Kubernetes In Action 学习笔记 服务发现
为什么要有Service?
- Pod需要对来自集群内部其他Pod以及来自集群外部的客户端的HTTP请求做出响应
- service为一组功能相同的pod提供单一不变的接入点的资源,外界只需要通过IP与端口与service建立连接,这些链接会被路由到提供该服务的任意一个Pod上,通过这种方式,客户端不需要知道每个单独的Pod提供服务的Pod地址
apiVersion: v1
kind: Service
metadata:
name: kubia
spec:
ports:
- port: 80
targetPort: 8080
selector:
app: kubia
首先启动3个Pod,然后创建service后,可以尝试在其中一个Pod远程执行命令
kubectl exec kubia-hplhc -- curl -s http://10.105.65.253
测试service是否成功
但是每次产生的请求都会随机路由到不同的Pod,如果想要每次请求都指向同一个Pod,可以设置服务的sessionAffinitty属性为ClientIP
apiVersion: v1
kind: Service
metadata:
name: kubia
spec:
sessionAffinity: ClientIP
ports:
- port: 80
targetPort: 8080
selector:
app: kubia
同一个服务暴露多个端口
必须给每个端口指定名字
apiVersion: v1
kind: Service
metadata:
name: kubia
spec:
ports:
- name: http
port: 80
targetPort: 8080
- name: https
port: 443
targetPort: 8443
selector:
app: kubia
服务发现
-
通过环境变量发现服务
-
通过DNS发现服务
-
通过FQDN连接服务
Endpoint
服务不是和pod直接相连的。service和pod是通过endpoint来进行相连的。Endpoint资源就是暴露一个服务的IP地址和端口的列表。
服务暴露给外部客户端的方法
- 把服务设置成NodePort
每个集群节点都会在节点上打开一个端口,并且把在这个端口上接收到的流量重定向到基础服务。这个服务在内部集群IP和端口上才可以访问。

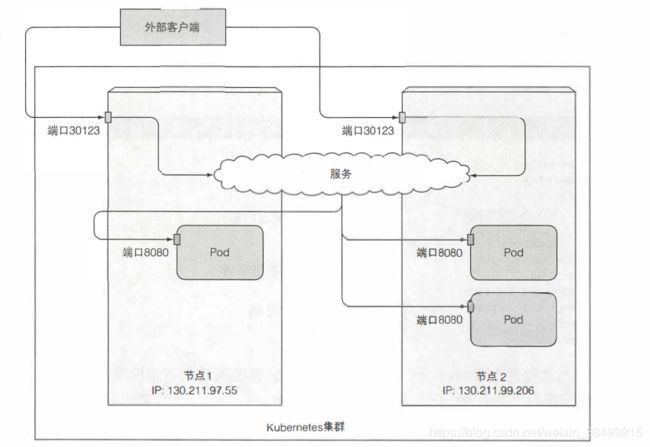
- LoadBalance
服务可以通过一个专用的负载均衡来访问,由Kubernetes中正在运行的云基础设施提供。负载均衡器把流量重定向到跨所有节点的节点端口,客户端再通过负载均衡器的IP连接到服务。
- Ingress
通过一个IP地址公开多个服务,运行在HTTP层。
为什么要有Ingress?
每个LoadBalancer服务都需要自己的负载均衡器以及独有的共有IP地址。Ingress只需要一个公网IP就可以为许多服务提供访问。当客户端向Ingress发送HTTP请求的时候,Ingress会根据请求的主机名和路径决定请求转发的服务。
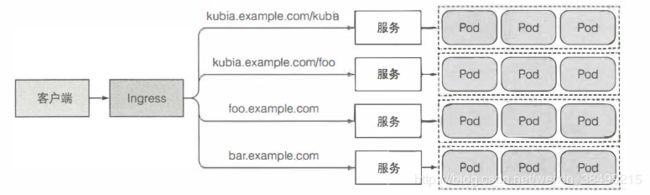
而且Ingress是在HTTP所属的应用层进行操作,可以提供一些服务不能实现的功能,诸如基于cookie的会话亲和性等功能。
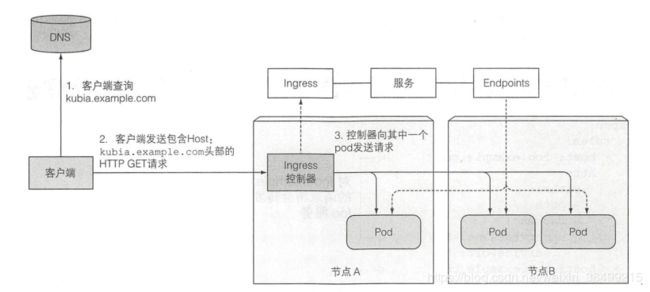
工作原理
1.执行DNS查询,返回IngressIP
2.客户端向Ingress控制器发送HTTP请求,并且在Host头中指定要访问的服务主机名和路径
3.Ingress controller就从报文头得知客户端尝试访问哪个服务
4.通过查询与该服务关联的Endpoint的对象查看pod IP,然后把客户端
的请求转发给其中一个Pod.
跨pod网络
- 同一个节点的pod怎么通信?

容器会创建一个虚拟的以太网接口对,其中一个对的接口会在物理主机的命名空间中。而其他的对会被移入容器的网络命名空间。
如果pod A发送网络包到pod B, 报文首先会经过pod A的veth 对到网桥然后经过pod B的veth 对。 所有节点上的容器都会连接到同一个网桥, 意味着它们都能够互相通信。 但是要让运行在不同节点上的容器之间能够通信, 这些节点的网桥需要以某种方式连接起来
- 不同节点上的pod通信

当报文从一个节点上容器发送到其他节点上的容器, 报文先通过
veth pair, 通过网桥到节点物理适配器,然后通过网线传到其他节点的物理适配器,再通过其他节点的网桥,最终经过vethpair到达目标容器。
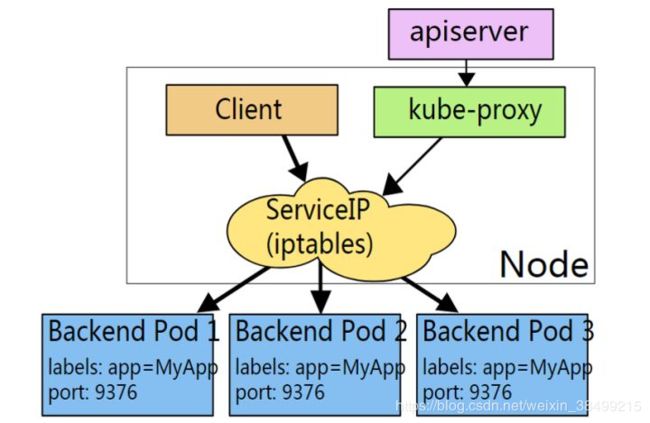
Service实现——Kube-proxy
采用kube-proxy负责service的实现,怎么决定使用哪个pod呢?
可以使用iptables的方法配置负载均衡,主要职责包括:
1.监听service
(service的创建删除与修改)
当在API服务器中创建一个服务 时, 虚拟 IP地址立刻就会分配给它。之后很短时间内, API服务器会 通知所有 运行在工作节点上的kube-proxy客户端有 一个新服务已经被创建了。然后 ,每个知be-proxy都会让该服务 在自己的运行 节点上可寻址。原理是通过建立一 些iptables规则, 确保每个目的地为服务的 IP/端口对的数据
包 被解析, 目的地址被修改, 这样数据包就会被重定向到支持服务的一个pod.
2.监听endpoint
Endpoint对象保存所有支持服务的pod的IP/端口对( 一
个IP/端口对也可以指向除pod之外的其他对象)。
(pod的扩容与缩容)
kube-proxy只是作为controller,真正提供服务的是内核的netfilter模块,体现在用户态的就是iptables。
iptables的负载分发策略下面介绍,就是轮询以及会话亲和性。
链接集群外部的服务
- Endpoint
service和pod并不是直接连接的,Endpoint资源介于pod和service之间,service会通过selector与pod建立关联,endpoint controller根据service关联到的pod的podIP组合成一个endpoint。
所谓endpoint资源就是暴露一个服务的IP地址和端口的列表,存储在etcd中,用来记录一个service对应的所有pod的访问地址。
- endpoint controller
service负载分发策略
那么service如何决定由哪个pod来提供服务?
1.RoundRobin: 轮询模式,轮询把请求转发到后端的各个Pod上
2.SessionAffinity: 基于客户端IP地址进程会话保持,第一次客户端访问后端某个pod,之后的请求都会转发到这个pod上
服务暴露给外部客户端
-
NodePort 每个集群节点都会在节点上打开一个端口,并且把端口上接收到的流量重定向到基础服务,服务仅仅在内部集群IP和端口上才能够访问,现在也可以通过所有节点上的专用端口访问
-
LoadBalance 服务可以通过一个专用的负载均衡器访问,负载均衡器把流量重定向到跨所有节点的节点端口,客户端通过负载均衡器的IP连接到服务
-
Ingress资源,通过一个IP地址公开多个服务,这是运行在HTTP层上面的
NodePort
apiVersion: v1
kind: Service
metadata:
name: kubia-nodeport
spec:
type: NodePort
ports:
- port: 80
targetPort: 8080
nodePort: 30123
selector:
app: kubia
可以通过集群任何节点的30123端口访问该服务
LoadBalancer
负载均衡器会有一个独一无二的可以供公开访问的IP地址,外界可以通过负载均衡器的IP地址访问服务
发送到LoadBalancer的请求会重定向到不同节点
apiVersion: v1
kind: Service
metadata:
name: kubia-loadbalancer
spec:
type: LoadBalancer
ports:
- port: 80
targetPort: 8080
selector:
app: kubia
为什么需要Ingress
- 因为每个LoadBalancer都要有自己的公有IP地址,而Ingress只需要一个公网IP就能为许多服务提供访问.
- 当客户端向Ingress发送HTTP请求的时候,Ingress会根据请求的主机名和路径决定请求转发到的服务
Ingress属于应用层操作,意味着可以提供基于cookie的会话亲和性功能
Ingress控制器
只有Ingress控制器在集群运行的时候,Ingress资源才能正常工作.
创建Ingress资源
大意就是Ingress控制器收到的所有请求主机kubia.example.com的HTTP请求,都会被转发到端口80的kubia-nodeport服务
apiVersion: extensions/v1beta1
kind: Ingress
metadata:
name: kubia
spec:
rules:
- host: kubia.example.com
http:
paths:
- path: /
backend:
serviceName: kubia-nodeport
servicePort: 80
创建Ingress之后,
alex@alex:~/Kubernetes-operator/kubernetes-in-action/Chapter05$ kubectl get ingresses
NAME HOSTS ADDRESS PORTS AGE
kubia kubia.example.com 10.0.2.15 80 30m
可以看到其绑定的IP地址
在/etc/hosts 下添加 kubia.example.com 10.0.2.15
然后访问该域名,通过Ingress就能成功访问该服务
了解Ingress的工作原理
- 客户端首先对域名执行DNS查找,DNS服务器会返回Ingress控制器的IP
- 客户端然后向Ingress控制器发送HTTP请求
- 通过查看Endpoint对象来查看pod IP
- 然后把客户端的请求转发给其中一个Pod
- Ingress控制器不会把请求转发给该服务,只用它来选择一个Pod
Pod就绪探针
有时候Pod启动之后需要一定时间来加载配置或者数据,这时候不希望pod立即开始接受请求,尤其是在运行的实例可以正确快速地处理请求的情况下,不要把请求转发到正在启动的Pod中,直到完全准备就绪
readiness probe会定期调用,确定特定的pod是否接受客户端请求,当容器准备就绪探测返回成功的时候,表示容器已经准备好接受请求
类型同样有三种
- exec
- HTTP
- TCP
大概工作过程:
- 启动容器的时候,为k8s配置一个等待时间,经过等待时间后才可以执行第一次准备检查
- 之后周期性调用探针,根据就绪探针的结果采取行动
- 如果探测失败,就把容器从Endpoint中删除
应该始终定义一个就绪探针
因为如果应用需要很长时间才能开始监听传入的连接,客户端马上把请求转发到该pod,客户端会看到"链接被拒绝"类型的错误
使用headless服务来发现独立的Pod
通过把yaml文件中的service的clusterIP设置为"None",那么该服务就变成headless服务了
因为没有ClusterIP,kube-proxy 并不处理此类服务,因为没有load balancing或 proxy 代理设置,在访问服务的时候回返回后端的全部的Pods IP地址
自定义Ingress-controller
这里参考ingress-controller
自定义写一个Ingress controller
apiVersion: apps/v1
kind: Deployment
metadata:
name: whoami
labels:
app: whoami
spec:
replicas: 1
selector:
matchLabels:
app: whoami
template:
metadata:
labels:
app: whoami
spec:
containers:
- name: whoami
image: cnych/whoami
ports:
- containerPort: 80
---
kind: Service
apiVersion: v1
metadata:
name: whoami
spec:
selector:
app: whoami
ports:
- protocol: TCP
port: 80
targetPort: 80
部署完该应用之后,在聚群内部可以通过whoami.default.svc.cluster.local来访问该应用,但是在集群外部的用户想要访问,方法有很多:
- 通过NodePort类型的Service来进行访问,但是应用多起来之后,端口管理会很麻烦
- 可以尝试用DaemonSet在每个边缘节点上运行一个Nginx应
用
spec:
hostNetwork: true
containers:
- image: nginx:1.15.3-alpine
name: nginx
ports:
- name: http
containerPort: 80
hostPort: 80
容器将使用宿主机网络,绑定节点的80端口,我们可以通过节点的公共IP地址的80端口访问到Nginx应用.
这种暴露服务方法的问题是如果应用发生了变更,需要手动修改配置,不能自动发现和热更新
第三种方法:
任何到域名who.alex.com的请求都会路由到whoami服务后面的pod列表中去
apiVersion: extensions/v1beta1
kind: Ingress
metadata:
name: whoami
spec:
tls:
- hosts:
- "*.alex.com"
secretName: alex-tls
rules:
- host: who.alex.com
http:
paths:
- path: /
backend:
serviceName: whoami
servicePort: 80
Ingress对象只是一个资源的声明而已,Ingress Controller才是真正的实现.
Ingress Controller的作用是负责读取Ingress对象的规则并且进行真正的请求处理,也就是说Ingress对象只是一个声明,Ingress Controller才是真正的实现