YOLOv3:Darknet代码解析(三)卷积操作
目的:读懂YOLO_v3中的卷积操作以及相关语句
相关:YOLOv3:Darknet代码解析(六)简化的程序与卷积拆分 https://blog.csdn.net/weixin_36474809/article/details/81739771
相关文章:
YOLOv3:Darknet代码解析(一)安装Darknet
YOLOv3:Darknet代码解析(二)代码初步
YOLOv3:Darknet代码解析(三)卷积操作
YOLOv3:Darknet代码解析(四)结构更改与训练
YOLOv3:Darknet代码解析(五)权重与特征存储
YOLOv3:Darknet代码解析(六)简化的程序与卷积拆分
目录
1.卷积内容
2. gemm(重要)
2.1 线性代数中的gemm
2.2 卷积的语句: gemm_nn
2.3 另一个角度的卷积
3.其他内容
3.1 自上而下迭代到卷积
主函数
test_detector子函数
实现网络语句parse_network_cfg
加载权重load_weight
实现卷积层的代码
1.卷积内容
卷积层中核心代码,前馈的卷积层,反向传播的卷积层。
void forward_convolutional_layer(convolutional_layer l, network_state state)
{
int out_h = convolutional_out_height(l);
int out_w = convolutional_out_width(l);
int i;
fill_cpu(l.outputs*l.batch, 0, l.output, 1);
if(l.xnor){
binarize_weights(l.weights, l.n, l.c*l.size*l.size, l.binary_weights);
swap_binary(&l);
binarize_cpu(state.input, l.c*l.h*l.w*l.batch, l.binary_input);
state.input = l.binary_input;
}
int m = l.n;
int k = l.size*l.size*l.c;
int n = out_h*out_w;
printf("Layer number - %d\n", l.layer_num);
int hw = 0;
if (l.layer_num == 0) hw = 1;
else hw = 0;
printf("\nValue of m (l.n) = %d, k (l.size*l.size*l.c) = %d, n (out_h*out_w) = %d, l.c = %d\n", m,k,n,l.c);
if (l.xnor && l.c%32 == 0 && AI2) {
forward_xnor_layer(l, state);
printf("xnor\n");
} else {
float *a = l.weights;
float *b = state.workspace;
float *c = l.output;
for(i = 0; i < l.batch; ++i){
im2col_cpu(state.input, l.c, l.h, l.w,
l.size, l.stride, l.pad, b);
if(hw)
gemm_cpu_hw(0,0,m,n,k,1,a,k,b,n,1,c,n);
else
gemm(0,0,m,n,k,1,a,k,b,n,1,c,n);
c += n*m;
state.input += l.c*l.h*l.w;
}
}
if(l.batch_normalize){
forward_batchnorm_layer(l, state);
}
add_bias(l.output, l.biases, l.batch, l.n, out_h*out_w);
activate_array(l.output, m*n*l.batch, l.activation);
if(l.binary || l.xnor) swap_binary(&l);
}
其中,核心语句为 gemm(0,0,m,n,k,1,a,k,b,n,1,c,n);这个语句表示卷积中的矩阵乘。相应的图像转为取框矩阵的格式与权重相乘。把一个三维卷积等价转换为一个二维的矩阵乘。
2. gemm(重要)
2.1 线性代数中的gemm
为卷积操作中的矩阵乘法。在gemm.c中。gemm即线性代数中的矩阵相乘。几种,gemm_nn 、gemm_nt 、gemm_tn 、gemm_
tt这几个分别表示两个矩阵是否进行转置。
void gemm(int TA, int TB, int M, int N, int K, float ALPHA,
float *A, int lda,
float *B, int ldb,
float BETA,
float *C, int ldc)
{
gemm_cpu( TA, TB, M, N, K, ALPHA,A,lda, B, ldb,BETA,C,ldc);
}
void gemm_cpu(int TA, int TB, int M, int N, int K, float ALPHA,
float *A, int lda,
float *B, int ldb,
float BETA,
float *C, int ldc)
{
//printf("cpu: %d %d %d %d %d %f %d %d %f %d\n",TA, TB, M, N, K, ALPHA, lda, ldb, BETA, ldc);
int i, j;
for(i = 0; i < M; ++i){
for(j = 0; j < N; ++j){
C[i*ldc + j] *= BETA;
}
}
if(!TA && !TB)
gemm_nn(M, N, K, ALPHA,A,lda, B, ldb,C,ldc);
else if(TA && !TB)
gemm_tn(M, N, K, ALPHA,A,lda, B, ldb,C,ldc);
else if(!TA && TB)
gemm_nt(M, N, K, ALPHA,A,lda, B, ldb,C,ldc);
else
gemm_tt(M, N, K, ALPHA,A,lda, B, ldb,C,ldc);
}前两个TA,TB决定了是否转置。后面运算函数为gemm_nn还是gemm_tn,gemm_nt,gemm_tt。输入层中输入TA,TB都为0,即不进行转置。因此用到的函数为gemm_nn。
2.2 卷积的语句: gemm_nn
void gemm_nn(int M, int N, int K, float ALPHA,
float *A, int lda,
float *B, int ldb,
float *C, int ldc)
{
printf ("GEMM NN SW\n");
int i,j,k;
for(i = 0; i < M; ++i){
for(k = 0; k < K; ++k){
register float A_PART = ALPHA*A[i*lda+k];
for(j = 0; j < N; ++j){
C[i*ldc+j] += A_PART*B[k*ldb+j];
}
}
}
}A,B,C都为指针,在forward_convolutional_layer.c中,A为权重,B为图像值,C为输出
float *a = l.weights;
float *b = state.workspace;
float *c = l.output;M,N,K为输出的featureMap的坐标,对应于下面的m,n,k。lda,ldb,ldc对应于下面的K,N,N
int M = l.n;
int K = l.size*l.size*l.c;
int N = out_h*out_w;- M卷积核的个数,
- K卷积核的大小,
- N输出的feature-map的大小
- 权重M*K,输入 K*N, 输出 M*N
整个卷积过程有两个重要步骤,一个是M,K,N的值的大小,另一个是指针a,b,c指向的位置。
核心语句为三个for循环里面,
C[i*ldc+j] += A[i*lda+k] * B[k*ldb+j];
即输入C[ i*N + j ]+=A[ i*K +k ] * B[k*N + j ]
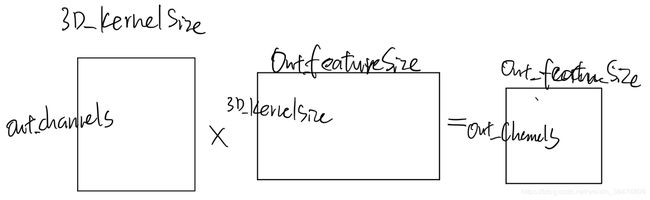
2.3 另一个角度的卷积
YOLOv3:Darknet代码解析(五)简化的程序与卷积拆分 https://blog.csdn.net/weixin_36474809/article/details/81739771
MTCNN(七)卷积更改为嵌套for循环格式 https://blog.csdn.net/weixin_36474809/article/details/83145601
// l.output[filters][width][height] +=
// state.input[channels][width][height] *
// l.weights[filters][channels][filter_width][filter_height];
// -------------convulution in 2D matrix format-------------------
// input kernel matrix * input feature matrix(Trans) = output feature matrix
// height (outChannels) height (3D_KernelSize) height (outChannels)
// width (3D_KernelSize) width (outFeatureSize) width (outFeatureSize)
//C=αAB + βC : outpBox=weightIn*matrixIn(T)
// A_transpose B_transpose
gemm_cpu(0, 1, \
//A row C row B col C col A col B row alpha
weightIn->out_ChannelNum, matrixIn->height, matrixIn->width, 1, \
//A* A'col B* B'col beta
weightIn->pdata,matrixIn->width,matrixIn->pdata,matrixIn->width, 0, \
//C* C'col
outpBox->pdata, matrixIn->height);3.其他内容
运行YOLO时的命令行为:./darknet detect cfg/yolov3-tiny.cfg yolov3-tiny.weights data/dog.jpg
我们需要找到m,k,n的大小,和a,b,c指针的位置。
3.1 自上而下迭代到卷积
找出一次实现网络之中迭代到卷积的函数
主函数
darknet.c
int main(int argc, char **argv)
{
if(argc < 2){
fprintf(stderr, "usage: %s \n", argv[0]);
return 0;
}
gpu_index = find_int_arg(argc, argv, "-i", 0);
if(find_arg(argc, argv, "-nogpu")) {
gpu_index = -1;
}
#ifndef GPU
gpu_index = -1;
#else
if(gpu_index >= 0){
cuda_set_device(gpu_index);
}
#endif
if (0 == strcmp(argv[1], "average")){
average(argc, argv);
} else if (0 == strcmp(argv[1], "detect")){
float thresh = find_float_arg(argc, argv, "-thresh", .25);
char *filename = (argc > 4) ? argv[4]: 0;
test_detector("cfg/coco.data", argv[2], argv[3], filename, thresh);
} else {
fprintf(stderr, "Not an option: %s\n", argv[1]);
}
return 0;
} test_detector子函数
主函数中test_detector子函数中,argv[2]为yolov3-tiny.cfg, argv[3]为yolov3-tiny.weights
//detector.c
void test_detector(char *datacfg, char *cfgfile, char *weightfile, char *filename, float thresh)
{
list *options = read_data_cfg(datacfg);
char *name_list = option_find_str(options, "names", "data/names.list");
char **names = get_labels(name_list);
image **alphabet = load_alphabet();
network net = parse_network_cfg(cfgfile);
if(weightfile){
load_weights(&net, weightfile);
}
layer l = net.layers[net.n-1];
set_batch_network(&net, 1);
srand(2222222);
clock_t time;
char buff[256];
char *input = buff;
int j;
float nms=.4;
box *boxes = calloc(l.w*l.h*l.n, sizeof(box));
float **probs = calloc(l.w*l.h*l.n, sizeof(float *));
for(j = 0; j < l.w*l.h*l.n; ++j) probs[j] = calloc(l.classes, sizeof(float *));
while(1){
if(filename){
strncpy(input, filename, 256);
} else {
printf("Enter Image Path: ");
fflush(stdout);
input = fgets(input, 256, stdin);
if(!input) return;
strtok(input, "\n");
}
image im = load_image_color(input,0,0);
image sized = resize_image(im, net.w, net.h);
float *X = sized.data;
time=clock();
network_predict(net, X);
printf("%s: Predicted in %f seconds.\n", input, sec(clock()-time));
get_region_boxes(l, 1, 1, thresh, probs, boxes, 0);
if (nms) do_nms_sort(boxes, probs, l.w*l.h*l.n, l.classes, nms);
draw_detections(im, l.w*l.h*l.n, thresh, boxes, probs, names, alphabet, l.classes);
save_image(im, "predictions");
show_image(im, "predictions");
free_image(im);
free_image(sized);
if (filename) break;
}
}实现网络语句parse_network_cfg
函数中,确定网络的语句:
network net = parse_network_cfg(cfgfile);
if(weightfile){
load_weights(&net, weightfile);
}
layer l = net.layers[net.n-1];
set_batch_network(&net, 1);加载权重load_weight
函数中重要的为parse_network_cfg,此函数为根据相应的cfg文件创建神经网络,根据相应的load_weights加载相应的参数。
//parser.c
network parse_network_cfg(char *filename)
{
list *sections = read_cfg(filename);
node *n = sections->front;
if(!n) error("Config file has no sections");
network net = make_network(sections->size - 1);
net.gpu_index = gpu_index;
size_params params;
section *s = (section *)n->val;
list *options = s->options;
if(!is_network(s)) error("First section must be [net] or [network]");
parse_net_options(options, &net);
params.h = net.h;
params.w = net.w;
params.c = net.c;
params.inputs = net.inputs;
params.batch = net.batch;
params.time_steps = net.time_steps;
params.net = net;
size_t workspace_size = 0;
n = n->next;
int count = 0;
free_section(s);
fprintf(stderr, "layer filters size input output\n");
while(n){
params.index = count;
fprintf(stderr, "%5d ", count);
s = (section *)n->val;
options = s->options;
layer l = {0};
LAYER_TYPE lt = string_to_layer_type(s->type);
if(lt == CONVOLUTIONAL){
l = parse_convolutional(options, params);
}else if(lt == LOCAL){
l = parse_local(options, params);
}else if(lt == DROPOUT){
l = parse_dropout(options, params);
l.output = net.layers[count-1].output;
l.delta = net.layers[count-1].delta;
}else{
fprintf(stderr, "Type not recognized: %s\n", s->type);
}
l.dontload = option_find_int_quiet(options, "dontload", 0);
l.dontloadscales = option_find_int_quiet(options, "dontloadscales", 0);
option_unused(options);
net.layers[count] = l;
if (l.workspace_size > workspace_size) workspace_size = l.workspace_size;
free_section(s);
n = n->next;
++count;
if(n){
params.h = l.out_h;
params.w = l.out_w;
params.c = l.out_c;
params.inputs = l.outputs;
}
}
free_list(sections);
net.outputs = get_network_output_size(net);
net.output = get_network_output(net);
if(workspace_size){
net.workspace = calloc(1, workspace_size);
}
return net;
}实现卷积层的代码
//parser.c
convolutional_layer parse_convolutional(list *options, size_params params)
{
int n = option_find_int(options, "filters",1);
int size = option_find_int(options, "size",1);
int stride = option_find_int(options, "stride",1);
int pad = option_find_int_quiet(options, "pad",0);
int padding = option_find_int_quiet(options, "padding",0);
if(pad) padding = size/2;
char *activation_s = option_find_str(options, "activation", "logistic");
ACTIVATION activation = get_activation(activation_s);
int batch,h,w,c;
h = params.h;
w = params.w;
c = params.c;
batch=params.batch;
if(!(h && w && c)) error("Layer before convolutional layer must output image.");
int batch_normalize = option_find_int_quiet(options, "batch_normalize", 0);
int binary = option_find_int_quiet(options, "binary", 0);
int xnor = option_find_int_quiet(options, "xnor", 0);
convolutional_layer layer = make_convolutional_layer(batch,h,w,c,n,size,stride,padding,activation, batch_normalize, binary, xnor, params.net.adam);
layer.flipped = option_find_int_quiet(options, "flipped", 0);
layer.dot = option_find_float_quiet(options, "dot", 0);
if(params.net.adam){
layer.B1 = params.net.B1;
layer.B2 = params.net.B2;
layer.eps = params.net.eps;
}
return layer;
}