vivado-HLS入门
前言
FPGA的能耗比优于GPU,且设计自由度高,受到许多深度学习开发者的青睐。但是用HDL语言开发神经网络过于复杂,利用Xilinx公司的高层次综合工具vivado HLS开发RTL逻辑的IP核则可以降低开发难度。
本文主要描述了如何使用vivado HLS的基本功能。文章内容主要来自于Xilinx官方文档:ug871-vivado-high-level-synthesis-tutorial,所用代码来自于Xilinx官方例程:ug871-design-files\2016.1\Introduction\lab1。读者可以在原文档中阅读到更详细的内容。
工具说明
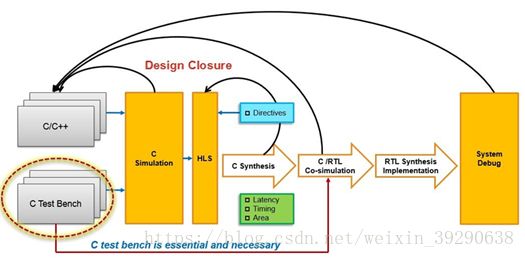
vivado-HLS可以实现直接使用 C,C++ 以及 System C 语言对Xilinx的FPGA器件进行编程。用户无需手动创建 RTL,通过高层次综合生成HDL级的IP核,从而加速IP创建。例如:神经网络的卷积层,用HDL语言实现是较复杂的,而用C代码描述是相对较简单的。用户用高层次语言将卷积层描述后,HLS工具再完成从高层次语言到HDL语言的转化。用户不用直面HDL级设计,提高了开发效率。同时,工具里的一些优化工具可以优化RTL的资源消耗和数据吞吐速率。
高层次综合工具的使用
本文包含3个内容:
1.如何新建HLS工程,并说明在HLS设计流程中需要执行所有主要步骤:
a)验证C代码。
b)创建和综合解决方案。
c)验证RTL并打包IP。
2.如何使用Tcl指令。
3.如何优化设计。
Lab01 HLS设计流程
Step 1: 新建一个工程
本步骤演示了在图形界面下新建一个工程(源代码来自于ug871-design-files.zip)。详细步骤见Fig.1~Fig.5。

Fig.1: 打开Vivado HLS,点击Create New Project,弹出一个小窗口。在小窗口中填上工程名以及工程存放的位置。完成后点击Next。
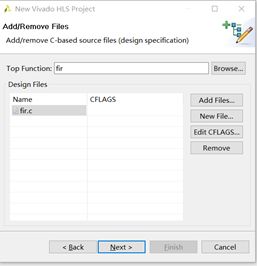
Fig.2:在Top Function一栏中填入顶层功能代码的文件名,点击Add Files或者New Files加入功能代码。“.h”头文件将会被自动加入工程。完成后点击Next。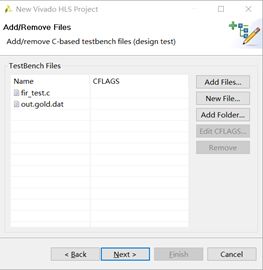
Fig.3:点击Add Files或者New Files加入testbench的测试代码和测试的数据集。完成后点击Next。
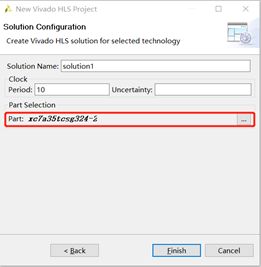
Fig.4:配置Solution Name,一般默认即可。配置Clock Period,单位是ns。配置Uncertainty,默认为12.5%。选择产品型号。完成后点击Finish。
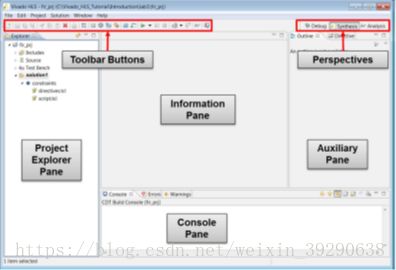
Fig.5:工程新建成功后进入的开发界面。HLS是典型的Eclipse框架,不再对各功能区做赘述。详细介绍见ug871-vivado-high-level-synthesis-tutorial中章节:Understanding the Graphical User Interface。
Step 2: C源代码验证
本步骤是对功能代码的逻辑验证,相当于功能前仿。
在source中编写好功能代码,在Test Bench中编写好测试代码,准备好标准输出数据。在测试代码中调用功能代码的函数,自己生成或者导入输入数据,保存输出数据并与标准输出数据作对比,验证功能的正确性。

Fig.6:点击红框中的按钮,开始C源代码验证
Step 3: 高层次综合
本步骤是把功能代码的综合成RTL逻辑。
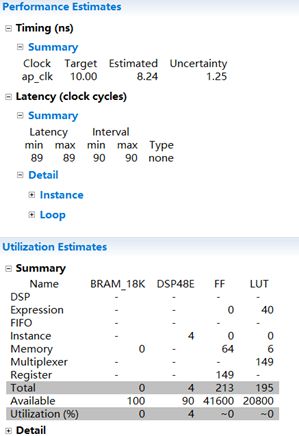
Fig.7:点击红框中的按钮,将C代码综合成RTL。综合完成后,查看结果。
Step 4: RTL验证
本步骤是对RTL的逻辑验证,由Test Bench提供测试数据和标准输出数据,相当于功能后仿。
Fig.8:点击红框中的按钮,进行RTL验证。
Step 5: IP创建
本步骤将RTL逻辑打包成HDL的IP核,右键点击solution1,选择Export RTL,弹出对话框,如图Fig.9。
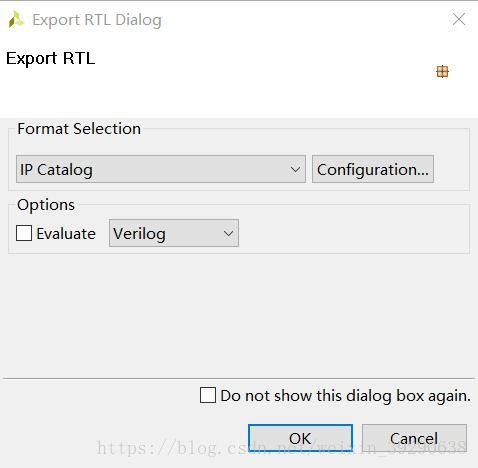
Fig.9:Configuration中可以配置IP核的信息,勾上Evaluate后,生成IP核的时间会增长。点击OK后,IP核会被打包成压缩文件到solution1/impl/ip/文件夹中。
Lab02 Tcl指令
在开始菜单中找到Vivado HLS 201x.x Command Prompt,单机打开,进入到HLS的Shell里,如图Fig.10。在Shell中可以运行“.tcl”文件。
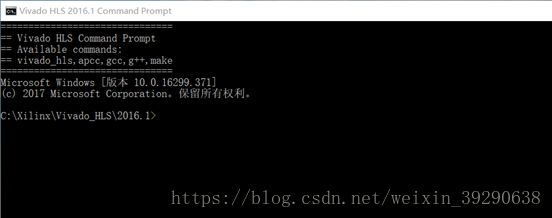
Fig.10: Vivado HLS 2016.1 Command Prompt是一个Shell,cd到相应的目录后,可以运行vivado_hls –f xxx.tcl编译相应工程。
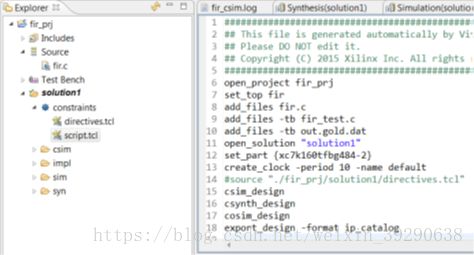
Fig.11: 如图,script.tcl文件中,包含多条Tcl 指令,script.tcl运行后,指令也相应地执行。
Fig.12: 可以直接在一个文件夹下仅用源代码,“.tcl”文件,测数据生成一个工程。
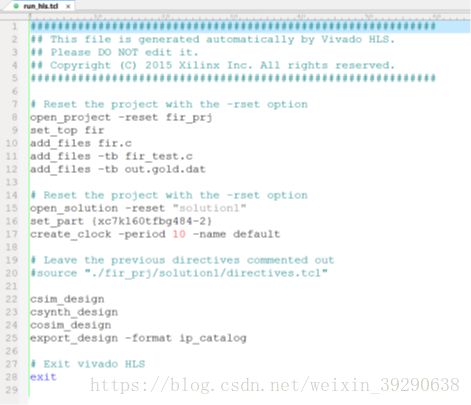
Fig.13: 一个Tcl示例如图所示,指令具体用法不再赘述,详细请参考ug871-vivado-high-level-synthesis-tutorial中章节:Using the Tcl Command Interface。
Lab03 优化设计(以Lab01为例)
1.优化I/O接口
高层次综合的设计实现中包括I/O协议,I/O接口的优化可以创建正确的I/O管脚,实现正确的I/O协议。
在Lab01中,主要有X,Y,C三个接口。X代表FIR的输入,Y代表FIR的输出,C代表FIR的滤波抽头系数的输入。对于这三种接口(接口综合结果见Fig.14),有以下几个特点:
a)接口X必须有一个输入数据有效信号。
b)接口Y必须有一个输出数据有效信号。
c)接口C相当于一个单端的RAM访问。
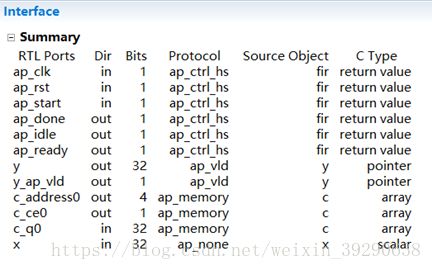
Fig.14:Lab01中,未在solution1中优化I/O,其默认结果如图。
接口分析如下:
1)输入端口X是一个32位数据端口。需要指定I/O协议ap_vld,将其实现为具有有效信号的输入数据端口。
2)输出端口Y已经具有相关的输出有效信号。这是指针参数的默认值。不必为该端口指定一个显式接口协议。考虑到设计 的规范性,要手动指定一个显式接口协议。
3)C端口是单端口RAM访问。但是,如果未显式指定RAM访问类型,则HLS为创建一个更高的吞吐量设计时,可能将其综合成双端口接口。应该手动显式指定RAM访问类型。
下面的操作(Fig.15~Fig.18)演示了如何手动指定I/O的接口协议
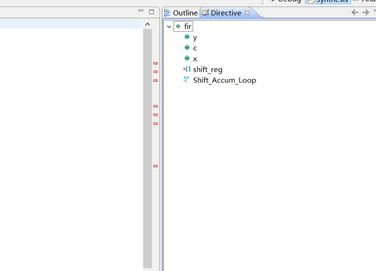
Fig.15:点击工具栏中的Project>New Solution,新建一个solution2。新建后,solution2为默认的solution。在辅助栏中点击Directive。右键点击每个端口,选择Insert Directive。
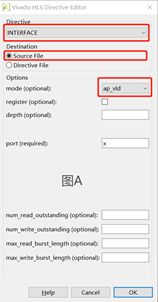
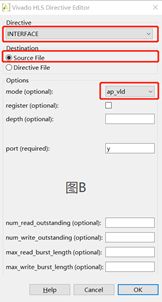
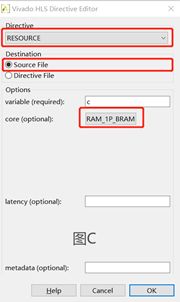
Fig.16:图A、B、C分别是点击开端口X、Y、C的Insert Directive后的配置界面,按照红框中的配置选项配置端口,点击OK。(其余可选的配置项不再赘述,可自行研究)
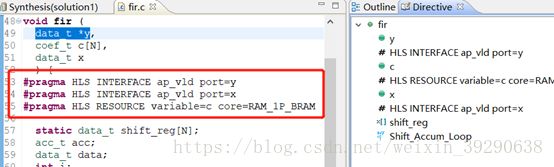
Fig.17:三个端口配置完成后,在源代码中会出现宏编译指令。
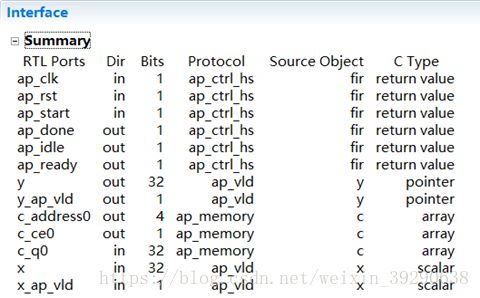
Fig.18:保存修改后,重新综合,综合后结果如上图。X端口增加了x_ap_vld。
2.综合结果分析
在优化设计之前,需要了解当前的设计。除了综合后的设计报告以外,Analysis窗口功能提供了更详细的细节分析,点击窗体右上角的 ,打开Analysis窗口,可以在Performance栏中看到操作逻辑的执行流程,如图Fig.19。
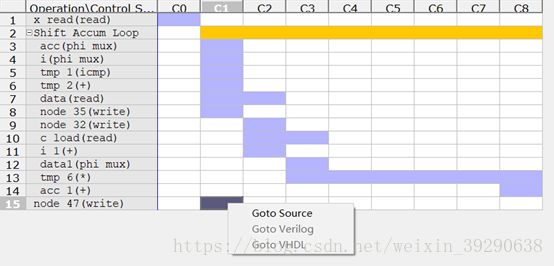
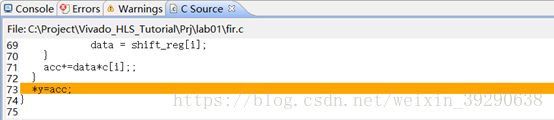
Fig.19:Performance是一张表格,这张表格描述了高层次逻辑综合成RTL逻辑后,逻辑操作与控制状态的对应表。第一列中排列好了逻辑操作的顺序,包括x read、shift Accum Loop、node 47三个操作,其中shift Accum Loop可以展开成多个子操作。第一行中的C0、C1…C8是RTL逻辑不同的控制状态,每个状态对应一个时钟,这些状态对应着RTL综合成的FSM的状态。对表中方块点击右键,选择Goto Source,可以定位到操作对应的源码。例如,此处的node 47对应着源码中的*y=acc。
Analysis窗口中的Resource栏中,展示了设计用到的资源,如图Fig.20。
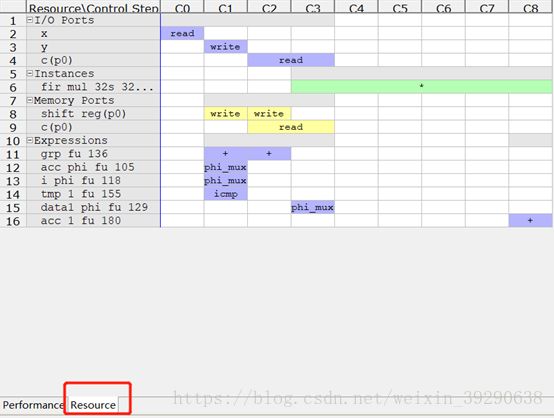
Fig.20:Resource表格描述了RTL逻辑对不同资源操作的时刻表。其中,图中带颜色的方块代表操作的类型。从表中可以看到不同操作所占用的时间。
3.优化最高吞吐率
有两个因素限制了设计的吞吐率:
for循环:默认情况下,for循环在综合时是未展开的。相同的操作逻辑会在没个时钟下重复执行。而展开for循环后,则能将for循环中多个时钟下的逻辑在一个时钟里并行执行。
移位寄存器被综合成block RAM:在默认的情况下,高层次代码中的移位寄存器会被综合成block RAM,而block RAM的读写需要两个周期。应该将移位寄存器综合成寄存器,读写仅一个周期。
下面的操作(Fig.21~Fig.24)演示了如何优化吞吐率

Fig.21:在Directive中,点击Shift_Accum_Loop,选中待优化的循环。点击右键,选择Insert Directive,进入配置界面。
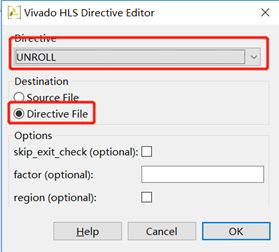
Fig.22:按图中红框配置,目标选为Directive File,这样不影响其他solution的配置(在源码中以宏编译选项配置在其他solution中仍生效)。点击OK后完成配置。
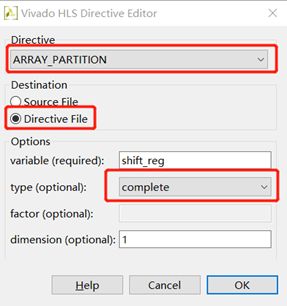
Fig.23:以同样的方法打开shift_reg的配置窗口,按照图中红框配置。点击OK后完成配置。
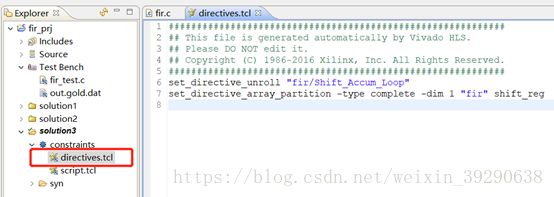
Fig.24:展开solution3,打开directives.tcl,可以看到优化指令。点击综合后可得到新的综合结果。
4.Solution比较

Fig.25:点击Project > Compare Reports,选择要比较的solution,得到上图。可以发现:增大吞吐率后,所用的资源增多。