【论文笔记】Auto-Encoding Variational Bayes
导读
VAE嘛,之前觉得水平不够,不敢读。现在觉得,试试吧。
Abstract
如何在连续隐变量,难以估计后验概率以及大量数据集的情况下,良好的推断与学习呢?
本文提出随机变量推断。
- 对于随机变量的下界估计使用重参数化可以直接通过随机梯度进行优化
- 在独立同分布数据集上的连续隐变量,后验估计可以很好的被估计出来。
Introduction
Auto-Encoding VB 算法,使用SGVB,使用简单的采样就可以估计出后验推断,并优化识别模型。
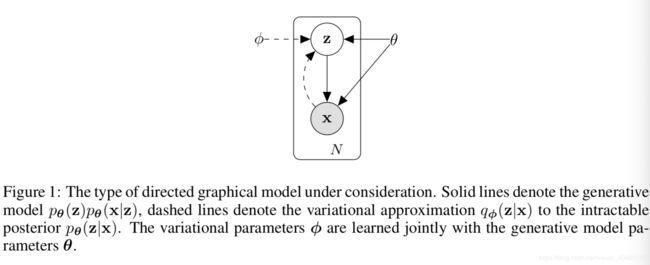
-
p θ ( z ) p θ ( x ∣ z ) p_{\theta}(\mathbf{z})p_{\theta}(\mathbf{x}|\mathbf{z}) pθ(z)pθ(x∣z) :生成模型,其中 p θ ( z ) p_{\theta}(\mathbf{z}) pθ(z)是先验, p θ ( x ∣ z ) p_{\theta}(\mathbf{x}|\mathbf{z}) pθ(x∣z)是似然函数。则观测变量 x \mathbf{x} x与目标变量 z \mathbf{z} z的联合概率就是生成模型。(因为 p θ ( x , z ) p_{\theta}(\mathbf{x}, \mathbf{z}) pθ(x,z))将二者都设定为随机变量,并且可以生成对应的概率分布。判别模型中是 p θ ( z ∣ x = x ) p_{\theta}(\mathbf{z}|\mathbf{x}=x) pθ(z∣x=x),只将 z \mathbf{z} z当作随机变量, x \mathbf{x} x是可观测且不会变化的。一个是联合分布,一个是条件概率分布。
-
q ϕ ( z ∣ x ) q_{\phi}(\mathbf{z}|\mathbf{x}) qϕ(z∣x):估计出来的后验分布
-
p θ ( z ∣ x ) p_\theta(\mathbf{z}|\mathbf{x}) pθ(z∣x):真实但难以计算的后验分布
那么显然其中的 ϕ \phi ϕ就是我们要学习variational 参数,并且会和生成模型的概率共同学习。
方法可以被用于online, non-stationary settings,很显然,因为先前学习的参数和后验会变成下一次优化的参数和先验,自然可以进行online的学习。
2.1 Problem scenario
假设 X = { x ( i ) } i = 1 N \mathbf{X}=\left\{\mathbf{x}^{(i)}\right\}_{i=1}^{N} X={x(i)}i=1N包含 N N N个连续或者离散的独立同分布变量。数据是由有一个不可观测的连续随机变量 z \mathbf{z} z的随机过程产生的
这个过程包含两步骤:
- z ( i ) \mathbf{z}^{(i)} z(i)是由先验分布 p θ ∗ ( z ) p_{\mathbf{\theta}^*}(\mathbf{z}) pθ∗(z)产生的
- x ( i ) \mathbf{x}^{(i)} x(i)是由条件概率分布 p θ ∗ ( x ∣ z ) p_{\mathbf{\theta}^*}(\mathbf{x}|\mathbf{z}) pθ∗(x∣z), 已知 z \mathbf{z} z分布,采样出 x ( i ) \mathbf{x}^{(i)} x(i)
假设先验 p θ ∗ ( z ) p_{\theta^*}(\mathbf{z}) pθ∗(z)和似然概率 p θ ∗ ( x ∣ z ) p_{\mathbf{\theta}^*}(\mathbf{x}|\mathbf{z}) pθ∗(x∣z)来自参数空间 p θ ( z ) p_{\theta}(\mathbf{z}) pθ(z)和 p θ ( x ∣ z ) p_{\mathbf{\theta}}(\mathbf{x}|\mathbf{z}) pθ(x∣z),那么 θ \theta θ和 z \mathbf{z} z都是可微分的。
这部分有两点难以读懂:
- x \mathbf{x} x 怎么是从给定 z \mathbf{z} z的条件概率中采样的?
- 这是assumption,观测到的 X \mathbf{X} X中的值均可以在给定 z \mathbf{z} z的情况下进行采样。
- 为什么都是可微分的?
- 因为可以通过 x \mathbf{x} x来进行微分?
此处不使用关于 p θ ( x ) p_{\theta}(\mathbf{x}) pθ(x)或者后验概率的一般简化假设。相反地,会使得普适性算法能够处理以下的特殊情况:
-
-
Intractability:
- p θ ( x ) = ∫ p θ ( z ) p θ ( x ∣ z ) d z p_\theta(x)=\int p_{\boldsymbol{\theta}}(\mathbf{z}) p_{\boldsymbol{\theta}}(\mathbf{x} \mid \mathbf{z}) d \mathbf{z} pθ(x)=∫pθ(z)pθ(x∣z)dz 是无法评估或者微分的。
- p θ ( z ∣ x ) = p θ ( x ∣ z ) p θ ( z ) / p θ ( x ) p_{\boldsymbol{\theta}}(\mathbf{z} \mid \mathbf{x})=p_{\boldsymbol{\theta}}(\mathbf{x} \mid \mathbf{z}) p_{\boldsymbol{\theta}}(\mathbf{z}) / p_{\boldsymbol{\theta}}(\mathbf{x}) pθ(z∣x)=pθ(x∣z)pθ(z)/pθ(x) 难解,无法使用EM算法
- 任何合理的均值场VB算法所需的积分也是难解的
这些难解的情况很常见,像中等程度复杂的似然概率函数 p θ ( x ∣ z ) p_{\boldsymbol{\theta}}(\mathbf{x} \mid \mathbf{z}) pθ(x∣z) ,例如有一层非线性隐藏层的神经网络。
-
A large dataset: 数据量很大,batch 优化消耗太大了,希望能够使用小数据甚至单个数据就可以对参数进行更新。基于采样的方案,例如蒙特卡洛EM算法,通常来说太慢了,因为每个数据点的采样过程中的loop太慢了。
-
更希望去处理以下三种情况:
- 高效的估计参数,参数本身会很有趣,因为可以反应neural的过程中存在的问题。
- 高效的后验推断估计, 在给定参数 θ \boldsymbol{\theta} θ和 x \mathbf{x} x观测的情况下情况下, p θ ( z ∣ x ) p_{\boldsymbol{\theta}}(\mathbf{z} \mid \mathbf{x}) pθ(z∣x)
- 高效的边缘概率估计, i.e. p θ ( x ) p_\boldsymbol{\theta}(\mathbf{x}) pθ(x)
为了解决上述问题,引入识别模型 q ϕ ( z ∣ x ) q_{\phi}(\mathbf{z}|\mathbf{x}) qϕ(z∣x),对真实难解的后验概率 p θ ( z ∣ x ) p_\theta(\mathbf{z}|\mathbf{x}) pθ(z∣x)的估计。
此处不需要重整计算参数,因为作者会将模型的参数 ϕ \boldsymbol{\phi} ϕ 与生成模型参数 θ \boldsymbol{\theta} θ进行共同学习。
从编码论角度,不可观测变量 z \mathbf{z} z作为隐表征或者编码。因此本文中会:
- 将识别模型 q ϕ ( z ∣ x ) q_{\phi}(\mathbf{z}|\mathbf{x}) qϕ(z∣x)作为概率编码器encoder,因为给定一个数据点 x x x,encoder会生成一个概率分布,并在其上产生一个可能的code z \mathbf{z} z,在code上可以产生原始数据点 x x x
- 将 p θ ( x ∣ z ) p_{\boldsymbol{\theta}}(\mathbf{x} \mid \mathbf{z}) pθ(x∣z)作为概率解码器decoder,因为给定一个code z \mathbf{z} z,他可以产生原始 x x x的对应值。
2.2 The variational bound
边缘似然是由独立点的边缘似然总和 log p θ ( x ( 1 ) , ⋯ , x ( N ) ) = ∑ i = 1 N log p θ ( x ( i ) ) \log p_{\boldsymbol{\theta}}\left(\mathbf{x}^{(1)}, \cdots, \mathbf{x}^{(N)}\right)=\sum_{i=1}^{N} \log p_{\boldsymbol{\theta}}\left(\mathbf{x}^{(i)}\right) logpθ(x(1),⋯,x(N))=∑i=1Nlogpθ(x(i)), 其中每一个点均可以被协作为:
log p θ ( x ( i ) ) = D K L ( q ϕ ( z ∣ x ( i ) ) ∥ p θ ( z ∣ x ( i ) ) ) + L ( θ , ϕ ; x ( i ) ) \log p_{\boldsymbol{\theta}}\left(\mathbf{x}^{(i)}\right)=D_{K L}\left(q_{\boldsymbol{\phi}}\left(\mathbf{z} \mid \mathbf{x}^{(i)}\right) \| p_{\boldsymbol{\theta}}\left(\mathbf{z} \mid \mathbf{x}^{(i)}\right)\right)+\mathcal{L}\left(\boldsymbol{\theta}, \boldsymbol{\phi} ; \mathbf{x}^{(i)}\right) logpθ(x(i))=DKL(qϕ(z∣x(i))∥pθ(z∣x(i)))+L(θ,ϕ;x(i))
第一项是识别模型的估计后验以及真实后验的KL散度误差。因为KL散度是非负的,第二项 L ( θ , ϕ ; x ( i ) ) \mathcal{L}\left(\boldsymbol{\theta}, \boldsymbol{\phi} ; \mathbf{x}^{(i)}\right) L(θ,ϕ;x(i))是数据点 i i i的边缘似然的变分下界。也是我们想要优化的目标。
KL散度是很自然可以理解的度量两个分布的相对熵
可以被写作
log p θ ( x ( i ) ) ≥ L ( θ , ϕ ; x ( i ) ) = E q ϕ ( z ∣ x ) [ − log q ϕ ( z ∣ x ) + log p θ ( x , z ) ] \log p_{\boldsymbol{\theta}}\left(\mathbf{x}^{(i)}\right) \geq \mathcal{L}\left(\boldsymbol{\theta}, \boldsymbol{\phi} ; \mathbf{x}^{(i)}\right)=\mathbb{E}_{q_{\boldsymbol{\phi}}(\mathbf{z} \mid \mathbf{x})}\left[-\log q_{\boldsymbol{\phi}}(\mathbf{z} \mid \mathbf{x})+\log p_{\boldsymbol{\theta}}(\mathbf{x}, \mathbf{z})\right] logpθ(x(i))≥L(θ,ϕ;x(i))=Eqϕ(z∣x)[−logqϕ(z∣x)+logpθ(x,z)]
也可以被写做:
L ( θ , ϕ ; x ( i ) ) = − D K L ( q ϕ ( z ∣ x ( i ) ) ∥ p θ ( z ) ) + E q ϕ ( z ∣ x ( i ) ) [ log p θ ( x ( i ) ∣ z ) ] \mathcal{L}\left(\boldsymbol{\theta}, \boldsymbol{\phi} ; \mathbf{x}^{(i)}\right)=-D_{K L}\left(q_{\boldsymbol{\phi}}\left(\mathbf{z} \mid \mathbf{x}^{(i)}\right) \| p_{\boldsymbol{\theta}}(\mathbf{z})\right)+\mathbb{E}_{q_{\boldsymbol{\phi}}\left(\mathbf{z} \mid \mathbf{x}^{(i)}\right)}\left[\log p_{\boldsymbol{\theta}}\left(\mathbf{x}^{(i)} \mid \mathbf{z}\right)\right] L(θ,ϕ;x(i))=−DKL(qϕ(z∣x(i))∥pθ(z))+Eqϕ(z∣x(i))[logpθ(x(i)∣z)]
看到这里感觉已经比较让我理解VAE了。有需要再in-depth
Understanding 2020-6-28
相较于之前仅仅只是映射到隐空间中,今天的阅读让我更区分了一些AE和VAE的区别。
AE将x-> z-> x’
VAE是将x映射成一个分布,并在分布上采样出可能的x。