深入浅出看懂AlphaGo Zero - PaperWeekly 第51期
AlphaGo Zero = 启发式搜索 + 强化学习 + 深度神经网络,你中有我,我中有你,互相对抗,不断自我进化。使用深度神经网络的训练作为策略改善,蒙特卡洛搜索树作为策略评价的强化学习算法。
1. 论文正文内容详细解析
先上干货论文:Mastering the Game of Go without Human Knowledge [1],之后会主要以翻译论文为主,在语言上尽量易懂,避免翻译腔。
AlphaGo Zero,从本质上来说完全不同于打败樊麾和李世石的版本。
算法上,自对弈强化学习,完全从随机落子开始,不用人类棋谱。之前使用了大量棋谱学习人类的下棋风格)。
数据结构上,只有黑子白子两种状态。之前包含这个点的气等相关棋盘信息。
模型上,使用一个神经网络。之前使用了策略网络(基于深度卷积神经网)学习人类的下棋风格,局面网络(基于左右互搏生成的棋谱,为什么这里需要使用左右互搏是因为现有的数据集不够,没法判断落子胜率这一更难的问题)来计算在当前局面下每一个不同落子的胜率。
策略上,基于训练好的这个神经网,进行简单的树形搜索。之前会使用蒙特卡洛算法实时演算并且加权得出落子的位置。
1.1 AlphaGo Zero 的强化学习
1.1.1 问题描述
在开始之前,必须再过一遍如何符号化的定义一个围棋问题。
围棋问题,棋盘 19×19=361 个交叉点可供落子,每个点三种状态,白(用 1 表示),黑(用 -1 表示),无子(用 0 表示),用
描述此时棋盘的状态,即棋盘的状态向量记为
假设状态
(action 首字母)。
公式1.2 假设其中 1 在向量中位置为 39 ,则
有以上定义,我们就把围棋问题转化为:任意给定一个状态
简而言之,看到

1.1.2 网络结构
新的网络中,使用了一个参数为 θ(需要通过训练来不断调整) 的深度神经网络 fθ。
网络输入: 19×19×17 0/1 值:现在棋盘状态的
网络输出(两个输出):落子概率( 362 个输出值)和一个评估值([-1,1]之间)记为
。
• 落子概率 P:向量表示下一步在每一个可能位置落子的概率,又称先验概率 (加上不下的选择),即
(公式表示在当前输入条件下在每个可能点落子的概率)。
• 评估值 v:表示现在准备下当前这步棋的选手在输入的这八步历史局面
网络结构:基于 Residual Network(大名鼎鼎 ImageNet 冠军 ResNet)的卷积网络,包含 20 或 40 个 Residual Block(残差模块),加入批量归一化 Batch normalisation 与非线性整流器 rectifier non-linearities 模块。
1.1.3 改进的强化学习算法
自对弈强化学习算法(什么是强化学习 [2],非常建议先看看强化学习的一些基本思想和步骤,有利于理解下面策略、价值的概念,推荐系列笔记 [3])。
在每一个状态
MCTS 搜索得出的落子概率比 fθ 输出的仅使用神经网络输出的落子概率 p 更强,因此,MCTS 可以被视为一个强力的策略改善(policy improvement)过程。
使用基于 MCTS 提升后的策略(policy)来进行落子,然后用自对弈最终对局的胜者 z 作为价值(Value),作为一个强力的策略评估(policy evaluation)过程。
并用上述的规则,完成一个通用策略迭代算法去更新神经网络的参数 θ ,使得神经网络输出的落子概率和评估值,即
在这里补充强化学习的通用策略迭代(Generalized Policy Iteration)方法。
• 从策略 π0 开始
• 策略评估(Policy Evaluation)- 得到策略 π0 的价值 vπ0 (对于围棋问题,即这一步棋是好棋还是臭棋)
• 策略改善(Policy Improvement)- 根据价值 vπ0,优化策略为 π0+1(即人类学习的过程,加强对棋局的判断能力,做出更好的判断)
• 迭代上面的步骤 2 和 3,直到找到最优价值 v∗,可以得到最优策略 π∗
△ Figure 1
图 a 表示自对弈过程 s1,…,sT。在每一个位置 st,使用最新的神经网络 fθ 执行一次 MCTS 搜索 αθ。根据搜索得出的概率 at∼πi 进行落子。终局 sT 时根据围棋规则计算胜者 z。 πi 是每一步时执行 MCTS 搜索得出的结果(柱状图表示概率的高低)。
图 b 表示更新神经网络参数过程。使用原始落子状态
作为输入,得到此棋盘状态
以最大化 pt 与 πt 相似度和最小化预测的胜者 vt 和局终胜者 z 的误差来更新神经网络参数 θ(详见公式1) ,更新参数 θ ,下一轮迭代中使用新神经网络进行自我对弈。
我们知道,最初的蒙特卡洛树搜索算法是使用随机来进行模拟,在 AlphaGo1.0 中使用局面函数辅助策略函数作为落子的参考进行模拟。在最新的模型中,蒙特卡洛搜索树使用神经网络 fθ的输出来作为落子的参考(详见下图 Figure 2)。
每一条边
(每个状态下的落子选择)保存的是三个值:先验概率
每次模拟(模拟一盘棋,直到分出胜负)从根状态开始,每次落子最大化上限置信区间
,直到遇到叶子节点 s′。
叶子节点(终局)只会被产生一次用于产生先验概率和评估值,符号表示即 fθ(s′)=(P(s′,⋅),V(s′))。
模拟过程中遍历每条边
时更新记录的统计数据。访问次数加一
;更新行动价值为整个模拟过程的平均值,即
表示在模拟过程中从
的所有落子行动
△ Figure 2
图 a 表示模拟过程中遍历时选 Q+U 更大的作为落子点。
图 b 表示叶子节点 sL 的扩展和评估。使用神经网络对状态 sL 进行评估,即 fθ(sL) = (P(sL,⋅),V(sL)) ,其中 P 的值存储在叶子节点扩展的边中。
图 c 更新行动价值 Q 等于此时根状态
图 d 表示当 MCTS 搜索完成后,返回这个状态
MCTS 搜索可以看成一个自对弈过程中决定每一步如何下的依据,根据神经网络的参数 θ 和根的状态
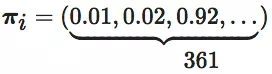


1.1.4 训练步骤总结
使用 MCTS 下每一步棋,进行自对弈,强化学习算法(必须了解通用策略迭代的基本方法)的迭代过程中训练神经网络。
• 神经网络参数随机初始化 θ0
• 每一轮迭代 i⩾1,都自对弈一盘(见Figure-1)
• 第 t 步:MCTS 搜索 πt=αθi−1(st) 使用前一次迭代的神经网络 fθi−1,根据MCTS结构计算出的落子策略 πt 的联合分布进行【采样】再落子
• 在 T 步 :双方都选择跳过;搜索时评估值低于投降线;棋盘无地落子。根据胜负得到奖励值 Reward rT∈{−1,+1}
• MCTS 搜索下至中盘的过程的每一个第 t 步的数据存储为
• 同时,从上一步
• 神经网络
其中 c 是 L2 正则化的系数。
1.2 AlphaGo Zero 训练过程中的经验
最开始,使用完全的随机落子训练持续了大概 3 天。训练过程中,产生 490 万场自对弈,每次 MCTS 大约 1600 次模拟,每一步使用的时间 0.4 秒。使用了 2048 个位置的 70 万个 Mini-Batches 来进行训练。训练结果如下,图3:
△ Figure 3
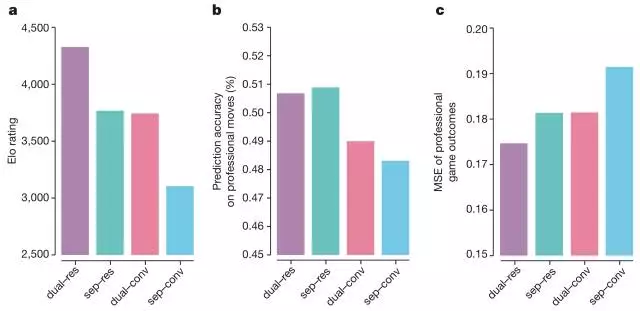
图 a 表示随时间 AlphaGo Zero 棋力的增长情况,显示了每一个不同的棋手 αθi 在每一次强化学习迭代时的表现,可以看到,它的增长曲线非常平滑,没有很明显的震荡,稳定性很好。图 b 表示的是预测准确率基于不同迭代第 i 轮的 fθi。图 c 表示的 MSE(平方误差)。
在 24 小时的学习后,无人工因素的强化学习方案就打败了通过模仿人类棋谱的监督学习方法为了分别评估结构和算法对结构的影响,得到了,下图 4:
△ Figure 4
dual-res 表示 AlphaGo Zero,sep-conv 表示 AlphaGo Lee(击败李世乭的)使用的网络结构(P+V 且分开)。

1.3 AlphaGo Zero 学到的知识
在训练过程中,AlphaGo Zero 可以一步步的学习到一些特殊的围棋技巧(定式),如图 5:

△ 图5
中间的黑色横轴表示的是学习时间,图 a 对应的 5 张棋谱展现的是不同阶段 AlphaGo Zero 在自对弈过过程中展现出来的围棋定式上的新发现。图 b 展示在右星位上的定式下法的进化。可以看到训练到 50 小时,点三三出现了,但再往后训练,b 图中的第五种定式高频率出现,在 AlphGa Zero 看来,这一种形式似乎更加强大。图 c 展现了前 80 手自对弈的棋谱伴随时间,明显有很大的提升,在第三幅图中,已经展现出了比较明显的围的倾向性。
1.4 AlphaGo Zero 的最终实力
之后,最终的 AlphaGo Zero 使用 40 个残差模块,训练接近 40 天。在训练过程中,产生了 2900 万盘的自对弈棋谱,使用了 310 万个 Mini-Batches 来训练神经网络,每一个 Mini-Batch 包含了 2048 个不同的状态。(覆盖的状态数是 63 亿(
被评测不同版本使用计算力的情况,AlphaGo Zero 和 AlphaGo Master 被部署到有 4 个 TPUs的单机上运行(主要用于做模型的输出预测 Inference 和 MCTS 搜索),AlphaGo Fan(打败樊麾版本)和 AlphaGo Lee(打败李世乭版本) 分布式部署到机器群里,总计有 176GPUs 和 48GPUs(Goolge 真有钱)。还加入了 raw network,它是每一步的仅仅使用训练好的深度学习神经网的输出 pa 为依据选择最大概率点来落子,不使用 MCTS 搜索(Raw Network 裸用深度神经网络的输出已经十分强大,甚至已经接近了 AlphaGo Fan) 。
下图 6 展示不同种 AlphaGo 版本的棋力情况:
△ 图6
图 a 随着训练时间棋力的增强曲线,图 b 裸神经网络得分 3055,AlphaGo Zero 得分 5185,AlphaGo Master 得分 4858,AlphaGo Lee 得分 3738,AlphaGo Fan 得分 3144。
最终,AlphaGo Zero 与 AlphaGo Master 的对战比分为 89:11,对局中限制一场比赛在 2 小时之内(新闻中的零封是对下赢李世乭的 AlphaGo Lee)。

2. 论文附录内容
我们知道,Nature 上的文章一般都是很强的可读性和严谨性,每一篇文章的正文可能只有 4-5 页,但是附录一般会远长于正文。基本所有你的技术细节疑惑都可以在其中找到结果,这里值列举一些我自己比较感兴趣的点,如果你是专业人士,甚至想复现 AlphaGo Zero,读原文更好更精确。
2.1 自对弈训练工作流
AlphaGo Zero 的工作流由三个模块构成,可以异步多线程进行:深度神经网络参数 θi 根据自对弈数据持续优化;持续对棋手 αθi 棋力值进行评估;使用表现最好的 αθ∗ 用来产生新的自对弈数据。
2.1.1 优化参数
每一个神经网络 fθi 在 64 个 GPU 工作节点和 19 个 CPU 参数服务器上进行优化。
批次(batch)每个工作节点 32 个,每一个 mini-batch 大小为 2048。每一个 mini-batch 的数据从最近 50 万盘的自对弈棋谱的状态中联合随机采样。
神经网络权重更新使用带有动量(momentum)和学习率退火(learning rate annealing)的随机梯度下降法(SGD),损失函数见公式 1。
学习率退火比率见下表:
动量参数设置为 0.9,L2 正则化系数设置为
,优化过程每 1000 个训练步数执行一次,并使用这个新模型来生成下一个 Batch 的自对弈棋谱。

2.1.2 评估器
在使用检查点(checkpoint)新的神经网络去生成自对弈棋谱前,使用现有的最好网络来对它进行评估。评估神经网络 fθi 的方法是使用 fθi 进行 MCTS 搜索得出 αθi。
每一个评估由 400 盘对局组成,MCTS 搜索使用 1600 次模拟,将温度参数设为无穷小 τ⇒0(目的是为了使用最多访问次数的落子下法去下,追求最强的棋力),如果新的选手 αθi 胜率大于 55%,将这个选手更新为最佳选手 αθ∗,用来产生下一轮的自对弈棋谱,并且设为下一轮的比较对象。
2.1.3 自对弈
通过评估器,现在已经有一个当前的最好棋手 αθ∗,使用它来产生数据。在每一次迭代中,αθ∗自对弈 25000 盘,其中每一步使用 1600 次 MCTS 模拟(每一步大约会花费 0.4 秒)。
前 30 步,温度 τ=1,与 MCTS 搜索中的访问次数成正比,目的是保证前 30 步下法的多样性。在之后的棋局中,温度设为无穷小。并在先验概率中加入狄利克雷噪声
,其中 η∼Dir(0.03) 且 ϵ=0.25。这个噪声保证所有的落子可能都会被尝试,但可能下出臭棋。
投降阈值 vrerign 自动设为错误正类率(如果 AlphaGo 没有投降可以赢的比例)小于 5%,为了测量错误正类(false positives),在 10% 的自对弈中关闭投降机制,必须下完。
2.2 搜索算法
这一部分详解的 AlphaGo Zero 的算法核心示意图(Figure2)。
每一个搜索树的中的节点
,每一条边存储一个数据集。
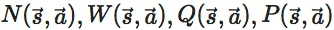
分别表示 MCST 的访问次数、行动价值的总和、行动价值的均值和选择这条边的先验概率。
多线程执行多次模拟,每一次迭代过程先重复执行 1600 次 Figure 2 中的前 3 个步骤,计算出一个 π ,根据这个向量下现在的这一步棋。
2.2.1 Selcet - Figure2a
MCTS 中的选择步骤和之前的版本相似,详见 AlphaGo 之前的详解文章 [5],这篇博文详细通俗的解读了这个过程。概括来说,假设 L 步走到叶子节点,当走第 t 步时,根据搜索树的统计概率落子。
其中计算
使用 PUCT 算法的变体。
其中 cpuct 是一个常数。这种搜索策略落子选择最开始更趋向于高先验概率和低访问次数的,但逐渐的会更加趋向于选择有着更高行动价值的落子。


2.2.2 Expand and evaluate - Figure 2b
将叶子节点
加到一个队列中等待输入至神经网络进行评估,
,其中 di 表示一个 1 至 8 的随机数来表示双面反射和旋转选择(从 8 个不同的方向进行评估)。
队列中的不同位置组成一个大小为 8 的 mini-batch 输入到神经网络中进行评估。整个 MCTS 搜索线程被锁死直到评估过程完成。叶子节点被展开,每一条边
被初始化为
。之后将神经网络的输出值 v 传回。
2.2.3 Backup - Figure 2c
沿着回溯的路线将边的统计数据更新。
注解:在
的更新中,使用了神经网络的输出 v,而最后的价值就是策略评估中的使用虚拟损失(virtual loss)确保每一个线程评估不同的节点。

2.2.4 Play - Figure 2d
进行了一次 MCTS 搜索后,AlphaGo Zero 才从
状态下走出第一步
其中 τ 是一个温度常数用来控制探索等级(level of exploration)。搜索树会在接下来的走子中继续使用,如果孩子节点和落子的位置吻合,它就成为新的根节点,保留子树的所有统计数据,同时丢弃其他的树。如果根的评价值和它最好孩子的评价值都低于 vresign,AlphaGo Zero 就认输。
与之前的版本的 MCTS 相比,AlphaGo Zero 最大的不同是没有使用走子网络(Rollout),而是使用一个神经网络。
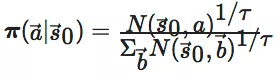
2.3 数据集
GoKifu 数据集:http://gokifu.com/
KGS 数据集:https://u-go.net/gamerecords/
2.4 图 5 更多细节
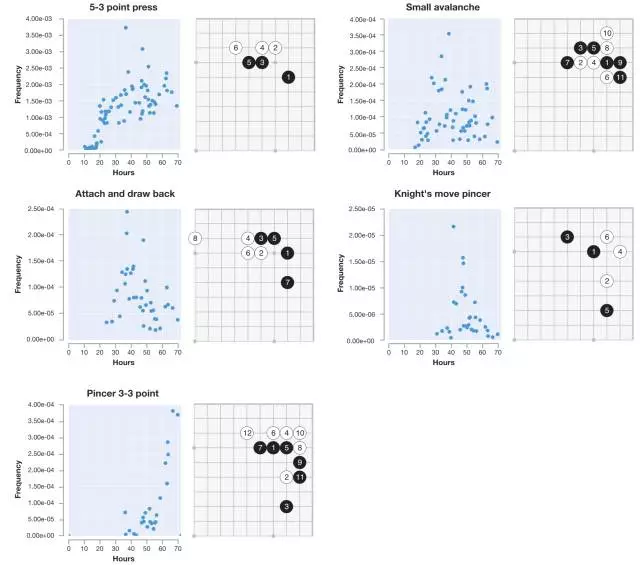
△ Figure 5a 中每种定式出现的频率图

△ Figure 5b 中每种定式出现的频率图
3. 总结与随想
AlphaGo Zero = 启发式搜索 + 强化学习 + 深度神经网络,你中有我,我中有你,互相对抗,不断自我进化。使用深度神经网络的训练作为策略改善,蒙特卡洛搜索树作为策略评价的强化学习算法。
之后提出一些我在看论文时带着的问题,最后给出我仔细看完每一行论文后得出的回答,如有错误,请批评指正。
3.1 问题与个人答案
Q: 训练好的 Alpha Zero 在真实对弈时,在面对一个局面时如何决定下在哪个位置?
A: 评估器的落子过程即最终对弈时的落子过程(自对弈中的落子就是真实最终对局时的落子方式):使用神经网络的输出 p 作为先验概率进行 MCTS 搜索,每步1600次(最后应用的版本可能和每一步的给的时间有关)模拟,前 30 步采样落子,剩下棋局使用最多访问次数来落子,得到 π ,然后选择落子策略中最大的一个位置落子。
Q: AlphaGo Zero 的 MCTS 搜索算法和和上个版本的有些什么区别?
A: 对于 AlphaGo Zero 来说,最大的区别在于,模拟过程中依据神经网络的输出 p 的概率分布采样落子。采样是关键词,首先采样保证一定的随机特性,不至于下的步数过于集中。其次,如果模拟的盘数足够多,那这一步就会越来越强 其次,在返回(Bakcup)部分每一个点的价值(得分),使用了神经网络的输出 v。这个值也是策略评估的重要依据。
Q: AlphaGo Zero 中的策略迭代法是如何工作的?
A: 策略迭代法(Policy Iteration)是强化学习中的一种算法,简单来说:以某种策略(π0)开始,计算当前策略下的价值函数(vπ0);然后利用这个价值函数,找到更好的策略(Evaluate 和 Improve);接下来再用这个更好的策略继续前行,更新价值函数……这样经过若干轮的计算,如果一切顺利,我们的策略会收敛到最优的策略(π∗),问题也就得到了解答。
对于 AlphaGo Zero 来说,简单总结如下:策略评估过程,即使用 MCTS 搜索每一次模拟的对局胜者,胜者的所有落子
总的来说,有点像一个嵌套过程,MCST 算法可以用来解决围棋问题,这个深度神经网络也可以用来解决围棋问题,而 AlphaGo Zero 将两者融合,你中有我,我中有你,不断对抗,不对自我进化。
Q: AlphaGo Zero 最精彩的是哪部分?
A: 毫无悬念的,我会选择这个漂亮的公式。看懂公式每一项的来历,即产生的过程,就读懂了 AlphaGo Zero。这个公式你中有我,我中有你,这是一个完美的对抗,完美的自我进化。
第二我觉得很精彩的点子是将深度神经网络作为一个模块嵌入到了强化学习的策略迭代法中。最关键的是,收敛速度快,效果好,解决各种复杂的局面(比如一个关于围棋棋盘的观看角度可以从八个方向来看的细节处理的很好,又如神经网络的输入状态选择了使用历史八步)。

3.2 随想评论
随着 AlphaGo Zero 的归隐,DeepMind 已经正式转移精力到其他的任务上了。期待这个天才的团队还能搞出什么大新闻。
对于围棋这项运动的影响可能是:以后的学围棋手段会发生变化,毕竟世界上能复现 AlphaGo Zero 的绝对很多,那么 AlphaGo Zero 的实力那就是棋神的感觉,向 AlphaGo Zero 直接学习不是更加高效嘛?另,围棋受到的关注也应该涨了一波,是利好。
感觉强化学习会越来越热,对于和环境交互这个领域,强化学习更加贴近于人类做决策的学习方式。个人预测,强化学习会在未来会有更多进展。AlphaGo Zero 可能仅仅是一个开头。
原文发布时间为:2017-10-24
本文作者:刘遥行
本文来自云栖社区合作伙伴“PaperWeekly”,了解相关信息可以关注“PaperWeekly”微信公众号