeeper和Region Serve,写数据访问Region Server)Master仅仅维护着table和Region的元数据信息。负载很低。