基于卷积神经网络(CNN)模型的肺炎诊断系统
本文主要基于kaggle数据集(胸部X射线照片)进行肺炎疾病的识别与预测。主要将探索两部分内容:
一是:通过训练深度学习模型(多层CNN模型),使CNN能够根据患者胸部的X射线图像检测患者是否患有肺炎疾病。
二是:通过flask构建web系统,使其加载训练好的神经网络模型能够使其实时进行图像检测,以应用深度学习方法(CNN)进行肺炎的检测。
目录
背景
相关工作
卷积神经网络概述
基于浅层卷积神经网络的肺炎检测模型构建与实验
基于CNN和flask构建的肺炎诊断预测系统
结论
参考文献及资料
背景
肺炎给人类的健康生活带来巨大风险和挑战,尤其是当今世界数十亿人面临能源匮乏,污染严重,人口众多的发展中国家。世界卫生组织估计,每年有超过400万的人死于空气污染所导致的疾病,包括肺炎。每年有超过1.5亿人感染肺炎,尤其是5岁以下的儿童。尤其在医疗技术不是很发达的国家,由于缺乏医疗资源和医护人员,这个问题可能会进一步恶化。例如,在非洲的57个国家中,医生和护士之间的缺口为230万。对于这些人群,准确而快速的诊断至关重要。它可以保证及时获得治疗,并为已经遭受贫困的人们节省很多时间和金钱。目前,精准医疗的提出,人工智能的发展为疾病的快速诊断奠定了基础。建立一种通过查看胸部X射线图像自动识别患者是否患有肺炎的算法是非常有必要的。
目前,胸部 X 光检查是诊断肺炎的最佳方法,它在临床护理和流行病学研究中发挥着至关重要的作用。然而,通过 X 光片来检测肺炎是一项具有挑战性的任务,需要依赖放射科医师的专业能力。然而,随着深度学习的兴起,卷积神经网络能够准确的应用于图像的识别与处理,为医疗诊断提供了新的技术和方法支持。
相关工作
17年吴恩达团队发表了一篇论文:CheXNet: Radiologist-Level Pneumonia Detection on Chest X-Rays with Deep Learning,该论文提出CheXNet技术,即是一个使用ChestX-ray14数据集训练的121层的深度卷积网络,该网络通过胸片识别肺炎的准确率已经和人类放射科医生持平甚至更高。网络输入为人体正面扫描的胸片,输入时患肺炎的概率。该模型层结构复杂,数据量大,因此训练的模型比较精准。
卷积神经网络概述
卷积神经网络(CNN)是一类深层神经网络,专门研究图像分析,因此被广泛用于计算机视觉应用,例如图像分类和聚类,对象检测以及神经样式转换。要了解CNN,首先需要看一下卷积是什么。假设有一个5×5的灰度图像和一个3×3的矩阵,称为过滤器或卷积核,我们想通过对每个使用过滤器的3×3图像块进行逐元素矩阵乘法来“卷积”图像,然后取特征总和。总和将成为所得3×3图像的元素。在下面的示例为卷积过程,计算新图像的第一个元素,其余的可以使用相同的策略计算。
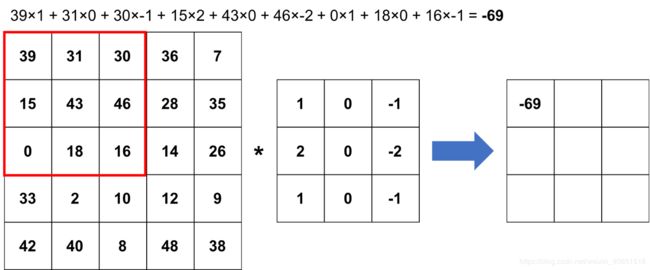
与灰度图像相比,彩色图像具有多个通道,例如红色,蓝色和绿色。因此,需要使用通道数相同的滤波器,并对每个通道进行卷积,然后求和。这本质上是单个卷积层。
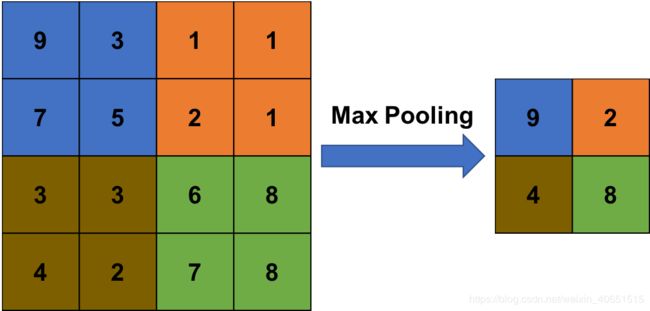
CNN的另一个结构是池化层。例如,最大池仅占用每个子块的最大值,而平均池则取平均值。实际上,最大池化更常用。如图所示,池化层可以减少维数,从而加快计算速度。
CNN的最后一层为全连接层。最后的卷积和池化层的输出将被展平为一维向量,并送入一个或多个完全连接的层。综上所述,CNN示例如下所示:

简单的CNN 层只能检测简单的特征(如边缘),但复杂结构层的CNN可以检测复杂的对象(如人脸)。要想了解更多有关CNN及其应用的信息,建议找相关资料和论文进行学习。

基于浅层卷积神经网络的肺炎检测模型构建与实验
实验环境:python3.6、tensorflow1.1.3、keras2.16
数据描述:
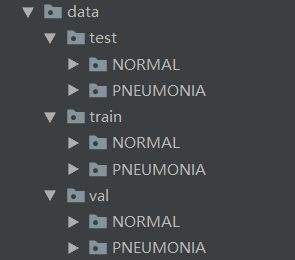
通过下载kaggle的Chest X-Ray Images (Pneumonia)数据集,其中一共包含5,863图像, 2种类别。当然还有其他数据集数据,例如ChestX-ray8数据集等。但是为了快速训练模型,我们随机选择了部分数据。其中包含训练集、验证集和测试集,其项目数据结构及数据统计如图所示(当大家的目的不是为了跑通模型,而是为了追求高准确率时,可以进行数据的合并):
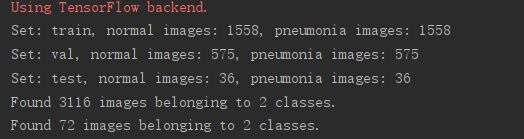
| 数据样本 | 正样本个数 | 负样本个数 |
| 训练集 | 1558 | 1558 |
| 验证集 | 575 | 575 |
| 测试集 | 36 | 36 |
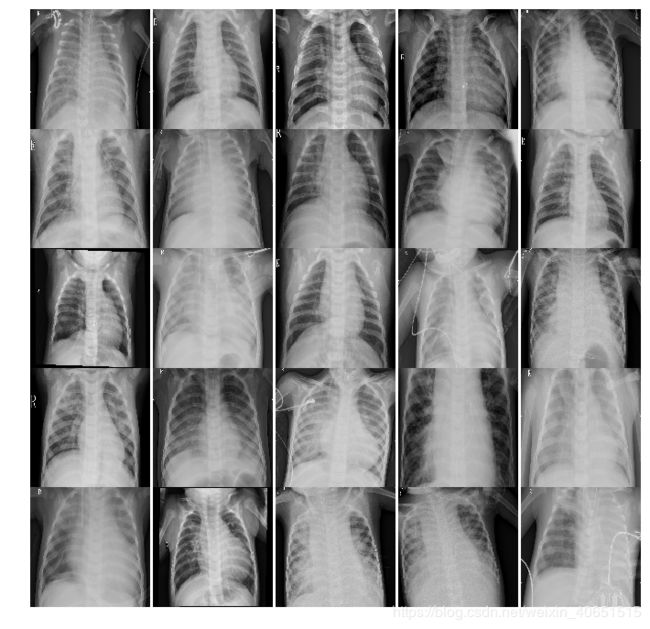
数据集样本展示:肺炎样本X-ray图像和正常X-ray肺部图像
正常肺部X-ray图像:

肺炎X-ray图像:
问题解决与模型构建:
根据X射线扫描出的图片进行检测肺炎其实就是一个简单的二进制分类问题:要么检测出肺炎,要么检测正常。用数字给这个表示法进行赋值,以便计算机模型能够理解,要么0表示正常,1表示肺炎,要么反之。然后,通过from keras.preprocessing.image import ImageDataGenerator定义了两个数据生成器:一个用于训练数据,另一个用于验证数据。数据生成器 能够直接从源文件夹中加载所需数量的数据(少量图像),将其转换为训练数据(馈入模型)和训练目标(属性向量-监督信号)。
最后则是模型的建立。本次实现主要使用了三个卷积块(为了训练快),这些卷积块由卷积层,最大池和批归一化组成。最后,使用一个扁平层,然后是全连接层。同样,在这两者之间,我使用dropout来减少过度拟合。
激活函数及模型优化问题:激活函数始终是Relu(求导快、速度快),除了最后一层是Sigmoid,因为是二分类问题。我使用adam作为优化器,使用交叉熵作为损失函数。其具体模型如图所示:
在训练模型中定义了两个方法用于模型的训练:ModelCheckpoint和EarlyStopping。
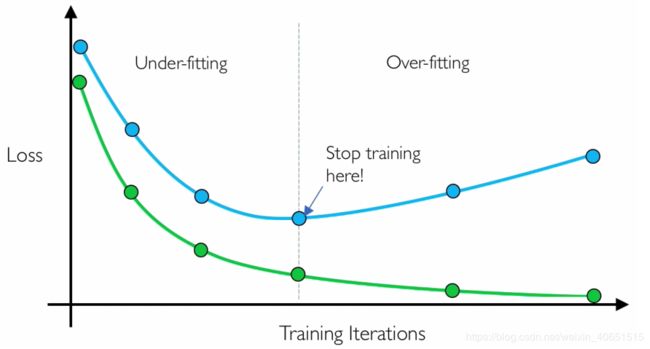
ModelCheckpoint:当训练需要大量时间才能获得良好的结果时,通常需要多次迭代。在这种情况下,最好仅在改善指标的时期结束时保存性能最佳的模型的副本。
EarlyStopping:有时,在训练过程中,我们可以注意到泛化差距(即训练与验证错误之间的差异)开始增加而不是减少。这是过度拟合的征兆,可以通过多种方式解决(减少模型容量,增加训练数据,数据汇总,正则化,退出等)。通常,一种实用而有效的解决方案是在泛化差距越来越严重时停止训练。
核心代码实现:
inputs = Input(shape=(img_dims, img_dims, 3))
# First
x = Conv2D(filters=16, kernel_size=(3, 3), activation='relu', padding='same')(inputs)
x = Conv2D(filters=16, kernel_size=(3, 3), activation='relu', padding='same')(x)
x = MaxPool2D(pool_size=(2, 2))(x)
# Second
x = SeparableConv2D(filters=32, kernel_size=(3, 3), activation='relu', padding='same')(x)
x = SeparableConv2D(filters=32, kernel_size=(3, 3), activation='relu', padding='same')(x)
x = BatchNormalization()(x)
x = MaxPool2D(pool_size=(2, 2))(x)
# Third
x = SeparableConv2D(filters=64, kernel_size=(3, 3), activation='relu', padding='same')(x)
x = SeparableConv2D(filters=64, kernel_size=(3, 3), activation='relu', padding='same')(x)
x = BatchNormalization()(x)
x = MaxPool2D(pool_size=(2, 2))(x)
# FC layer
x = Flatten()(x)
x = Dense(units=512, activation='relu')(x)
x = Dropout(rate=0.7)(x)
x = Dense(units=128, activation='relu')(x)
x = Dropout(rate=0.5)(x)
x = Dense(units=64, activation='relu')(x)
x = Dropout(rate=0.3)(x)
# Output layer
output = Dense(units=1, activation='sigmoid')(x)
# Creating model and compiling
model = Model(inputs=inputs, outputs=output)
model.compile(optimizer='adam', loss='binary_crossentropy', metrics=['accuracy'])
# plot_model(model, to_file='./model2.png', show_shapes=True)
# Callbacks
checkpoint = ModelCheckpoint(filepath='best_weights.hdf5', save_best_only=True, save_weights_only=True)
lr_reduce = ReduceLROnPlateau(monitor='val_loss', factor=0.3, patience=2, verbose=2, mode='max')
early_stop = EarlyStopping(monitor='val_loss', min_delta=0.1, patience=1, mode='min')
hist = model.fit_generator(
train_gen, steps_per_epoch=train_gen.samples // batch_size,
epochs=epochs, validation_data=test_gen,
validation_steps=test_gen.samples // batch_size, callbacks=[checkpoint, lr_reduce])实现结果分析:
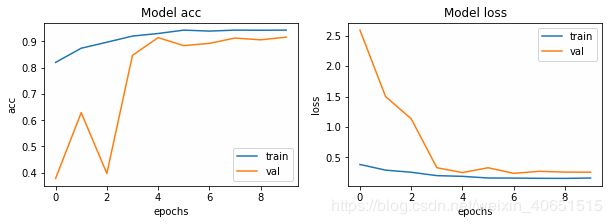
至此,模型已经构建好了,接下来,训练了10个迭代次数,批处理大小为32。(注意,通常批处理大小越大,效果越好,但是要以计算负担较大为代价。在该模型训练时,模型在第七次已经达到较好,Epoch 000015: ReduceLROnPlateau reducing learning rate to 9.000000427477062e-05.但是为了训练VGG快一点,只训练10次)大家在复现我的方法时,为了获得最佳结果,可以花费一些时间来进行超参数的调整。模型在迭代10次后其结果如下所示:
不同模型结果对比:
在该相同测试数据集上,迭代10次进行比较(其中VGG19模型内增加了各500个正负样本,调小了部分参数,便于训练):
| 深度学习模型 | P | R | F |
| 多层CNN | 86.96 | 90.35 | 83.89 |
| VGG19 | 89.76 | 96.66 | 93.08 |
在该数据集上现实,VGG19能够更好的进行肺炎疾病的检测。但是,VGG由于模型结构复杂,训练较慢,如果合作调整参数和增加数据集,应该会得到更好的效果。在这里我不在进行尝试。
基于CNN和flask构建的肺炎诊断预测系统
开发环境及依赖库:python-3.6、Flask、uwsgi、tensorflow、keras、Pillow、numpy
实现功能:将训练好的模型保存为model.h5的形式供系统调用实现检测功能。因此,该系统具有两个简单功能:1.点击肺炎知识可以跳转到其他学习网页,以便更多的了解肺炎知识。2. 该项目通过界面进行上传胸部X射线图像作为预训练好的模型输入,并预测是否存在肺炎,然后通过界面进行结果反馈。可视化系统界面如图所示:
系统核心功能应用测试:通过选择文件按钮进行上传测试图形,然后点击预测按钮进行预测。其返回结果需要等待几秒钟。测试结果实现界面如下:
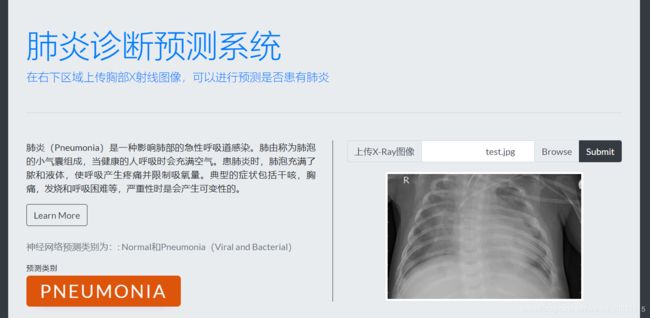
结论
尽管这个项目以初步完成,但是仍旧有许多需要细化的点。其中有以下两点:
1.尽管简单的肺炎识别通过大量数据和复杂模型能够做到精准预测与识别,但是区分包含肺癌和肺炎的X射线图像一直是一个大问题,解决此类问题,最重要的就是有一手数据集。当然提出一个解决能够实现精准肺炎诊断的高性能模型仍旧值得研究。
2. 肺炎检测系统的实现需要更为人性化的设计,包括该系统的响应时间,如何做到最快。
参考文献及资料
(1) CheXNet: Radiologist-Level Pneumonia Detection on Chest X-Rays with Deep Learning
(2) Pneumonia Detection using CNN -https://www.slideshare.net/YashIyengar/pneumonia-detection-using-cnn
(3) Classification of Images of Childhood Pneumonia using CNN
(4)Development and validation of a deep learning algorithmfor detection of diabetic retinopathy in retinal fundus photographs
(5) An Efficient Deep Learning Approach to Pneumonia Classification in Healthcare
(6) Chest-xray-pneumonia data
(8) ChestX-ray14数据集
卷积神经网络学习资源和地址:https://setosa.io/ev/image-kernels/
通过模型yi胸部X射线照片(肺炎)胸部X射线照片(肺炎)
通过